Modelos do tipo ChatGPT estão agora sendo treinados para revelar a perspectiva subjacente de uma notícia — mesmo quando esse ponto de vista está oculto por citações, enquadramento ou uma aparência de neutralidade (às vezes insincera). Ao dividir as notícias em segmentos como títulos, leads e citações, um novo sistema aprende a identificar preconceitos mesmo em jornalismo profissional de formato longo.
A capacidade de compreender a verdadeira posição de um escritor ou orador — conhecida na literatura acadêmica como detecção de postura— aborda um dos desafios mais complexos da interpretação linguística: discernir a intenção a partir de um conteúdo que pode ter sido deliberadamente elaborado para ocultá-la ou obscurecê-la.
De A Modest Proposal, de Jonathan Swift, a performances políticas recentes em que atores emprestam a retórica de seus oponentes ideológicos, a superfície de uma declaração não é mais um indicador confiável de sua intenção. O surgimento da ironia, do trollagem, da desinformação e da ambiguidade estratégica tornou cada vez mais difícil determinar de que lado um texto realmente está — ou se ele realmente toma partido.
Muitas vezes, o que não é dito tem tanto significado quanto o que é dito, e a simples decisão de abordar um tema pode sinalizar a posição do autor.
Isso torna a detecção automatizada de posições particularmente desafiadora, pois um sistema eficaz deve fazer mais do que rotular frases individuais como “favoráveis” ou “contrárias”. Em vez disso, ele deve navegar por camadas de significado, ponderando pistas sutis em relação ao fluxo e à direção geral do artigo — uma tarefa que se torna mais difícil no jornalismo de formato longo, onde o tom pode mudar e as opiniões raramente são declaradas diretamente.
Agentes de mudança
Para enfrentar esses desafios, pesquisadores na Coreia do Sul desenvolveram um novo sistema chamado JOA-ICL (Journalism-guided Agentic In-Context Learning, ou Aprendizado Agente em Contexto Guiado pelo Jornalismo) para detectar a postura de artigos de notícias longos.
A ideia central por trás do JoA-ICL é que a postura em nível de artigo é inferida pela agregação de previsões em nível de segmento produzidas por um agente de modelo de linguagem separado. Fonte: https://arxiv.org/pdf/2507.11049
Em vez de avaliar um artigo como um todo, o JOA-ICL o divide em componentes estruturais — título, lead, citações e conclusão — e atribui um modelo menor para rotular cada segmento. Essas previsões localizadas são então passadas para um modelo maior, que as usa para determinar a postura geral do artigo.
O método foi testado em um conjunto de dados coreano recém-compilado contendo 2.000 artigos de notícias anotados para a postura tanto em nível de artigo quanto em nível de segmento. Cada artigo foi rotulado com a contribuição de um especialista em jornalismo, refletindo como a postura é distribuída por toda a estrutura da redação profissional de notícias.
De acordo com o artigo, o JOA-ICL supera as linhas de base baseadas em prompts e ajustadas, mostrando particular força na detecção de posições favoráveis — uma categoria que modelos semelhantes muitas vezes deixam passar. A abordagem também se mostrou eficaz quando aplicada a um conjunto de dados alemão em condições comparáveis, sugerindo que seus princípios podem ser resilientes em diferentes idiomas.
Os autores afirmam:
“Experimentos mostram que o JOA-ICL supera os métodos existentes de detecção de postura, destacando os benefícios da agência em nível de segmento na captura da posição geral de artigos de notícias longos.”
O novo artigo é intitulado Journalism-Guided Agentic In-Context Learning for News Stance Detection (Aprendizado contextual orientado pelo jornalismo para detecção de posições em notícias) e é proveniente de várias faculdades da Universidade Soongsil de Seul, bem como da Escola de Pós-Graduação em Estratégia Futura da KAIST.
Método
Parte do desafio na detecção de postura aumentada por IA é logística, relacionada à quantidade de informações que um sistema de aprendizado de máquina pode processar e correlacionar de uma só vez, dadas as limitações atuais da tecnologia de ponta.
As notícias muitas vezes evitam expressões diretas de opinião, confiando, em vez disso, em uma postura implícita ou presumida sinalizada por meio de escolhas como quais fontes citar, como a narrativa é enquadrada e quais detalhes são omitidos.
Mesmo quando um artigo assume uma posição clara, o sinal muitas vezes está espalhado pelo texto, com diferentes segmentos apontando em diferentes direções. Como os modelos de linguagem (LMs) ainda enfrentam restrições com janelas de contexto limitadas, isso torna difícil para eles avaliar a postura da mesma forma que fariam para conteúdos mais curtos — como tweets ou postagens em mídias sociais — onde a relação entre o texto e a intenção é mais explícita.
