
















 Дом
Дом
Nvidia представила модель искусственного интеллекта Nemotron-Nano-9B-v2 с открытым исходным кодом и возможностью отключаемого рассуждения
Небольшие языковые модели набирают популярность. После дебюта модели искусственного зрения размером со смарт-часы от Liquid AI, созданной на базе технологий MIT, и предложения Google для смартфонов, Nvidia теперь выходит на сцену со своим собственным упрощенным конкурентом: Nemotron-Nano-9B-V2. Эта новая модель лидирует в своем классе по ключевым показателям и обладает уникальной функцией, которая позволяет пользователям включать или отключать «рассуждения» ИИ — по сути, процесс самопроверки перед предоставлением окончательного ответа.
Хотя 9 миллиардов параметров превышают масштаб микромоделей с миллионами параметров, о которых мы недавно сообщали, Nvidia подчеркивает, что это значительная оптимизация по сравнению с первоначальными 12 миллиардами параметров. Переработанный размер специально разработан для работы на одном широко доступном графическом процессоре Nvidia A10.
Как объяснил Олексий Кучиаев, директор Nvidia по пост-обучению моделей искусственного интеллекта, в ответ на вопрос о X: «Мы сократили модель с 12 миллиардов до 9 миллиардов, чтобы она идеально подходила для A10, популярного графического процессора для развертывания. Кроме того, это гибридная архитектура, которая позволяет обрабатывать более крупные пакеты данных и достигать скорости, в шесть раз превышающей скорость традиционных трансформаторных моделей аналогичного размера».
Для сравнения: многие ведущие большие языковые модели работают в диапазоне 70+ миллиардов параметров. Параметры — это внутренние настройки, которые определяют поведение модели, где более высокие значения обычно указывают на большие возможности, но также требуют значительно большей вычислительной мощности.
Модель поддерживает несколько языков, включая английский, немецкий, испанский, французский, итальянский и японский. Расширенные возможности также охватывают корейский, португальский, русский и китайский языки. Она хорошо подходит для задач, начиная от выполнения инструкций и заканчивая генерацией кода.
Nemotron-Nano-9B-V2 и ее предварительно обученные наборы данных в настоящее время доступны на Hugging Face и через собственный каталог моделей Nvidia.
Слияние архитектур Transformer и Mamba
Модель построена на основе Nemotron-H, семейства гибридных моделей Mamba-Transformer, которые служат основой для новейших продуктов Nvidia в области искусственного интеллекта.
Хотя доминирующие LLM обычно полагаются исключительно на архитектуру Transformer и ее механизмы внимания, они могут стать непомерно дорогостоящими с точки зрения памяти и вычислений по мере увеличения длины входных последовательностей.
Модели Nemotron-H и другие модели, использующие архитектуру Mamba, разработанную исследователями из Университета Карнеги-Меллона и Принстона, включают в себя модели выборочного пространства состояний (SSM). Эти SSM эффективно управляют чрезвычайно длинными последовательностями, поддерживая внутреннее состояние.
Эти слои масштабируются линейно по длине последовательности, что позволяет им обрабатывать гораздо более длинные контексты, чем стандартное самовнимание, без таких же вычислительных затрат.
Гибридная конструкция Mamba-Transformer снижает затраты за счет замены большинства слоев внимания слоями пространства состояний с линейным временем. Это может дать до 2–3 раз более высокую пропускную способность при выполнении задач с длинным контекстом при сохранении сопоставимой точности.
Nvidia не единственная компания, использующая этот подход; другие исследовательские лаборатории в области ИИ, такие как AI2, также выпустили модели, основанные на архитектуре Mamba.
Включение и выключение рассуждений с помощью простых команд
Nemotron-Nano-9B-v2 разработан как унифицированная текстовая модель, способная как к разговорному взаимодействию, так и к сложному рассуждению, обученная полностью с нуля.
По умолчанию система генерирует подробный отчет о рассуждениях, прежде чем дать окончательный ответ. Пользователи могут контролировать это поведение с помощью простых командных токенов, таких как /think или /no_think.
