Les modèles de type ChatGPT sont désormais entraînés à mettre au jour le point de vue sous-jacent d'un article d'actualité, même lorsque celui-ci est dissimulé derrière des citations, un cadrage ou un vernis de neutralité (parfois hypocrite). En découpant les articles en segments tels que les titres, les chapeaux et les citations, un nouveau système apprend à identifier les biais, même dans les longs articles journalistiques professionnels.
La capacité à saisir la véritable position d'un auteur ou d'un orateur, connue dans la littérature académique sous le nom de « détection de position», relève l'un des défis les plus complexes de l'interprétation linguistique : discerner l'intention à partir d'un contenu qui peut être délibérément conçu pour la dissimuler ou la rendre obscure.
De « Une modeste proposition » de Jonathan Swift aux récentes performances politiques où les acteurs empruntent la rhétorique de leurs adversaires idéologiques, la surface d'une déclaration n'est plus un indicateur fiable de son intention. L'essor de l'ironie, du trolling, de la désinformation et de l'ambiguïté stratégique a rendu de plus en plus difficile de déterminer quel camp un texte soutient réellement, ou s'il prend parti.
Souvent, ce qui n'est pas dit a autant d'importance que ce qui est dit, et le simple fait de traiter un sujet peut révéler la position de l'auteur.
Cela rend la détection automatisée des positions particulièrement difficile, car un système efficace doit faire plus que simplement étiqueter des phrases individuelles comme « favorables » ou « opposées ». Il doit plutôt naviguer entre les différentes couches de sens, en évaluant les indices subtils par rapport au flux et à la direction générale de l'article, une tâche rendue plus difficile dans le journalisme de fond, où le ton peut changer et où les opinions sont rarement exprimées directement.
Agents du changement
Pour relever ces défis, des chercheurs sud-coréens ont mis au point un nouveau système appelé JOA-ICL (Journalism-guided Agentic In-Context Learning) afin de détecter la position des articles de presse longs.
L'idée centrale derrière JoA-ICL est que la position au niveau de l'article est déduite en agrégeant les prédictions au niveau des segments produites par un agent de modèle linguistique distinct. Source : https://arxiv.org/pdf/2507.11049
Plutôt que d'évaluer un article dans son ensemble, JOA-ICL le décompose en éléments structurels (titre, introduction, citations et conclusion) et attribue un modèle plus petit pour étiqueter chaque segment. Ces prédictions localisées sont ensuite transmises à un modèle plus large, qui les utilise pour déterminer la position générale de l'article.
La méthode a été testée sur un ensemble de données coréennes nouvellement compilé contenant 2 000 articles de presse annotés pour leur position au niveau de l'article et au niveau des segments. Chaque article a été étiqueté à partir des commentaires d'un expert en journalisme, reflétant la manière dont la position est répartie dans la structure de la rédaction professionnelle d'articles de presse.
Selon l'article, JOA-ICL surpasse les références basées sur les invites et les références affinées, et se montre particulièrement efficace pour détecter les positions favorables, une catégorie que les modèles similaires négligent souvent. Cette approche s'est également révélée efficace lorsqu'elle a été appliquée à un ensemble de données allemand dans des conditions comparables, ce qui suggère que ses principes peuvent s'appliquer à toutes les langues.
Les auteurs affirment :
« Les expériences montrent que JOA-ICL surpasse les méthodes existantes de détection de position, soulignant les avantages de l'agence au niveau des segments pour saisir la position globale des articles d'actualité longs. »
Le nouvel article, intitulé Journalism-Guided Agentic In-Context Learning for News Stance Detection (Apprentissage contextuel guidé par le journalisme pour la détection des positions dans les actualités), a été rédigé par plusieurs facultés de l'université Soongsil de Séoul, ainsi que par l'école supérieure de stratégie future du KAIST.
