Модели в стиле ChatGPT сейчас обучаются выявлять основную точку зрения новостной статьи — даже если эта точка зрения скрыта за цитатами, формулировками или фасадом (иногда неискренней) нейтральности. Разбивая статьи на сегменты, такие как заголовки, вступления и цитаты, новая система учится выявлять предвзятость даже в длинных профессиональных журналистских материалах.
Способность понять истинную позицию автора или оратора — известная в академической литературе как «обнаружение позиции»— решает одну из самых сложных задач в интерпретации языка: распознавание намерения из контента, который может быть специально разработан, чтобы скрыть или завуалировать его.
От «Скромного предложения» Джонатана Свифта до недавних политических выступлений, в которых актеры заимствуют риторику своих идеологических оппонентов, поверхностное содержание высказывания больше не является надежным показателем его намерения. Распространение иронии, троллинга, дезинформации и стратегической двусмысленности сделало все более сложным определить, какую сторону действительно поддерживает текст — или поддерживает ли он вообще какую-либо сторону.
Часто то, что остается несказанным, имеет такое же значение, как и то, что сказано, и само решение осветить ту или иную тему может сигнализировать о позиции автора.
Это делает автоматическое определение позиции особенно сложной задачей, поскольку эффективная система должна делать больше, чем просто маркировать отдельные предложения как «поддерживающие» или «противоположные». Вместо этого она должна ориентироваться в многослойном значении, взвешивая тонкие намеки в контексте общего смысла и направления статьи — задача, которая становится еще более сложной в длинных журналистских материалах, где тон может меняться, а мнения редко выражаются прямо.
Агенты перемен
Чтобы решить эти проблемы, исследователи из Южной Кореи разработали новую систему под названием JOA-ICL (Journalism-guided Agentic In-Context Learning) для определения позиции в длинных новостных статьях.
Основная идея JoA-ICL заключается в том, что позиция на уровне статьи выводится путем агрегирования прогнозов на уровне сегментов, произведенных отдельным языковым модельным агентом. Источник: https://arxiv.org/pdf/2507.11049
Вместо того чтобы оценивать статью в целом, JOA-ICL разбивает ее на структурные компоненты — заголовок, вступление, цитаты и заключение — и назначает меньшую модель для маркировки каждого сегмента. Затем эти локализованные прогнозы передаются в более крупную модель, которая использует их для определения общей позиции статьи.
Метод был протестирован на недавно скомпилированном корейском наборе данных, содержащем 2000 новостных статей с аннотациями как на уровне статьи, так и на уровне сегмента. Каждая статья была помечена с помощью ввода данных от эксперта в области журналистики, отражающего распределение позиции по всей структуре профессионального новостного текста.
Согласно статье, JOA-ICL превосходит как базовые модели, основанные на подсказках, так и модели с точной настройкой, демонстрируя особую силу в обнаружении позиций поддержки — категории, которую аналогичные модели часто упускают. Этот подход также оказался эффективным при применении к немецкому набору данных в сопоставимых условиях, что позволяет предположить, что его принципы могут быть универсальными для разных языков.
Авторы заявляют:
«Эксперименты показывают, что JOA-ICL превосходит существующие методы обнаружения позиции, подчеркивая преимущества агентства на уровне сегментов в определении общей позиции длинных новостных статей».
Новая статья озаглавлена «Журналистское контекстное обучение для обнаружения позиции в новостях » и подготовлена различными факультетами Сеульского университета Сунгсил, а также Высшей школой будущих стратегий KAIST.
Метод
Часть проблемы в обнаружении позиции с помощью искусственного интеллекта носит логистический характер и связана с тем, сколько информации система машинного обучения может обработать и соотнести одновременно, учитывая современные ограничения.
В новостных статьях часто избегают прямого выражения мнения, полагаясь вместо этого на неявную или предполагаемую позицию, которая сигнализируется через выбор таких элементов, как источники, которые цитируются, как сформулирована повествовательная часть и какие детали опущены.
