
















 Дом
ДомОптимизация выбора модели ИИ для реальной производительности
Предприятия должны обеспечивать эффективную работу моделей ИИ, управляющих приложениями, в реальных сценариях. Предсказание этих сценариев может быть сложным, что затрудняет оценку. Обновленный бенчмарк RewardBench 2 предоставляет организациям более четкое представление о практической производительности модели.
Институт Аллена по искусственному интеллекту (Ai2) представил RewardBench 2, улучшенную версию своего бенчмарка RewardBench, разработанную для всесторонней оценки производительности модели и соответствия целям предприятия.
Ai2 разработал RewardBench с задачами классификации, которые оценивают корреляции через вычисления во время вывода и последующее обучение. RewardBench фокусируется на моделях вознаграждения (RMs), которые оценивают результаты больших языковых моделей, присваивая баллы или «вознаграждения» для управления обучением с подкреплением на основе человеческой обратной связи (RHLF).
RewardBench 2 здесь! Мы потратили много времени, чтобы извлечь уроки из нашего первого инструмента оценки моделей вознаграждения и создать более сложный и коррелирующий с последующим RLHF и масштабированием во время вывода. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 июня 2025
Натан Ламберт, старший научный сотрудник Ai2, рассказал VentureBeat, что изначально RewardBench работал хорошо, но эволюция модельных сред потребовала обновленных бенчмарков.
«По мере того как модели вознаграждения становились более сложными, а сценарии использования — более комплексными, мы, вместе с сообществом, увидели, что первая версия не полностью учитывала сложности человеческих предпочтений в реальном мире», — объяснил он.
Ламберт отметил, что RewardBench 2 расширяет объем и глубину оценки, включая разнообразные, сложные запросы и усовершенствованные методы, чтобы лучше отражать человеческое суждение о результатах ИИ. Он включает новые человеческие запросы, более строгую систему оценки и дополнительные домены.
Использование оценок для анализа моделей
Модели вознаграждения оценивают производительность моделей, но их соответствие ценностям компании имеет решающее значение. Неправильно выровненные RMs могут усиливать проблемы, такие как галлюцинации, снижать обобщающую способность или чрезмерно благоприятствовать вредным ответам во время тонкой настройки и обучения с подкреплением.
RewardBench 2 охватывает шесть доменов: фактическая точность, точное следование инструкциям, математика, безопасность, фокус и равенство.
«Предприятия могут использовать RewardBench 2 двумя способами в зависимости от их потребностей. Для RLHF они должны интегрировать лучшие практики и наборы данных от топовых моделей в свои процессы, поскольку модели вознаграждения требуют обучения в реальном времени. Для масштабирования во время вывода или фильтрации данных RewardBench 2 помогает выбрать лучшую модель для их домена с коррелирующей производительностью», — сказал Ламберт.
Ламберт подчеркнул, что бенчмарки, такие как RewardBench, позволяют пользователям оценивать модели на основе наиболее важных для них приоритетов, а не общего балла. Он отметил, что производительность субъективна, сильно связана с контекстом и целями пользователя, а человеческие предпочтения часто очень нюансированы.
Ai2 запустил оригинальный RewardBench в марте 2024 года, назвав его первым бенчмарком и таблицей лидеров для моделей вознаграждения. С тех пор появились новые методы, такие как reWordBench от Meta FAIR и Self-Principled Critique Tuning от DeepSeek для более умных и масштабируемых RMs.
Очень рад, что наша вторая оценка моделей вознаграждения вышла. Она значительно сложнее, чище и хорошо коррелирует с последующим PPO/BoN сэмплированием.
Счастливого восхождения на холм!
Огромные поздравления @saumyamalik44, которая руководила проектом с полной приверженностью к совершенству. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2 июня 2025
Инсайты по производительности моделей
С помощью RewardBench 2 Ai2 протестировал как существующие, так и недавно обученные модели, включая варианты Gemini, Claude, GPT-4.1 и Llama-3.1, а также наборы данных и модели, такие как Qwen, Skywork и Tulu.
Результаты показали, что большие модели вознаграждения превосходят благодаря более сильным базовым моделям. Варианты Llama-3.1 Instruct возглавили бенчмарк, при этом данные Skywork помогли в фокусе и безопасности, а Tulu показал хорошие результаты в фактической точности.
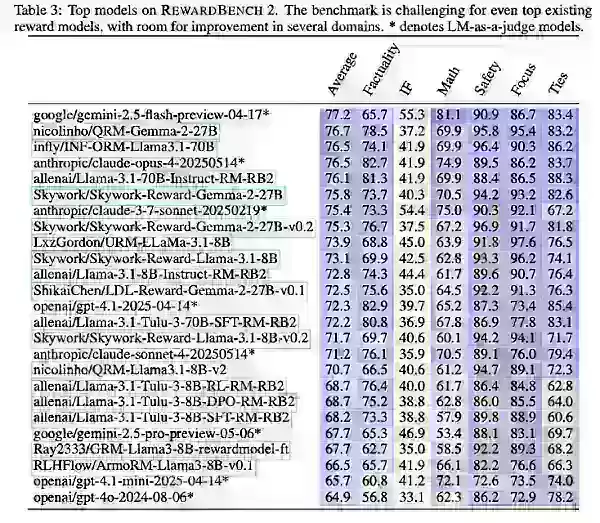
Ai2 отметил, что, хотя RewardBench 2 продвигает многодоменную оценку, ориентированную на точность, для моделей вознаграждения, он в первую очередь должен направлять предприятия в выборе моделей, наиболее подходящих для их конкретных потребностей.