Méthode
Une partie du défi que représente la détection de position assistée par l'IA est d'ordre logistique et concerne la quantité d'informations qu'un système d'apprentissage automatique peut traiter et corréler à la fois, compte tenu des limites actuelles de la technologie de pointe.
Les articles d'actualité évitent souvent d'exprimer directement une opinion, s'appuyant plutôt sur une position implicite ou supposée, signalée par des choix tels que les sources à citer, la manière dont le récit est formulé et les détails qui sont omis.
Même lorsqu'un article adopte une position claire, le signal est souvent dispersé dans le texte, avec différents segments pointant dans différentes directions. Étant donné que les modèles linguistiques (LM) sont encore confrontés à des contraintes liées à des fenêtres contextuelles limitées, il leur est difficile d'évaluer la position de la même manière que pour des contenus plus courts, tels que les tweets ou les publications sur les réseaux sociaux, où la relation entre le texte et l'intention est plus explicite.
Par conséquent, les approches standard sont souvent insuffisantes lorsqu'elles sont appliquées à des articles journalistiques complets, où l'ambiguïté est souvent une caractéristique et non un défaut.
L'article indique :
« Pour relever ces défis, nous proposons une approche de modélisation hiérarchique qui consiste d'abord à déduire la position au niveau d'unités discursives plus petites (par exemple, des paragraphes ou des sections), puis à intégrer ces prédictions locales pour déterminer la position globale de l'article.
Ce cadre est conçu pour conserver le contexte local et saisir les indices de position dispersés afin d'évaluer comment les différentes parties d'un article contribuent à sa position globale sur une question. »
À cette fin, les auteurs ont compilé un nouvel ensemble de données appelé K-NEWS-STANCE, tiré de la couverture médiatique coréenne entre juin 2022 et juin 2024. Les articles ont d'abord été identifiés grâce à BigKinds, un service de métadonnées soutenu par le gouvernement et géré par la Korea Press Foundation, puis les textes complets ont été récupérés à l'aide de l'API de l'agrégateur Naver News. L'ensemble de données final comprenait 2 000 articles provenant de 31 médias, couvrant 47 questions d'intérêt national.
Chaque article a été annoté deux fois : une fois pour sa position générale sur une question donnée, et une autre fois pour des segments individuels, en particulier le titre, le chapeau, la conclusion et les citations directes.
L'annotation a été dirigée par l'expert en journalisme Jiyoung Han, troisième auteur de l'article, qui a guidé le processus en utilisant des repères établis issus des études sur les médias, tels que la sélection des sources, le cadrage lexical et les modèles de citation. Au total, 19 650 étiquettes de position au niveau des segments ont été obtenues.
Afin de s'assurer que les articles contenaient des signaux de point de vue significatifs, chacun a d'abord été classé par genre, et seuls ceux étiquetés comme analyse ou opinion, où le cadrage subjectif est plus probable, ont été utilisés pour l'annotation de la position.
Deux annotateurs formés ont étiqueté tous les articles et ont reçu pour instruction de consulter les articles connexes lorsque la position n'était pas claire. Les désaccords ont été résolus par la discussion et un examen supplémentaire.
Exemples d'entrées tirées de l'ensemble de données K-NEWS-STANCE, traduites en anglais. Seuls le titre, le chapeau et les citations sont affichés ; le corps du texte est omis. Les surlignages indiquent les étiquettes de position pour les citations, en bleu pour les citations favorables et en rouge pour les citations défavorables. Veuillez vous reporter au PDF source cité pour une interprétation plus claire.
JoA-ICL
Au lieu de traiter un article comme un bloc de texte unique, le système proposé le divise en plusieurs parties structurelles clés : titre, introduction, citations et conclusion. Chaque segment est attribué à un agent de modèle linguistique, qui le classe comme favorable, opposé ou neutre.
Ces prédictions locales sont ensuite transmises à un deuxième agent qui détermine la position globale de l'article. Les deux agents sont coordonnés par un contrôleur qui prépare les invites et recueille les résultats.