Даже когда статья занимает четкую позицию, сигнал часто разбросан по всему тексту, а разные фрагменты указывают в разные стороны. Поскольку языковые модели (LM) по-прежнему сталкиваются с ограничениями из-за ограниченных контекстных окон, им сложно оценивать позицию так же, как в случае с более коротким контентом, таким как твиты или посты в социальных сетях, где связь между текстом и намерением более явная.
В результате стандартные подходы часто оказываются неэффективными при применении к полноформатной журналистике, где неоднозначность часто является особенностью, а не недостатком.
В статье говорится:
«Для решения этих проблем мы предлагаем иерархический подход к моделированию, который сначала определяет позицию на уровне более мелких единиц дискурса (например, абзацев или разделов), а затем интегрирует эти локальные прогнозы, чтобы определить общую позицию статьи.
Эта структура предназначена для сохранения локального контекста и улавливания разрозненных сигналов позиции при оценке того, как различные части новостной статьи влияют на ее общую позицию по вопросу».
С этой целью авторы скомпилировали новый набор данных под названием K-NEWS-STANCE, основанный на корейских новостях за период с июня 2022 года по июнь 2024 года. Статьи были сначала идентифицированы с помощью BigKinds, поддерживаемого правительством сервиса метаданных, управляемого Корейским фондом прессы, а полные тексты были получены с помощью API агрегатора Naver News. Окончательный набор данных включал 2000 статей из 31 издания, охватывающих 47 вопросов, имеющих национальное значение.
Каждая статья была аннотирована дважды: один раз для общей позиции по данному вопросу и еще раз для отдельных сегментов, в частности, заголовка, вступления, заключения и прямых цитат.
Аннотирование проводилось под руководством эксперта в области журналистики Джиёнга Хана, третьего автора статьи, который направлял процесс, используя установленные критерии из медиа-исследований, такие как выбор источников, лексическое фреймирование и шаблоны цитирования. В общей сложности было получено 19 650 меток позиции на уровне сегментов.
Чтобы гарантировать, что статьи содержали значимые сигналы о точке зрения, каждая из них сначала была классифицирована по жанру, и только те, которые были помечены как анализ или мнение — где более вероятно субъективное фреймирование — были использованы для аннотирования позиции.
Два обученных аннотатора маркировали все статьи и получили инструкции консультироваться со связанными статьями, когда позиция была неясна. Разногласия разрешались путем обсуждения и дополнительного рассмотрения.
Примеры записей из набора данных K-NEWS-STANCE, переведенные на английский язык. Показаны только заголовок, вступление и цитаты; полный текст опущен. Выделение обозначает метки позиции для цитат: синий цвет означает поддержку, а красный — противодействие. Для более четкого представления обратитесь к цитируемому источнику в формате PDF.
JoA-ICL
Вместо того чтобы рассматривать статью как единый блок текста, предлагаемая система делит ее на ключевые структурные части: заголовок, вступление, цитаты и заключение. Каждый сегмент назначается агенту языковой модели, который маркирует его как поддерживающий, оппозиционный или нейтральный.
Затем эти локальные прогнозы передаются второму агенту, который определяет общую позицию статьи. Два агента координируются контроллером, который готовит подсказки и собирает результаты.
Таким образом, JoA-ICL адаптирует контекстное обучение, при котором модель учится на примерах из подсказки, к структуре профессионального новостного письма, используя подсказки с учетом сегментов вместо одного общего ввода.
(Обращаем ваше внимание, что большинство примеров и иллюстраций в статье являются объемными и их сложно воспроизвести в онлайн-версии статьи. Поэтому мы рекомендуем читателям обратиться к исходному источнику в формате PDF).
