
















 首頁
首頁人工智慧揭露新聞內容中的隱藏議程
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。
這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。
從喬納森·斯威夫特的《一個謙卑的建議》到當代政治表演中演員借用意識形態對手的修辭手法,陳述的表層已不再是意圖的可靠指標。反諷、網絡騷擾、虛假信息與戰略性模糊的盛行,使得判斷文本真正支持哪一方——甚至是否持立場——變得日益困難。
往往,未言明之處與明言內容同等重要,而選擇是否觸及某個主題的決定本身,便已透露出作者的立場。
這使得自動立場檢測尤為艱鉅,因為有效的系統不僅需標註單句為「支持」或「反對」,更須穿梭於多層次語義間,在文章整體脈絡與走向中權衡微妙線索——此任務在長篇報導中更顯困難,因其語氣可能轉折,觀點鮮少直白陳述。
變革的推動者
為解決這些難題,韓國研究人員開發了名為JOA-ICL(新聞導向的語境內學習)的新系統,用於檢測長篇新聞文章的立場。
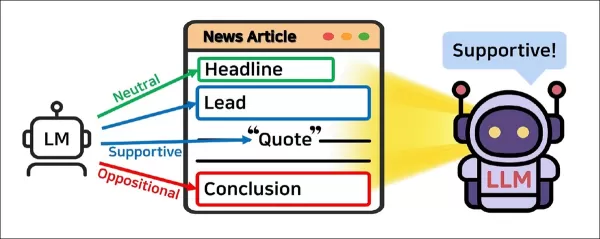
JOA-ICL的核心理念在於:透過整合獨立語言模型代理產生的分段預測結果,推導出文章層級的立場。來源:https://arxiv.org/pdf/2507.11049
JOA-ICL 並非整體評估文章,而是將其拆解為標題、導語、引述與結論等結構性元件,並指派小型模型為各段落標註立場。這些局部預測結果隨後傳遞至大型模型,用以判定文章整體立場。
該方法在全新編纂的韓語數據集上進行測試,該數據集包含2,000篇經文章層級與分段層級立場標註的新聞報導。每篇文章皆由新聞專業人士提供標註,反映立場在專業新聞寫作結構中的分布模式。
根據論文所述,JOA-ICL在檢測支持性立場(類似模型常忽略的類別)方面表現尤為突出,其效能超越基於提示與微調的基準模型。該方法在類似條件下應用於德語數據集時同樣有效,顯示其原理可能具備跨語言適應性。
作者指出:
「實驗證實JOA-ICL超越現有立場檢測方法,凸顯分段層級能動性在捕捉長篇新聞整體立場的優勢。」
這篇新論文題為《新聞導向的語境內能動性學習:新聞立場檢測》,由首爾崇實大學多個院系及韓國科學技術院未來戰略研究院共同發表。
方法
人工智慧輔助立場檢測的挑戰部分在於後勤層面,涉及在當前尖端技術限制下,機器學習系統能同時處理與關聯的資訊量。
新聞報導往往避免直接表達觀點,而是透過選擇引述哪些消息來源、如何構建敘事框架、以及省略哪些細節等手法,隱含 或暗示立場。
即使文章立場明確,相關訊號也常分散於文本各處,不同段落指向不同方向。由於語言模型(LM)仍受限於有限的上下文視窗,使其難以像處理推文或社群媒體貼文等短篇內容那樣評估立場——後者中文字與意圖的關聯性更為明確。
因此,標準方法應用於長篇新聞報導時往往力有未逮——在新聞報導中,模糊性常是特徵而非缺陷。
論文指出:
「為解決這些挑戰,我們提出分層建模方法:先在較小語篇單位(如段落或節)層級推斷立場,再整合這些局部預測以確定文章整體立場。
「此框架旨在保留局部語境,捕捉分散的立場線索,以評估新聞報導各部分如何共同形塑其對議題的整體立場。」
為此,作者彙編了名為K-NEWS-STANCE的創新資料集,素材取自2022年6月至2024年6月間的韓國新聞報導。 文章首先透過韓國新聞基金會營運的政府支援元數據服務BigKinds識別,再利用Naver新聞聚合API擷取全文。最終資料集涵蓋31家媒體機構的2,000篇文章,涉及47項全國性議題。