Ainsi, JoA-ICL adapte l'apprentissage contextuel (où le modèle apprend à partir d'exemples dans l'invite) pour s'aligner sur la structure de la rédaction professionnelle d'actualités, en utilisant des invites sensibles aux segments plutôt qu'une seule entrée générique.
(Veuillez noter que la plupart des exemples et illustrations présentés dans l'article sont longs et difficiles à reproduire de manière lisible dans un article en ligne. Nous encourageons donc les lecteurs à se référer au PDF original).
Données et tests
Lors des tests, les chercheurs ont utilisé la macro F1 et la précision pour évaluer les performances, en calculant la moyenne des résultats sur dix exécutions avec des graines aléatoires comprises entre 42 et 51 et en indiquant l'erreur type. Les données d'entraînement ont été utilisées pour affiner les modèles de base et les agents au niveau des segments, avec des échantillons few-shot sélectionnés par recherche de similarité à l'aide de KLUE-RoBERTa-large.
Les tests ont été réalisés sur trois GPU RTX A6000 (chacun avec 48 Go de VRAM), à l'aide de Python 3.9.19, PyTorch 2.5.1, Transformers 4.52.0 et vLLM 0.8.5.
GPT-4o-mini, Claude 3 Haiku et Gemini 2 Flash ont été utilisés via l'API, avec une température de 1,0 et un nombre maximal de jetons fixé à 1 000 pour les invites de chaîne de pensée, et à 100 pour les autres.
Pour le réglage fin complet d'Exaone-3.5-2.4B, l'optimiseur AdamW a été utilisé avec un taux d'apprentissage de 5e-5, une décroissance de poids de 0,01, 100 étapes de préchauffage et un entraînement pendant 10 époques avec une taille de lot de 6.
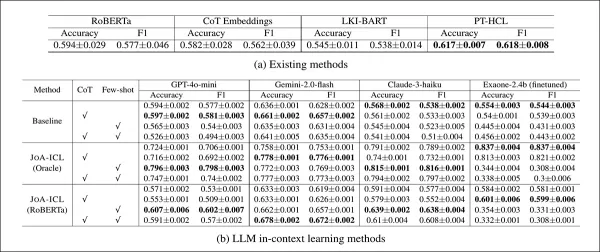
Pour les références, les auteurs ont utilisé RoBERTa, ajusté pour la détection de position au niveau des articles ; Chain-of-Thought (CoT) Embeddings, un autre réglage de RoBERTa pour la tâche assignée ; LKI-BART, un modèle encodeur-décodeur qui intègre les connaissances contextuelles d'un grand modèle linguistique en lui fournissant à la fois le texte d'entrée et les étiquettes de position souhaitées ; et PT-HCL, une méthode qui utilise l'apprentissage contrastif pour séparer les caractéristiques générales de celles spécifiques à la question cible :
Performances de chaque modèle sur l'ensemble de test K-NEWS-STANCE pour la prédiction globale de la position. Les résultats sont présentés sous forme de macro F1 et de précision, le score le plus élevé de chaque groupe étant indiqué en gras.
JOA-ICL a obtenu les meilleures performances globales en termes de précision et de macro F1, un avantage observé pour les trois modèles testés : GPT-4o-mini, Claude 3 Haiku et Gemini 2 Flash.
La méthode basée sur les segments a systématiquement surpassé toutes les autres approches, les auteurs soulignant une force particulière dans la détection des positions favorables, une faiblesse courante dans les modèles similaires.
Les modèles de référence ont obtenu des résultats globalement moins bons. Les variantes RoBERTa et Chain-of-Thought ont eu du mal avec les cas nuancés, tandis que PT-HCL et LKI-BART ont obtenu de meilleurs résultats, mais sont restés derrière JOA-ICL dans la plupart des catégories. Le résultat le plus précis a été obtenu par JOA-ICL (Claude), avec un macro F1 de 64,8 % et une précision de 66,1 %.