Данные и тесты
При тестировании исследователи использовали макро F1 и точность для оценки производительности, усредняя результаты за десять прогонов со случайными семенами от 42 до 51 и сообщая стандартную ошибку. Данные обучения использовались для тонкой настройки базовых моделей и агентов на уровне сегментов, с выбором небольшого количества образцов посредством поиска по схожести с использованием KLUE-RoBERTa-large.
Тесты проводились на трех графических процессорах RTX A6000 (каждый с 48 ГБ VRAM) с использованием Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0 и vLLM 0.8.5.
GPT-4o-mini, Claude 3 Haiku и Gemini 2 Flash использовались через API с температурой 1,0 и максимальным количеством токенов, установленным на 1000 для подсказок цепочки мыслей и 100 для других.
Для полной настройки Exaone-3.5-2.4B использовался оптимизатор AdamW с коэффициентом обучения 5e-5, затуханием веса 0,01, 100 шагами прогрева и обучением в течение 10 эпох с размером партии 6.
В качестве базовых показателей авторы использовали RoBERTa, настроенную для определения позиции на уровне статьи; Chain-of-Thought (CoT) Embeddings, альтернативную настройку RoBERTa для заданной задачи; LKI-BART, модель кодировщика-декодировщика, которая включает контекстуальные знания из большой языковой модели, подсказывая ей как входной текст, так и предполагаемые метки позиции; и PT-HCL, метод, который использует контрастивное обучение для отделения общих характеристик от характеристик, специфичных для целевого вопроса:
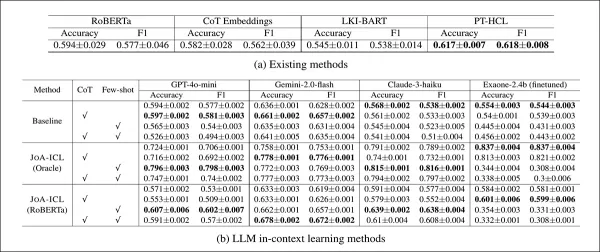
Производительность каждой модели на тестовом наборе K-NEWS-STANCE для общего прогнозирования позиции. Результаты показаны в виде макро-F1 и точности, причем наивысший балл в каждой группе выделен жирным шрифтом.
JOA-ICL продемонстрировал лучшую общую производительность как по точности, так и по макро-F1, что является преимуществом, наблюдаемым во всех трех протестированных моделях: GPT-4o-mini, Claude 3 Haiku и Gemini 2 Flash.
Метод на основе сегментов стабильно превосходил все другие подходы, причем авторы отмечают его особую сильную сторону в обнаружении поддерживающих позиций — распространенную слабость в аналогичных моделях.
Базовые модели в целом показали худшие результаты. Варианты RoBERTa и Chain-of-Thought испытывали трудности с нюансированными случаями, в то время как PT-HCL и LKI-BART показали лучшие результаты, но все же уступали JOA-ICL в большинстве категорий. Наиболее точный единичный результат был получен JOA-ICL (Claude) с макро F1 64,8% и точностью 66,1%.
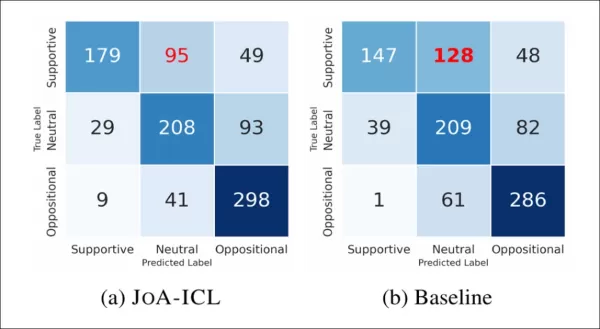
На изображении ниже показано, как часто модели правильно или неправильно идентифицировали каждую метку:
Матрицы путаницы, сравнивающие базовую модель и JoA-ICL, показывают, что оба метода испытывают наибольшие трудности с обнаружением «поддерживающих» позиций.
