
















 Maison
Maison
Meta défend la version Llama 4, cite les bogues comme cause de rapports de qualité mixte
Durant le week-end, Meta, la puissance derrière Facebook, Instagram, WhatsApp et Quest VR, a surpris tout le monde en dévoilant son dernier modèle de langage AI, Llama 4. Pas un, mais trois nouvelles versions ont été présentées, chacune dotée de capacités améliorées grâce à l'architecture "Mixture-of-Experts" et une nouvelle approche d'entraînement appelée MetaP, impliquant des hyperparamètres fixes. De plus, les trois modèles offrent des fenêtres de contexte étendues, leur permettant de traiter plus d'informations en une seule interaction.
Malgré l'enthousiasme de la sortie, la réaction de la communauté AI a été au mieux tiède. Samedi, Meta a rendu deux de ces modèles, Llama 4 Scout et Llama 4 Maverick, disponibles au téléchargement et à l'utilisation, mais la réponse a été loin d'être enthousiaste.
Llama 4 suscite confusion et critiques parmi les utilisateurs AI
Un message non vérifié sur le forum 1point3acres, une communauté populaire de langue chinoise en Amérique du Nord, a trouvé son chemin vers le subreddit r/LocalLlama sur Reddit. Le message, prétendument d'un chercheur de l'organisation GenAI de Meta, affirmait que Llama 4 sous-performait sur des benchmarks tiers internes. Il suggérait que la direction de Meta avait manipulé les résultats en mélangeant les ensembles de tests pendant l'entraînement pour atteindre divers indicateurs et présenter un résultat favorable. L'authenticité de cette affirmation a été accueillie avec scepticisme, et Meta n'a pas encore répondu aux demandes de VentureBeat.
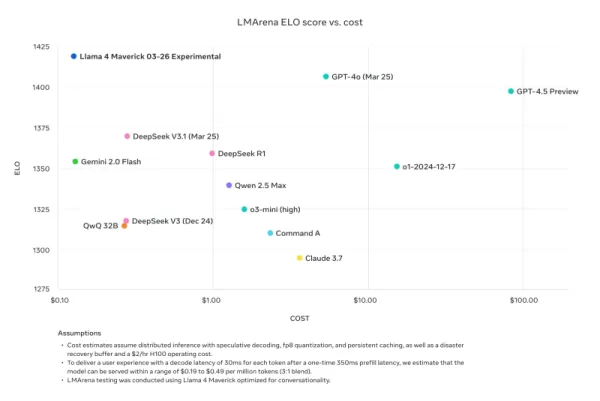
Cependant, les doutes sur les performances de Llama 4 ne s'arrêtent pas là. Sur X, l'utilisateur @cto_junior a exprimé son incrédulité face aux performances du modèle, citant un test indépendant où Llama 4 Maverick a obtenu seulement 16 % sur le benchmark polyglot aider, qui teste les tâches de codage. Ce score est nettement inférieur à celui de modèles plus anciens de taille similaire comme DeepSeek V3 et Claude 3.7 Sonnet.
Le docteur en AI et auteur Andriy Burkov a également pris la parole sur X pour remettre en question la fenêtre de contexte annoncée de 10 millions de tokens pour Llama 4 Scout, déclarant qu'elle est "virtuelle" car le modèle n'a pas été entraîné sur des prompts dépassant 256k tokens. Il a averti que l'envoi de prompts plus longs entraînerait probablement des sorties de faible qualité.
Sur le subreddit r/LocalLlama, l'utilisateur Dr_Karminski a partagé sa déception envers Llama 4, comparant ses mauvaises performances à celles du modèle non-raisonnant V3 de DeepSeek sur des tâches comme la simulation de mouvements de balle dans un heptagone.
Nathan Lambert, ancien chercheur chez Meta et actuel scientifique senior chez AI2, a critiqué les comparaisons de benchmarks de Meta sur son blog Interconnects Substack. Il a souligné que le modèle Llama 4 Maverick utilisé dans les supports promotionnels de Meta était différent de celui publié publiquement, optimisé plutôt pour la conversation. Lambert a noté l'écart, disant : "Sournois. Les résultats ci-dessous sont faux, et c'est une grave offense à la communauté de Meta de ne pas publier le modèle utilisé pour leur grande campagne marketing." Il a ajouté que bien que le modèle promotionnel "nuise à la réputation technique de la sortie car son caractère est juvénile", le modèle réellement disponible sur d'autres plateformes était "assez intelligent et a un ton raisonnable."
