
















 家
家AIがニュースコンテンツに潜む隠された意図を明らかにする
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。
執筆者や発言者の真の立場を把握する能力——学術文献ではスタンス検出として知られる——は、言語解釈における最も複雑な課題の一つに取り組むものである。意図を隠蔽または曖昧化するために意図的に設計された可能性のある内容から、その真意を見極めることである。
ジョナサン・スウィフトの『謙虚な提案』から、イデオロギー的対立者のレトリックを借りる現代政治家のパフォーマンスに至るまで、発言の表面はもはや意図の信頼できる指標ではない。皮肉、荒らし行為、偽情報、戦略的曖昧性の台頭により、テキストが真に支持する立場——あるいは立場を表明しているか否か——を判断することはますます困難になっている。
しばしば、語られないことは語られたことと同等の重要性を持ち、ある主題を扱うという選択そのものが著者の立場を示唆する。
このため自動的な立場検出は特に困難である。効果的なシステムは個々の文を「支持的」または「対立的」とラベル付けするだけでは不十分だ。代わりに、意味の層をナビゲートし、微妙な手がかりを記事全体の流れや方向性と照らし合わせて評価しなければならない。トーンが変化し意見が直接表明されることが稀な長文ジャーナリズムでは、この作業はさらに困難になる。
変化をもたらすエージェント
これらの課題に対処するため、韓国の研究者らは長文ニュース記事のスタンスを検出する新システム「JOA-ICL(ジャーナリズム主導型エージェント的文脈学習)」を開発した。
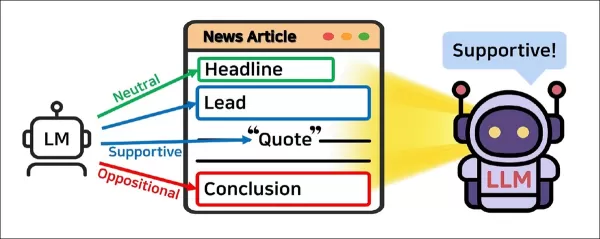
JOA-ICLの中核となる考え方は、個別の言語モデルエージェントが生成するセグメントレベルの予測を集約することで、記事全体のスタンスを推定するというものである。出典: https://arxiv.org/pdf/2507.11049
JOA-ICLは記事全体を評価するのではなく、見出し・リード文・引用文・結論といった構造的構成要素に分解し、各セグメントに小型モデルを割り当ててラベル付けを行う。こうして生成された局所的予測は大型モデルに伝達され、記事全体のスタンス判定に活用される。
この手法は、記事レベルとセグメントレベルの両方の立場が注釈された2,000本のニュース記事を含む新規に構築された韓国語データセットでテストされた。各記事はジャーナリズム専門家による入力でラベル付けされ、プロのニュース記事の構造全体に立場がどのように分布しているかを反映している。
論文によれば、JOA-ICLはプロンプトベースおよび微調整済みベースラインの両方を上回り、特に支持的立場の検出に強みを発揮した。類似モデルがしばしば見落とすカテゴリーである。同手法は同等の条件下でドイツ語データセットにも有効であり、その原理が言語を超えて適用可能であることを示唆している。
著者らは次のように述べている:
「実験により、JOA-ICLが既存のスタンス検出手法を上回る性能を発揮し、長文ニュース記事の全体的な立場を捉える上でセグメントレベルの主体性が有益であることを示した」
本論文は「ジャーナリズム主導の文脈内主体性学習によるニューススタンス検出」と題され、ソウル・崇実大学の複数学部およびKAIST未来戦略大学院による共同研究である。
手法
AIを活用したスタンス検出における課題の一部は、現在の最先端技術の限界を考慮した際、機械学習システムが一度に処理・関連付け可能な情報量に関連するロジスティクス面にある。
ニュース記事は往々にして意見の直接的な表明を避け、代わりに引用する情報源の選択、物語の枠組みの組み立て方、省略される詳細といった選択を通じて示される暗黙的または 想定されるスタンスに依存している。
記事が明確な立場を取っている場合でも、そのシグナルはテキスト全体に散在し、異なるセグメントが異なる方向を指し示すことが多い。言語モデル(LM)は依然として限られたコンテキストウィンドウの制約に直面しているため、テキストと意図の関係がより明示的なツイートやソーシャルメディアの投稿のような短いコンテンツの場合と同じ方法でスタンスを評価することは困難である。
