Los modelos del tipo ChatGPT se están entrenando ahora para descubrir la perspectiva subyacente de un artículo periodístico, incluso cuando ese punto de vista se oculta tras citas, encuadres o una apariencia de neutralidad (a veces insincera). Al dividir los artículos en segmentos como titulares, entradillas y citas, un nuevo sistema aprende a identificar sesgos incluso en el periodismo profesional de formato largo.
La capacidad de comprender la verdadera posición de un escritor o orador, conocida en la literatura académica como detección de postura, aborda uno de los retos más complejos de la interpretación del lenguaje: discernir la intención a partir de un contenido que puede estar deliberadamente diseñado para ocultarla o difuminarla.
Desde La modesta propuesta de Jonathan Swift hasta las recientes actuaciones políticas en las que los actores toman prestada la retórica de sus oponentes ideológicos, la superficie de una declaración ya no es un indicador fiable de su intención. El auge de la ironía, el trolling, la desinformación y la ambigüedad estratégica ha hecho que sea cada vez más difícil determinar qué lado apoya realmente un texto, o si realmente toma partido.
A menudo, lo que no se dice tiene tanta importancia como lo que se dice, y la mera decisión de tratar un tema puede indicar la posición del autor.
Esto hace que la detección automática de posturas sea especialmente difícil, ya que un sistema eficaz debe hacer algo más que etiquetar frases individuales como «favorables» u «opuestas». En cambio, debe navegar por capas de significado, sopesando las sutiles pistas con respecto al flujo y la dirección generales del artículo, una tarea que se complica en el periodismo de formato largo, donde el tono puede cambiar y las opiniones rara vez se expresan de forma directa.
Agentes del cambio
Para abordar estos retos, investigadores de Corea del Sur han desarrollado un nuevo sistema llamado JOA-ICL (Journalism-guided Agentic In-Context Learning, aprendizaje contextual basado en el periodismo) para detectar la postura de los artículos periodísticos largos.
La idea central detrás de JoA-ICL es que la postura a nivel del artículo se deduce mediante la agregación de predicciones a nivel de segmento producidas por un agente de modelo de lenguaje independiente. Fuente: https://arxiv.org/pdf/2507.11049
En lugar de evaluar un artículo en su conjunto, JOA-ICL lo desglosa en componentes estructurales (titular, entradilla, citas y conclusión) y asigna un modelo más pequeño para etiquetar cada segmento. A continuación, estas predicciones localizadas se pasan a un modelo más grande, que las utiliza para determinar la postura general del artículo.
El método se probó en un conjunto de datos coreanos recién recopilado que contiene 2000 artículos de noticias anotados tanto a nivel de artículo como a nivel de segmento. Cada artículo fue etiquetado con la aportación de un experto en periodismo, lo que refleja cómo se distribuye la postura a lo largo de la estructura de la redacción profesional de noticias.
Según el artículo, JOA-ICL supera tanto a las bases de referencia basadas en indicaciones como a las ajustadas, mostrando una fortaleza particular en la detección de posturas de apoyo, una categoría que los modelos similares suelen pasar por alto. El enfoque también demostró su eficacia cuando se aplicó a un conjunto de datos alemán en condiciones comparables, lo que sugiere que sus principios pueden ser resistentes en todos los idiomas.
Los autores afirman:
«Los experimentos demuestran que JOA-ICL supera a los métodos de detección de postura existentes, lo que pone de relieve las ventajas de la agencia a nivel de segmento para captar la posición general de los artículos periodísticos de formato largo».
El nuevo artículo se titula Journalism-Guided Agentic In-Context Learning for News Stance Detection (Aprendizaje contextual basado en el periodismo para la detección de posturas en las noticias) y procede de varias facultades de la Universidad Soongsil de Seúl, así como de la Escuela de Posgrado de Estrategia Futura del KAIST.
Método
Parte del reto de la detección de posturas aumentada por IA es logístico, y está relacionado con la cantidad de información que un sistema de aprendizaje automático puede procesar y correlacionar a la vez, dadas las limitaciones actuales de la tecnología punta.
Los artículos periodísticos suelen evitar las expresiones directas de opinión, basándose en cambio en una postura implícita o supuesta que se transmite a través de elecciones como las fuentes que se citan, la forma en que se enmarca la narración y los detalles que se omiten.
Incluso cuando un artículo adopta una postura clara, la señal suele estar dispersa a lo largo del texto, con diferentes segmentos que apuntan en diferentes direcciones. Dado que los modelos de lenguaje (LM) siguen enfrentándose a limitaciones con ventanas de contexto restringidas, les resulta difícil evaluar la postura de la misma manera que lo harían con contenidos más breves, como tuits o publicaciones en redes sociales, donde la relación entre el texto y la intención es más explícita.