Como resultado, as abordagens padrão muitas vezes ficam aquém quando aplicadas ao jornalismo completo, onde a ambiguidade é frequentemente uma característica, não uma falha.
O artigo afirma:
“Para enfrentar esses desafios, propomos uma abordagem de modelagem hierárquica que primeiro infere a postura no nível de unidades discursivas menores (por exemplo, parágrafos ou seções) e, subsequentemente, integra essas previsões locais para determinar a postura geral do artigo.
“Essa estrutura foi projetada para manter o contexto local e capturar pistas de postura dispersas ao avaliar como diferentes partes de uma notícia contribuem para sua posição geral sobre um assunto.”
Para esse fim, os autores compilaram um novo conjunto de dados chamado K-NEWS-STANCE, extraído da cobertura jornalística coreana entre junho de 2022 e junho de 2024. Os artigos foram inicialmente identificados através do BigKinds, um serviço de metadados apoiado pelo governo e gerido pela Korea Press Foundation, e os textos completos foram recuperados utilizando a API do agregador Naver News. O conjunto de dados final incluiu 2.000 artigos de 31 veículos de comunicação, cobrindo 47 questões de relevância nacional.
Cada artigo foi anotado duas vezes: uma para sua postura geral sobre uma determinada questão e outra para segmentos individuais — especificamente o título, a introdução, a conclusão e as citações diretas.
A anotação foi liderada pela especialista em jornalismo Jiyoung Han, terceira autora do artigo, que orientou o processo usando pistas estabelecidas a partir de estudos de mídia, como seleção de fontes, enquadramento lexical e padrões de citação. No total, foram obtidos 19.650 rótulos de posição em nível de segmento.
Para garantir que os artigos contivessem sinais de pontos de vista significativos, cada um foi primeiro classificado por gênero, e apenas aqueles rotulados como análise ou opinião — onde o enquadramento subjetivo é mais provável — foram usados para a anotação de posição.
Dois anotadores treinados rotularam todos os artigos e foram instruídos a consultar artigos relacionados quando a postura não estava clara. As divergências foram resolvidas por meio de discussão e revisão adicional.
Exemplos de entradas do conjunto de dados K-NEWS-STANCE, traduzidos para o inglês. Apenas o título, o lead e as citações são mostrados; o texto completo é omitido. O destaque indica rótulos de postura para citações, com azul para apoio e vermelho para oposição. Consulte o PDF da fonte citada para uma interpretação mais clara.
JoA-ICL
Em vez de tratar um artigo como um único bloco de texto, o sistema proposto o divide em partes estruturais principais: título, lead, citações e conclusão. Cada segmento é atribuído a um agente de modelo de linguagem, que o rotula como favorável, contrário ou neutro.
Essas previsões locais são então passadas para um segundo agente que determina a posição geral do artigo. Os dois agentes são coordenados por um controlador que prepara prompts e reúne resultados.
Assim, o JoA-ICL adapta a aprendizagem contextual — em que o modelo aprende com exemplos na solicitação — para se alinhar com a estrutura da redação profissional de notícias, usando solicitações sensíveis ao segmento em vez de uma única entrada genérica.
(Observe que a maioria dos exemplos e ilustrações no artigo são longos e difíceis de reproduzir de forma legível em um artigo online. Portanto, incentivamos os leitores a consultar o PDF da fonte original.)
Dados e testes
Nos testes, os pesquisadores usaram macro F1 e precisão para avaliar o desempenho, calculando a média dos resultados em dez execuções com sementes aleatórias de 42 a 51 e relatando o erro padrão. Os dados de treinamento foram usados para ajustar os modelos de linha de base e os agentes em nível de segmento, com amostras de poucos disparos selecionadas por meio de pesquisa de similaridade usando KLUE-RoBERTa-large.
Os testes foram realizados em três GPUs RTX A6000 (cada uma com 48 GB de VRAM), usando Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0 e vLLM 0.8.5.
GPT-4o-mini, Claude 3 Haiku e Gemini 2 Flash foram utilizados via API, com uma temperatura de 1,0 e tokens máximos definidos para 1000 para prompts de cadeia de pensamento e 100 para outros.
Para o ajuste fino completo do Exaone-3.5-2.4B, o otimizador AdamW foi usado com uma taxa de aprendizagem de 5e-5, decaimento de peso de 0,01, 100 etapas de aquecimento e treinamento por 10 épocas com um tamanho de lote de 6.
Para as linhas de base, os autores utilizaram o RoBERTa, ajustado para a detecção de postura ao nível do artigo; Chain-of-Thought (CoT) Embeddings, um ajuste alternativo do RoBERTa para a tarefa atribuída; LKI-BART, um modelo codificador-decodificador que incorpora conhecimento contextual de um grande modelo de linguagem, solicitando-lhe tanto o texto de entrada como os rótulos de posição pretendidos; e PT-HCL, um método que utiliza aprendizagem contrastiva para separar características gerais das específicas da questão-alvo:
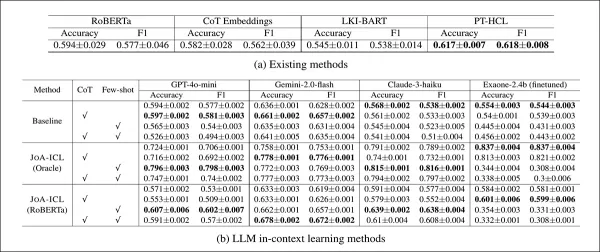
Desempenho de cada modelo no conjunto de testes K-NEWS-STANCE para previsão geral de postura. Os resultados são apresentados como macro F1 e precisão, com a pontuação mais alta em cada grupo em negrito.
O JOA-ICL alcançou o melhor desempenho geral tanto em precisão quanto em macro F1, uma vantagem observada em todas as três estruturas de modelo testadas: GPT-4o-mini, Claude 3 Haiku e Gemini 2 Flash.
O método baseado em segmentos superou consistentemente todas as outras abordagens, com os autores observando uma força particular na detecção de posturas de apoio — uma fraqueza comum em modelos semelhantes.
Os modelos de linha de base tiveram um desempenho pior no geral. As variantes RoBERTa e Chain-of-Thought tiveram dificuldades com casos sutis, enquanto PT-HCL e LKI-BART tiveram um desempenho melhor, mas ainda ficaram atrás do JOA-ICL na maioria das categorias. O resultado único mais preciso veio do JOA-ICL (Claude), com 64,8% de macro F1 e 66,1% de precisão.
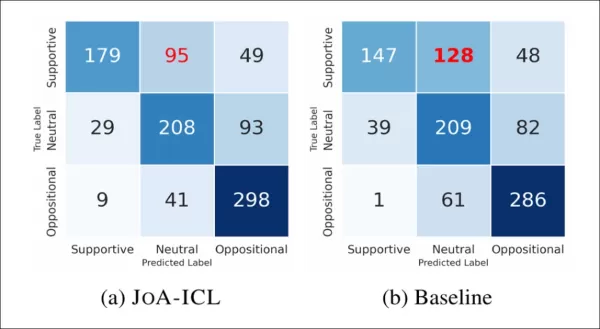
A imagem abaixo mostra com que frequência os modelos identificaram corretamente ou incorretamente cada rótulo:
Matrizes de confusão comparando a linha de base e o JoA-ICL, mostrando que ambos os métodos têm mais dificuldade em detectar posições “favoráveis”.
O JoA-ICL teve um desempenho melhor do que a linha de base, identificando corretamente mais rótulos em todas as categorias. No entanto, ambos os modelos tiveram mais dificuldade com artigos favoráveis, e a linha de base classificou erroneamente quase metade deles, muitas vezes rotulando-os como neutros.
O JoA-ICL cometeu menos erros, mas seguiu o mesmo padrão, reforçando que as posições “positivas” são mais difíceis de detectar pelos modelos.
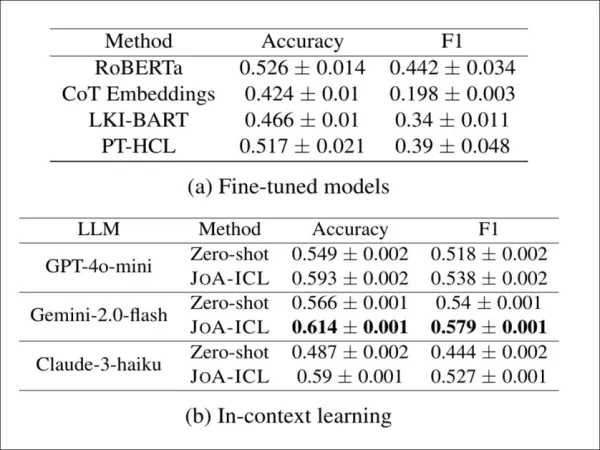
Para testar se o JoA-ICL funciona além do idioma coreano, os autores o aplicaram ao CheeSE, um conjunto de dados alemão para detecção de postura em nível de artigo. Como o CheeSE não possui rótulos em nível de segmento, os pesquisadores usaram supervisão distante, atribuindo a cada segmento o mesmo rótulo de postura do artigo completo.
Resultados da detecção de postura no conjunto de dados CheeSE em alemão. O JoA-ICL melhora consistentemente em relação ao prompt zero-shot em todos os três LLMs e supera as linhas de base ajustadas, com o Gemini-2.0-flash apresentando o melhor desempenho geral.
