
















 집
집메타는 LLAMA 4 릴리스를 방어하고 혼합 품질 보고서의 원인으로 버그를 인용합니다.
주말 동안 페이스북, 인스타그램, 왓츠앱, 퀘스트 VR을 이끄는 메타가 최신 AI 언어 모델 라마 4를 공개하며 모두를 놀라게 했다. 하나가 아닌 세 가지 새로운 버전이 소개되었으며, 각 버전은 "Mixture-of-Experts" 아키텍처와 고정 하이퍼파라미터를 사용하는 새로운 훈련 방식인 MetaP 덕분에 향상된 기능을 자랑한다. 더욱이, 세 모델 모두 광범위한 컨텍스트 윈도우를 제공하여 단일 상호작용에서 더 많은 정보를 처리할 수 있다.
출시의 흥분에도 불구하고 AI 커뮤니티의 반응은 미지근했다. 토요일, 메타는 라마 4 스카우트와 라마 4 매버릭 두 모델을 다운로드 및 사용 가능하게 했으나, 반응은 열광적이지 않았다.
라마 4, AI 사용자들 사이에서 혼란과 비판 불러일으켜
북아메리카의 인기 중국어 커뮤니티 1point3acres 포럼에 올라온 검증되지 않은 게시물이 레딧의 r/LocalLlama 서브레딧에 퍼졌다. 메타의 GenAI 조직 연구원으로 추정되는 이 게시물은 라마 4가 내부 타사 벤치마크에서 저조한 성능을 보였다고 주장했다. 이는 메타의 리더십이 사후 훈련 중 테스트 세트를 혼합하여 다양한 메트릭을 충족하고 유리한 결과를 제시했다고 암시했다. 이 주장의 진위 여부는 회의적인 반응을 얻었으며, 메타는 VentureBeat의 문의에 아직 응답하지 않았다.
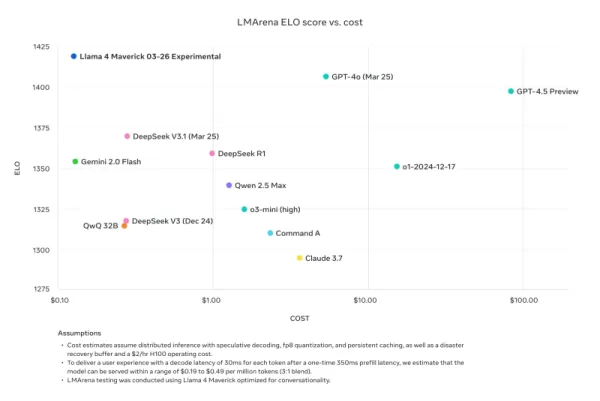
하지만 라마 4의 성능에 대한 의구심은 여기서 그치지 않았다. X에서 사용자 @cto_junior는 모델의 성능에 대한 불신을 표하며, 라마 4 매버릭이 코딩 작업을 테스트하는 aider 폴리글롯 벤치마크에서 16%라는 낮은 점수를 기록했다고 밝혔다. 이 점수는 DeepSeek V3나 Claude 3.7 Sonnet 같은 비슷한 크기의 구형 모델보다 훨씬 낮다.
AI 박사이자 작가인 Andriy Burkov도 X에서 라마 4 스카우트의 광고된 1000만 토큰 컨텍스트 윈도우에 의문을 제기하며, 모델이 256k 토큰 이상의 프롬프트로 훈련되지 않았기 때문에 "가상"이라고 말했다. 그는 더 긴 프롬프트를 보내면 낮은 품질의 출력이 나올 가능성이 높다고 경고했다.
r/LocalLlama 서브레딧에서 사용자 Dr_Karminski는 라마 4의 성능에 실망을 표하며, 칠각형 내 공의 움직임을 시뮬레이션하는 작업에서 DeepSeek의 비추론 V3 모델과 비교해 저조한 성능을 보였다고 전했다.
전 메타 연구원이자 현재 AI2의 선임 연구원인 Nathan Lambert는 자신의 Interconnects Substack 블로그에서 메타의 벤치마크 비교를 비판했다. 그는 메타의 홍보 자료에 사용된 라마 4 매버릭 모델이 공개된 모델과 달리 대화성에 최적화되었다고 지적했다. Lambert는 "교활하다. 아래 결과는 가짜이며, 메타 커뮤니티에 그들이 주요 마케팅에 사용한 모델을 공개하지 않은 것은 큰 실례다"라고 말했다. 그는 홍보 모델이 "출시의 기술적 명성을 떨어뜨리고 있으며 그 성격이 유치하다"고 덧붙였지만, 다른 플랫폼에서 사용 가능한 실제 모델은 "상당히 똑똑하고 합리적인 톤을 가지고 있다"고 했다.