JoA-ICL в целом показал лучшие результаты, чем базовый уровень, правильно идентифицировав больше меток в каждой категории. Однако обе модели испытывали наибольшие трудности с поддерживающими статьями, а базовый уровень неправильно классифицировал почти половину из них, часто маркируя их как нейтральные.
JoA-ICL допустил меньше ошибок, но следовал той же схеме, что подтверждает, что «позитивные» позиции сложнее обнаружить для моделей.
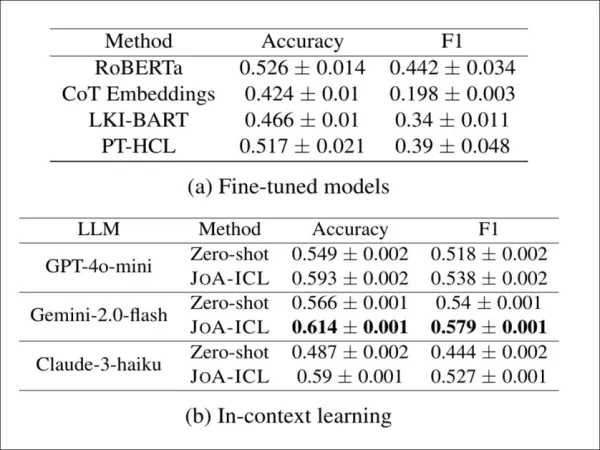
Чтобы проверить, работает ли JoA-ICL за пределами корейского языка, авторы применили его к CheeSE, немецкому набору данных для обнаружения позиции на уровне статей. Поскольку CheeSE не имеет меток на уровне сегментов, исследователи использовали дистанционный надзор, присваивая каждому сегменту ту же метку позиции, что и всей статье.
Результаты определения позиции на немецкоязычном наборе данных CheeSE. JoA-ICL последовательно улучшает результаты по сравнению с нулевым подсказыванием во всех трех LLM и превосходит точно настроенные базовые показатели, причем Gemini-2.0-flash демонстрирует самые высокие общие показатели.
Даже в этих «шумных» условиях JoA-ICL превосходил как точно настроенные модели, так и подсказки zero-shot. Из трех протестированных базовых моделей Gemini-2.0-flash показал самые высокие результаты.
Заключение
Немногие задачи в машинном обучении являются столь же политически чувствительными, как прогнозирование позиции, однако к ним часто подходят с технической, механической точки зрения. Между тем, менее сложные вопросы в области генеративного ИИ, такие как создание видео и изображений, как правило, привлекают больше внимания и попадают в заголовки новостей.
Наиболее обнадеживающим аспектом нового корейского исследования является его вклад в анализ полноформатного контента, а не твитов и коротких постов в социальных сетях, влияние которых часто более мимолетно, чем влияние трактатов, эссе или других существенных работ.
Одним из заметных пробелов в этом исследовании — и в литературе по прогнозированию позиции в целом — является отсутствие учета гиперссылок, которые часто служат дополнительными ресурсами для читателей, желающих более глубоко изучить тему. Однако выбор таких URL-адресов может быть весьма субъективным и даже иметь политическую окраску.
При этом чем престижнее издание, тем меньше вероятность, что оно будет содержать ссылки, которые отвлекают читателей от его собственного домена. Это, наряду с различными видами использования и злоупотребления гиперссылками в целях SEO, делает их более сложными для количественной оценки, чем прямые цитаты, заголовки или другие элементы, которые могут сознательно или бессознательно формировать мнение читателя.