その結果、曖昧さが欠陥ではなく特徴であることが多い長編ジャーナリズムに適用する場合、標準的な手法はしばしば不十分である。
本論文は次のように述べている:
「これらの課題に対処するため、我々は階層的モデリング手法を提案する。まず小規模な談話単位(段落やセクションなど)レベルでスタンスを推定し、その後これらの局所的予測を統合して記事全体のスタンスを決定する。
「この枠組みは、ローカルな文脈を維持しつつ、ニュース記事の各部分が問題に対する全体的な立場にどのように寄与するかを評価する際に、分散したスタンスの手がかりを捉えるよう設計されている。」
この目的のため、著者らは2022年6月から2024年6月までの韓国ニュース報道から抽出した新規データセット「K-NEWS-STANCE」を構築した。 記事はまず、韓国報道財団が運営する政府支援メタデータサービス「BigKinds」を通じて特定され、全文はNaverニュースアグリゲーターAPIを用いて取得された。最終データセットには31の報道機関から2,000本の記事が含まれ、47の全国的に関連する問題を取り上げた。
各記事は二重に注釈が付けられた:一つは特定問題に対する全体的なスタンス、もう一つは個々のセグメント(具体的には見出し、リード文、結論、直接引用)に対するものである。
注釈はジャーナリズム専門家である本論文の第三著者、ハン・ジヨン氏が主導し、情報源の選択、語彙的フレーミング、引用パターンなど、メディア研究で確立された手がかりを用いてプロセスを指導した。合計19,650のセグメントレベルのスタンスラベルが得られた。
記事に意味のある視点のシグナルが含まれていることを保証するため、まず各記事をジャンル別に分類し、主観的なフレーミングが行われる可能性が高い「分析」または「意見」とラベル付けされた記事のみをスタンス注釈に使用した。
訓練を受けた2名のアノテーターが全記事をラベル付けし、スタンスが不明確な場合は関連記事を参照するよう指示された。意見の相違は議論と追加レビューを通じて解決された。

K-NEWS-STANCEデータセットからのサンプル記事(英語訳)。見出し、リード文、引用文のみを示し、本文全文は省略。ハイライトは引用文のスタンスラベルを示し、支持的は青、反対的は赤で表示。より明確な表示については引用文献PDFを参照のこと。
JoA-ICL
提案システムは記事を単一のテキストブロックとして扱う代わりに、見出し、リード文、引用文、結論という主要構造部分に分割する。各セグメントは言語モデルエージェントに割り当てられ、支持的 ・反対的 ・中立的のいずれかでラベル付けされる。
これらの局所予測は、記事全体のスタンスを決定する第二のエージェントに渡される。両エージェントは、プロンプトを準備し結果を集約するコントローラーによって調整される。
こうしてJoA-ICLは、単一の汎用入力ではなくセグメント認識型プロンプトを用いることで、プロのニュース執筆構造に適合させるため、文脈内学習(モデルがプロンプト内の例から学習する手法)を適応させている。
(本論文の例や図表の多くは長文であり、オンライン記事で読みやすく再現することが困難です。そのため、読者の皆様には原典のPDFを参照されることをお勧めします。)
データとテスト
テストでは、研究者らはマクロF1と精度を用いて性能を評価し、42から51のランダムシードを用いた10回の実行結果を平均化し、標準誤差を報告した。トレーニングデータはベースラインモデルとセグメントレベルエージェントの微調整に使用され、KLUE-RoBERTa-largeを用いた類似性検索を通じて少数のショットサンプルが選択された。
テストは3台のRTX A6000 GPU(各48GB VRAM)上で実施。環境はPython 3.9.19、PyTorch 2.5.1、Transformers 4.52.0、vLLM 0.8.5を使用。