Meta répond, niant l'entraînement sur les ensembles de tests et citant des bugs dans l'implémentation en raison d'un déploiement rapide
En réponse aux critiques et accusations, le vice-président et chef de GenAI de Meta, Ahmad Al-Dahle, s'est exprimé sur X pour répondre aux préoccupations. Il a exprimé son enthousiasme pour l'engagement de la communauté avec Llama 4 mais a reconnu des rapports de qualité incohérente à travers différents services. Il a attribué ces problèmes au déploiement rapide et au temps nécessaire pour stabiliser les implémentations publiques. Al-Dahle a fermement nié les allégations d'entraînement sur les ensembles de tests, soulignant que la qualité variable était due à des bugs d'implémentation plutôt qu'à une inconduite. Il a réaffirmé la croyance de Meta dans les avancées significatives des modèles Llama 4 et leur engagement à travailler avec la communauté pour réaliser leur potentiel.
Cependant, la réponse n'a pas suffi à apaiser les frustrations de la communauté, beaucoup signalant encore de mauvaises performances et exigeant plus de documentation technique sur les processus d'entraînement des modèles. Cette sortie a rencontré plus de problèmes que les versions précédentes de Llama, soulevant des questions sur son développement et son déploiement.
Le timing de cette sortie est notable, car elle suit le départ de Joelle Pineau, vice-présidente de la recherche chez Meta, qui a annoncé son départ sur LinkedIn la semaine dernière avec gratitude pour son temps dans l'entreprise. Pineau avait également promu la famille de modèles Llama 4 pendant le week-end.
Alors que Llama 4 continue d'être adopté par d'autres fournisseurs d'inférence avec des résultats mitigés, il est clair que la sortie initiale n'a pas été le succès espéré par Meta. La prochaine Meta LlamaCon, le 29 avril, qui sera le premier rassemblement pour les développeurs tiers de la famille de modèles, risque d'être un foyer de discussions et de débats. Nous suivrons de près les développements, alors restez à l'écoute.
Article connexe
 Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
Meta signe un contrat portant sur plusieurs millions de processeurs IA d'Amazon
Amazon a conclu un partenariat majeur avec Meta, en s'appuyant une nouvelle fois sur ses propres puces conçues sur mesure. Meta a accepté de déployer des millions de puces AWS Graviton pour répondre à
L'essor du gaz naturel chez Meta pourrait alimenter le réseau électrique du Dakota du Sud
Les centres de données ont pris une telle ampleur que leur consommation d'électricité équivaut désormais à celle de certains États américains. Prenons l'exemple du centre de données Hyperion AI de Met
Recommandations de sujets spéciaux liés
Création de bande dessinée
Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
Meta signe un contrat portant sur plusieurs millions de processeurs IA d'Amazon
Amazon a conclu un partenariat majeur avec Meta, en s'appuyant une nouvelle fois sur ses propres puces conçues sur mesure. Meta a accepté de déployer des millions de puces AWS Graviton pour répondre à
L'essor du gaz naturel chez Meta pourrait alimenter le réseau électrique du Dakota du Sud
Les centres de données ont pris une telle ampleur que leur consommation d'électricité équivaut désormais à celle de certains États américains. Prenons l'exemple du centre de données Hyperion AI de Met
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (11)
commentaires (11)
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
Durant le week-end, Meta, la puissance derrière Facebook, Instagram, WhatsApp et Quest VR, a surpris tout le monde en dévoilant son dernier modèle de langage AI, Llama 4. Pas un, mais trois nouvelles versions ont été présentées, chacune dotée de capacités améliorées grâce à l'architecture "Mixture-of-Experts" et une nouvelle approche d'entraînement appelée MetaP, impliquant des hyperparamètres fixes. De plus, les trois modèles offrent des fenêtres de contexte étendues, leur permettant de traiter plus d'informations en une seule interaction.
Malgré l'enthousiasme de la sortie, la réaction de la communauté AI a été au mieux tiède. Samedi, Meta a rendu deux de ces modèles, Llama 4 Scout et Llama 4 Maverick, disponibles au téléchargement et à l'utilisation, mais la réponse a été loin d'être enthousiaste.
Llama 4 suscite confusion et critiques parmi les utilisateurs AI
Un message non vérifié sur le forum 1point3acres, une communauté populaire de langue chinoise en Amérique du Nord, a trouvé son chemin vers le subreddit r/LocalLlama sur Reddit. Le message, prétendument d'un chercheur de l'organisation GenAI de Meta, affirmait que Llama 4 sous-performait sur des benchmarks tiers internes. Il suggérait que la direction de Meta avait manipulé les résultats en mélangeant les ensembles de tests pendant l'entraînement pour atteindre divers indicateurs et présenter un résultat favorable. L'authenticité de cette affirmation a été accueillie avec scepticisme, et Meta n'a pas encore répondu aux demandes de VentureBeat.
Cependant, les doutes sur les performances de Llama 4 ne s'arrêtent pas là. Sur X, l'utilisateur @cto_junior a exprimé son incrédulité face aux performances du modèle, citant un test indépendant où Llama 4 Maverick a obtenu seulement 16 % sur le benchmark polyglot aider, qui teste les tâches de codage. Ce score est nettement inférieur à celui de modèles plus anciens de taille similaire comme DeepSeek V3 et Claude 3.7 Sonnet.