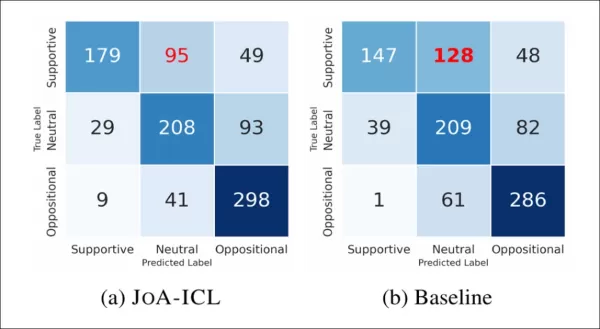
L'image ci-dessous montre la fréquence à laquelle les modèles ont correctement ou incorrectement identifié chaque étiquette :
Les matrices de confusion comparant la référence et JoA-ICL montrent que les deux méthodes ont le plus de mal à détecter les positions « favorables ».
JoA-ICL a obtenu de meilleurs résultats globaux que la référence, identifiant correctement plus d'étiquettes dans chaque catégorie. Cependant, les deux modèles ont eu le plus de difficultés avec les articles favorables, et la référence en a mal classé près de la moitié, les étiquetant souvent comme neutres.
JoA-ICL a commis moins d'erreurs, mais a suivi le même schéma, ce qui confirme que les positions « positives » sont plus difficiles à détecter pour les modèles.
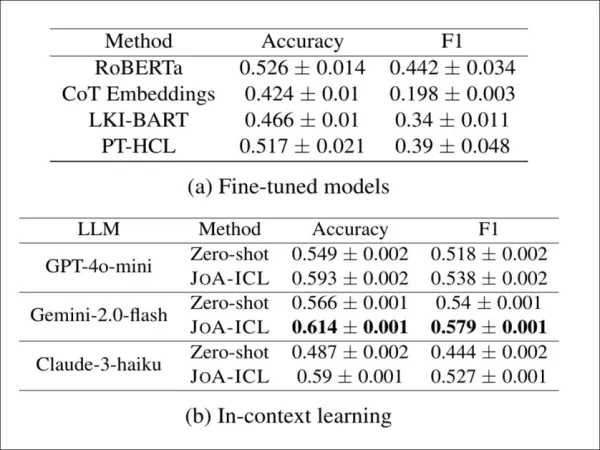
Afin de vérifier si JoA-ICL fonctionne au-delà de la langue coréenne, les auteurs l'ont appliqué à CheeSE, un ensemble de données allemand pour la détection des positions au niveau des articles. Comme CheeSE ne dispose pas d'étiquettes au niveau des segments, les chercheurs ont utilisé la supervision distante, attribuant à chaque segment la même étiquette de position que l'article complet.
Résultats de la détection des positions sur l'ensemble de données CheeSE en allemand. JoA-ICL s'améliore constamment par rapport à la saisie instantanée sur les trois LLM et surpasse les références affinées, Gemini-2.0-flash offrant les meilleures performances globales.
Même dans ces conditions « bruitées », JoA-ICL a surpassé les modèles affinés et le prompting zéro-shot. Parmi les trois backbones testés, Gemini-2.0-flash a obtenu les meilleurs résultats.
Conclusion
Peu de tâches dans le domaine de l'apprentissage automatique sont aussi sensibles sur le plan politique que la prédiction des positions, mais elles sont souvent abordées en termes techniques et mécaniques. Parallèlement, les questions moins complexes liées à l'IA générative, telles que la création de vidéos et d'images, ont tendance à attirer davantage l'attention et à faire les gros titres.
L'aspect le plus encourageant de cette nouvelle recherche coréenne est sa contribution à l'analyse de contenus complets, plutôt que de tweets et de publications courtes sur les réseaux sociaux, dont l'impact est souvent plus éphémère que celui d'un traité, d'un essai ou d'autres travaux substantiels.