GPT-4o-mini、Claude 3 Haiku、Gemini 2 FlashはAPI経由で利用され、思考連鎖プロンプトでは温度1.0、最大トークン数1000、その他では100に設定された。
Exaone-3.5-2.4Bの完全な微調整には、AdamWオプティマイザーを使用し、学習率は5e-5、重み減衰は0.01、ウォームアップステップは100、バッチサイズ6で10エポックのトレーニングを実施した。
ベースラインとして、著者らは以下のモデルを採用した:- 記事レベルスタンス検出用に微調整されたRoBERTa- 割り当てられたタスク向けにRoBERTaを代替調整したChain-of-Thought (CoT) Embeddings LKI-BART(入力テキストと意図するスタンスラベルの両方でプロンプトを提示することで大規模言語モデルからの文脈知識を組み込んだエンコーダ-デコーダモデル)、およびPT-HCL(対比学習を用いて一般的な特徴と対象問題固有の特徴を分離する手法)を比較対象とした。
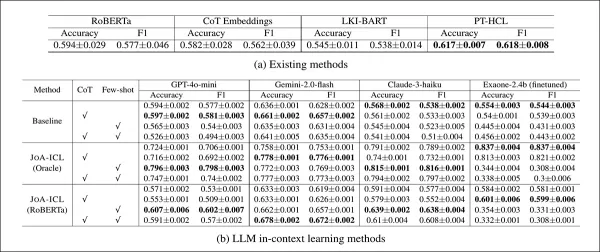
K-NEWS-STANCEテストセットにおける各モデルの総合的スタンス予測性能。結果はマクロF1と精度で示され、各グループ最高スコアは太字で表示。
JOA-ICLは精度とマクロF1の両方で最高の総合性能を達成し、テストした3つのモデル基盤(GPT-4o-mini、Claude 3 Haiku、Gemini 2 Flash)すべてで優位性が確認された。
セグメントベース手法は一貫して他手法を上回り、特に支持的スタンス検出に強みを持つと著者らは指摘している(類似モデルに共通する弱点)。
ベースラインモデルは全体的に劣る結果となった。RoBERTaおよびChain-of-Thoughtの変種は微妙なケースで苦戦し、PT-HCLとLKI-BARTはより良い性能を示したものの、ほとんどのカテゴリーでJOA-ICLに及ばなかった。最も正確な単一結果はJOA-ICL(Claude)から得られ、マクロF1スコア64.8%、精度66.1%を記録した。
下図は各ラベルの正誤判定頻度を示す:
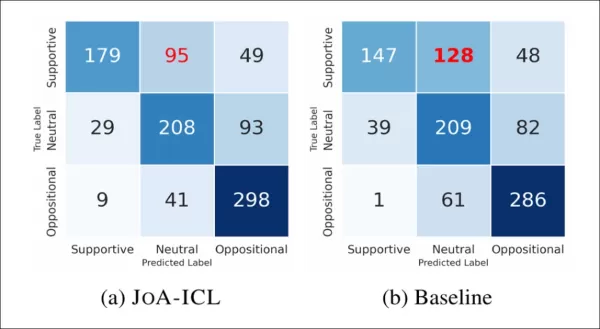
ベースラインとJoA-ICLを比較した混同行列。両手法とも「支持的」スタンスの検出に最も苦戦していることがわかる。
JoA-ICLは全体的にベースラインより優れており、全カテゴリでより多くのラベルを正しく識別した。しかし両モデルとも支持的記事の識別が最も困難で、ベースラインはほぼ半数を誤分類し、しばしば中立とラベル付けした。
JoA-ICLは誤りが少なかったものの同様の傾向を示し、「肯定的」な立場の検出がモデルにとって困難であることを裏付けた。
JoA-ICLが韓国語を超えて機能するか検証するため、著者らはドイツ語記事レベルスタンス検出データセットCheeSEに適用した。CheeSEにはセグメントレベルラベルが存在しないため、研究者らは遠隔教師付き学習を採用し、各セグメントに記事全体のスタンスラベルを付与した。
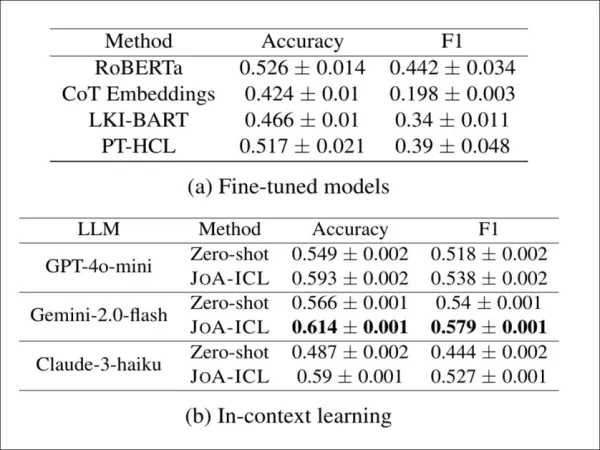
ドイツ語CheeSEデータセットにおけるスタンス検出結果。JoA-ICLは3つのLLM全てでゼロショットプロンプティングを一貫して上回り、ファインチューニング済みベースラインを凌駕。Gemini-2.0-flashが総合的に最強の性能を発揮。
こうした「ノイズの多い」条件下でも、JoA-ICLはファインチューニング済みモデルとゼロショットプロンプティングの両方を上回った。テストした3つのバックボーンのうち、Gemini-2.0-flashが最も優れた結果をもたらした。
結論
機械学習において、スタンス予測ほど政治的に敏感なタスクはほとんどない。にもかかわらず、この課題は往々にして技術的・機械的な観点からアプローチされる。一方、生成AIにおける動画や画像生成といった比較的単純な課題の方が、より多くの注目や見出しを集める傾向にある。
今回の韓国研究で最も期待される点は、ツイートや短文ソーシャルメディア投稿ではなく、論文やエッセイなどの本格的な著作物と同様に持続的な影響力を持つ長文コンテンツの分析に貢献していることだ。