Модель также вводит управление «бюджетом мышления» во время выполнения. Это позволяет разработчикам устанавливать максимальный предел количества токенов, которые модель может использовать для внутреннего мышления, прежде чем она должна дать ответ.
Этот механизм предназначен для балансирования точности и задержки ответа, что имеет решающее значение для таких приложений, как чат-боты для поддержки клиентов или автономные агенты.
Бенчмарки показывают высокую производительность
Результаты оценки демонстрируют конкурентоспособную точность по сравнению с другими ведущими небольшими открытыми моделями. При тестировании с включенным рассуждением с использованием набора NeMo-Skills, Nemotron-Nano-9B-v2 достиг результатов 72,1% по AIME25, 97,8% по MATH500, 64,0% по GPQA и 71,1% по LiveCodeBench.
Результаты тестов на следование инструкциям и длинный контекст также высоки: 90,3% по IFEval и 78,9% по тесту RULER 128K, с дополнительными измеримыми улучшениями по BFCL v3 и тесту HLE.
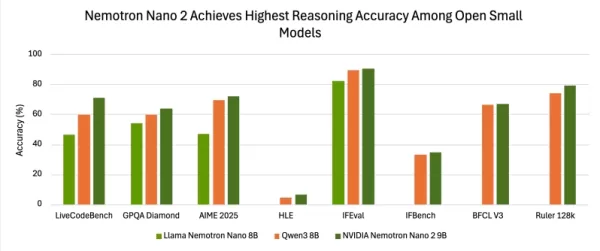
В ходе нескольких оценок Nano-9B-v2 постоянно демонстрирует более высокую точность, чем обычная точка сравнения, модель Qwen3-8B.
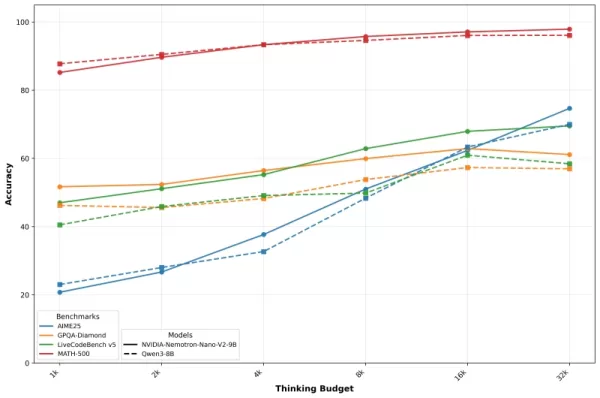
Nvidia представляет эти результаты с помощью кривых «точность против бюджета», которые иллюстрируют, как производительность улучшается по мере увеличения количества токенов, выделенных для рассуждений. Компания отмечает, что тщательный контроль бюджета позволяет разработчикам оптимизировать как качество, так и скорость в производственных средах.
Обучение на синтетических наборах данных
Как модель Nano, так и более широкая семья Nemotron-H обучены на смеси тщательно отобранных веб-данных, проприетарных источников и синтетических обучающих данных.
Корпус обучения включает общий текст, код, математику, научную литературу, юридические и финансовые документы, а также наборы данных с вопросами и ответами, ориентированные на согласование.
Nvidia подтверждает использование синтетических следов рассуждений, сгенерированных другими крупными моделями, для повышения производительности при выполнении сложных тестовых задач.
Лицензирование и коммерческое использование
Модель Nano-9B-v2 выпускается в соответствии с лицензионным соглашением Nvidia Open Model License Agreement, которое в последний раз обновлялось в июне 2025 года.
Эта лицензия разработана с учетом требований разрешительности и удобства для предприятий. Nvidia прямо заявляет, что модели готовы к коммерческому использованию и что разработчики могут свободно создавать и распространять производные работы.
Важно отметить, что Nvidia не претендует на право собственности на любые результаты, сгенерированные моделью, оставляя все права и обязанности за разработчиком или организацией, использующей ее.