每篇報導均進行雙重標註:其一標示整體立場,其二標示各段落立場——具體涵蓋標題、導語、結論及 直接引述。
標註工作由新聞學專家韓智英(論文第三作者)主導,其運用媒體研究確立的指標(如消息來源選擇、詞彙框架與引述模式)指導流程,共獲得19,650個段落層級立場標籤。
為確保文章具備有效觀點信號,研究人員先按體裁分類,僅選用標記為分析或評論類(主觀框架較可能出現)的文章進行立場標註。
兩名受訓標註者為所有文章進行標註,並受指示在立場不明確時參照相關文章。分歧意見透過討論與追加審查解決。

K-NEWS-STANCE資料集樣本條目英譯版。僅呈現標題、導語及引述內容;正文全文省略。高亮標示為引述立場標籤,藍色代表支持立場,紅色代表反對立場。清晰呈現請參閱引用的PDF來源文件。
JoA-ICL
本系統不將文章視為單一文本塊,而是將其劃分為關鍵結構部分:標題、導語、引述及結論。每個段落由語言模型代理進行標註,判定其立場為支持性、反對性或中立性。
這些局部預測將傳遞至第二個代理程式,用以判定文章整體立場。兩者由控制器協調運作,負責準備提示語並彙整結果。
JoA-ICL 藉此將「上下文學習」(模型從提示中的範例學習)適應於專業新聞寫作結構,採用分段感知提示取代單一通用輸入。
(請注意,論文中多數範例與圖解篇幅冗長,難以在線上文章中清晰呈現。故建議讀者參閱原始PDF文件。)
數據與測試
測試中,研究人員採用宏觀F1值與準確度評估效能,以42至51個隨機種子進行十次運行取平均值,並報告標準誤差。訓練資料用於微調基線模型與分段級代理,少次樣本則透過KLUE-RoBERTa-large的相似性搜尋選取。
測試環境配置為三組RTX A6000 GPU(每組配備48GB VRAM),採用Python 3.9.19、PyTorch 2.5.1、Transformers 4.52.0及vLLM 0.8.5版本。
透過 API 調用 GPT-4o-mini、Claude 3 Haiku 及 Gemini 2 Flash,鏈式思考提示設定溫度值 1.0 與最大令牌數 1000,其餘提示則設定為 100。
針對 Exaone-3.5-2.4B 的完整微調,採用 AdamW 優化器,設定學習率 5e-5、權重衰減 0.01、預熱步驟 100,以批次大小 6 進行 10 個 epoch 的訓練。
基準模型採用經文章層級立場檢測微調的RoBERTa;另採用針對指定任務調整的RoBERTa變體——思考鏈嵌入(CoT Embeddings); LKI-BART(一種編碼器-解碼器模型,透過同時輸入文本與預期立場標籤,從大型語言模型中提取語境知識);以及PT-HCL(一種運用對比學習分離通用特徵與目標議題特徵的方法):
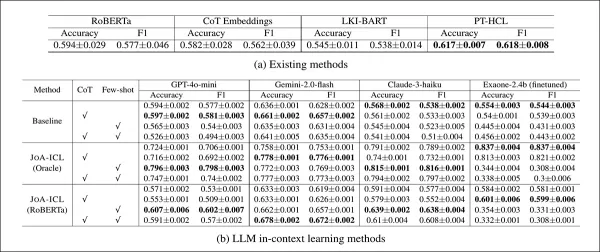
各模型於 K-NEWS-STANCE 測試集的整體立場預測表現。結果以宏觀 F1 分數與準確度呈現,各組最高分以粗體標示。
JOA-ICL 在準確度與宏觀 F1 值兩項指標均取得最佳整體表現,此優勢體現在所有三種測試模型骨架中:GPT-4o-mini、Claude 3 Haiku 及 Gemini 2 Flash。
基於分段的方法持續超越所有其他方案,作者特別指出其在偵測支持性立場方面具有優勢——此為類似模型常見的弱點。
基準模型整體表現較差。RoBERTa與Chain-of-Thought變體在細微案例中表現吃力,而PT-HCL與LKI-BART雖表現較佳,但在多數類別仍落後於JOA-ICL。最高單項準確度來自JOA-ICL(Claude),宏觀F1達64.8%,準確度達66.1%。
