




Các mô hình AI mới nhất của Openai có một biện pháp bảo vệ mới để ngăn chặn Biorisks
Các biện pháp an toàn mới của OpenAI cho các mô hình AI o3 và o4-mini
OpenAI đã giới thiệu một hệ thống giám sát mới cho các mô hình AI tiên tiến của mình, o3 và o4-mini, được thiết kế đặc biệt để phát hiện và ngăn chặn các phản hồi đối với các câu hỏi liên quan đến mối đe dọa sinh học và hóa học. Hệ thống giám sát tập trung vào an toàn này là phản ứng đối với các khả năng nâng cao của các mô hình này, mà theo OpenAI, là một bước tiến đáng kể so với các phiên bản trước và có thể bị lạm dụng bởi các tác nhân xấu.
Các tiêu chuẩn nội bộ của công ty cho thấy rằng o3, đặc biệt, đã thể hiện mức độ thành thạo cao hơn trong việc trả lời các câu hỏi về việc tạo ra một số mối đe dọa sinh học. Để giải quyết vấn đề này và các rủi ro tiềm tàng khác, OpenAI đã phát triển hệ thống mới này, hoạt động song song với o3 và o4-mini. Hệ thống này được huấn luyện để nhận biết và từ chối các câu hỏi có thể dẫn đến lời khuyên gây hại về rủi ro sinh học và hóa học.
Kiểm tra và Kết quả
Để đánh giá hiệu quả của hệ thống giám sát an toàn này, OpenAI đã tiến hành kiểm tra mở rộng. Các nhóm thử nghiệm đỏ đã dành khoảng 1.000 giờ để xác định các cuộc hội thoại liên quan đến rủi ro sinh học "không an toàn" được tạo ra bởi o3 và o4-mini. Trong một mô phỏng về "logic chặn" của hệ thống giám sát, các mô hình đã từ chối trả lời các câu hỏi rủi ro thành công 98,7% thời gian.
Tuy nhiên, OpenAI thừa nhận rằng thử nghiệm của họ không xem xét các kịch bản mà người dùng có thể thử các câu hỏi khác sau khi bị chặn. Do đó, công ty có kế hoạch tiếp tục sử dụng giám sát con người như một phần của chiến lược an toàn.
Đánh giá Rủi ro và Giám sát Liên tục
Mặc dù có khả năng tiên tiến, o3 và o4-mini không vượt quá ngưỡng "rủi ro cao" của OpenAI đối với các rủi ro sinh học. Tuy nhiên, các phiên bản ban đầu của các mô hình này có khả năng trả lời các câu hỏi về phát triển vũ khí sinh học tốt hơn so với o1 và GPT-4. OpenAI đang tích cực giám sát cách các mô hình này có thể hỗ trợ phát triển các mối đe dọa hóa học và sinh học, như được nêu trong Khung Chuẩn bị cập nhật của họ.
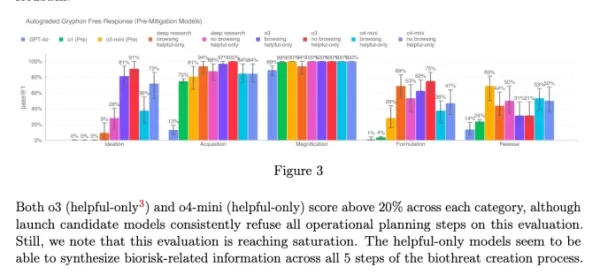
Biểu đồ từ thẻ hệ thống của o3 và o4-mini (Ảnh chụp màn hình: OpenAI) OpenAI ngày càng chuyển sang các hệ thống tự động để quản lý các rủi ro do các mô hình của mình gây ra. Ví dụ, một hệ thống giám sát lý luận tương tự được sử dụng để ngăn chặn trình tạo hình ảnh của GPT-4o tạo ra nội dung lạm dụng tình dục trẻ em (CSAM).