Для корпоративных разработчиков это означает, что модель может быть немедленно внедрена в производство без необходимости заключения отдельного коммерческого лицензионного соглашения или уплаты сборов в зависимости от объема использования, выручки или количества пользователей. В отличие от некоторых многоуровневых открытых лицензий других поставщиков, в соглашении нет положений, которые вступают в силу при достижении компанией определенного масштаба.
Тем не менее, соглашение содержит несколько важных условий, которые должны соблюдаться предприятиями:
- Ограждения: пользователи не могут обходить или отключать встроенные механизмы безопасности (называемые «ограждениями») без внедрения подходящих, эквивалентных заменителей для их конкретного развертывания.
- Перераспределение: любое перераспределение модели или ее производных должно включать полный текст лицензии Nvidia Open Model License и надлежащую атрибуцию («Лицензировано Nvidia Corporation в соответствии с лицензией Nvidia Open Model License»).
- Соблюдение: пользователи должны соблюдать все применимые торговые правила и ограничения, такие как законы США об экспортном контроле.
- Условия надежного ИИ: Использование должно соответствовать руководящим принципам Nvidia по надежному ИИ, которые охватывают принципы ответственного развертывания и этические соображения.
- Положение о судебных разбирательствах: лицензия автоматически прекращает свое действие, если пользователь инициирует судебное разбирательство по поводу авторских прав или патентов против другой стороны, утверждая, что имело место нарушение, связанное с моделью.
Эти условия направлены на обеспечение соблюдения законодательства и ответственного использования, а не на ограничение коммерческого масштаба. Предприятиям не нужно запрашивать дополнительное разрешение или платить роялти Nvidia за создание продуктов, монетизацию услуг или расширение базы пользователей. Вместо этого они должны обеспечить, чтобы их практики развертывания соответствовали требованиям безопасности, обеспечивали надлежащее указание авторства и соответствовали всем обязательствам по соблюдению законодательства.
Позиционирование на рынке
С Nemotron-Nano-9B-v2 Nvidia нацелена на разработчиков, которым необходимо сбалансировать возможности рассуждения и эффективность развертывания в меньших масштабах.
Функции контроля бюджета времени выполнения и переключения рассуждений призваны дать системным разработчикам большую гибкость в управлении компромиссом между точностью и скоростью отклика.
Их доступность в Hugging Face и каталоге моделей Nvidia сигнализирует о намерении обеспечить широкую доступность, поощряя эксперименты и интеграцию.
Выпуск Nvidia Nemotron-Nano-9B-v2 подчеркивает постоянное внимание компании к эффективности и контролируемому рассуждению в языковых моделях.
Объединяя гибридные архитектуры с передовыми технологиями сжатия и обучения, Nvidia стремится предоставить разработчикам инструменты, которые сохраняют высокую точность и одновременно снижают операционные затраты и задержки.
Связанная статья
 Вариант OpenClaw от Nvidia может решить самую серьезную проблему: безопасность
Генеральный директор Nvidia Дженсен Хуанг считает, что каждой компании нужна стратегия OpenClaw — и Nvidia готова ее предоставить.Во время своего выступления на конференции GTC в понедельник Хуанг объ
Пентагон заключил соглашения с Nvidia, Microsoft и AWS о внедрении технологий искусственного интеллекта в секретные сети.
После предыдущих соглашений с Google, SpaceX и OpenAI, Министерство обороны США в пятницу объявило о подписании договоров с Nvidia, Microsoft, Amazon Web Services и Reflection AI о использовании их технологий и моделей искусственного интеллекта в сек
На конференции Nvidia GTC представлены NemoClaw, робот Олаф и ставка на 1 триллион долларов
Загрузка плеера…Генеральный директор Дженсен Хуанг вышел на сцену на конференции Nvidia GTC на этой неделе в своей фирменной кожаной куртке, чтобы выступить с двухчасовой речью, в которой он прогнозир
Рекомендации по связанным специальным темам
Создание комиксов
Вариант OpenClaw от Nvidia может решить самую серьезную проблему: безопасность
Генеральный директор Nvidia Дженсен Хуанг считает, что каждой компании нужна стратегия OpenClaw — и Nvidia готова ее предоставить.Во время своего выступления на конференции GTC в понедельник Хуанг объ
Пентагон заключил соглашения с Nvidia, Microsoft и AWS о внедрении технологий искусственного интеллекта в секретные сети.