Le docteur en AI et auteur Andriy Burkov a également pris la parole sur X pour remettre en question la fenêtre de contexte annoncée de 10 millions de tokens pour Llama 4 Scout, déclarant qu'elle est "virtuelle" car le modèle n'a pas été entraîné sur des prompts dépassant 256k tokens. Il a averti que l'envoi de prompts plus longs entraînerait probablement des sorties de faible qualité.
Sur le subreddit r/LocalLlama, l'utilisateur Dr_Karminski a partagé sa déception envers Llama 4, comparant ses mauvaises performances à celles du modèle non-raisonnant V3 de DeepSeek sur des tâches comme la simulation de mouvements de balle dans un heptagone.
Nathan Lambert, ancien chercheur chez Meta et actuel scientifique senior chez AI2, a critiqué les comparaisons de benchmarks de Meta sur son blog Interconnects Substack. Il a souligné que le modèle Llama 4 Maverick utilisé dans les supports promotionnels de Meta était différent de celui publié publiquement, optimisé plutôt pour la conversation. Lambert a noté l'écart, disant : "Sournois. Les résultats ci-dessous sont faux, et c'est une grave offense à la communauté de Meta de ne pas publier le modèle utilisé pour leur grande campagne marketing." Il a ajouté que bien que le modèle promotionnel "nuise à la réputation technique de la sortie car son caractère est juvénile", le modèle réellement disponible sur d'autres plateformes était "assez intelligent et a un ton raisonnable."
Meta répond, niant l'entraînement sur les ensembles de tests et citant des bugs dans l'implémentation en raison d'un déploiement rapide
En réponse aux critiques et accusations, le vice-président et chef de GenAI de Meta, Ahmad Al-Dahle, s'est exprimé sur X pour répondre aux préoccupations. Il a exprimé son enthousiasme pour l'engagement de la communauté avec Llama 4 mais a reconnu des rapports de qualité incohérente à travers différents services. Il a attribué ces problèmes au déploiement rapide et au temps nécessaire pour stabiliser les implémentations publiques. Al-Dahle a fermement nié les allégations d'entraînement sur les ensembles de tests, soulignant que la qualité variable était due à des bugs d'implémentation plutôt qu'à une inconduite. Il a réaffirmé la croyance de Meta dans les avancées significatives des modèles Llama 4 et leur engagement à travailler avec la communauté pour réaliser leur potentiel.
Cependant, la réponse n'a pas suffi à apaiser les frustrations de la communauté, beaucoup signalant encore de mauvaises performances et exigeant plus de documentation technique sur les processus d'entraînement des modèles. Cette sortie a rencontré plus de problèmes que les versions précédentes de Llama, soulevant des questions sur son développement et son déploiement.
Le timing de cette sortie est notable, car elle suit le départ de Joelle Pineau, vice-présidente de la recherche chez Meta, qui a annoncé son départ sur LinkedIn la semaine dernière avec gratitude pour son temps dans l'entreprise. Pineau avait également promu la famille de modèles Llama 4 pendant le week-end.
Alors que Llama 4 continue d'être adopté par d'autres fournisseurs d'inférence avec des résultats mitigés, il est clair que la sortie initiale n'a pas été le succès espéré par Meta. La prochaine Meta LlamaCon, le 29 avril, qui sera le premier rassemblement pour les développeurs tiers de la famille de modèles, risque d'être un foyer de discussions et de débats. Nous suivrons de près les développements, alors restez à l'écoute.










 Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
 Meta signe un contrat portant sur plusieurs millions de processeurs IA d'Amazon
Amazon a conclu un partenariat majeur avec Meta, en s'appuyant une nouvelle fois sur ses propres puces conçues sur mesure. Meta a accepté de déployer des millions de puces AWS Graviton pour répondre à
Meta signe un contrat portant sur plusieurs millions de processeurs IA d'Amazon
Amazon a conclu un partenariat majeur avec Meta, en s'appuyant une nouvelle fois sur ses propres puces conçues sur mesure. Meta a accepté de déployer des millions de puces AWS Graviton pour répondre à
 L'essor du gaz naturel chez Meta pourrait alimenter le réseau électrique du Dakota du Sud
Les centres de données ont pris une telle ampleur que leur consommation d'électricité équivaut désormais à celle de certains États américains. Prenons l'exemple du centre de données Hyperion AI de Met
L'essor du gaz naturel chez Meta pourrait alimenter le réseau électrique du Dakota du Sud
Les centres de données ont pris une telle ampleur que leur consommation d'électricité équivaut désormais à celle de certains États américains. Prenons l'exemple du centre de données Hyperion AI de Met

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