Como resultado, los enfoques estándar a menudo se quedan cortos cuando se aplican al periodismo de larga duración, donde la ambigüedad suele ser una característica, no un defecto.
El artículo afirma:
«Para abordar estos retos, proponemos un enfoque de modelización jerárquica que primero infiere la postura a nivel de unidades discursivas más pequeñas (por ejemplo, párrafos o secciones) y, posteriormente, integra estas predicciones locales para determinar la postura general del artículo.
Este marco está diseñado para conservar el contexto local y captar las señales de postura dispersas al evaluar cómo las diferentes partes de una noticia contribuyen a su posición general sobre un tema».
Con este fin, los autores recopilaron un novedoso conjunto de datos denominado K-NEWS-STANCE, extraído de la cobertura informativa coreana entre junio de 2022 y junio de 2024. Los artículos se identificaron primero a través de BigKinds, un servicio de metadatos respaldado por el gobierno y gestionado por la Fundación de Prensa de Corea, y los textos completos se recuperaron utilizando la API del agregador de noticias Naver. El conjunto de datos final incluyó 2000 artículos de 31 medios de comunicación, que cubrían 47 temas de relevancia nacional.
Cada artículo se anotó dos veces: una por su postura general sobre un tema determinado y otra por segmentos individuales, concretamente el titular, la entradilla, la conclusión y las citas directas.
La anotación fue dirigida por la experta en periodismo Jiyoung Han, tercera autora del artículo, quien guió el proceso utilizando pautas establecidas en los estudios sobre medios de comunicación, como la selección de fuentes, el encuadre léxico y los patrones de citas. En total, se obtuvieron 19 650 etiquetas de postura a nivel de segmento.
Para garantizar que los artículos contuvieran señales de puntos de vista significativos, cada uno se clasificó primero por género, y solo los etiquetados como análisis u opinión, en los que es más probable que haya un encuadre subjetivo, se utilizaron para la anotación de la postura.
Dos anotadores capacitados etiquetaron todos los artículos y se les indicó que consultaran artículos relacionados cuando la postura no estuviera clara. Las discrepancias se resolvieron mediante debate y revisión adicional.
Entradas de muestra del conjunto de datos K-NEWS-STANCE, traducidas al inglés. Solo se muestran el titular, el lead y las citas; se omite el texto completo. El resaltado indica las etiquetas de postura para las citas, con azul para las favorables y rojo para las contrarias. Consulte el PDF de la fuente citada para obtener una interpretación más clara.
JoA-ICL
En lugar de tratar un artículo como un único bloque de texto, el sistema propuesto lo divide en partes estructurales clave: titular, entradilla, citas y conclusión. Cada segmento se asigna a un agente de modelo lingüístico, que lo etiqueta como favorable, contrario o neutral.
Estas predicciones locales se pasan a un segundo agente que determina la postura general del artículo. Los dos agentes están coordinados por un controlador que prepara las indicaciones y recopila los resultados.
Así, JoA-ICL adapta el aprendizaje en contexto —en el que el modelo aprende a partir de ejemplos en la indicación— para alinearse con la estructura de la redacción profesional de noticias, utilizando indicaciones sensibles al segmento en lugar de una única entrada genérica.
(Tenga en cuenta que la mayoría de los ejemplos e ilustraciones del artículo son largos y difíciles de reproducir de forma legible en un artículo en línea. Por lo tanto, recomendamos a los lectores que consulten el PDF original).
Datos y pruebas
En las pruebas, los investigadores utilizaron macro F1 y precisión para evaluar el rendimiento, promediando los resultados de diez ejecuciones con semillas aleatorias de 42 a 51 e informando del error estándar. Los datos de entrenamiento se utilizaron para ajustar los modelos de referencia y los agentes a nivel de segmento, con muestras de pocos disparos seleccionadas mediante búsqueda de similitud utilizando KLUE-RoBERTa-large.
Las pruebas se realizaron en tres GPU RTX A6000 (cada una con 48 GB de VRAM), utilizando Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0 y vLLM 0.8.5.
Se utilizaron GPT-4o-mini, Claude 3 Haiku y Gemini 2 Flash a través de la API, con una temperatura de 1,0 y un máximo de tokens establecido en 1000 para las indicaciones de cadena de pensamiento, y 100 para las demás.
Para el ajuste completo de Exaone-3.5-2.4B, se utilizó el optimizador AdamW con una tasa de aprendizaje de 5e-5, una disminución de peso de 0,01, 100 pasos de calentamiento y un entrenamiento de 10 épocas con un tamaño de lote de 6.
