ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like headlines, leads, and quotations, a new system learns to identify bias even in long-form professional journalism.
The ability to grasp the true position of a writer or speaker—known in academic literature as stance detection—tackles one of the most complex challenges in language interpretation: discerning intent from content that may be deliberately designed to conceal or obscure it.
From Jonathan Swift’s A Modest Proposal to recent political performances where actors borrow the rhetoric of their ideological opponents, the surface of a statement is no longer a reliable indicator of its intent. The rise of irony, trolling, disinformation, and strategic ambiguity has made it increasingly difficult to determine which side a text truly supports—or whether it takes a side at all.
Often, what is left unsaid carries as much significance as what is stated, and the mere decision to cover a topic can signal the author's position.
This makes automated stance detection particularly challenging, as an effective system must do more than label individual sentences as “supportive” or “oppositional.” Instead, it must navigate layers of meaning, weighing subtle cues against the overall flow and direction of the article—a task made more difficult in long-form journalism, where tone may shift and opinions are rarely stated directly.
Agents For Change
To address these challenges, researchers in South Korea have developed a new system called JOA-ICL (Journalism-guided Agentic In-Context Learning) to detect the stance of long-form news articles.
The core idea behind JoA-ICL is that article-level stance is inferred by aggregating segment-level predictions produced by a separate language model agent. Source: https://arxiv.org/pdf/2507.11049
Rather than evaluating an article as a whole, JOA-ICL breaks it down into structural components—headline, lead, quotations, and conclusion—and assigns a smaller model to label each segment. These localized predictions are then passed to a larger model, which uses them to determine the article’s overall stance.
The method was tested on a newly compiled Korean dataset containing 2,000 news articles annotated for both article-level and segment-level stance. Each article was labeled with input from a journalism expert, reflecting how stance is distributed throughout the structure of professional news writing.
According to the paper, JOA-ICL outperforms both prompting-based and fine-tuned baselines, showing particular strength in detecting supportive stances—a category that similar models often miss. The approach also proved effective when applied to a German dataset under comparable conditions, suggesting its principles may be resilient across languages.
The authors state:
“Experiments show that JOA-ICL outperforms existing stance detection methods, highlighting the benefits of segment-level agency in capturing the overall position of long-form news articles.”
The new paper is titled Journalism-Guided Agentic In-Context Learning for News Stance Detection and comes from various faculties at Seoul's Soongsil University, as well as KAIST's Graduate School of Future Strategy.
Method
Part of the challenge in AI-augmented stance detection is logistical, related to how much information a machine learning system can process and correlate at once, given current state-of-the-art limitations.
News articles often avoid direct expressions of opinion, relying instead on an implicit or assumed stance signaled through choices such as which sources to quote, how the narrative is framed, and which details are omitted.
Even when an article takes a clear position, the signal is often scattered across the text, with different segments pointing in different directions. Since language models (LMs) still face constraints with limited context windows, this makes it difficult for them to assess stance in the same way they might for shorter content—like tweets or social media posts—where the relationship between text and intent is more explicit.
As a result, standard approaches often fall short when applied to full-length journalism, where ambiguity is often a feature, not a flaw.
The paper states:
“To address these challenges, we propose a hierarchical modeling approach that first infers the stance at the level of smaller discourse units (e.g., paragraphs or sections), and subsequently integrates these local predictions to determine the overall stance of the article.
“This framework is designed to retain local context and capture dispersed stance cues in assessing how different parts of a news story contribute to its overall position on an issue.”
To this end, the authors compiled a novel dataset called K-NEWS-STANCE, drawn from Korean news coverage between June 2022 and June 2024. Articles were first identified through BigKinds, a government-supported metadata service run by the Korea Press Foundation, and full texts were retrieved using the Naver News aggregator API. The final dataset included 2,000 articles from 31 outlets, covering 47 nationally relevant issues.
Each article was annotated twice: once for its overall stance on a given issue, and again for individual segments—specifically the headline, lead, conclusion, and direct quotations.
The annotation was led by journalism expert Jiyoung Han, the paper's third author, who guided the process using established cues from media studies, such as source selection, lexical framing, and quotation patterns. In total, 19,650 segment-level stance labels were obtained.
