
















 Lar
LarEstudo da Microsoft Revela Limitações de Modelos de IA na Depuração de Software
Modelos de IA da OpenAI, Anthropic e outros laboratórios de IA líderes estão sendo cada vez mais utilizados para tarefas de codificação. O CEO da Google, Sundar Pichai, observou em outubro que a IA gera 25% do novo código na empresa, enquanto o CEO da Meta, Mark Zuckerberg, pretende implementar amplamente ferramentas de codificação por IA na gigante das redes sociais.
No entanto, mesmo os modelos de melhor desempenho têm dificuldades para corrigir bugs de software que desenvolvedores experientes lidam com facilidade.
Um recente estudo da Microsoft Research, conduzido pela divisão de P&D da Microsoft, mostra que modelos como o Claude 3.7 Sonnet da Anthropic e o o3-mini da OpenAI têm dificuldades para resolver muitos problemas no benchmark de desenvolvimento de software SWE-bench Lite. As descobertas destacam que, apesar das afirmações ambiciosas de empresas como a OpenAI, a IA ainda fica aquém da expertise humana em áreas como codificação.
Os pesquisadores do estudo testaram nove modelos como base para um “agente baseado em prompt único” equipado com ferramentas de depuração, incluindo um depurador Python. O agente foi encarregado de abordar 300 desafios de depuração de software selecionados do SWE-bench Lite.
Os resultados mostraram que, mesmo com modelos avançados, o agente raramente resolveu mais da metade das tarefas com sucesso. O Claude 3.7 Sonnet liderou com uma taxa de sucesso de 48,4%, seguido pelo o1 da OpenAI com 30,2% e o o3-mini com 22,1%.
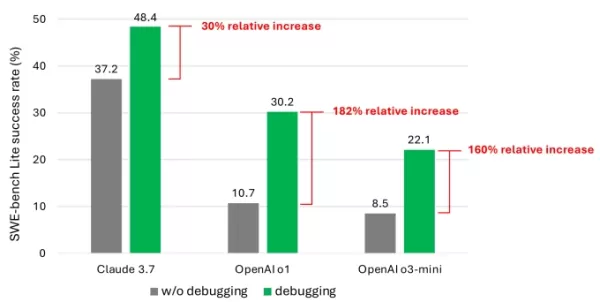
Um gráfico do estudo mostrando o aumento de desempenho que os modelos obtiveram com ferramentas de depuração. Créditos da imagem: Microsoft O que explica os resultados decepcionantes? Alguns modelos tiveram dificuldades para usar efetivamente as ferramentas de depuração disponíveis ou identificar quais ferramentas eram adequadas para problemas específicos. O principal problema, segundo os pesquisadores, foi a falta de dados de treinamento suficientes, particularmente dados que capturam “processos de tomada de decisão sequencial” como rastros de depuração humana.
“Acreditamos que treinar ou ajustar esses modelos pode melhorar suas capacidades de depuração”, escreveram os pesquisadores. “No entanto, isso requer dados especializados, como dados de trajetória que capturam agentes interagindo com um depurador para coletar informações antes de propor correções.”
Participe das Sessões TechCrunch: IA
Reserve seu lugar em nosso principal evento da indústria de IA, com palestrantes da OpenAI, Anthropic e Cohere. Por tempo limitado, os ingressos custam apenas $292 para um dia inteiro de palestras de especialistas, workshops e oportunidades de networking.
Exiba no TechCrunch Sessions: IA
Reserve seu espaço no TC Sessions: IA para apresentar seu trabalho a mais de 1.200 tomadores de decisão. Oportunidades de exposição estão disponíveis até 9 de maio ou até que as mesas estejam totalmente reservadas.
As descobertas não são surpreendentes. Numerosos estudos mostraram que o código gerado por IA frequentemente introduz falhas de segurança e erros devido a fraquezas na compreensão da lógica de programação. Um teste recente do Devin, uma conhecida ferramenta de codificação por IA, revelou que ela só conseguiu completar três de 20 tarefas de programação.
O estudo da Microsoft oferece uma das análises mais aprofundadas desse desafio contínuo para modelos de IA. Embora seja improvável que isso reduza o interesse dos investidores em ferramentas de codificação alimentadas por IA, pode levar desenvolvedores e seus líderes a reconsiderarem a dependência excessiva em IA para tarefas de codificação.
Notavelmente, vários líderes de tecnologia refutaram a ideia de que a IA eliminará empregos de codificação. O cofundador da Microsoft, Bill Gates, o CEO da Replit, Amjad Masad, o CEO da Okta, Todd McKinnon, e o CEO da IBM, Arvind Krishna, expressaram confiança de que a programação como profissão perdurará.
Artigo relacionado
 A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
Recomendações de tópicos especiais relacionados
Educação e Aprendizagem
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
Recomendações de tópicos especiais relacionados
Educação e Aprendizagem
 Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai
Análise de dados
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai
Mídias Sociais
Kits de identidade visual com IA para redes sociais: mantenha a identidade visual da marca consistente em todos os canais
Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores aplicativos de namoradas virtuais com IA e ferramentas de companhia com IA para jogos de interpretação (Guia de 2026)
Descubra as melhores ferramentas de IA para companhia de 2026, idealizadas para uma experiência imersiva de interpretação de papéis e conexão. O guia selecionado pela XIX.AI apresenta aplicativos poderosos e revolucionários, com rankings atualizados semanalmente, comparações entre versões gratuitas e pagas e testes práticos. Encontre a sua combinação perfeita e desfrute hoje mesmo de uma companhia digital significativa.
10 ferramentas
xix.ai

