
















 Lar
Lar
Meta defende a liberação do llama 4, cita bugs como causa de relatórios de qualidade mista
Durante o fim de semana, a Meta, a potência por trás do Facebook, Instagram, WhatsApp e Quest VR, surpreendeu a todos ao revelar seu mais recente modelo de linguagem de IA, o Llama 4. Não apenas um, mas três novas versões foram apresentadas, cada uma com capacidades aprimoradas graças à arquitetura "Mixture-of-Experts" e uma nova abordagem de treinamento chamada MetaP, que envolve hiperparâmetros fixos. Além disso, todos os três modelos vêm com janelas de contexto expansivas, permitindo que processem mais informações em uma única interação.
Apesar da empolgação com o lançamento, a reação da comunidade de IA tem sido, na melhor das hipóteses, morna. No sábado, a Meta disponibilizou dois desses modelos, Llama 4 Scout e Llama 4 Maverick, para download e uso, mas a resposta está longe de ser entusiástica.
Llama 4 Gera Confusão e Críticas Entre Usuários de IA
Uma postagem não verificada no fórum 1point3acres, uma comunidade popular em língua chinesa na América do Norte, chegou ao subreddit r/LocalLlama no Reddit. A postagem, supostamente de um pesquisador da organização GenAI da Meta, alegava que o Llama 4 teve desempenho inferior em benchmarks de terceiros internos. Sugeria que a liderança da Meta manipulou os resultados ao misturar conjuntos de testes durante o pós-treinamento para atender a várias métricas e apresentar um resultado favorável. A autenticidade dessa alegação foi recebida com ceticismo, e a Meta ainda não respondeu às perguntas da VentureBeat.
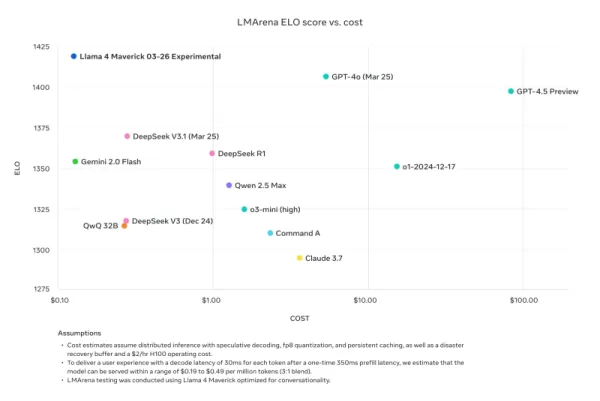
No entanto, as dúvidas sobre o desempenho do Llama 4 não pararam por aí. No X, o usuário @cto_junior expressou descrença no desempenho do modelo, citando um teste independente onde o Llama 4 Maverick obteve apenas 16% no benchmark poliglota aider, que testa tarefas de codificação. Essa pontuação é significativamente menor do que a de modelos mais antigos de tamanho semelhante, como DeepSeek V3 e Claude 3.7 Sonnet.
O doutor em IA e autor Andriy Burkov também usou o X para questionar a janela de contexto de 10 milhões de tokens anunciada para o Llama 4 Scout, afirmando que ela é "virtual" porque o modelo não foi treinado em prompts superiores a 256 mil tokens. Ele alertou que enviar prompts mais longos provavelmente resultaria em saídas de baixa qualidade.
No subreddit r/LocalLlama, o usuário Dr_Karminski compartilhou decepção com o Llama 4, comparando seu desempenho fraco ao do modelo V3 sem raciocínio da DeepSeek em tarefas como simular movimentos de bola dentro de um heptágono.
Nathan Lambert, ex-pesquisador da Meta e atual Cientista Sênior de Pesquisa na AI2, criticou as comparações de benchmark da Meta em seu blog Interconnects Substack. Ele apontou que o modelo Llama 4 Maverick usado nos materiais promocionais da Meta era diferente do lançado publicamente, otimizado em vez disso para conversacionalidade. Lambert destacou a discrepância, dizendo: "Furtivo. Os resultados abaixo são falsos, e é uma grande desfeita à comunidade da Meta não lançar o modelo que eles usaram para criar sua grande campanha de marketing." Ele acrescentou que, enquanto o modelo promocional estava "prejudicando a reputação técnica do lançamento porque seu caráter é juvenil," o modelo real disponível em outras plataformas era "bastante inteligente e tem um tom razoável."