Une lacune notable dans cette étude, et plus largement dans la littérature sur la prédiction des positions, est le manque de prise en compte des hyperliens, qui servent souvent de ressources optionnelles permettant aux lecteurs d'approfondir un sujet. Or, la sélection de ces URL peut être très subjective, voire politiquement chargée.
Cela dit, plus une publication est prestigieuse, moins elle est susceptible d'inclure des liens qui éloignent les lecteurs de son propre domaine. Ceci, ajouté aux diverses utilisations et abus des hyperliens liés au référencement naturel (SEO), les rend plus difficiles à quantifier que les citations explicites, les titres ou d'autres éléments susceptibles d'influencer consciemment ou inconsciemment l'opinion du lecteur.
Publié pour la première fois le mercredi 16 juillet 2025
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
En cliquant sur "Accepter tous les cookies", vous consentez au stockage de cookies sur votre appareil afin d’améliorer la navigation sur le site, d’analyser l’utilisation du site et de soutenir nos efforts marketing.Politique de confidentialité Avis
Lorsque vous visitez un site web, il peut stocker ou récupérer des informations sur votre navigateur, principalement sous forme de cookies. Ces informations peuvent concerner vous, vos préférences ou votre appareil et sont principalement utilisées pour faire fonctionner le site comme vous vous y attendez. Ces informations n’identifient généralement pas directement vous-même, mais elles peuvent vous offrir une expérience web plus personnalisée. Parce que nous respectons votre droit à la vie privée, vous pouvez choisir de ne pas autoriser certains types de cookies. Cliquez sur les différents titres de catégorie pour en savoir plus et modifier nos paramètres par défaut. Cependant, bloquer certains types de cookies peut affecter votre expérience sur le site et les services que nous sommes en mesure de proposer. Politique de confidentialitéDéclaration
Gérer les préférences
Cookie strictement nécessaire
Toujours actif
Ces cookies sont nécessaires au fonctionnement du site web et ne peuvent pas être désactivés dans nos systèmes. Ils ne sont généralement définis qu’en réponse à des actions que vous effectuez qui équivalent à une demande de services, telles que la configuration de vos préférences de confidentialité, la connexion ou le remplissage de formulaires. Vous pouvez configurer votre navigateur pour bloquer ces cookies ou vous alerter à leur sujet, mais certaines parties du site ne fonctionneront alors plus. Ces cookies ne stockent aucune information permettant d’identifier personnellement.

















 Maison
Maison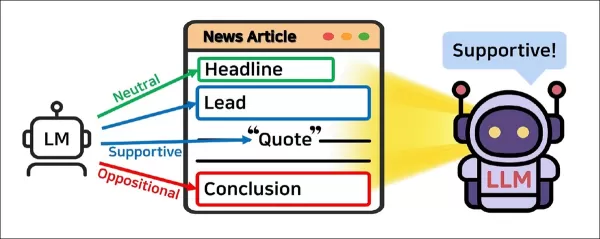

 Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
 Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
 10 outils
10 outils
 xix.ai
code
xix.ai
code

 commentaires (0)
commentaires (0)















 Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
 Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour
Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour
 OpenAI conservera les données du ChatGPT en vertu d'une décision de justice, le PDG Altman propose un "privilège de l'IA".
De nombreux utilisateurs réguliers de ChatGPT, dont l'auteur de cet article, ont peut-être eu recours à la fonction de "chat temporaire". Cette option, offerte par le populaire chatbot d'OpenAI, est c
OpenAI conservera les données du ChatGPT en vertu d'une décision de justice, le PDG Altman propose un "privilège de l'IA".
De nombreux utilisateurs réguliers de ChatGPT, dont l'auteur de cet article, ont peut-être eu recours à la fonction de "chat temporaire". Cette option, offerte par le populaire chatbot d'OpenAI, est c



