메타, '테스트 세트 훈련' 부인하며 빠른 출시로 인한 구현 버그 지적
비판과 비난에 대응해 메타의 GenAI 부사장 겸 책임자인 Ahmad Al-Dahle는 X에서 우려를 해결했다. 그는 커뮤니티의 라마 4 참여에 열정을 표했지만, 다양한 서비스에서 일관되지 않은 품질 보고를 인정했다. 그는 이러한 문제를 빠른 출시와 공개 구현 안정화에 필요한 시간 때문이라고 설명했다. Al-Dahle는 테스트 세트 훈련 혐의를 단호히 부인하며, 가변 품질은 부정 행위가 아닌 구현 버그 때문이라고 강조했다. 그는 라마 4 모델의 상당한 발전에 대한 메타의 믿음과 커뮤니티와 협력해 잠재력을 실현하겠다는 약속을 재확인했다.
그러나 이 응답은 커뮤니티의 좌절을 진정시키지 못했으며, 많은 이들이 여전히 저조한 성능을 보고하고 모델 훈련 과정에 대한 더 많은 기술적 문서를 요구했다. 이번 출시는 이전 라마 버전보다 더 많은 문제를 겪으며 개발과 출시에 대한 의문을 불러일으켰다.
이번 출시 시기는 메타의 연구 부사장 Joelle Pineau가 지난주 LinkedIn에서 회사 떠남을 발표하며 감사의 마음을 전한 직후라는 점에서 주목할 만하다. Pineau는 주말 동안 라마 4 모델 제품군을 홍보하기도 했다.
라마 4가 다른 추론 제공자들에 의해 채택되며 혼합된 결과를 보이고 있는 가운데, 초기 출시가 메타가 기대했던 성공을 거두지 못한 것이 분명하다. 4월 29일에 열리는 최초의 모델 제품군 타사 개발자 모임인 메타 라마콘은 토론과 논쟁의 중심지가 될 가능성이 높다. 우리는 발전 상황을 면밀히 주시할 것이니, 계속 지켜봐 달라.
관련 기사
 메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
메타의 천연가스 수요 급증으로 사우스다코타주 전력망에 활력을 불어넣을 수 있다
데이터 센터의 규모가 워낙 거대해져서, 현재 그 전력 소비량은 미국 내 한 주 전체의 소비량에 맞먹습니다. 메타(Meta)의 하이페리온(Hyperion) AI 데이터 센터를 예로 들어보겠습니다. 이 시설이 완공되면 사우스다코타주만큼의 전력을 소비하게 될 것입니다.메타는 최근 270억 달러 규모의 데이터 센터 운영을 지원하기 위해, 이미 계획된 3곳 외에도
관련 특별 주제 추천
만화 창작
메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
메타의 천연가스 수요 급증으로 사우스다코타주 전력망에 활력을 불어넣을 수 있다
데이터 센터의 규모가 워낙 거대해져서, 현재 그 전력 소비량은 미국 내 한 주 전체의 소비량에 맞먹습니다. 메타(Meta)의 하이페리온(Hyperion) AI 데이터 센터를 예로 들어보겠습니다. 이 시설이 완공되면 사우스다코타주만큼의 전력을 소비하게 될 것입니다.메타는 최근 270억 달러 규모의 데이터 센터 운영을 지원하기 위해, 이미 계획된 3곳 외에도
관련 특별 주제 추천
만화 창작
 소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
 15 도구
15 도구
 xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

 의견 (11)
0/500
의견 (11)
0/500
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
주말 동안 페이스북, 인스타그램, 왓츠앱, 퀘스트 VR을 이끄는 메타가 최신 AI 언어 모델 라마 4를 공개하며 모두를 놀라게 했다. 하나가 아닌 세 가지 새로운 버전이 소개되었으며, 각 버전은 "Mixture-of-Experts" 아키텍처와 고정 하이퍼파라미터를 사용하는 새로운 훈련 방식인 MetaP 덕분에 향상된 기능을 자랑한다. 더욱이, 세 모델 모두 광범위한 컨텍스트 윈도우를 제공하여 단일 상호작용에서 더 많은 정보를 처리할 수 있다.
출시의 흥분에도 불구하고 AI 커뮤니티의 반응은 미지근했다. 토요일, 메타는 라마 4 스카우트와 라마 4 매버릭 두 모델을 다운로드 및 사용 가능하게 했으나, 반응은 열광적이지 않았다.
라마 4, AI 사용자들 사이에서 혼란과 비판 불러일으켜
북아메리카의 인기 중국어 커뮤니티 1point3acres 포럼에 올라온 검증되지 않은 게시물이 레딧의 r/LocalLlama 서브레딧에 퍼졌다. 메타의 GenAI 조직 연구원으로 추정되는 이 게시물은 라마 4가 내부 타사 벤치마크에서 저조한 성능을 보였다고 주장했다. 이는 메타의 리더십이 사후 훈련 중 테스트 세트를 혼합하여 다양한 메트릭을 충족하고 유리한 결과를 제시했다고 암시했다. 이 주장의 진위 여부는 회의적인 반응을 얻었으며, 메타는 VentureBeat의 문의에 아직 응답하지 않았다.
하지만 라마 4의 성능에 대한 의구심은 여기서 그치지 않았다. X에서 사용자 @cto_junior는 모델의 성능에 대한 불신을 표하며, 라마 4 매버릭이 코딩 작업을 테스트하는 aider 폴리글롯 벤치마크에서 16%라는 낮은 점수를 기록했다고 밝혔다. 이 점수는 DeepSeek V3나 Claude 3.7 Sonnet 같은 비슷한 크기의 구형 모델보다 훨씬 낮다.