Meta Responde, Negando 'Treinamento em Conjuntos de Teste' e Citando Bugs na Implementação Devido ao Lançamento Rápido
Em resposta às críticas e acusações, o vice-presidente e chefe de GenAI da Meta, Ahmad Al-Dahle, usou o X para abordar as preocupações. Ele expressou entusiasmo pelo envolvimento da comunidade com o Llama 4, mas reconheceu relatos de qualidade inconsistente em diferentes serviços. Ele atribuiu esses problemas ao lançamento rápido e ao tempo necessário para que as implementações públicas se estabilizem. Al-Dahle negou firmemente as alegações de treinamento em conjuntos de teste, enfatizando que a qualidade variável era devido a bugs de implementação, e não a qualquer má conduta. Ele reafirmou a crença da Meta nos avanços significativos dos modelos Llama 4 e seu compromisso em trabalhar com a comunidade para realizar seu potencial.
No entanto, a resposta fez pouco para acalmar as frustrações da comunidade, com muitos ainda relatando desempenho ruim e exigindo mais documentação técnica sobre os processos de treinamento dos modelos. Este lançamento enfrentou mais problemas do que as versões anteriores do Llama, levantando questões sobre seu desenvolvimento e implementação.
O momento deste lançamento é notável, pois segue a saída de Joelle Pineau, vice-presidente de Pesquisa da Meta, que anunciou sua saída no LinkedIn na última semana com gratidão por seu tempo na empresa. Pineau também promoveu a família de modelos Llama 4 durante o fim de semana.
À medida que o Llama 4 continua a ser adotado por outros provedores de inferência com resultados mistos, está claro que o lançamento inicial não foi o sucesso que a Meta poderia ter esperado. A próxima Meta LlamaCon, em 29 de abril, que será o primeiro encontro para desenvolvedores terceirizados da família de modelos, provavelmente será um foco de discussão e debate. Estaremos acompanhando de perto os desenvolvimentos, então fique atento.
Artigo relacionado
 A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
Meta fecha acordo para a aquisição de milhões de CPUs de IA da Amazon
A Amazon fechou uma parceria significativa com a Meta, mais uma vez contando com seus próprios chips projetados sob medida. A Meta concordou em implantar milhões de chips AWS Graviton para atender às
O aumento da produção de gás natural da Meta pode abastecer a rede elétrica de Dakota do Sul
Os data centers cresceram tanto que seu consumo de eletricidade agora se equipara ao de estados inteiros dos EUA. Veja o caso do data center de IA Hyperion, da Meta: quando estiver concluído, consumir
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
Meta fecha acordo para a aquisição de milhões de CPUs de IA da Amazon
A Amazon fechou uma parceria significativa com a Meta, mais uma vez contando com seus próprios chips projetados sob medida. A Meta concordou em implantar milhões de chips AWS Graviton para atender às
O aumento da produção de gás natural da Meta pode abastecer a rede elétrica de Dakota do Sul
Os data centers cresceram tanto que seu consumo de eletricidade agora se equipara ao de estados inteiros dos EUA. Veja o caso do data center de IA Hyperion, da Meta: quando estiver concluído, consumir
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
 Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
 15 ferramentas
15 ferramentas
 xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (11)
Comentários (11)
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
Durante o fim de semana, a Meta, a potência por trás do Facebook, Instagram, WhatsApp e Quest VR, surpreendeu a todos ao revelar seu mais recente modelo de linguagem de IA, o Llama 4. Não apenas um, mas três novas versões foram apresentadas, cada uma com capacidades aprimoradas graças à arquitetura "Mixture-of-Experts" e uma nova abordagem de treinamento chamada MetaP, que envolve hiperparâmetros fixos. Além disso, todos os três modelos vêm com janelas de contexto expansivas, permitindo que processem mais informações em uma única interação.
Apesar da empolgação com o lançamento, a reação da comunidade de IA tem sido, na melhor das hipóteses, morna. No sábado, a Meta disponibilizou dois desses modelos, Llama 4 Scout e Llama 4 Maverick, para download e uso, mas a resposta está longe de ser entusiástica.
Llama 4 Gera Confusão e Críticas Entre Usuários de IA
Uma postagem não verificada no fórum 1point3acres, uma comunidade popular em língua chinesa na América do Norte, chegou ao subreddit r/LocalLlama no Reddit. A postagem, supostamente de um pesquisador da organização GenAI da Meta, alegava que o Llama 4 teve desempenho inferior em benchmarks de terceiros internos. Sugeria que a liderança da Meta manipulou os resultados ao misturar conjuntos de testes durante o pós-treinamento para atender a várias métricas e apresentar um resultado favorável. A autenticidade dessa alegação foi recebida com ceticismo, e a Meta ainda não respondeu às perguntas da VentureBeat.
No entanto, as dúvidas sobre o desempenho do Llama 4 não pararam por aí. No X, o usuário @cto_junior expressou descrença no desempenho do modelo, citando um teste independente onde o Llama 4 Maverick obteve apenas 16% no benchmark poliglota aider, que testa tarefas de codificação. Essa pontuação é significativamente menor do que a de modelos mais antigos de tamanho semelhante, como DeepSeek V3 e Claude 3.7 Sonnet.