下圖呈現各模型對標籤的正誤判別頻率:
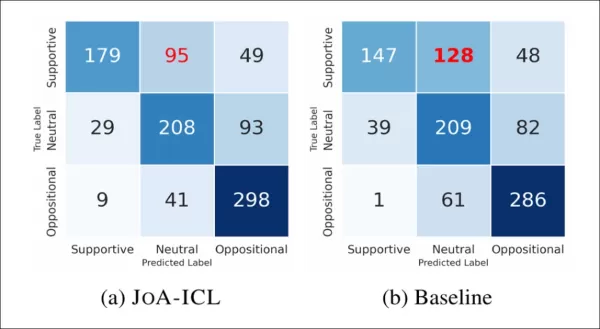
基準模型與JoA-ICL的混淆矩陣對比顯示,兩者在識別「支持性」立場時均面臨最大挑戰。
JoA-ICL整體表現優於基準模型,在所有類別中皆能正確識別更多標籤。然而兩者皆在支持性文章辨識上最為吃力,基準模型甚至將近半數文章誤判為中立立場。
JoA-ICL 雖錯誤較少但呈現相同模式,再次印證「正向」立場對模型而言更難偵測。
為驗證JoA-ICL能否突破韓語限制,作者將其應用於德語文章立場檢測數據集CheeSE。由於CheeSE缺乏分段標籤,研究人員採用遠程監督法,將每段文字標記為與全文相同的立場標籤。
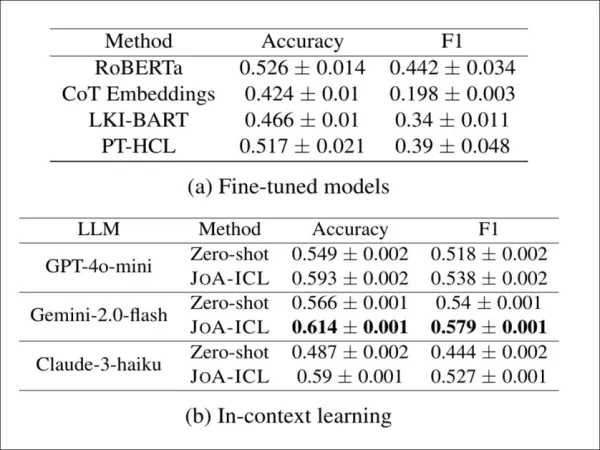
德語CheeSE數據集立場檢測結果顯示:JoA-ICL在三種大型語言模型上均持續超越零樣本提示法,且優於微調基準模型,其中Gemini-2.0-flash展現最強整體表現。
即使在這些「雜訊」條件下,JoA-ICL 仍優於微調模型與零次提示。在三種測試骨架模型中,Gemini-2.0-flash 展現最強勁的表現。
結論
在機器學習領域中,鮮少任務如立場預測般具有高度政治敏感性,然而此議題常被以技術性、機械化的方式處理。與此同時,生成式人工智慧中較不複雜的議題——例如影片與圖像創作——往往更受矚目並登上頭條。
這項韓國新研究最令人振奮之處,在於其聚焦於完整篇幅內容的分析——而非推文或短篇社群媒體貼文。後者相較於論文、專論等實質性著作,其影響力往往更為短暫。
此研究(乃至更廣泛的立場預測文獻)存在一項顯著缺失:未考量超連結的價值。這些連結常作為讀者深入探索主題的選用資源,然而連結選擇往往高度主觀,甚至帶有政治色彩。
話雖如此,出版物聲譽越高,越不傾向包含將讀者導離自身網域的連結。加上超連結在搜尋引擎優化(SEO)相關用途與濫用層面的複雜性,使其相較於明確引文、標題等可能有意識或無意識形塑讀者觀點的元素,更難進行量化分析。
初版發佈於2025年7月16日星期三
相關文章
 Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
OpenAI 將依據法院命令保留 ChatGPT 資料,執行長 Altman 提出「AI 特權」建議
許多常使用 ChatGPT 的使用者,包括本文作者,可能都曾與 「臨時聊天 」功能互動過。這個選項是由 OpenAI 受歡迎的聊天機器人所提供,目的是在會話關閉後立即自動清除會話中交換的所有資訊。此外,使用者也可以手動刪除網頁、桌面和行動應用程式側邊欄上過去的 ChatGPT 對話。您可以透過左鍵按一下、按住 Control 鍵按一下或長按所需的聊天內容來刪除對話。然而,本週 OpenAI 面臨使
相關專題推薦
寫作
Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
OpenAI 將依據法院命令保留 ChatGPT 資料,執行長 Altman 提出「AI 特權」建議
許多常使用 ChatGPT 的使用者,包括本文作者,可能都曾與 「臨時聊天 」功能互動過。這個選項是由 OpenAI 受歡迎的聊天機器人所提供,目的是在會話關閉後立即自動清除會話中交換的所有資訊。此外,使用者也可以手動刪除網頁、桌面和行動應用程式側邊欄上過去的 ChatGPT 對話。您可以透過左鍵按一下、按住 Control 鍵按一下或長按所需的聊天內容來刪除對話。然而,本週 OpenAI 面臨使
相關專題推薦
寫作
 最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。
這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。
從喬納森·斯威夫特的《一個謙卑的建議》到當代政治表演中演員借用意識形態對手的修辭手法,陳述的表層已不再是意圖的可靠指標。反諷、網絡騷擾、虛假信息與戰略性模糊的盛行,使得判斷文本真正支持哪一方——甚至是否持立場——變得日益困難。
往往,未言明之處與明言內容同等重要,而選擇是否觸及某個主題的決定本身,便已透露出作者的立場。
這使得自動立場檢測尤為艱鉅,因為有效的系統不僅需標註單句為「支持」或「反對」,更須穿梭於多層次語義間,在文章整體脈絡與走向中權衡微妙線索——此任務在長篇報導中更顯困難,因其語氣可能轉折,觀點鮮少直白陳述。
變革的推動者
為解決這些難題,韓國研究人員開發了名為JOA-ICL(新聞導向的語境內學習)的新系統,用於檢測長篇新聞文章的立場。

JOA-ICL的核心理念在於:透過整合獨立語言模型代理產生的分段預測結果,推導出文章層級的立場。來源:https://arxiv.org/pdf/2507.11049
JOA-ICL 並非整體評估文章,而是將其拆解為標題、導語、引述與結論等結構性元件,並指派小型模型為各段落標註立場。這些局部預測結果隨後傳遞至大型模型,用以判定文章整體立場。
該方法在全新編纂的韓語數據集上進行測試,該數據集包含2,000篇經文章層級與分段層級立場標註的新聞報導。每篇文章皆由新聞專業人士提供標註,反映立場在專業新聞寫作結構中的分布模式。
根據論文所述,JOA-ICL在檢測支持性立場(類似模型常忽略的類別)方面表現尤為突出,其效能超越基於提示與微調的基準模型。該方法在類似條件下應用於德語數據集時同樣有效,顯示其原理可能具備跨語言適應性。
作者指出:
「實驗證實JOA-ICL超越現有立場檢測方法,凸顯分段層級能動性在捕捉長篇新聞整體立場的優勢。」
這篇新論文題為《新聞導向的語境內能動性學習:新聞立場檢測》,由首爾崇實大學多個院系及韓國科學技術院未來戰略研究院共同發表。
方法
人工智慧輔助立場檢測的挑戰部分在於後勤層面,涉及在當前尖端技術限制下,機器學習系統能同時處理與關聯的資訊量。
新聞報導往往避免直接表達觀點,而是透過選擇引述哪些消息來源、如何構建敘事框架、以及省略哪些細節等手法,隱含 或暗示立場。
即使文章立場明確,相關訊號也常分散於文本各處,不同段落指向不同方向。由於語言模型(LM)仍受限於有限的上下文視窗,使其難以像處理推文或社群媒體貼文等短篇內容那樣評估立場——後者中文字與意圖的關聯性更為明確。
因此,標準方法應用於長篇新聞報導時往往力有未逮——在新聞報導中,模糊性常是特徵而非缺陷。
論文指出:
「為解決這些挑戰,我們提出分層建模方法:先在較小語篇單位(如段落或節)層級推斷立場,再整合這些局部預測以確定文章整體立場。
「此框架旨在保留局部語境,捕捉分散的立場線索,以評估新聞報導各部分如何共同形塑其對議題的整體立場。」
為此,作者彙編了名為K-NEWS-STANCE的創新資料集,素材取自2022年6月至2024年6月間的韓國新聞報導。 文章首先透過韓國新聞基金會營運的政府支援元數據服務BigKinds識別,再利用Naver新聞聚合API擷取全文。最終資料集涵蓋31家媒體機構的2,000篇文章,涉及47項全國性議題。
每篇報導均進行雙重標註:其一標示整體立場,其二標示各段落立場——具體涵蓋標題、導語、結論及 直接引述。
標註工作由新聞學專家韓智英(論文第三作者)主導,其運用媒體研究確立的指標(如消息來源選擇、詞彙框架與引述模式)指導流程,共獲得19,650個段落層級立場標籤。
為確保文章具備有效觀點信號,研究人員先按體裁分類,僅選用標記為分析或評論類(主觀框架較可能出現)的文章進行立場標註。
兩名受訓標註者為所有文章進行標註,並受指示在立場不明確時參照相關文章。分歧意見透過討論與追加審查解決。

K-NEWS-STANCE資料集樣本條目英譯版。僅呈現標題、導語及引述內容;正文全文省略。高亮標示為引述立場標籤,藍色代表支持立場,紅色代表反對立場。清晰呈現請參閱引用的PDF來源文件。
JoA-ICL
本系統不將文章視為單一文本塊,而是將其劃分為關鍵結構部分:標題、導語、引述及結論。每個段落由語言模型代理進行標註,判定其立場為支持性、反對性或中立性。
這些局部預測將傳遞至第二個代理程式,用以判定文章整體立場。兩者由控制器協調運作,負責準備提示語並彙整結果。
JoA-ICL 藉此將「上下文學習」(模型從提示中的範例學習)適應於專業新聞寫作結構,採用分段感知提示取代單一通用輸入。
(請注意,論文中多數範例與圖解篇幅冗長,難以在線上文章中清晰呈現。故建議讀者參閱原始PDF文件。)
數據與測試
測試中,研究人員採用宏觀F1值與準確度評估效能,以42至51個隨機種子進行十次運行取平均值,並報告標準誤差。訓練資料用於微調基線模型與分段級代理,少次樣本則透過KLUE-RoBERTa-large的相似性搜尋選取。
測試環境配置為三組RTX A6000 GPU(每組配備48GB VRAM),採用Python 3.9.19、PyTorch 2.5.1、Transformers 4.52.0及vLLM 0.8.5版本。
透過 API 調用 GPT-4o-mini、Claude 3 Haiku 及 Gemini 2 Flash,鏈式思考提示設定溫度值 1.0 與最大令牌數 1000,其餘提示則設定為 100。
針對 Exaone-3.5-2.4B 的完整微調,採用 AdamW 優化器,設定學習率 5e-5、權重衰減 0.01、預熱步驟 100,以批次大小 6 進行 10 個 epoch 的訓練。
基準模型採用經文章層級立場檢測微調的RoBERTa;另採用針對指定任務調整的RoBERTa變體——思考鏈嵌入(CoT Embeddings); LKI-BART(一種編碼器-解碼器模型,透過同時輸入文本與預期立場標籤,從大型語言模型中提取語境知識);以及PT-HCL(一種運用對比學習分離通用特徵與目標議題特徵的方法):

各模型於 K-NEWS-STANCE 測試集的整體立場預測表現。結果以宏觀 F1 分數與準確度呈現,各組最高分以粗體標示。
JOA-ICL 在準確度與宏觀 F1 值兩項指標均取得最佳整體表現,此優勢體現在所有三種測試模型骨架中:GPT-4o-mini、Claude 3 Haiku 及 Gemini 2 Flash。
基於分段的方法持續超越所有其他方案,作者特別指出其在偵測支持性立場方面具有優勢——此為類似模型常見的弱點。
基準模型整體表現較差。RoBERTa與Chain-of-Thought變體在細微案例中表現吃力,而PT-HCL與LKI-BART雖表現較佳,但在多數類別仍落後於JOA-ICL。最高單項準確度來自JOA-ICL(Claude),宏觀F1達64.8%,準確度達66.1%。
下圖呈現各模型對標籤的正誤判別頻率:

基準模型與JoA-ICL的混淆矩陣對比顯示,兩者在識別「支持性」立場時均面臨最大挑戰。
JoA-ICL整體表現優於基準模型,在所有類別中皆能正確識別更多標籤。然而兩者皆在支持性文章辨識上最為吃力,基準模型甚至將近半數文章誤判為中立立場。
JoA-ICL 雖錯誤較少但呈現相同模式,再次印證「正向」立場對模型而言更難偵測。
為驗證JoA-ICL能否突破韓語限制,作者將其應用於德語文章立場檢測數據集CheeSE。由於CheeSE缺乏分段標籤,研究人員採用遠程監督法,將每段文字標記為與全文相同的立場標籤。

德語CheeSE數據集立場檢測結果顯示:JoA-ICL在三種大型語言模型上均持續超越零樣本提示法,且優於微調基準模型,其中Gemini-2.0-flash展現最強整體表現。
即使在這些「雜訊」條件下,JoA-ICL 仍優於微調模型與零次提示。在三種測試骨架模型中,Gemini-2.0-flash 展現最強勁的表現。
結論
在機器學習領域中,鮮少任務如立場預測般具有高度政治敏感性,然而此議題常被以技術性、機械化的方式處理。與此同時,生成式人工智慧中較不複雜的議題——例如影片與圖像創作——往往更受矚目並登上頭條。
這項韓國新研究最令人振奮之處,在於其聚焦於完整篇幅內容的分析——而非推文或短篇社群媒體貼文。後者相較於論文、專論等實質性著作,其影響力往往更為短暫。
此研究(乃至更廣泛的立場預測文獻)存在一項顯著缺失:未考量超連結的價值。這些連結常作為讀者深入探索主題的選用資源,然而連結選擇往往高度主觀,甚至帶有政治色彩。
話雖如此,出版物聲譽越高,越不傾向包含將讀者導離自身網域的連結。加上超連結在搜尋引擎優化(SEO)相關用途與濫用層面的複雜性,使其相較於明確引文、標題等可能有意識或無意識形塑讀者觀點的元素,更難進行量化分析。
初版發佈於2025年7月16日星期三










 Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
 Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
 OpenAI 將依據法院命令保留 ChatGPT 資料,執行長 Altman 提出「AI 特權」建議
許多常使用 ChatGPT 的使用者,包括本文作者,可能都曾與 「臨時聊天 」功能互動過。這個選項是由 OpenAI 受歡迎的聊天機器人所提供,目的是在會話關閉後立即自動清除會話中交換的所有資訊。此外,使用者也可以手動刪除網頁、桌面和行動應用程式側邊欄上過去的 ChatGPT 對話。您可以透過左鍵按一下、按住 Control 鍵按一下或長按所需的聊天內容來刪除對話。然而,本週 OpenAI 面臨使
OpenAI 將依據法院命令保留 ChatGPT 資料,執行長 Altman 提出「AI 特權」建議
許多常使用 ChatGPT 的使用者,包括本文作者,可能都曾與 「臨時聊天 」功能互動過。這個選項是由 OpenAI 受歡迎的聊天機器人所提供,目的是在會話關閉後立即自動清除會話中交換的所有資訊。此外,使用者也可以手動刪除網頁、桌面和行動應用程式側邊欄上過去的 ChatGPT 對話。您可以透過左鍵按一下、按住 Control 鍵按一下或長按所需的聊天內容來刪除對話。然而,本週 OpenAI 面臨使

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai













