
















 家
家MetaはLlama 4リリースを擁護し、バグを混合品質レポートの原因として引用します
週末、Facebook、Instagram、WhatsApp、Quest VRを運営するMetaは、最新のAI言語モデルLlama 4を公開し、驚きを与えた。3つの新バージョンが導入され、それぞれ「Mixture-of-Experts」アーキテクチャと固定ハイパーパラメータを用いた新しいトレーニング手法MetaPにより強化された機能を持つ。さらに、3つのモデルはすべて広範なコンテキストウィンドウを備え、1回の対話でより多くの情報を処理できる。
リリースの興奮にもかかわらず、AIコミュニティの反応はせいぜい冷淡だった。土曜日、MetaはLlama 4 ScoutとLlama 4 Maverickの2つのモデルをダウンロードと使用可能にしたが、反応は熱狂的とは程遠い。
Llama 4、AIユーザーの間で混乱と批判を呼ぶ
北米の中国語コミュニティで人気の1point3acresフォーラムに投稿された未検証の投稿が、Redditのr/LocalLlamaサブレディットに広まった。この投稿は、MetaのGenAI組織の研究者によるものとされ、Llama 4が内部のサードパーティベンチマークで期待外れだったと主張。Metaの経営陣がテストセットを混ぜて結果を操作し、好ましい結果を示したと示唆した。この主張の真偽は疑問視され、MetaはVentureBeatからの問い合わせにまだ回答していない。
しかし、Llama 4のパフォーマンスに対する疑問はそれだけに止まらなかった。Xでユーザー@cto_juniorは、Llama 4 Maverickがコーディングタスクをテストするaider polyglotベンチマークでわずか16%のスコアを記録した独立テストを引用し、モデルのパフォーマンスに疑問を呈した。このスコアは、DeepSeek V3やClaude 3.7 Sonnetといった同規模の旧モデルよりも大幅に低い。
AI博士で著者のAndriy BurkovもXで、Llama 4 Scoutの宣伝されている1000万トークンのコンテキストウィンドウが「仮想」だと指摘。モデルは256kトークンを超えるプロンプトでトレーニングされておらず、長いプロンプトを送ると低品質な出力になる可能性が高いと警告した。
r/LocalLlamaサブレディットでは、ユーザーDr_KarminskiがLlama 4の性能に失望を表明し、七角形内でのボールの動きをシミュレートするタスクでDeepSeekの非推論V3モデルと比較して劣ると述べた。
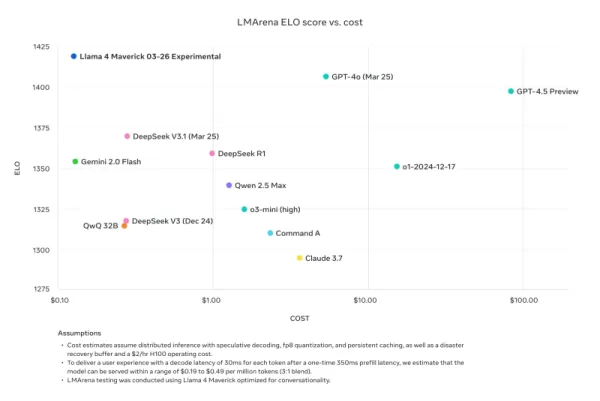
元Meta研究者で現在AI2のシニア研究者であるNathan Lambertは、自身のInterconnects SubstackブログでMetaのベンチマーク比較を批判。Metaのプロモーション資料で使用されたLlama 4 Maverickモデルは公開されたものとは異なり、会話向けに最適化されていたと指摘。「狡猾だ。以下の結果は偽物で、マーケティングのために使用したモデルを公開しないのはMetaコミュニティに対する重大な侮辱だ」と述べ、プロモーションモデルは「その性格が幼稚でリリースの技術的評判を損なっている」としつつ、他のプラットフォームで利用可能な実際のモデルは「かなり賢く、合理的なトーンを持っている」と付け加えた。
Meta、テストセットでのトレーニング否定と迅速な展開によるバグを理由に反論
批判と非難に対し、MetaのGenAI副社長兼責任者のAhmad Al-DahleはXで懸念に対応。Llama 4へのコミュニティの関与に熱意を示しつつ、異なるサービスでの品質のばらつきを認め、迅速な展開と公開実装の安定化に時間がかかるためだと説明。テストセットでのトレーニングの疑惑を強く否定し、品質の変動は不正ではなく実装バグによるものだと強調。MetaはLlama 4モデルの大きな進歩を信じ、コミュニティと協力してその可能性を実現する決意を再確認した。
しかし、この対応はコミュニティの不満を鎮めるには至らず、多くの人が依然として性能の低さを報告し、モデルのトレーニングプロセスに関する詳細な技術文書を求めている。このリリースは以前のLlamaバージョンよりも多くの問題に直面し、開発と展開に関する疑問を呼んでいる。
このリリースのタイミングは、Metaの研究副社長Joelle Pineauが先週LinkedInで退社を発表し、会社での時間に感謝を述べたことに続く注目すべきもの。Pineauは週末にLlama 4モデルファミリーを宣伝していた。
Llama 4が他の推論プロバイダーに採用される中、結果はまちまちで、Metaが期待した成功とは言えない。4月29日に開催されるMeta LlamaConは、モデルファミリーのサードパーティ開発者向け初の集会となり、議論と論争の場となるだろう。引き続き動向を注視するので、注目してほしい。
関連記事
 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
Metaによる天然ガス需要の急増が、サウスダコタ州の電力網を支えることになるかもしれない
データセンターは巨大化し、その電力消費量は今や米国の州全体に匹敵するほどになっています。MetaのHyperion AIデータセンターを例に挙げると、完成すればサウスダコタ州と同じだけの電力を消費することになります。Metaは最近、270億ドル規模のデータセンターを支えるため、すでに計画されている3基に加え、さらに7基の天然ガス発電所への資金提供を発表した。ルイジアナ州に建設されるこれら10基の発
関連特集おすすめ
漫画制作
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
Metaによる天然ガス需要の急増が、サウスダコタ州の電力網を支えることになるかもしれない
データセンターは巨大化し、その電力消費量は今や米国の州全体に匹敵するほどになっています。MetaのHyperion AIデータセンターを例に挙げると、完成すればサウスダコタ州と同じだけの電力を消費することになります。Metaは最近、270億ドル規模のデータセンターを支えるため、すでに計画されている3基に加え、さらに7基の天然ガス発電所への資金提供を発表した。ルイジアナ州に建設されるこれら10基の発
関連特集おすすめ
漫画制作
 少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
 15 ツール
15 ツール
 xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

 コメント (11)
0/500
コメント (11)
0/500
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
週末、Facebook、Instagram、WhatsApp、Quest VRを運営するMetaは、最新のAI言語モデルLlama 4を公開し、驚きを与えた。3つの新バージョンが導入され、それぞれ「Mixture-of-Experts」アーキテクチャと固定ハイパーパラメータを用いた新しいトレーニング手法MetaPにより強化された機能を持つ。さらに、3つのモデルはすべて広範なコンテキストウィンドウを備え、1回の対話でより多くの情報を処理できる。
リリースの興奮にもかかわらず、AIコミュニティの反応はせいぜい冷淡だった。土曜日、MetaはLlama 4 ScoutとLlama 4 Maverickの2つのモデルをダウンロードと使用可能にしたが、反応は熱狂的とは程遠い。
Llama 4、AIユーザーの間で混乱と批判を呼ぶ
北米の中国語コミュニティで人気の1point3acresフォーラムに投稿された未検証の投稿が、Redditのr/LocalLlamaサブレディットに広まった。この投稿は、MetaのGenAI組織の研究者によるものとされ、Llama 4が内部のサードパーティベンチマークで期待外れだったと主張。Metaの経営陣がテストセットを混ぜて結果を操作し、好ましい結果を示したと示唆した。この主張の真偽は疑問視され、MetaはVentureBeatからの問い合わせにまだ回答していない。
しかし、Llama 4のパフォーマンスに対する疑問はそれだけに止まらなかった。Xでユーザー@cto_juniorは、Llama 4 Maverickがコーディングタスクをテストするaider polyglotベンチマークでわずか16%のスコアを記録した独立テストを引用し、モデルのパフォーマンスに疑問を呈した。このスコアは、DeepSeek V3やClaude 3.7 Sonnetといった同規模の旧モデルよりも大幅に低い。