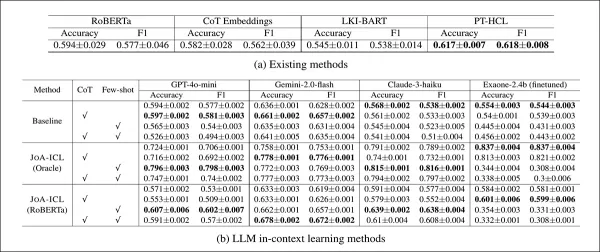
Como referencia, los autores utilizaron RoBERTa, ajustado para la detección de posturas a nivel de artículo; Chain-of-Thought (CoT) Embeddings, un ajuste alternativo de RoBERTa para la tarea asignada; LKI-BART, un modelo codificador-decodificador que incorpora el conocimiento contextual de un gran modelo lingüístico al solicitarle tanto el texto de entrada como las etiquetas de postura previstas; y PT-HCL, un método que utiliza el aprendizaje contrastivo para separar las características generales de las específicas del tema en cuestión:
Rendimiento de cada modelo en el conjunto de pruebas K-NEWS-STANCE para la predicción general de postura. Los resultados se muestran como macro F1 y precisión, con la puntuación más alta de cada grupo en negrita.
JOA-ICL logró el mejor rendimiento general tanto en precisión como en macro F1, una ventaja observada en las tres estructuras de modelos probadas: GPT-4o-mini, Claude 3 Haiku y Gemini 2 Flash.
El método basado en segmentos superó sistemáticamente a todos los demás enfoques, y los autores señalaron una fortaleza particular en la detección de posturas de apoyo, una debilidad común en modelos similares.
Los modelos de referencia obtuvieron peores resultados en general. Las variantes RoBERTa y Chain-of-Thought tuvieron dificultades con los casos más matizados, mientras que PT-HCL y LKI-BART obtuvieron mejores resultados, pero siguieron por detrás de JOA-ICL en la mayoría de las categorías. El resultado individual más preciso fue el de JOA-ICL (Claude), con un macro F1 del 64,8 % y una precisión del 66,1 %.
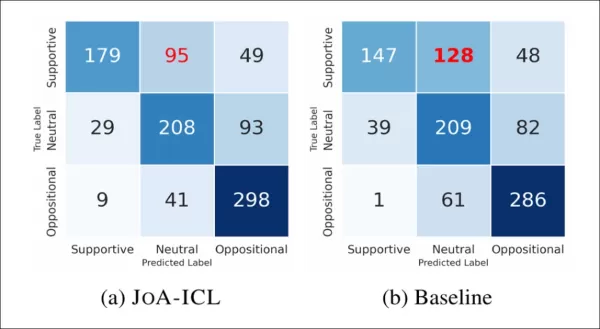
La imagen siguiente muestra la frecuencia con la que los modelos identificaron correctamente o incorrectamente cada etiqueta:
Matrices de confusión que comparan la referencia y JoA-ICL, que muestran que ambos métodos tienen más dificultades para detectar posturas «favorables».
JoA-ICL obtuvo mejores resultados en general que la línea de base, identificando correctamente más etiquetas en todas las categorías. Sin embargo, ambos modelos tuvieron más dificultades con los artículos favorables, y la línea de base clasificó erróneamente casi la mitad, etiquetándolos a menudo como neutrales.
JoA-ICL cometió menos errores, pero siguió el mismo patrón, lo que refuerza la idea de que las posturas «positivas» son más difíciles de detectar para los modelos.
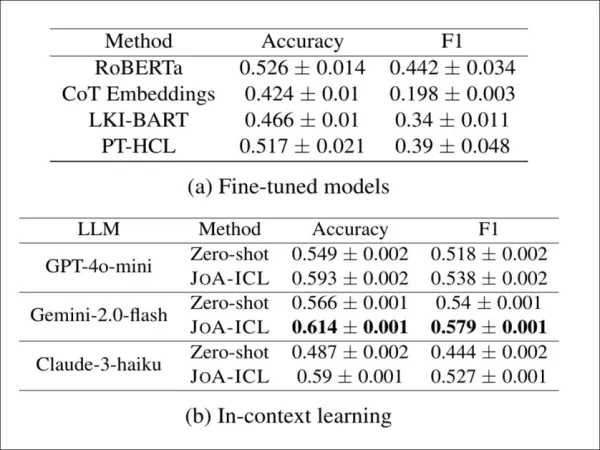
Para comprobar si JoA-ICL funciona más allá del idioma coreano, los autores lo aplicaron a CheeSE, un conjunto de datos alemán para la detección de posturas a nivel de artículo. Dado que CheeSE carece de etiquetas a nivel de segmento, los investigadores utilizaron la supervisión distante, asignando a cada segmento la misma etiqueta de postura que al artículo completo.