 Comentários (6)
Comentários (6)
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
Modelos de IA da OpenAI, Anthropic e outros laboratórios de IA líderes estão sendo cada vez mais utilizados para tarefas de codificação. O CEO da Google, Sundar Pichai, observou em outubro que a IA gera 25% do novo código na empresa, enquanto o CEO da Meta, Mark Zuckerberg, pretende implementar amplamente ferramentas de codificação por IA na gigante das redes sociais.
No entanto, mesmo os modelos de melhor desempenho têm dificuldades para corrigir bugs de software que desenvolvedores experientes lidam com facilidade.
Um recente estudo da Microsoft Research, conduzido pela divisão de P&D da Microsoft, mostra que modelos como o Claude 3.7 Sonnet da Anthropic e o o3-mini da OpenAI têm dificuldades para resolver muitos problemas no benchmark de desenvolvimento de software SWE-bench Lite. As descobertas destacam que, apesar das afirmações ambiciosas de empresas como a OpenAI, a IA ainda fica aquém da expertise humana em áreas como codificação.
Os pesquisadores do estudo testaram nove modelos como base para um “agente baseado em prompt único” equipado com ferramentas de depuração, incluindo um depurador Python. O agente foi encarregado de abordar 300 desafios de depuração de software selecionados do SWE-bench Lite.
Os resultados mostraram que, mesmo com modelos avançados, o agente raramente resolveu mais da metade das tarefas com sucesso. O Claude 3.7 Sonnet liderou com uma taxa de sucesso de 48,4%, seguido pelo o1 da OpenAI com 30,2% e o o3-mini com 22,1%.
O que explica os resultados decepcionantes? Alguns modelos tiveram dificuldades para usar efetivamente as ferramentas de depuração disponíveis ou identificar quais ferramentas eram adequadas para problemas específicos. O principal problema, segundo os pesquisadores, foi a falta de dados de treinamento suficientes, particularmente dados que capturam “processos de tomada de decisão sequencial” como rastros de depuração humana.
“Acreditamos que treinar ou ajustar esses modelos pode melhorar suas capacidades de depuração”, escreveram os pesquisadores. “No entanto, isso requer dados especializados, como dados de trajetória que capturam agentes interagindo com um depurador para coletar informações antes de propor correções.”
Participe das Sessões TechCrunch: IA
Reserve seu lugar em nosso principal evento da indústria de IA, com palestrantes da OpenAI, Anthropic e Cohere. Por tempo limitado, os ingressos custam apenas $292 para um dia inteiro de palestras de especialistas, workshops e oportunidades de networking.
Exiba no TechCrunch Sessions: IA
Reserve seu espaço no TC Sessions: IA para apresentar seu trabalho a mais de 1.200 tomadores de decisão. Oportunidades de exposição estão disponíveis até 9 de maio ou até que as mesas estejam totalmente reservadas.
As descobertas não são surpreendentes. Numerosos estudos mostraram que o código gerado por IA frequentemente introduz falhas de segurança e erros devido a fraquezas na compreensão da lógica de programação. Um teste recente do Devin, uma conhecida ferramenta de codificação por IA, revelou que ela só conseguiu completar três de 20 tarefas de programação.
O estudo da Microsoft oferece uma das análises mais aprofundadas desse desafio contínuo para modelos de IA. Embora seja improvável que isso reduza o interesse dos investidores em ferramentas de codificação alimentadas por IA, pode levar desenvolvedores e seus líderes a reconsiderarem a dependência excessiva em IA para tarefas de codificação.
Notavelmente, vários líderes de tecnologia refutaram a ideia de que a IA eliminará empregos de codificação. O cofundador da Microsoft, Bill Gates, o CEO da Replit, Amjad Masad, o CEO da Okta, Todd McKinnon, e o CEO da IBM, Arvind Krishna, expressaram confiança de que a programação como profissão perdurará.









 A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
 Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
 O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de IA para companhia de 2026, idealizadas para uma experiência imersiva de interpretação de papéis e conexão. O guia selecionado pela XIX.AI apresenta aplicativos poderosos e revolucionários, com rankings atualizados semanalmente, comparações entre versões gratuitas e pagas e testes práticos. Encontre a sua combinação perfeita e desfrute hoje mesmo de uma companhia digital significativa.
10 ferramentas
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