После предыдущих соглашений с Google, SpaceX и OpenAI, Министерство обороны США в пятницу объявило о подписании договоров с Nvidia, Microsoft, Amazon Web Services и Reflection AI о использовании их технологий и моделей искусственного интеллекта в сек
На конференции Nvidia GTC представлены NemoClaw, робот Олаф и ставка на 1 триллион долларов
Загрузка плеера…Генеральный директор Дженсен Хуанг вышел на сцену на конференции Nvidia GTC на этой неделе в своей фирменной кожаной куртке, чтобы выступить с двухчасовой речью, в которой он прогнозир
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (1)
Комментарии (1)
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
Небольшие языковые модели набирают популярность. После дебюта модели искусственного зрения размером со смарт-часы от Liquid AI, созданной на базе технологий MIT, и предложения Google для смартфонов, Nvidia теперь выходит на сцену со своим собственным упрощенным конкурентом: Nemotron-Nano-9B-V2. Эта новая модель лидирует в своем классе по ключевым показателям и обладает уникальной функцией, которая позволяет пользователям включать или отключать «рассуждения» ИИ — по сути, процесс самопроверки перед предоставлением окончательного ответа.
Хотя 9 миллиардов параметров превышают масштаб микромоделей с миллионами параметров, о которых мы недавно сообщали, Nvidia подчеркивает, что это значительная оптимизация по сравнению с первоначальными 12 миллиардами параметров. Переработанный размер специально разработан для работы на одном широко доступном графическом процессоре Nvidia A10.
Как объяснил Олексий Кучиаев, директор Nvidia по пост-обучению моделей искусственного интеллекта, в ответ на вопрос о X: «Мы сократили модель с 12 миллиардов до 9 миллиардов, чтобы она идеально подходила для A10, популярного графического процессора для развертывания. Кроме того, это гибридная архитектура, которая позволяет обрабатывать более крупные пакеты данных и достигать скорости, в шесть раз превышающей скорость традиционных трансформаторных моделей аналогичного размера».
Для сравнения: многие ведущие большие языковые модели работают в диапазоне 70+ миллиардов параметров. Параметры — это внутренние настройки, которые определяют поведение модели, где более высокие значения обычно указывают на большие возможности, но также требуют значительно большей вычислительной мощности.
Модель поддерживает несколько языков, включая английский, немецкий, испанский, французский, итальянский и японский. Расширенные возможности также охватывают корейский, португальский, русский и китайский языки. Она хорошо подходит для задач, начиная от выполнения инструкций и заканчивая генерацией кода.
Nemotron-Nano-9B-V2 и ее предварительно обученные наборы данных в настоящее время доступны на Hugging Face и через собственный каталог моделей Nvidia.
Слияние архитектур Transformer и Mamba
Модель построена на основе Nemotron-H, семейства гибридных моделей Mamba-Transformer, которые служат основой для новейших продуктов Nvidia в области искусственного интеллекта.
Хотя доминирующие LLM обычно полагаются исключительно на архитектуру Transformer и ее механизмы внимания, они могут стать непомерно дорогостоящими с точки зрения памяти и вычислений по мере увеличения длины входных последовательностей.
Модели Nemotron-H и другие модели, использующие архитектуру Mamba, разработанную исследователями из Университета Карнеги-Меллона и Принстона, включают в себя модели выборочного пространства состояний (SSM). Эти SSM эффективно управляют чрезвычайно длинными последовательностями, поддерживая внутреннее состояние.
Эти слои масштабируются линейно по длине последовательности, что позволяет им обрабатывать гораздо более длинные контексты, чем стандартное самовнимание, без таких же вычислительных затрат.
Гибридная конструкция Mamba-Transformer снижает затраты за счет замены большинства слоев внимания слоями пространства состояний с линейным временем. Это может дать до 2–3 раз более высокую пропускную способность при выполнении задач с длинным контекстом при сохранении сопоставимой точности.