本研究(およびスタンス予測研究全般)における顕著な欠落点は、ハイパーリンクの考慮不足である。リンクは読者がテーマを深く探求するための補助的資源となるが、その選択は極めて主観的であり、政治的意図すら内包し得る。
とはいえ、出版物の権威が高ければ高いほど、自ドメイン外へ誘導するリンクを掲載する可能性は低くなる。この特性に加え、SEO関連の様々なハイパーリンクの活用や悪用が、明示的な引用やタイトルなど、読者の意見を意識的・無意識的に形成しうる要素よりも、リンクの定量化を困難にしている。
初出:2025年7月16日(水)
関連記事
 AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
OpenAI、裁判所命令によりChatGPTデータを保持へ アルトマンCEOは「AI特権」を提案
この記事の筆者を含め、ChatGPTの常連ユーザーの多くは、「一時チャット」機能を利用したことがあるかもしれません。OpenAIの人気チャットボットによって提供されるこのオプションは、セッションが閉じられると同時に、セッション中に交換されたすべての情報を自動的に消去するように設計されています。さらに、ユーザーはウェブ、デスクトップ、モバイルアプリケーションのサイドバーから、過去のChatGPTの会
関連特集おすすめ
仕事
AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
OpenAI、裁判所命令によりChatGPTデータを保持へ アルトマンCEOは「AI特権」を提案
この記事の筆者を含め、ChatGPTの常連ユーザーの多くは、「一時チャット」機能を利用したことがあるかもしれません。OpenAIの人気チャットボットによって提供されるこのオプションは、セッションが閉じられると同時に、セッション中に交換されたすべての情報を自動的に消去するように設計されています。さらに、ユーザーはウェブ、デスクトップ、モバイルアプリケーションのサイドバーから、過去のChatGPTの会
関連特集おすすめ
仕事
 AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
 10 ツール
10 ツール
 xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。
執筆者や発言者の真の立場を把握する能力——学術文献ではスタンス検出として知られる——は、言語解釈における最も複雑な課題の一つに取り組むものである。意図を隠蔽または曖昧化するために意図的に設計された可能性のある内容から、その真意を見極めることである。
ジョナサン・スウィフトの『謙虚な提案』から、イデオロギー的対立者のレトリックを借りる現代政治家のパフォーマンスに至るまで、発言の表面はもはや意図の信頼できる指標ではない。皮肉、荒らし行為、偽情報、戦略的曖昧性の台頭により、テキストが真に支持する立場——あるいは立場を表明しているか否か——を判断することはますます困難になっている。
しばしば、語られないことは語られたことと同等の重要性を持ち、ある主題を扱うという選択そのものが著者の立場を示唆する。
このため自動的な立場検出は特に困難である。効果的なシステムは個々の文を「支持的」または「対立的」とラベル付けするだけでは不十分だ。代わりに、意味の層をナビゲートし、微妙な手がかりを記事全体の流れや方向性と照らし合わせて評価しなければならない。トーンが変化し意見が直接表明されることが稀な長文ジャーナリズムでは、この作業はさらに困難になる。
変化をもたらすエージェント
これらの課題に対処するため、韓国の研究者らは長文ニュース記事のスタンスを検出する新システム「JOA-ICL(ジャーナリズム主導型エージェント的文脈学習)」を開発した。

JOA-ICLの中核となる考え方は、個別の言語モデルエージェントが生成するセグメントレベルの予測を集約することで、記事全体のスタンスを推定するというものである。出典: https://arxiv.org/pdf/2507.11049