Связанная статья
 Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Рекомендации по связанным специальным темам
Создание комиксов
Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (3)
Комментарии (3)
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
Предприятия должны обеспечивать эффективную работу моделей ИИ, управляющих приложениями, в реальных сценариях. Предсказание этих сценариев может быть сложным, что затрудняет оценку. Обновленный бенчмарк RewardBench 2 предоставляет организациям более четкое представление о практической производительности модели.
Институт Аллена по искусственному интеллекту (Ai2) представил RewardBench 2, улучшенную версию своего бенчмарка RewardBench, разработанную для всесторонней оценки производительности модели и соответствия целям предприятия.
Ai2 разработал RewardBench с задачами классификации, которые оценивают корреляции через вычисления во время вывода и последующее обучение. RewardBench фокусируется на моделях вознаграждения (RMs), которые оценивают результаты больших языковых моделей, присваивая баллы или «вознаграждения» для управления обучением с подкреплением на основе человеческой обратной связи (RHLF).
RewardBench 2 здесь! Мы потратили много времени, чтобы извлечь уроки из нашего первого инструмента оценки моделей вознаграждения и создать более сложный и коррелирующий с последующим RLHF и масштабированием во время вывода. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 июня 2025
Натан Ламберт, старший научный сотрудник Ai2, рассказал VentureBeat, что изначально RewardBench работал хорошо, но эволюция модельных сред потребовала обновленных бенчмарков.
«По мере того как модели вознаграждения становились более сложными, а сценарии использования — более комплексными, мы, вместе с сообществом, увидели, что первая версия не полностью учитывала сложности человеческих предпочтений в реальном мире», — объяснил он.
Ламберт отметил, что RewardBench 2 расширяет объем и глубину оценки, включая разнообразные, сложные запросы и усовершенствованные методы, чтобы лучше отражать человеческое суждение о результатах ИИ. Он включает новые человеческие запросы, более строгую систему оценки и дополнительные домены.
Использование оценок для анализа моделей
Модели вознаграждения оценивают производительность моделей, но их соответствие ценностям компании имеет решающее значение. Неправильно выровненные RMs могут усиливать проблемы, такие как галлюцинации, снижать обобщающую способность или чрезмерно благоприятствовать вредным ответам во время тонкой настройки и обучения с подкреплением.
RewardBench 2 охватывает шесть доменов: фактическая точность, точное следование инструкциям, математика, безопасность, фокус и равенство.
«Предприятия могут использовать RewardBench 2 двумя способами в зависимости от их потребностей. Для RLHF они должны интегрировать лучшие практики и наборы данных от топовых моделей в свои процессы, поскольку модели вознаграждения требуют обучения в реальном времени. Для масштабирования во время вывода или фильтрации данных RewardBench 2 помогает выбрать лучшую модель для их домена с коррелирующей производительностью», — сказал Ламберт.
Ламберт подчеркнул, что бенчмарки, такие как RewardBench, позволяют пользователям оценивать модели на основе наиболее важных для них приоритетов, а не общего балла. Он отметил, что производительность субъективна, сильно связана с контекстом и целями пользователя, а человеческие предпочтения часто очень нюансированы.
Ai2 запустил оригинальный RewardBench в марте 2024 года, назвав его первым бенчмарком и таблицей лидеров для моделей вознаграждения. С тех пор появились новые методы, такие как reWordBench от Meta FAIR и Self-Principled Critique Tuning от DeepSeek для более умных и масштабируемых RMs.
Очень рад, что наша вторая оценка моделей вознаграждения вышла. Она значительно сложнее, чище и хорошо коррелирует с последующим PPO/BoN сэмплированием.
— Nathan Lambert (@natolambert) 2 июня 2025
Счастливого восхождения на холм!
Огромные поздравления @saumyamalik44, которая руководила проектом с полной приверженностью к совершенству. https://t.co/c0b6rHTXY5
Инсайты по производительности моделей
С помощью RewardBench 2 Ai2 протестировал как существующие, так и недавно обученные модели, включая варианты Gemini, Claude, GPT-4.1 и Llama-3.1, а также наборы данных и модели, такие как Qwen, Skywork и Tulu.
Результаты показали, что большие модели вознаграждения превосходят благодаря более сильным базовым моделям. Варианты Llama-3.1 Instruct возглавили бенчмарк, при этом данные Skywork помогли в фокусе и безопасности, а Tulu показал хорошие результаты в фактической точности.
Ai2 отметил, что, хотя RewardBench 2 продвигает многодоменную оценку, ориентированную на точность, для моделей вознаграждения, он в первую очередь должен направлять предприятия в выборе моделей, наиболее подходящих для их конкретных потребностей.










 Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
 Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
 Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