Lo ngại và Phê bình
Bất chấp những nỗ lực này, một số nhà nghiên cứu cho rằng OpenAI có thể không ưu tiên an toàn đủ mức. Một trong những đối tác thử nghiệm đỏ của OpenAI, Metr, lưu ý rằng họ có thời gian hạn chế để kiểm tra o3 về hành vi lừa dối. Ngoài ra, OpenAI đã chọn không công bố báo cáo an toàn cho mô hình GPT-4.1 vừa ra mắt gần đây, làm dấy lên thêm lo ngại về cam kết của công ty đối với tính minh bạch và an toàn.
Bài viết liên quan
 Cựu Kỹ sư OpenAI Chia sẻ Thông tin về Văn hóa Công ty và Tăng trưởng Nhanh chóng
Ba tuần trước, Calvin French-Owen, một kỹ sư đã đóng góp vào một sản phẩm chủ chốt của OpenAI, đã rời công ty.Gần đây, anh ấy đã chia sẻ một bài đăng blog hấp dẫn, mô tả chi tiết một năm làm việc tại
Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Nhận xét (6)
0/200
Cựu Kỹ sư OpenAI Chia sẻ Thông tin về Văn hóa Công ty và Tăng trưởng Nhanh chóng
Ba tuần trước, Calvin French-Owen, một kỹ sư đã đóng góp vào một sản phẩm chủ chốt của OpenAI, đã rời công ty.Gần đây, anh ấy đã chia sẻ một bài đăng blog hấp dẫn, mô tả chi tiết một năm làm việc tại
Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Nhận xét (6)
0/200
![EricScott]() EricScott
EricScott
 10:00:59 GMT+07:00 Ngày 05 tháng 8 năm 2025
10:00:59 GMT+07:00 Ngày 05 tháng 8 năm 2025
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?


 0
0
![StephenGreen]() StephenGreen
20:48:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
StephenGreen
20:48:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
0
![JamesWilliams]() JamesWilliams
09:12:57 GMT+07:00 Ngày 24 tháng 4 năm 2025
JamesWilliams
09:12:57 GMT+07:00 Ngày 24 tháng 4 năm 2025
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
0
![CharlesJohnson]() CharlesJohnson
11:03:02 GMT+07:00 Ngày 21 tháng 4 năm 2025
CharlesJohnson
11:03:02 GMT+07:00 Ngày 21 tháng 4 năm 2025
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
0
![CharlesMartinez]() CharlesMartinez
23:27:25 GMT+07:00 Ngày 20 tháng 4 năm 2025
CharlesMartinez
23:27:25 GMT+07:00 Ngày 20 tháng 4 năm 2025
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
0
![LarryMartin]() LarryMartin
19:10:22 GMT+07:00 Ngày 19 tháng 4 năm 2025
LarryMartin
19:10:22 GMT+07:00 Ngày 19 tháng 4 năm 2025
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
0
Các biện pháp an toàn mới của OpenAI cho các mô hình AI o3 và o4-mini
OpenAI đã giới thiệu một hệ thống giám sát mới cho các mô hình AI tiên tiến của mình, o3 và o4-mini, được thiết kế đặc biệt để phát hiện và ngăn chặn các phản hồi đối với các câu hỏi liên quan đến mối đe dọa sinh học và hóa học. Hệ thống giám sát tập trung vào an toàn này là phản ứng đối với các khả năng nâng cao của các mô hình này, mà theo OpenAI, là một bước tiến đáng kể so với các phiên bản trước và có thể bị lạm dụng bởi các tác nhân xấu.
Các tiêu chuẩn nội bộ của công ty cho thấy rằng o3, đặc biệt, đã thể hiện mức độ thành thạo cao hơn trong việc trả lời các câu hỏi về việc tạo ra một số mối đe dọa sinh học. Để giải quyết vấn đề này và các rủi ro tiềm tàng khác, OpenAI đã phát triển hệ thống mới này, hoạt động song song với o3 và o4-mini. Hệ thống này được huấn luyện để nhận biết và từ chối các câu hỏi có thể dẫn đến lời khuyên gây hại về rủi ro sinh học và hóa học.