Nvidia не единственная компания, использующая этот подход; другие исследовательские лаборатории в области ИИ, такие как AI2, также выпустили модели, основанные на архитектуре Mamba.
Включение и выключение рассуждений с помощью простых команд
Nemotron-Nano-9B-v2 разработан как унифицированная текстовая модель, способная как к разговорному взаимодействию, так и к сложному рассуждению, обученная полностью с нуля.
По умолчанию система генерирует подробный отчет о рассуждениях, прежде чем дать окончательный ответ. Пользователи могут контролировать это поведение с помощью простых командных токенов, таких как /think или /no_think.
Модель также вводит управление «бюджетом мышления» во время выполнения. Это позволяет разработчикам устанавливать максимальный предел количества токенов, которые модель может использовать для внутреннего мышления, прежде чем она должна дать ответ.
Этот механизм предназначен для балансирования точности и задержки ответа, что имеет решающее значение для таких приложений, как чат-боты для поддержки клиентов или автономные агенты.
Бенчмарки показывают высокую производительность
Результаты оценки демонстрируют конкурентоспособную точность по сравнению с другими ведущими небольшими открытыми моделями. При тестировании с включенным рассуждением с использованием набора NeMo-Skills, Nemotron-Nano-9B-v2 достиг результатов 72,1% по AIME25, 97,8% по MATH500, 64,0% по GPQA и 71,1% по LiveCodeBench.
Результаты тестов на следование инструкциям и длинный контекст также высоки: 90,3% по IFEval и 78,9% по тесту RULER 128K, с дополнительными измеримыми улучшениями по BFCL v3 и тесту HLE.
В ходе нескольких оценок Nano-9B-v2 постоянно демонстрирует более высокую точность, чем обычная точка сравнения, модель Qwen3-8B.
Nvidia представляет эти результаты с помощью кривых «точность против бюджета», которые иллюстрируют, как производительность улучшается по мере увеличения количества токенов, выделенных для рассуждений. Компания отмечает, что тщательный контроль бюджета позволяет разработчикам оптимизировать как качество, так и скорость в производственных средах.
Обучение на синтетических наборах данных
Как модель Nano, так и более широкая семья Nemotron-H обучены на смеси тщательно отобранных веб-данных, проприетарных источников и синтетических обучающих данных.
Корпус обучения включает общий текст, код, математику, научную литературу, юридические и финансовые документы, а также наборы данных с вопросами и ответами, ориентированные на согласование.
Nvidia подтверждает использование синтетических следов рассуждений, сгенерированных другими крупными моделями, для повышения производительности при выполнении сложных тестовых задач.
Лицензирование и коммерческое использование
Модель Nano-9B-v2 выпускается в соответствии с лицензионным соглашением Nvidia Open Model License Agreement, которое в последний раз обновлялось в июне 2025 года.
Эта лицензия разработана с учетом требований разрешительности и удобства для предприятий. Nvidia прямо заявляет, что модели готовы к коммерческому использованию и что разработчики могут свободно создавать и распространять производные работы.
Важно отметить, что Nvidia не претендует на право собственности на любые результаты, сгенерированные моделью, оставляя все права и обязанности за разработчиком или организацией, использующей ее.
Для корпоративных разработчиков это означает, что модель может быть немедленно внедрена в производство без необходимости заключения отдельного коммерческого лицензионного соглашения или уплаты сборов в зависимости от объема использования, выручки или количества пользователей. В отличие от некоторых многоуровневых открытых лицензий других поставщиков, в соглашении нет положений, которые вступают в силу при достижении компанией определенного масштаба.
Тем не менее, соглашение содержит несколько важных условий, которые должны соблюдаться предприятиями:
- Ограждения: пользователи не могут обходить или отключать встроенные механизмы безопасности (называемые «ограждениями») без внедрения подходящих, эквивалентных заменителей для их конкретного развертывания.
- Перераспределение: любое перераспределение модели или ее производных должно включать полный текст лицензии Nvidia Open Model License и надлежащую атрибуцию («Лицензировано Nvidia Corporation в соответствии с лицензией Nvidia Open Model License»).