O doutor em IA e autor Andriy Burkov também usou o X para questionar a janela de contexto de 10 milhões de tokens anunciada para o Llama 4 Scout, afirmando que ela é "virtual" porque o modelo não foi treinado em prompts superiores a 256 mil tokens. Ele alertou que enviar prompts mais longos provavelmente resultaria em saídas de baixa qualidade.
No subreddit r/LocalLlama, o usuário Dr_Karminski compartilhou decepção com o Llama 4, comparando seu desempenho fraco ao do modelo V3 sem raciocínio da DeepSeek em tarefas como simular movimentos de bola dentro de um heptágono.
Nathan Lambert, ex-pesquisador da Meta e atual Cientista Sênior de Pesquisa na AI2, criticou as comparações de benchmark da Meta em seu blog Interconnects Substack. Ele apontou que o modelo Llama 4 Maverick usado nos materiais promocionais da Meta era diferente do lançado publicamente, otimizado em vez disso para conversacionalidade. Lambert destacou a discrepância, dizendo: "Furtivo. Os resultados abaixo são falsos, e é uma grande desfeita à comunidade da Meta não lançar o modelo que eles usaram para criar sua grande campanha de marketing." Ele acrescentou que, enquanto o modelo promocional estava "prejudicando a reputação técnica do lançamento porque seu caráter é juvenil," o modelo real disponível em outras plataformas era "bastante inteligente e tem um tom razoável."
Meta Responde, Negando 'Treinamento em Conjuntos de Teste' e Citando Bugs na Implementação Devido ao Lançamento Rápido
Em resposta às críticas e acusações, o vice-presidente e chefe de GenAI da Meta, Ahmad Al-Dahle, usou o X para abordar as preocupações. Ele expressou entusiasmo pelo envolvimento da comunidade com o Llama 4, mas reconheceu relatos de qualidade inconsistente em diferentes serviços. Ele atribuiu esses problemas ao lançamento rápido e ao tempo necessário para que as implementações públicas se estabilizem. Al-Dahle negou firmemente as alegações de treinamento em conjuntos de teste, enfatizando que a qualidade variável era devido a bugs de implementação, e não a qualquer má conduta. Ele reafirmou a crença da Meta nos avanços significativos dos modelos Llama 4 e seu compromisso em trabalhar com a comunidade para realizar seu potencial.
No entanto, a resposta fez pouco para acalmar as frustrações da comunidade, com muitos ainda relatando desempenho ruim e exigindo mais documentação técnica sobre os processos de treinamento dos modelos. Este lançamento enfrentou mais problemas do que as versões anteriores do Llama, levantando questões sobre seu desenvolvimento e implementação.
O momento deste lançamento é notável, pois segue a saída de Joelle Pineau, vice-presidente de Pesquisa da Meta, que anunciou sua saída no LinkedIn na última semana com gratidão por seu tempo na empresa. Pineau também promoveu a família de modelos Llama 4 durante o fim de semana.
À medida que o Llama 4 continua a ser adotado por outros provedores de inferência com resultados mistos, está claro que o lançamento inicial não foi o sucesso que a Meta poderia ter esperado. A próxima Meta LlamaCon, em 29 de abril, que será o primeiro encontro para desenvolvedores terceirizados da família de modelos, provavelmente será um foco de discussão e debate. Estaremos acompanhando de perto os desenvolvimentos, então fique atento.










 A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
 Meta fecha acordo para a aquisição de milhões de CPUs de IA da Amazon
A Amazon fechou uma parceria significativa com a Meta, mais uma vez contando com seus próprios chips projetados sob medida. A Meta concordou em implantar milhões de chips AWS Graviton para atender às
Meta fecha acordo para a aquisição de milhões de CPUs de IA da Amazon
A Amazon fechou uma parceria significativa com a Meta, mais uma vez contando com seus próprios chips projetados sob medida. A Meta concordou em implantar milhões de chips AWS Graviton para atender às
 O aumento da produção de gás natural da Meta pode abastecer a rede elétrica de Dakota do Sul
Os data centers cresceram tanto que seu consumo de eletricidade agora se equipara ao de estados inteiros dos EUA. Veja o caso do data center de IA Hyperion, da Meta: quando estiver concluído, consumir
O aumento da produção de gás natural da Meta pode abastecer a rede elétrica de Dakota do Sul
Os data centers cresceram tanto que seu consumo de eletricidade agora se equipara ao de estados inteiros dos EUA. Veja o caso do data center de IA Hyperion, da Meta: quando estiver concluído, consumir

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