JOA-ICLは記事全体を評価するのではなく、見出し・リード文・引用文・結論といった構造的構成要素に分解し、各セグメントに小型モデルを割り当ててラベル付けを行う。こうして生成された局所的予測は大型モデルに伝達され、記事全体のスタンス判定に活用される。
この手法は、記事レベルとセグメントレベルの両方の立場が注釈された2,000本のニュース記事を含む新規に構築された韓国語データセットでテストされた。各記事はジャーナリズム専門家による入力でラベル付けされ、プロのニュース記事の構造全体に立場がどのように分布しているかを反映している。
論文によれば、JOA-ICLはプロンプトベースおよび微調整済みベースラインの両方を上回り、特に支持的立場の検出に強みを発揮した。類似モデルがしばしば見落とすカテゴリーである。同手法は同等の条件下でドイツ語データセットにも有効であり、その原理が言語を超えて適用可能であることを示唆している。
著者らは次のように述べている:
「実験により、JOA-ICLが既存のスタンス検出手法を上回る性能を発揮し、長文ニュース記事の全体的な立場を捉える上でセグメントレベルの主体性が有益であることを示した」
本論文は「ジャーナリズム主導の文脈内主体性学習によるニューススタンス検出」と題され、ソウル・崇実大学の複数学部およびKAIST未来戦略大学院による共同研究である。
手法
AIを活用したスタンス検出における課題の一部は、現在の最先端技術の限界を考慮した際、機械学習システムが一度に処理・関連付け可能な情報量に関連するロジスティクス面にある。
ニュース記事は往々にして意見の直接的な表明を避け、代わりに引用する情報源の選択、物語の枠組みの組み立て方、省略される詳細といった選択を通じて示される暗黙的または 想定されるスタンスに依存している。
記事が明確な立場を取っている場合でも、そのシグナルはテキスト全体に散在し、異なるセグメントが異なる方向を指し示すことが多い。言語モデル(LM)は依然として限られたコンテキストウィンドウの制約に直面しているため、テキストと意図の関係がより明示的なツイートやソーシャルメディアの投稿のような短いコンテンツの場合と同じ方法でスタンスを評価することは困難である。
その結果、曖昧さが欠陥ではなく特徴であることが多い長編ジャーナリズムに適用する場合、標準的な手法はしばしば不十分である。
本論文は次のように述べている:
「これらの課題に対処するため、我々は階層的モデリング手法を提案する。まず小規模な談話単位(段落やセクションなど)レベルでスタンスを推定し、その後これらの局所的予測を統合して記事全体のスタンスを決定する。
「この枠組みは、ローカルな文脈を維持しつつ、ニュース記事の各部分が問題に対する全体的な立場にどのように寄与するかを評価する際に、分散したスタンスの手がかりを捉えるよう設計されている。」
この目的のため、著者らは2022年6月から2024年6月までの韓国ニュース報道から抽出した新規データセット「K-NEWS-STANCE」を構築した。 記事はまず、韓国報道財団が運営する政府支援メタデータサービス「BigKinds」を通じて特定され、全文はNaverニュースアグリゲーターAPIを用いて取得された。最終データセットには31の報道機関から2,000本の記事が含まれ、47の全国的に関連する問題を取り上げた。
各記事は二重に注釈が付けられた:一つは特定問題に対する全体的なスタンス、もう一つは個々のセグメント(具体的には見出し、リード文、結論、直接引用)に対するものである。
注釈はジャーナリズム専門家である本論文の第三著者、ハン・ジヨン氏が主導し、情報源の選択、語彙的フレーミング、引用パターンなど、メディア研究で確立された手がかりを用いてプロセスを指導した。合計19,650のセグメントレベルのスタンスラベルが得られた。
記事に意味のある視点のシグナルが含まれていることを保証するため、まず各記事をジャンル別に分類し、主観的なフレーミングが行われる可能性が高い「分析」または「意見」とラベル付けされた記事のみをスタンス注釈に使用した。