To ensure the articles contained meaningful viewpoint signals, each was first classified by genre, and only those labeled as analysis or opinion—where subjective framing is more likely—were used for stance annotation.
Two trained annotators labeled all articles and were instructed to consult related articles when the stance was unclear. Disagreements were resolved through discussion and additional review.
Sample entries from the K-NEWS-STANCE dataset, translated into English. Only the headline, lead, and quotations are shown; full body text is omitted. Highlighting indicates stance labels for quotations, with blue for supportive and red for oppositional. Please refer to the cited source PDF for clearer rendition.
JoA-ICL
Instead of treating an article as a single block of text, the proposed system divides it into key structural parts: headline, lead, quotations, and conclusion. Each segment is assigned to a language model agent, which labels it as supportive, oppositional, or neutral.
These local predictions are then passed to a second agent that determines the article’s overall stance. The two agents are coordinated by a controller that prepares prompts and gathers results.
Thus, JoA-ICL adapts in-context learning—where the model learns from examples in the prompt—to align with the structure of professional news writing, using segment-aware prompts instead of a single generic input.
(Please note that most of the examples and illustrations in the paper are lengthy and difficult to reproduce legibly in an online article. We therefore encourage readers to refer to the original source PDF.)
Data and Tests
In testing, the researchers used macro F1 and accuracy to evaluate performance, averaging results over ten runs with random seeds from 42 to 51 and reporting standard error. Training data was used to fine-tune baseline models and segment-level agents, with few-shot samples selected through similarity search using KLUE-RoBERTa-large.
Tests were conducted on three RTX A6000 GPUs (each with 48GB of VRAM), using Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0, and vLLM 0.8.5.
GPT-4o-mini, Claude 3 Haiku, and Gemini 2 Flash were utilized via API, with a temperature of 1.0 and max tokens set to 1000 for chain-of-thought prompts, and 100 for others.
For full fine-tuning of Exaone-3.5-2.4B, the AdamW optimizer was used with a 5e-5 learning rate, 0.01 weight decay, 100 warmup steps, and training for 10 epochs at a batch size of 6.
For baselines, the authors used RoBERTa, fine-tuned for article-level stance detection; Chain-of-Thought (CoT) Embeddings, an alternate tuning of RoBERTa for the assigned task; LKI-BART, an encoder-decoder model that incorporates contextual knowledge from a large language model by prompting it with both input text and intended stance labels; and PT-HCL, a method that uses contrastive learning to separate general features from those specific to the target issue:
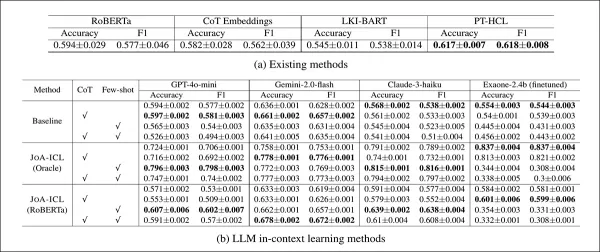
Performance of each model on the K-NEWS-STANCE test set for overall stance prediction. Results are shown as macro F1 and accuracy, with the top score in each group in bold.
JOA-ICL achieved the best overall performance in both accuracy and macro F1, an advantage seen across all three model backbones tested: GPT-4o-mini, Claude 3 Haiku, and Gemini 2 Flash.
The segment-based method consistently outperformed all other approaches, with the authors noting a particular strength in detecting supportive stances—a common weakness in similar models.
Baseline models performed worse overall. RoBERTa and Chain-of-Thought variants struggled with nuanced cases, while PT-HCL and LKI-BART performed better but still trailed JOA-ICL in most categories. The most accurate single result came from JOA-ICL (Claude), with 64.8% macro F1 and 66.1% accuracy.
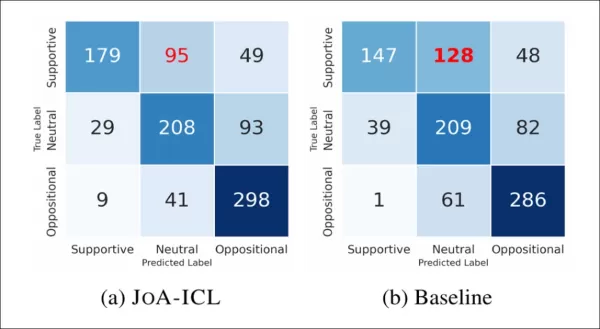
The image below shows how often the models correctly or incorrectly identified each label:
Confusion matrices comparing the baseline and JoA-ICL, showing that both methods struggle most with detecting ‘supportive' stances.