- Соблюдение: пользователи должны соблюдать все применимые торговые правила и ограничения, такие как законы США об экспортном контроле.
- Условия надежного ИИ: Использование должно соответствовать руководящим принципам Nvidia по надежному ИИ, которые охватывают принципы ответственного развертывания и этические соображения.
- Положение о судебных разбирательствах: лицензия автоматически прекращает свое действие, если пользователь инициирует судебное разбирательство по поводу авторских прав или патентов против другой стороны, утверждая, что имело место нарушение, связанное с моделью.
Эти условия направлены на обеспечение соблюдения законодательства и ответственного использования, а не на ограничение коммерческого масштаба. Предприятиям не нужно запрашивать дополнительное разрешение или платить роялти Nvidia за создание продуктов, монетизацию услуг или расширение базы пользователей. Вместо этого они должны обеспечить, чтобы их практики развертывания соответствовали требованиям безопасности, обеспечивали надлежащее указание авторства и соответствовали всем обязательствам по соблюдению законодательства.
Позиционирование на рынке
С Nemotron-Nano-9B-v2 Nvidia нацелена на разработчиков, которым необходимо сбалансировать возможности рассуждения и эффективность развертывания в меньших масштабах.
Функции контроля бюджета времени выполнения и переключения рассуждений призваны дать системным разработчикам большую гибкость в управлении компромиссом между точностью и скоростью отклика.
Их доступность в Hugging Face и каталоге моделей Nvidia сигнализирует о намерении обеспечить широкую доступность, поощряя эксперименты и интеграцию.
Выпуск Nvidia Nemotron-Nano-9B-v2 подчеркивает постоянное внимание компании к эффективности и контролируемому рассуждению в языковых моделях.
Объединяя гибридные архитектуры с передовыми технологиями сжатия и обучения, Nvidia стремится предоставить разработчикам инструменты, которые сохраняют высокую точность и одновременно снижают операционные затраты и задержки.










 Вариант OpenClaw от Nvidia может решить самую серьезную проблему: безопасность
Генеральный директор Nvidia Дженсен Хуанг считает, что каждой компании нужна стратегия OpenClaw — и Nvidia готова ее предоставить.Во время своего выступления на конференции GTC в понедельник Хуанг объ
Вариант OpenClaw от Nvidia может решить самую серьезную проблему: безопасность
Генеральный директор Nvidia Дженсен Хуанг считает, что каждой компании нужна стратегия OpenClaw — и Nvidia готова ее предоставить.Во время своего выступления на конференции GTC в понедельник Хуанг объ
 Пентагон заключил соглашения с Nvidia, Microsoft и AWS о внедрении технологий искусственного интеллекта в секретные сети.
После предыдущих соглашений с Google, SpaceX и OpenAI, Министерство обороны США в пятницу объявило о подписании договоров с Nvidia, Microsoft, Amazon Web Services и Reflection AI о использовании их технологий и моделей искусственного интеллекта в сек
Пентагон заключил соглашения с Nvidia, Microsoft и AWS о внедрении технологий искусственного интеллекта в секретные сети.
После предыдущих соглашений с Google, SpaceX и OpenAI, Министерство обороны США в пятницу объявило о подписании договоров с Nvidia, Microsoft, Amazon Web Services и Reflection AI о использовании их технологий и моделей искусственного интеллекта в сек
 На конференции Nvidia GTC представлены NemoClaw, робот Олаф и ставка на 1 триллион долларов
Загрузка плеера…Генеральный директор Дженсен Хуанг вышел на сцену на конференции Nvidia GTC на этой неделе в своей фирменной кожаной куртке, чтобы выступить с двухчасовой речью, в которой он прогнозир
На конференции Nvidia GTC представлены NemoClaw, робот Олаф и ставка на 1 триллион долларов
Загрузка плеера…Генеральный директор Дженсен Хуанг вышел на сцену на конференции Nvidia GTC на этой неделе в своей фирменной кожаной куртке, чтобы выступить с двухчасовой речью, в которой он прогнозир

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