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
При нажатии на «Принять все файлы cookie» вы соглашаетесь на хранение файлов cookie на вашем устройстве для улучшения навигации по сайту, анализа использования сайта и поддержки наших маркетинговых усилий.Политика конфиденциальности Уведомление
При посещении любого веб-сайта он может хранить или получать информацию в вашем браузере, главным образом в виде файлов cookie. Эта информация может относиться к вам, вашим предпочтениям или вашему устройству и в основном используется для того, чтобы сайт работал так, как вы ожидаете. Эта информация обычно не идентифицирует вас напрямую, но может предоставить вам более персонализированный веб-опыт. Поскольку мы уважаем ваше право на конфиденциальность, вы можете отказаться от разрешения определенных типов файлов cookie. Нажмите на разные заголовки категорий, чтобы узнать больше и изменить наши параметры по умолчанию. Однако блокировка некоторых типов файлов cookie может повлиять на ваше восприятие сайта и предоставляемые нами услуги. Политика конфиденциальностиЗаявление
Управление предпочтениями
Строго необходимые файлы cookie
Всегда активен
Эти файлы cookie необходимы для работы веб-сайта и не могут быть отключены в наших системах. Обычно они устанавливаются только в ответ на ваши действия, которые являются запросом на предоставление услуг, например, настройка предпочтений конфиденциальности, вход в систему или заполнение форм. Вы можете настроить браузер на блокировку этих файлов cookie или оповещение о них, но тогда некоторые части сайта не будут работать. Эти файлы cookie не хранят никакой персональной информации, позволяющей идентифицировать вас.

















 Дом
Дом

 Claude 4.1 от Anthropic превосходит GPT-5 по результатам тестов на кодирование перед запуском GPT-5
В понедельник компания Anthropic представила усовершенствованную версию своей ведущей модели искусственного интеллекта, установив новый стандарт производительности в области программного обеспечения.
Claude 4.1 от Anthropic превосходит GPT-5 по результатам тестов на кодирование перед запуском GPT-5
В понедельник компания Anthropic представила усовершенствованную версию своей ведущей модели искусственного интеллекта, установив новый стандарт производительности в области программного обеспечения.
 Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
 10 инструментов
10 инструментов
 xix.ai
код
xix.ai
код

 Комментарии (0)
Комментарии (0)















 Claude 4.1 от Anthropic превосходит GPT-5 по результатам тестов на кодирование перед запуском GPT-5
В понедельник компания Anthropic представила усовершенствованную версию своей ведущей модели искусственного интеллекта, установив новый стандарт производительности в области программного обеспечения.
Claude 4.1 от Anthropic превосходит GPT-5 по результатам тестов на кодирование перед запуском GPT-5
В понедельник компания Anthropic представила усовершенствованную версию своей ведущей модели искусственного интеллекта, установив новый стандарт производительности в области программного обеспечения.
 Nvidia представила модель искусственного интеллекта Nemotron-Nano-9B-v2 с открытым исходным кодом и возможностью отключаемого рассуждения
Небольшие языковые модели набирают популярность. После дебюта модели искусственного зрения размером со смарт-часы от Liquid AI, созданной на базе технологий MIT, и предложения Google для смартфонов, N
Nvidia представила модель искусственного интеллекта Nemotron-Nano-9B-v2 с открытым исходным кодом и возможностью отключаемого рассуждения
Небольшие языковые модели набирают популярность. После дебюта модели искусственного зрения размером со смарт-часы от Liquid AI, созданной на базе технологий MIT, и предложения Google для смартфонов, N
 OpenAI сохранит данные ChatGPT по решению суда, генеральный директор Альтман предлагает "привилегию ИИ
Многие постоянные пользователи ChatGPT, в том числе и автор этой статьи, возможно, сталкивались с функцией "временного чата". Эта опция, предлагаемая популярным чатботом OpenAI, предназначена для авто
OpenAI сохранит данные ChatGPT по решению суда, генеральный директор Альтман предлагает "привилегию ИИ
Многие постоянные пользователи ChatGPT, в том числе и автор этой статьи, возможно, сталкивались с функцией "временного чата". Эта опция, предлагаемая популярным чатботом OpenAI, предназначена для авто



