訓練を受けた2名のアノテーターが全記事をラベル付けし、スタンスが不明確な場合は関連記事を参照するよう指示された。意見の相違は議論と追加レビューを通じて解決された。

K-NEWS-STANCEデータセットからのサンプル記事(英語訳)。見出し、リード文、引用文のみを示し、本文全文は省略。ハイライトは引用文のスタンスラベルを示し、支持的は青、反対的は赤で表示。より明確な表示については引用文献PDFを参照のこと。
JoA-ICL
提案システムは記事を単一のテキストブロックとして扱う代わりに、見出し、リード文、引用文、結論という主要構造部分に分割する。各セグメントは言語モデルエージェントに割り当てられ、支持的 ・反対的 ・中立的のいずれかでラベル付けされる。
これらの局所予測は、記事全体のスタンスを決定する第二のエージェントに渡される。両エージェントは、プロンプトを準備し結果を集約するコントローラーによって調整される。
こうしてJoA-ICLは、単一の汎用入力ではなくセグメント認識型プロンプトを用いることで、プロのニュース執筆構造に適合させるため、文脈内学習(モデルがプロンプト内の例から学習する手法)を適応させている。
(本論文の例や図表の多くは長文であり、オンライン記事で読みやすく再現することが困難です。そのため、読者の皆様には原典のPDFを参照されることをお勧めします。)
データとテスト
テストでは、研究者らはマクロF1と精度を用いて性能を評価し、42から51のランダムシードを用いた10回の実行結果を平均化し、標準誤差を報告した。トレーニングデータはベースラインモデルとセグメントレベルエージェントの微調整に使用され、KLUE-RoBERTa-largeを用いた類似性検索を通じて少数のショットサンプルが選択された。
テストは3台のRTX A6000 GPU(各48GB VRAM)上で実施。環境はPython 3.9.19、PyTorch 2.5.1、Transformers 4.52.0、vLLM 0.8.5を使用。
GPT-4o-mini、Claude 3 Haiku、Gemini 2 FlashはAPI経由で利用され、思考連鎖プロンプトでは温度1.0、最大トークン数1000、その他では100に設定された。
Exaone-3.5-2.4Bの完全な微調整には、AdamWオプティマイザーを使用し、学習率は5e-5、重み減衰は0.01、ウォームアップステップは100、バッチサイズ6で10エポックのトレーニングを実施した。
ベースラインとして、著者らは以下のモデルを採用した:- 記事レベルスタンス検出用に微調整されたRoBERTa- 割り当てられたタスク向けにRoBERTaを代替調整したChain-of-Thought (CoT) Embeddings LKI-BART(入力テキストと意図するスタンスラベルの両方でプロンプトを提示することで大規模言語モデルからの文脈知識を組み込んだエンコーダ-デコーダモデル)、およびPT-HCL(対比学習を用いて一般的な特徴と対象問題固有の特徴を分離する手法)を比較対象とした。

K-NEWS-STANCEテストセットにおける各モデルの総合的スタンス予測性能。結果はマクロF1と精度で示され、各グループ最高スコアは太字で表示。
JOA-ICLは精度とマクロF1の両方で最高の総合性能を達成し、テストした3つのモデル基盤(GPT-4o-mini、Claude 3 Haiku、Gemini 2 Flash)すべてで優位性が確認された。
セグメントベース手法は一貫して他手法を上回り、特に支持的スタンス検出に強みを持つと著者らは指摘している(類似モデルに共通する弱点)。
ベースラインモデルは全体的に劣る結果となった。RoBERTaおよびChain-of-Thoughtの変種は微妙なケースで苦戦し、PT-HCLとLKI-BARTはより良い性能を示したものの、ほとんどのカテゴリーでJOA-ICLに及ばなかった。最も正確な単一結果はJOA-ICL(Claude)から得られ、マクロF1スコア64.8%、精度66.1%を記録した。
下図は各ラベルの正誤判定頻度を示す:

ベースラインとJoA-ICLを比較した混同行列。両手法とも「支持的」スタンスの検出に最も苦戦していることがわかる。
JoA-ICLは全体的にベースラインより優れており、全カテゴリでより多くのラベルを正しく識別した。しかし両モデルとも支持的記事の識別が最も困難で、ベースラインはほぼ半数を誤分類し、しばしば中立とラベル付けした。
JoA-ICLは誤りが少なかったものの同様の傾向を示し、「肯定的」な立場の検出がモデルにとって困難であることを裏付けた。
JoA-ICLが韓国語を超えて機能するか検証するため、著者らはドイツ語記事レベルスタンス検出データセットCheeSEに適用した。CheeSEにはセグメントレベルラベルが存在しないため、研究者らは遠隔教師付き学習を採用し、各セグメントに記事全体のスタンスラベルを付与した。

ドイツ語CheeSEデータセットにおけるスタンス検出結果。JoA-ICLは3つのLLM全てでゼロショットプロンプティングを一貫して上回り、ファインチューニング済みベースラインを凌駕。Gemini-2.0-flashが総合的に最強の性能を発揮。
こうした「ノイズの多い」条件下でも、JoA-ICLはファインチューニング済みモデルとゼロショットプロンプティングの両方を上回った。テストした3つのバックボーンのうち、Gemini-2.0-flashが最も優れた結果をもたらした。
結論
機械学習において、スタンス予測ほど政治的に敏感なタスクはほとんどない。にもかかわらず、この課題は往々にして技術的・機械的な観点からアプローチされる。一方、生成AIにおける動画や画像生成といった比較的単純な課題の方が、より多くの注目や見出しを集める傾向にある。
今回の韓国研究で最も期待される点は、ツイートや短文ソーシャルメディア投稿ではなく、論文やエッセイなどの本格的な著作物と同様に持続的な影響力を持つ長文コンテンツの分析に貢献していることだ。
本研究(およびスタンス予測研究全般)における顕著な欠落点は、ハイパーリンクの考慮不足である。リンクは読者がテーマを深く探求するための補助的資源となるが、その選択は極めて主観的であり、政治的意図すら内包し得る。
とはいえ、出版物の権威が高ければ高いほど、自ドメイン外へ誘導するリンクを掲載する可能性は低くなる。この特性に加え、SEO関連の様々なハイパーリンクの活用や悪用が、明示的な引用やタイトルなど、読者の意見を意識的・無意識的に形成しうる要素よりも、リンクの定量化を困難にしている。
初出:2025年7月16日(水)










 AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
 Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
 OpenAI、裁判所命令によりChatGPTデータを保持へ アルトマンCEOは「AI特権」を提案
この記事の筆者を含め、ChatGPTの常連ユーザーの多くは、「一時チャット」機能を利用したことがあるかもしれません。OpenAIの人気チャットボットによって提供されるこのオプションは、セッションが閉じられると同時に、セッション中に交換されたすべての情報を自動的に消去するように設計されています。さらに、ユーザーはウェブ、デスクトップ、モバイルアプリケーションのサイドバーから、過去のChatGPTの会
OpenAI、裁判所命令によりChatGPTデータを保持へ アルトマンCEOは「AI特権」を提案
この記事の筆者を含め、ChatGPTの常連ユーザーの多くは、「一時チャット」機能を利用したことがあるかもしれません。OpenAIの人気チャットボットによって提供されるこのオプションは、セッションが閉じられると同時に、セッション中に交換されたすべての情報を自動的に消去するように設計されています。さらに、ユーザーはウェブ、デスクトップ、モバイルアプリケーションのサイドバーから、過去のChatGPTの会

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai













