Modelle im Stil von ChatGPT werden derzeit darauf trainiert, die zugrunde liegende Perspektive eines Nachrichtenartikels aufzudecken – selbst wenn diese Sichtweise hinter Zitaten, Framing oder einer Fassade (manchmal unaufrichtiger) Neutralität verborgen ist. Durch die Aufteilung von Artikeln in Segmente wie Überschriften, Einleitungen und Zitate lernt ein neues System, selbst in langen professionellen Journalismusbeiträgen Voreingenommenheit zu erkennen.
Die Fähigkeit, die wahre Position eines Autors oder Redners zu erfassen – in der wissenschaftlichen Literatur als „Stance Detection”bekannt – befasst sich mit einer der komplexesten Herausforderungen der Sprachinterpretation: der Unterscheidung von Absichten anhand von Inhalten, die möglicherweise bewusst darauf ausgelegt sind, diese zu verbergen oder zu verschleiern.
Von Jonathan Swifts „A Modest Proposal“ bis hin zu aktuellen politischen Auftritten, bei denen Schauspieler die Rhetorik ihrer ideologischen Gegner übernehmen, ist die Oberfläche einer Aussage kein verlässlicher Indikator mehr für ihre Absicht. Durch das Aufkommen von Ironie, Trolling, Desinformation und strategischer Mehrdeutigkeit ist es immer schwieriger geworden, zu bestimmen, welche Seite ein Text wirklich unterstützt – oder ob er überhaupt eine Seite unterstützt.
Oft hat das, was ungesagt bleibt, ebenso viel Bedeutung wie das, was ausgesprochen wird, und allein die Entscheidung, ein Thema zu behandeln, kann die Position des Autors signalisieren.
Dies macht die automatisierte Erkennung von Standpunkten besonders schwierig, da ein effektives System mehr leisten muss, als einzelne Sätze als „befürwortend” oder „ablehnend” zu kennzeichnen. Stattdessen muss es sich durch mehrere Bedeutungsebenen navigieren und subtile Hinweise gegen den Gesamtfluss und die Richtung des Artikels abwägen – eine Aufgabe, die im Langformjournalismus, wo sich der Ton ändern kann und Meinungen selten direkt geäußert werden, noch schwieriger ist.
Agenten für Veränderung
Um diesen Herausforderungen zu begegnen, haben Forscher in Südkorea ein neues System namens JOA-ICL (Journalism-guided Agentic In-Context Learning) entwickelt, um die Haltung von Langform-Nachrichtenartikeln zu erkennen.
Die Kernidee hinter JoA-ICL besteht darin, dass die Haltung auf Artikelebene durch die Aggregation von Segmentvorhersagen abgeleitet wird, die von einem separaten Sprachmodell-Agenten erstellt werden. Quelle: https://arxiv.org/pdf/2507.11049
Anstatt einen Artikel als Ganzes zu bewerten, zerlegt JOA-ICL ihn in strukturelle Komponenten – Überschrift, Einleitung, Zitate und Schlussfolgerung – und weist jedem Segment ein kleineres Modell zu, um es zu kennzeichnen. Diese lokalisierten Vorhersagen werden dann an ein größeres Modell weitergeleitet, das sie verwendet, um die allgemeine Haltung des Artikels zu bestimmen.
Die Methode wurde an einem neu zusammengestellten koreanischen Datensatz getestet, der 2.000 Nachrichtenartikel enthält, die sowohl auf Artikel- als auch auf Segmentebene mit einer Haltung versehen sind. Jeder Artikel wurde mit Hilfe eines Journalismus-Experten gekennzeichnet, der widerspiegelte, wie sich die Haltung in der Struktur professioneller Nachrichtenartikel verteilt.
Laut der Veröffentlichung übertrifft JOA-ICL sowohl prompting-basierte als auch fein abgestimmte Baselines und zeigt besondere Stärken bei der Erkennung unterstützender Standpunkte – eine Kategorie, die ähnliche Modelle oft übersehen. Der Ansatz erwies sich auch bei der Anwendung auf einen deutschen Datensatz unter vergleichbaren Bedingungen als wirksam, was darauf hindeutet, dass seine Prinzipien sprachübergreifend robust sind.
Die Autoren stellen fest:
„Experimente zeigen, dass JOA-ICL bestehende Methoden zur Erkennung von Standpunkten übertrifft und die Vorteile der Segmentebene bei der Erfassung der Gesamtposition von Langform-Nachrichtenartikeln hervorhebt.“
Die neue Veröffentlichung trägt den Titel „Journalism-Guided Agentic In-Context Learning for News Stance Detection“ und stammt von verschiedenen Fakultäten der Soongsil-Universität in Seoul sowie der KAIST Graduate School of Future Strategy.
Methode
Ein Teil der Herausforderung bei der KI-gestützten Standpunkterkennung ist logistischer Natur und hängt damit zusammen, wie viele Informationen ein maschinelles Lernsystem angesichts der aktuellen Grenzen des Stands der Technik auf einmal verarbeiten und korrelieren kann.
Nachrichtenartikel vermeiden oft direkte Meinungsäußerungen und verlassen sich stattdessen auf eine implizite oder vermutete Haltung, die durch Entscheidungen wie die Auswahl der zitierten Quellen, die Art und Weise, wie die Erzählung gestaltet ist, und die Auslassung bestimmter Details signalisiert wird.
Selbst wenn ein Artikel eine klare Position vertritt, ist das Signal oft über den Text verstreut, wobei verschiedene Abschnitte in unterschiedliche Richtungen weisen. Da Sprachmodelle (LMs) aufgrund begrenzter Kontextfenster immer noch Einschränkungen unterliegen, ist es für sie schwierig, die Haltung auf die gleiche Weise zu bewerten wie bei kürzeren Inhalten – wie Tweets oder Social-Media-Beiträgen –, bei denen die Beziehung zwischen Text und Absicht expliziter ist.
Infolgedessen sind Standardansätze oft unzureichend, wenn sie auf journalistische Texte in voller Länge angewendet werden, bei denen Mehrdeutigkeit oft ein Merkmal und kein Mangel ist.
In dem Artikel heißt es:
„Um diesen Herausforderungen zu begegnen, schlagen wir einen hierarchischen Modellierungsansatz vor, der zunächst die Haltung auf der Ebene kleinerer Diskurseinheiten (z. B. Absätze oder Abschnitte) ableitet und anschließend diese lokalen Vorhersagen integriert, um die Gesamthaltung des Artikels zu bestimmen.
Dieser Rahmen wurde entwickelt, um den lokalen Kontext beizubehalten und verstreute Standpunkt-Hinweise zu erfassen, um zu beurteilen, wie verschiedene Teile einer Nachricht zu ihrer Gesamtposition zu einem Thema beitragen.“
Zu diesem Zweck stellten die Autoren einen neuartigen Datensatz namens K-NEWS-STANCE zusammen, der aus der koreanischen Berichterstattung zwischen Juni 2022 und Juni 2024 stammt. Die Artikel wurden zunächst über BigKinds, einen von der Regierung unterstützten Metadatendienst der Korea Press Foundation, identifiziert, und die Volltexte wurden mithilfe der Naver News Aggregator API abgerufen. Der endgültige Datensatz umfasste 2.000 Artikel aus 31 Medien, die 47 national relevante Themen abdeckten.
Jeder Artikel wurde zweimal kommentiert: einmal für seine allgemeine Haltung zu einem bestimmten Thema und erneut für einzelne Abschnitte – insbesondere die Überschrift, die Einleitung, die Schlussfolgerung und direkte Zitate.
Die Kommentierung wurde von der Journalismusexpertin Jiyoung Han, der dritten Autorin der Arbeit, geleitet, die den Prozess anhand etablierter Hinweise aus der Medienwissenschaft, wie Quellenauswahl, lexikalische Rahmung und Zitiermuster, steuerte. Insgesamt wurden 19.650 Stellungnahmen auf Segmentebene erfasst.
Um sicherzustellen, dass die Artikel aussagekräftige Standpunktsignale enthielten, wurden sie zunächst nach Genre klassifiziert, und nur diejenigen, die als Analyse oder Meinung gekennzeichnet waren – wo subjektive Formulierungen wahrscheinlicher sind – wurden für die Stellungnahme-Annotation verwendet.
Zwei geschulte Annotatoren kennzeichneten alle Artikel und wurden angewiesen, bei unklarer Haltung verwandte Artikel zu konsultieren. Meinungsverschiedenheiten wurden durch Diskussion und zusätzliche Überprüfung gelöst.
Beispieleinträge aus dem K-NEWS-STANCE-Datensatz, übersetzt ins Englische. Es werden nur die Überschrift, der Vorspann und die Zitate angezeigt; der vollständige Text wird weggelassen. Die Hervorhebungen kennzeichnen Standpunktkennzeichnungen für Zitate, wobei Blau für Zustimmung und Rot für Ablehnung steht. Eine klarere Darstellung finden Sie in der zitierten PDF-Quelle.
JoA-ICL
Anstatt einen Artikel als einen einzigen Textblock zu behandeln, unterteilt das vorgeschlagene System ihn in wichtige strukturelle Teile: Überschrift, Einleitung, Zitate und Schlussfolgerung. Jeder Abschnitt wird einem Sprachmodell-Agenten zugewiesen, der ihn als unterstützend, ablehnend oder neutral kennzeichnet.
Diese lokalen Vorhersagen werden dann an einen zweiten Agenten weitergeleitet, der die allgemeine Haltung des Artikels bestimmt. Die beiden Agenten werden von einem Controller koordiniert, der Eingabeaufforderungen vorbereitet und Ergebnisse sammelt.
Auf diese Weise passt JoA-ICL das kontextbezogene Lernen – bei dem das Modell aus Beispielen in der Eingabeaufforderung lernt – an die Struktur professioneller Nachrichtenberichterstattung an, indem es segmentbezogene Eingabeaufforderungen anstelle einer einzigen generischen Eingabe verwendet.
(Bitte beachten Sie, dass die meisten Beispiele und Illustrationen in der Veröffentlichung sehr lang sind und in einem Online-Artikel nur schwer lesbar wiedergegeben werden können. Wir empfehlen daher den Lesern, die Originalquelle im PDF-Format zu konsultieren.
Daten und Tests
Bei den Tests verwendeten die Forscher Makro-F1 und Genauigkeit, um die Leistung zu bewerten, wobei sie die Ergebnisse aus zehn Durchläufen mit zufälligen Startwerten von 42 bis 51 mittelten und den Standardfehler angaben. Die Trainingsdaten wurden zur Feinabstimmung der Basismodelle und der Agenten auf Segmentebene verwendet, wobei wenige Beispiele durch eine Ähnlichkeitssuche mit KLUE-RoBERTa-large ausgewählt wurden.
Die Tests wurden auf drei RTX A6000-GPUs (jeweils mit 48 GB VRAM) unter Verwendung von Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0 und vLLM 0.8.5 durchgeführt.
GPT-4o-mini, Claude 3 Haiku und Gemini 2 Flash wurden über API verwendet, mit einer Temperatur von 1,0 und einer maximalen Tokenanzahl von 1000 für Chain-of-Thought-Prompts und 100 für andere.
Für die vollständige Feinabstimmung von Exaone-3.5-2.4B wurde der AdamW-Optimierer mit einer Lernrate von 5e-5, einem Gewichtsabfall von 0,01, 100 Aufwärmschritten und einem Training für 10 Epochen bei einer Stapelgröße von 6 verwendet.
Als Baselines verwendeten die Autoren RoBERTa, feinabgestimmt für die Erkennung von Standpunkten auf Artikelebene; Chain-of-Thought (CoT) Embeddings, eine alternative Abstimmung von RoBERTa für die zugewiesene Aufgabe; LKI-BART, ein Encoder-Decoder-Modell, das Kontextwissen aus einem großen Sprachmodell einbezieht, indem es sowohl mit dem Eingabetext als auch mit den beabsichtigten Standpunkt-Labels gefüttert wird; und PT-HCL, eine Methode, die kontrastives Lernen verwendet, um allgemeine Merkmale von denen zu trennen, die für das Zielthema spezifisch sind:
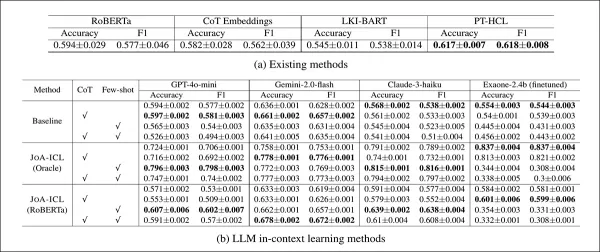
Leistung jedes Modells im K-NEWS-STANCE-Testsatz für die allgemeine Standpunktvorhersage. Die Ergebnisse werden als Makro-F1 und Genauigkeit angezeigt, wobei die höchste Punktzahl in jeder Gruppe fett gedruckt ist.