AI博士で著者のAndriy BurkovもXで、Llama 4 Scoutの宣伝されている1000万トークンのコンテキストウィンドウが「仮想」だと指摘。モデルは256kトークンを超えるプロンプトでトレーニングされておらず、長いプロンプトを送ると低品質な出力になる可能性が高いと警告した。
r/LocalLlamaサブレディットでは、ユーザーDr_KarminskiがLlama 4の性能に失望を表明し、七角形内でのボールの動きをシミュレートするタスクでDeepSeekの非推論V3モデルと比較して劣ると述べた。
元Meta研究者で現在AI2のシニア研究者であるNathan Lambertは、自身のInterconnects SubstackブログでMetaのベンチマーク比較を批判。Metaのプロモーション資料で使用されたLlama 4 Maverickモデルは公開されたものとは異なり、会話向けに最適化されていたと指摘。「狡猾だ。以下の結果は偽物で、マーケティングのために使用したモデルを公開しないのはMetaコミュニティに対する重大な侮辱だ」と述べ、プロモーションモデルは「その性格が幼稚でリリースの技術的評判を損なっている」としつつ、他のプラットフォームで利用可能な実際のモデルは「かなり賢く、合理的なトーンを持っている」と付け加えた。
Meta、テストセットでのトレーニング否定と迅速な展開によるバグを理由に反論
批判と非難に対し、MetaのGenAI副社長兼責任者のAhmad Al-DahleはXで懸念に対応。Llama 4へのコミュニティの関与に熱意を示しつつ、異なるサービスでの品質のばらつきを認め、迅速な展開と公開実装の安定化に時間がかかるためだと説明。テストセットでのトレーニングの疑惑を強く否定し、品質の変動は不正ではなく実装バグによるものだと強調。MetaはLlama 4モデルの大きな進歩を信じ、コミュニティと協力してその可能性を実現する決意を再確認した。
しかし、この対応はコミュニティの不満を鎮めるには至らず、多くの人が依然として性能の低さを報告し、モデルのトレーニングプロセスに関する詳細な技術文書を求めている。このリリースは以前のLlamaバージョンよりも多くの問題に直面し、開発と展開に関する疑問を呼んでいる。
このリリースのタイミングは、Metaの研究副社長Joelle Pineauが先週LinkedInで退社を発表し、会社での時間に感謝を述べたことに続く注目すべきもの。Pineauは週末にLlama 4モデルファミリーを宣伝していた。
Llama 4が他の推論プロバイダーに採用される中、結果はまちまちで、Metaが期待した成功とは言えない。4月29日に開催されるMeta LlamaConは、モデルファミリーのサードパーティ開発者向け初の集会となり、議論と論争の場となるだろう。引き続き動向を注視するので、注目してほしい。










 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
 Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
 Metaによる天然ガス需要の急増が、サウスダコタ州の電力網を支えることになるかもしれない
データセンターは巨大化し、その電力消費量は今や米国の州全体に匹敵するほどになっています。MetaのHyperion AIデータセンターを例に挙げると、完成すればサウスダコタ州と同じだけの電力を消費することになります。Metaは最近、270億ドル規模のデータセンターを支えるため、すでに計画されている3基に加え、さらに7基の天然ガス発電所への資金提供を発表した。ルイジアナ州に建設されるこれら10基の発
Metaによる天然ガス需要の急増が、サウスダコタ州の電力網を支えることになるかもしれない
データセンターは巨大化し、その電力消費量は今や米国の州全体に匹敵するほどになっています。MetaのHyperion AIデータセンターを例に挙げると、完成すればサウスダコタ州と同じだけの電力を消費することになります。Metaは最近、270億ドル規模のデータセンターを支えるため、すでに計画されている3基に加え、さらに7基の天然ガス発電所への資金提供を発表した。ルイジアナ州に建設されるこれら10基の発

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