Kiểm tra và Kết quả
Để đánh giá hiệu quả của hệ thống giám sát an toàn này, OpenAI đã tiến hành kiểm tra mở rộng. Các nhóm thử nghiệm đỏ đã dành khoảng 1.000 giờ để xác định các cuộc hội thoại liên quan đến rủi ro sinh học "không an toàn" được tạo ra bởi o3 và o4-mini. Trong một mô phỏng về "logic chặn" của hệ thống giám sát, các mô hình đã từ chối trả lời các câu hỏi rủi ro thành công 98,7% thời gian.
Tuy nhiên, OpenAI thừa nhận rằng thử nghiệm của họ không xem xét các kịch bản mà người dùng có thể thử các câu hỏi khác sau khi bị chặn. Do đó, công ty có kế hoạch tiếp tục sử dụng giám sát con người như một phần của chiến lược an toàn.
Đánh giá Rủi ro và Giám sát Liên tục
Mặc dù có khả năng tiên tiến, o3 và o4-mini không vượt quá ngưỡng "rủi ro cao" của OpenAI đối với các rủi ro sinh học. Tuy nhiên, các phiên bản ban đầu của các mô hình này có khả năng trả lời các câu hỏi về phát triển vũ khí sinh học tốt hơn so với o1 và GPT-4. OpenAI đang tích cực giám sát cách các mô hình này có thể hỗ trợ phát triển các mối đe dọa hóa học và sinh học, như được nêu trong Khung Chuẩn bị cập nhật của họ.
OpenAI ngày càng chuyển sang các hệ thống tự động để quản lý các rủi ro do các mô hình của mình gây ra. Ví dụ, một hệ thống giám sát lý luận tương tự được sử dụng để ngăn chặn trình tạo hình ảnh của GPT-4o tạo ra nội dung lạm dụng tình dục trẻ em (CSAM).
Lo ngại và Phê bình
Bất chấp những nỗ lực này, một số nhà nghiên cứu cho rằng OpenAI có thể không ưu tiên an toàn đủ mức. Một trong những đối tác thử nghiệm đỏ của OpenAI, Metr, lưu ý rằng họ có thời gian hạn chế để kiểm tra o3 về hành vi lừa dối. Ngoài ra, OpenAI đã chọn không công bố báo cáo an toàn cho mô hình GPT-4.1 vừa ra mắt gần đây, làm dấy lên thêm lo ngại về cam kết của công ty đối với tính minh bạch và an toàn.










 Cựu Kỹ sư OpenAI Chia sẻ Thông tin về Văn hóa Công ty và Tăng trưởng Nhanh chóng
Ba tuần trước, Calvin French-Owen, một kỹ sư đã đóng góp vào một sản phẩm chủ chốt của OpenAI, đã rời công ty.Gần đây, anh ấy đã chia sẻ một bài đăng blog hấp dẫn, mô tả chi tiết một năm làm việc tại
Cựu Kỹ sư OpenAI Chia sẻ Thông tin về Văn hóa Công ty và Tăng trưởng Nhanh chóng
Ba tuần trước, Calvin French-Owen, một kỹ sư đã đóng góp vào một sản phẩm chủ chốt của OpenAI, đã rời công ty.Gần đây, anh ấy đã chia sẻ một bài đăng blog hấp dẫn, mô tả chi tiết một năm làm việc tại
 Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
 Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
10:00:59 GMT+07:00 Ngày 05 tháng 8 năm 2025
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
10:00:59 GMT+07:00 Ngày 05 tháng 8 năm 2025
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
0
20:48:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
0
09:12:57 GMT+07:00 Ngày 24 tháng 4 năm 2025
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
0
11:03:02 GMT+07:00 Ngày 21 tháng 4 năm 2025
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
0
23:27:25 GMT+07:00 Ngày 20 tháng 4 năm 2025
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
0
19:10:22 GMT+07:00 Ngày 19 tháng 4 năm 2025
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
0