JOA-ICL erzielte sowohl bei der Genauigkeit als auch bei der Makro-F1 die beste Gesamtleistung, ein Vorteil, der bei allen drei getesteten Modell-Backbones zu beobachten war: GPT-4o-mini, Claude 3 Haiku und Gemini 2 Flash.
Die segmentbasierte Methode übertraf durchweg alle anderen Ansätze, wobei die Autoren eine besondere Stärke bei der Erkennung unterstützender Standpunkte feststellten – eine häufige Schwäche ähnlicher Modelle.
Die Basismodelle schnitten insgesamt schlechter ab. Die Varianten RoBERTa und Chain-of-Thought hatten Schwierigkeiten mit nuancierten Fällen, während PT-HCL und LKI-BART zwar besser abschnitten, aber in den meisten Kategorien dennoch hinter JOA-ICL zurückblieben. Das genaueste Einzelergebnis erzielte JOA-ICL (Claude) mit 64,8 % Makro-F1 und 66,1 % Genauigkeit.
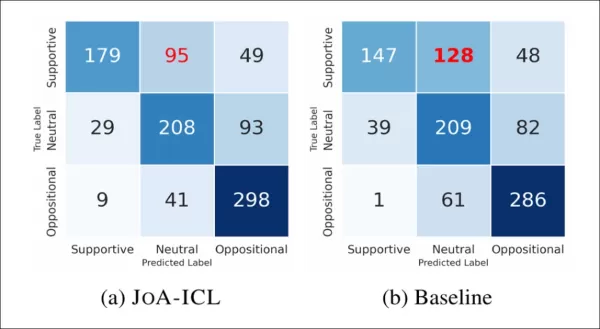
Die folgende Abbildung zeigt, wie oft die Modelle jedes Label richtig oder falsch identifiziert haben:
Vergleichende Verwechslungsmatrizen zwischen dem Basismodell und JoA-ICL zeigen, dass beide Methoden größte Schwierigkeiten bei der Erkennung „unterstützender” Standpunkte haben.
JoA-ICL schnitt insgesamt besser ab als die Baseline und identifizierte in jeder Kategorie mehr Labels korrekt. Beide Modelle hatten jedoch die größten Schwierigkeiten mit unterstützenden Artikeln, und die Baseline klassifizierte fast die Hälfte davon falsch und stufte sie oft als neutral ein.
JoA-ICL machte weniger Fehler, folgte jedoch dem gleichen Muster, was bestätigt, dass „positive” Standpunkte für Modelle schwieriger zu erkennen sind.
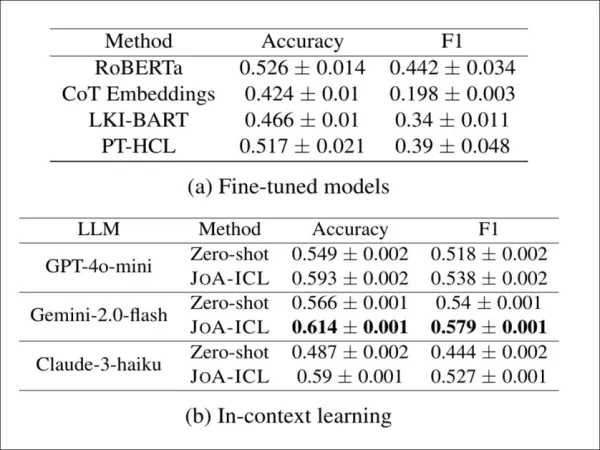
Um zu testen, ob JoA-ICL auch über die koreanische Sprache hinaus funktioniert, wandten die Autoren es auf CheeSE an, einen deutschen Datensatz zur Erkennung von Standpunkten auf Artikelebene. Da CheeSE keine Labels auf Segmentebene enthält, verwendeten die Forscher Distant Supervision und wiesen jedem Segment das gleiche Standpunkt-Label wie dem gesamten Artikel zu.
Ergebnisse der Standpunkterkennung im deutschsprachigen CheeSE-Datensatz. JoA-ICL verbessert sich gegenüber Zero-Shot-Prompting bei allen drei LLMs durchweg und übertrifft fein abgestimmte Baselines, wobei Gemini-2.0-flash die insgesamt stärkste Leistung erzielt.
Selbst unter diesen „verrauschten” Bedingungen übertraf JoA-ICL sowohl fein abgestimmte Modelle als auch Zero-Shot-Prompting. Von den drei getesteten Backbones lieferte Gemini-2.0-flash die besten Ergebnisse.
Fazit
Nur wenige Aufgaben im maschinellen Lernen sind so politisch sensibel wie die Vorhersage von Standpunkten, dennoch wird sie oft aus technischer, mechanischer Sicht angegangen. Unterdessen ziehen weniger komplexe Themen der generativen KI – wie die Erstellung von Videos und Bildern – tendenziell mehr Aufmerksamkeit und Schlagzeilen auf sich.
Der ermutigendste Aspekt der neuen koreanischen Forschung ist ihr Beitrag zur Analyse von Inhalten in voller Länge und nicht von Tweets und kurzen Social-Media-Beiträgen, deren Wirkung oft flüchtiger ist als die von Abhandlungen, Essays oder anderen substanziellen Werken.
Eine bemerkenswerte Lücke in dieser Studie – und in der Literatur zur Standpunktvorhersage im Allgemeinen – ist die mangelnde Berücksichtigung von Hyperlinks, die oft als optionale Ressourcen dienen, mit denen Leser ein Thema weiter vertiefen können. Die Auswahl solcher URLs kann jedoch sehr subjektiv und sogar politisch aufgeladen sein.
Je renommierter eine Publikation ist, desto unwahrscheinlicher ist es jedoch, dass sie Links enthält, die die Leser von ihrer eigenen Domain wegführen. Dies und verschiedene SEO-bezogene Verwendungen und Missbräuche von Hyperlinks machen es schwieriger, sie zu quantifizieren als explizite Zitate, Titel oder andere Elemente, die bewusst oder unbewusst die Meinung der Leser beeinflussen können.
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
Durch das Klicken auf „Alle Cookies akzeptieren“ stimmen Sie zu, dass Cookies auf Ihrem Gerät gespeichert werden, um die Seitennavigation zu verbessern, die Seitennutzung zu analysieren und unsere Marketingbemühungen zu unterstützen.Datenschutzerklärung Hinweis
Beim Besuch einer Website kann diese Informationen in Ihrem Browser speichern oder abrufen, hauptsächlich in Form von Cookies. Diese Informationen können sich auf Sie, Ihre Präferenzen oder Ihr Gerät beziehen und dienen hauptsächlich dazu, dass die Website so funktioniert, wie Sie es erwarten. Die Informationen identifizieren Sie in der Regel nicht direkt, können Ihnen aber ein personalisierteres Web-Erlebnis bieten. Da wir Ihr Recht auf Privatsphäre respektieren, können Sie wählen, dass Sie bestimmte Arten von Cookies nicht zulassen. Klicken Sie auf die verschiedenen Kategorietitel, um mehr zu erfahren und unsere Standardeinstellungen zu ändern. Das Blockieren bestimmter Arten von Cookies kann jedoch Ihre Erfahrung auf der Website und die von uns angebotenen Dienste beeinträchtigen. DatenschutzerklärungErklärung
Einstellungen verwalten
Unbedingt erforderliche Cookies
Immer aktiv
Diese Cookies sind für die Funktionalität der Website erforderlich und können in unseren Systemen nicht deaktiviert werden. Sie werden normalerweise nur in Reaktion auf Ihre Aktionen gesetzt, die einer Dienstanfrage entsprechen, z. B. das Einstellen Ihrer Datenschutzpräferenzen, das Anmelden oder das Ausfüllen von Formularen. Sie können Ihren Browser so einstellen, dass diese Cookies blockiert oder Sie darüber benachrichtigt werden, aber einige Teile der Website werden dann nicht mehr funktionieren. Diese Cookies speichern keine personenbezogenen Daten.

















 Heim
Heim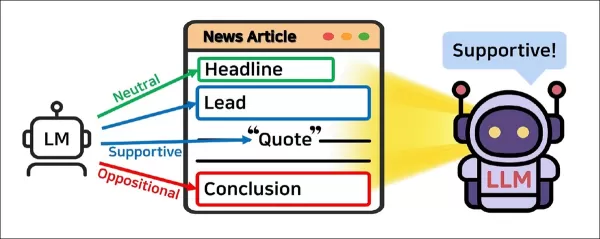

 Anthropics Claude 4.1 übertrifft GPT-5 bei Coding-Benchmarks vor dessen Markteinführung
Anthropic hat am Montag eine verbesserte Version seines führenden KI-Modells vorgestellt und damit einen neuen Maßstab für die Leistung bei Softwareentwicklungsaufgaben gesetzt. Mit dieser Einführung
Anthropics Claude 4.1 übertrifft GPT-5 bei Coding-Benchmarks vor dessen Markteinführung
Anthropic hat am Montag eine verbesserte Version seines führenden KI-Modells vorgestellt und damit einen neuen Maßstab für die Leistung bei Softwareentwicklungsaufgaben gesetzt. Mit dieser Einführung
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
xix.ai
Comic-Erstellung

 Kommentare (0)
Kommentare (0)















 Anthropics Claude 4.1 übertrifft GPT-5 bei Coding-Benchmarks vor dessen Markteinführung
Anthropic hat am Montag eine verbesserte Version seines führenden KI-Modells vorgestellt und damit einen neuen Maßstab für die Leistung bei Softwareentwicklungsaufgaben gesetzt. Mit dieser Einführung
Anthropics Claude 4.1 übertrifft GPT-5 bei Coding-Benchmarks vor dessen Markteinführung
Anthropic hat am Montag eine verbesserte Version seines führenden KI-Modells vorgestellt und damit einen neuen Maßstab für die Leistung bei Softwareentwicklungsaufgaben gesetzt. Mit dieser Einführung
 Nvidia stellt Open-Source-KI-Modell Nemotron-Nano-9B-v2 mit umschaltbarem Denkvermögen vor
Kleine Sprachmodelle sorgen für Aufsehen. Nach der Vorstellung des Smartwatch-großen Bildverarbeitungsmodells von Liquid AI, einem Spin-off des MIT, und des Smartphone-fähigen Modells von Google betri
Nvidia stellt Open-Source-KI-Modell Nemotron-Nano-9B-v2 mit umschaltbarem Denkvermögen vor
Kleine Sprachmodelle sorgen für Aufsehen. Nach der Vorstellung des Smartwatch-großen Bildverarbeitungsmodells von Liquid AI, einem Spin-off des MIT, und des Smartphone-fähigen Modells von Google betri
 OpenAI speichert ChatGPT-Daten per Gerichtsbeschluss, CEO Altman schlägt "KI-Privileg" vor
Viele regelmäßige ChatGPT-Nutzer, darunter auch der Autor dieses Artikels, haben vielleicht schon mit der Funktion "temporärer Chat" interagiert. Diese Option, die von OpenAIs beliebtem Chatbot angebo
OpenAI speichert ChatGPT-Daten per Gerichtsbeschluss, CEO Altman schlägt "KI-Privileg" vor
Viele regelmäßige ChatGPT-Nutzer, darunter auch der Autor dieses Artikels, haben vielleicht schon mit der Funktion "temporärer Chat" interagiert. Diese Option, die von OpenAIs beliebtem Chatbot angebo



