AI 박사이자 작가인 Andriy Burkov도 X에서 라마 4 스카우트의 광고된 1000만 토큰 컨텍스트 윈도우에 의문을 제기하며, 모델이 256k 토큰 이상의 프롬프트로 훈련되지 않았기 때문에 "가상"이라고 말했다. 그는 더 긴 프롬프트를 보내면 낮은 품질의 출력이 나올 가능성이 높다고 경고했다.
r/LocalLlama 서브레딧에서 사용자 Dr_Karminski는 라마 4의 성능에 실망을 표하며, 칠각형 내 공의 움직임을 시뮬레이션하는 작업에서 DeepSeek의 비추론 V3 모델과 비교해 저조한 성능을 보였다고 전했다.
전 메타 연구원이자 현재 AI2의 선임 연구원인 Nathan Lambert는 자신의 Interconnects Substack 블로그에서 메타의 벤치마크 비교를 비판했다. 그는 메타의 홍보 자료에 사용된 라마 4 매버릭 모델이 공개된 모델과 달리 대화성에 최적화되었다고 지적했다. Lambert는 "교활하다. 아래 결과는 가짜이며, 메타 커뮤니티에 그들이 주요 마케팅에 사용한 모델을 공개하지 않은 것은 큰 실례다"라고 말했다. 그는 홍보 모델이 "출시의 기술적 명성을 떨어뜨리고 있으며 그 성격이 유치하다"고 덧붙였지만, 다른 플랫폼에서 사용 가능한 실제 모델은 "상당히 똑똑하고 합리적인 톤을 가지고 있다"고 했다.
메타, '테스트 세트 훈련' 부인하며 빠른 출시로 인한 구현 버그 지적
비판과 비난에 대응해 메타의 GenAI 부사장 겸 책임자인 Ahmad Al-Dahle는 X에서 우려를 해결했다. 그는 커뮤니티의 라마 4 참여에 열정을 표했지만, 다양한 서비스에서 일관되지 않은 품질 보고를 인정했다. 그는 이러한 문제를 빠른 출시와 공개 구현 안정화에 필요한 시간 때문이라고 설명했다. Al-Dahle는 테스트 세트 훈련 혐의를 단호히 부인하며, 가변 품질은 부정 행위가 아닌 구현 버그 때문이라고 강조했다. 그는 라마 4 모델의 상당한 발전에 대한 메타의 믿음과 커뮤니티와 협력해 잠재력을 실현하겠다는 약속을 재확인했다.
그러나 이 응답은 커뮤니티의 좌절을 진정시키지 못했으며, 많은 이들이 여전히 저조한 성능을 보고하고 모델 훈련 과정에 대한 더 많은 기술적 문서를 요구했다. 이번 출시는 이전 라마 버전보다 더 많은 문제를 겪으며 개발과 출시에 대한 의문을 불러일으켰다.
이번 출시 시기는 메타의 연구 부사장 Joelle Pineau가 지난주 LinkedIn에서 회사 떠남을 발표하며 감사의 마음을 전한 직후라는 점에서 주목할 만하다. Pineau는 주말 동안 라마 4 모델 제품군을 홍보하기도 했다.
라마 4가 다른 추론 제공자들에 의해 채택되며 혼합된 결과를 보이고 있는 가운데, 초기 출시가 메타가 기대했던 성공을 거두지 못한 것이 분명하다. 4월 29일에 열리는 최초의 모델 제품군 타사 개발자 모임인 메타 라마콘은 토론과 논쟁의 중심지가 될 가능성이 높다. 우리는 발전 상황을 면밀히 주시할 것이니, 계속 지켜봐 달라.










 메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
 메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
 메타의 천연가스 수요 급증으로 사우스다코타주 전력망에 활력을 불어넣을 수 있다
데이터 센터의 규모가 워낙 거대해져서, 현재 그 전력 소비량은 미국 내 한 주 전체의 소비량에 맞먹습니다. 메타(Meta)의 하이페리온(Hyperion) AI 데이터 센터를 예로 들어보겠습니다. 이 시설이 완공되면 사우스다코타주만큼의 전력을 소비하게 될 것입니다.메타는 최근 270억 달러 규모의 데이터 센터 운영을 지원하기 위해, 이미 계획된 3곳 외에도
메타의 천연가스 수요 급증으로 사우스다코타주 전력망에 활력을 불어넣을 수 있다
데이터 센터의 규모가 워낙 거대해져서, 현재 그 전력 소비량은 미국 내 한 주 전체의 소비량에 맞먹습니다. 메타(Meta)의 하이페리온(Hyperion) AI 데이터 센터를 예로 들어보겠습니다. 이 시설이 완공되면 사우스다코타주만큼의 전력을 소비하게 될 것입니다.메타는 최근 270억 달러 규모의 데이터 센터 운영을 지원하기 위해, 이미 계획된 3곳 외에도

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