Resultados de la detección de posturas en el conjunto de datos CheeSE en alemán. JoA-ICL mejora constantemente con respecto a las indicaciones sin disparo en los tres LLM y supera a las bases de referencia ajustadas, con Gemini-2.0-flash obteniendo el mejor rendimiento general.
Incluso en estas condiciones «ruidosas», JoA-ICL superó tanto a los modelos ajustados como a la solicitud sin entrenamiento previo. De las tres estructuras probadas, Gemini-2.0-flash obtuvo los mejores resultados.
Conclusión
Pocas tareas en el aprendizaje automático son tan delicadas políticamente como la predicción de posturas, pero a menudo se aborda en términos técnicos y mecánicos. Mientras tanto, cuestiones menos complejas de la IA generativa, como la creación de vídeos e imágenes, tienden a atraer más atención y titulares.
El aspecto más alentador de la nueva investigación coreana es su contribución al análisis de contenidos completos, en lugar de tuits y publicaciones breves en redes sociales, cuyo impacto suele ser más efímero que el de un tratado, un ensayo u otra obra sustancial.
Una laguna notable en este estudio —y en la literatura sobre predicción de posturas en general— es la falta de consideración de los hipervínculos, que a menudo sirven como recursos opcionales para que los lectores exploren un tema más a fondo. Sin embargo, la selección de estas URL puede ser muy subjetiva e incluso tener connotaciones políticas.
Dicho esto, cuanto más prestigiosa es la publicación, menos probable es que incluya enlaces que alejen a los lectores de su propio dominio. Esto, junto con diversos usos y abusos de los hipervínculos relacionados con el SEO, hace que sean más difíciles de cuantificar que las citas explícitas, los títulos u otros elementos que pueden moldear consciente o inconscientemente la opinión del lector.
Publicado por primera vez el miércoles, 16 de julio de 2025.
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
Al hacer clic en "Aceptar todos los cookies", usted acepta el almacenamiento de cookies en su dispositivo para mejorar la navegación por el sitio, analizar el uso del sitio y ayudar en nuestros esfuerzos de marketing.Política de privacidad Aviso
Al visitar cualquier sitio web, este puede almacenar o recuperar información en su navegador, principalmente en forma de cookies. Esta información puede referirse a usted, sus preferencias o su dispositivo y se usa principalmente para que el sitio funcione como espera. Por lo general, la información no lo identifica directamente, pero puede brindarle una experiencia web más personalizada. Debido a que respetamos su derecho a la privacidad, puede optar por no permitir algunos tipos de cookies. Haga clic en los diferentes títulos de categoría para obtener más información y cambiar nuestros ajustes predeterminados. Sin embargo, bloquear algunos tipos de cookies puede afectar su experiencia en el sitio y los servicios que podemos ofrecer. Política de privacidadDeclaración
Gestionar preferencias
Cookie estrictamente necesario
Siempre activo
Estos cookies son necesarios para que el sitio web funcione y no pueden ser desactivados en nuestros sistemas. Por lo general, solo se establecen en respuesta a acciones que realice usted que equivalen a una solicitud de servicios, como configurar sus preferencias de privacidad, iniciar sesión o completar formularios. Puede configurar su navegador para bloquear estos cookies o alertarle sobre ellos, pero algunas partes del sitio no funcionarán luego. Estos cookies no almacenan ninguna información que permita identificar personalmente.

















 Hogar
Hogar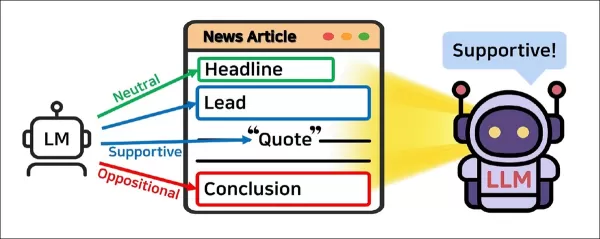

 Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
 Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
 10 herramientas
10 herramientas
 xix.ai
Texto a voz
xix.ai
Texto a voz

 comentario (0)
0/500
comentario (0)
0/500















 Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
 Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para
Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para
 OpenAI retendrá los datos de ChatGPT por orden judicial, el CEO Altman propone el "privilegio de la IA
Es posible que muchos usuarios habituales de ChatGPT, incluido el autor de este artículo, hayan interactuado con la función de "chat temporal". Esta opción, ofrecida por el popular chatbot de OpenAI,
OpenAI retendrá los datos de ChatGPT por orden judicial, el CEO Altman propone el "privilegio de la IA
Es posible que muchos usuarios habituales de ChatGPT, incluido el autor de este artículo, hayan interactuado con la función de "chat temporal". Esta opción, ofrecida por el popular chatbot de OpenAI,



