JoA-ICL performed better overall than the baseline, correctly identifying more labels in every category. However, both models struggled most with supportive articles, and the baseline misclassified nearly half, often labeling them as neutral.
JoA-ICL made fewer errors but followed the same pattern, reinforcing that “positive” stances are harder for models to detect.
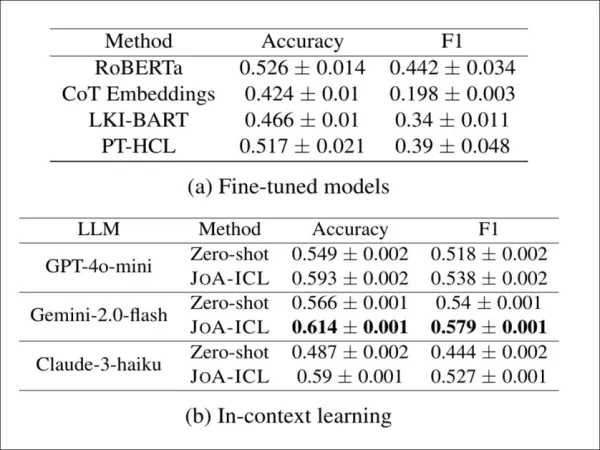
To test whether JoA-ICL works beyond the Korean language, the authors applied it to CheeSE, a German dataset for article-level stance detection. Since CheeSE lacks segment-level labels, the researchers used distant supervision, assigning every segment the same stance label as the full article.
Stance detection results on the German-language CheeSE dataset. JoA-ICL consistently improves over zero-shot prompting across all three LLMs and outperforms fine-tuned baselines, with Gemini-2.0-flash yielding the strongest overall performance.
Even under these “noisy” conditions, JoA-ICL outperformed both fine-tuned models and zero-shot prompting. Of the three backbones tested, Gemini-2.0-flash delivered the strongest results.
Conclusion
Few tasks in machine learning are as politically sensitive as stance prediction, yet it is often approached in technical, mechanical terms. Meanwhile, less complex issues in generative AI—such as video and image creation—tend to attract more attention and headlines.
The most encouraging aspect of the new Korean research is its contribution to analyzing full-length content, rather than tweets and short-form social media posts, whose impact is often more fleeting than that of a treatise, essay, or other substantial work.
One notable gap in this study—and in the stance prediction literature more broadly—is the lack of consideration for hyperlinks, which often serve as optional resources for readers to explore a topic further. Yet the selection of such URLs can be highly subjective and even politically charged.
That said, the more prestigious the publication, the less likely it is to include links that direct readers away from its own domain. This, along with various SEO-related uses and abuses of hyperlinks, makes them harder to quantify than explicit quotes, titles, or other elements that may consciously or unconsciously shape the reader’s opinion.
AI Reveals Hidden Agendas in News ContentChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 LaunchAnthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable ReasoningSmall language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
By clicking "Accept All Cookies", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.Privacy Policy Notice
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings.However, blocking some types of cookies may impact your experience of the site and the services we are able to offer. Privacy PolicyStatement
Manage Preferences
Strictly Necessary Cookie
Always Active
These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information.

















 Home
Home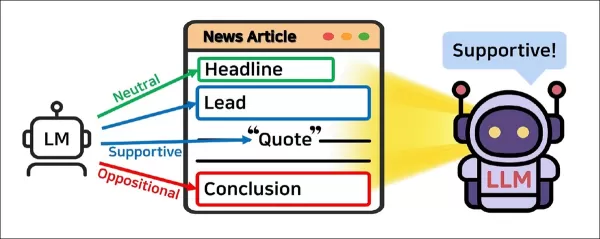

 AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
 Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
 15 tools
15 tools
 xix.ai
Business
xix.ai
Business

 Comments (0)
0/500
Comments (0)
0/500















 AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
 Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
 Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th
Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th



