Mesmo nessas condições “ruidosas”, o JoA-ICL superou os modelos ajustados e o prompt zero-shot. Dos três backbones testados, o Gemini-2.0-flash apresentou os melhores resultados.
Conclusão
Poucas tarefas em aprendizado de máquina são tão politicamente sensíveis quanto a previsão de postura, mas muitas vezes ela é abordada em termos técnicos e mecânicos. Enquanto isso, questões menos complexas em IA generativa — como criação de vídeos e imagens — tendem a atrair mais atenção e manchetes.
O aspecto mais encorajador da nova pesquisa coreana é sua contribuição para a análise de conteúdo completo, em vez de tweets e postagens curtas nas redes sociais, cujo impacto costuma ser mais fugaz do que o de um tratado, ensaio ou outro trabalho substancial.
Uma lacuna notável neste estudo — e na literatura sobre previsão de postura de forma mais ampla — é a falta de consideração pelos hiperlinks, que muitas vezes servem como recursos opcionais para os leitores explorarem um tópico mais a fundo. No entanto, a seleção desses URLs pode ser altamente subjetiva e até mesmo politicamente carregada.
Dito isso, quanto mais prestigiada for a publicação, menos provável será que ela inclua links que direcionem os leitores para fora de seu próprio domínio. Isso, juntamente com vários usos e abusos de hiperlinks relacionados ao SEO, torna-os mais difíceis de quantificar do que citações explícitas, títulos ou outros elementos que podem, consciente ou inconscientemente, moldar a opinião do leitor.
Publicado pela primeira vez na quarta-feira, 16 de julho de 2025
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
Ao clicar em "Aceitar todos os cookies", você concorda com o armazenamento de cookies em seu dispositivo para melhorar a navegação no site, analisar o uso do site e auxiliar em nossos esforços de marketing.Política de Privacidade Aviso
Ao visitar qualquer site, ele pode armazenar ou recuperar informações em seu navegador, principalmente na forma de cookies. Essas informações podem ser sobre você, suas preferências ou seu dispositivo e são usadas principalmente para fazer com que o site funcione conforme esperado. As informações geralmente não identificam você diretamente, mas podem proporcionar uma experiência web mais personalizada. Como respeitamos seu direito à privacidade, você pode optar por não permitir alguns tipos de cookies. Clique nos diferentes títulos de categoria para saber mais e alterar nossas configurações padrão. No entanto, bloquear alguns tipos de cookies pode afetar sua experiência no site e os serviços que podemos oferecer. Política de PrivacidadeDeclaração
Gerenciar preferências
Cookie estritamente necessário
Sempre ativado
Esses cookies são necessários para o funcionamento do site e não podem ser desativados em nossos sistemas. Eles geralmente são definidos apenas em resposta a ações que você realiza, que equivalem a uma solicitação de serviços, como configurar suas preferências de privacidade, fazer login ou preencher formulários. Você pode configurar seu navegador para bloquear esses cookies ou alertá-lo sobre eles, mas algumas partes do site não funcionarão depois. Esses cookies não armazenam nenhuma informação que permita identificar pessoalmente.

















 Lar
Lar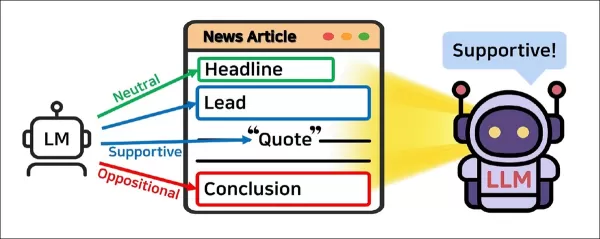

 Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
 Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
 10 ferramentas
10 ferramentas
 xix.ai
código
xix.ai
código

 Comentários (0)
Comentários (0)















 Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
 Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog
Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog
 OpenAI reterá dados do ChatGPT por ordem judicial, CEO Altman propõe 'privilégio de IA'
Muitos usuários regulares do ChatGPT, incluindo o autor deste artigo, podem ter interagido com o recurso de "bate-papo temporário". Essa opção, oferecida pelo popular chatbot da OpenAI, foi projetada
OpenAI reterá dados do ChatGPT por ordem judicial, CEO Altman propõe 'privilégio de IA'
Muitos usuários regulares do ChatGPT, incluindo o autor deste artigo, podem ter interagido com o recurso de "bate-papo temporário". Essa opção, oferecida pelo popular chatbot da OpenAI, foi projetada



















