
















 Hogar
Hogar
Meta Defiense Llama 4 Lanzamiento, cita errores como causa de informes de calidad mixta
Durante el fin de semana, Meta, la potencia detrás de Facebook, Instagram, WhatsApp y Quest VR, sorprendió a todos al presentar su último modelo de lenguaje de IA, Llama 4. No solo uno, sino tres nuevas versiones fueron introducidas, cada una con capacidades mejoradas gracias a la arquitectura "Mixture-of-Experts" y un nuevo enfoque de entrenamiento llamado MetaP, que implica hiperparámetros fijos. Además, todos los modelos vienen con ventanas de contexto expansivas, permitiéndoles procesar más información en una sola interacción.
A pesar de la emoción del lanzamiento, la reacción de la comunidad de IA ha sido, en el mejor de los casos, tibia. El sábado, Meta puso a disposición para descarga y uso dos de estos modelos, Llama 4 Scout y Llama 4 Maverick, pero la respuesta ha estado lejos de ser entusiasta.
Llama 4 Genera Confusión y Críticas Entre Usuarios de IA
Una publicación no verificada en el foro 1point3acres, una comunidad popular en chino en América del Norte, llegó al subreddit r/LocalLlama en Reddit. La publicación, supuestamente de un investigador de la organización GenAI de Meta, afirmaba que Llama 4 tuvo un desempeño inferior en pruebas internas de terceros. Sugería que el liderazgo de Meta manipuló los resultados mezclando conjuntos de pruebas durante el post-entrenamiento para cumplir con varias métricas y presentar un resultado favorable. La autenticidad de esta afirmación fue recibida con escepticismo, y Meta aún no ha respondido a las consultas de VentureBeat.
Sin embargo, las dudas sobre el rendimiento de Llama 4 no terminaron ahí. En X, el usuario @cto_junior expresó incredulidad sobre el rendimiento del modelo, citando una prueba independiente donde Llama 4 Maverick obtuvo solo un 16% en el benchmark aider polyglot, que evalúa tareas de codificación. Esta puntuación es significativamente menor que la de modelos más antiguos de tamaño similar como DeepSeek V3 y Claude 3.7 Sonnet.
El doctor en IA y autor Andriy Burkov también recurrió a X para cuestionar la ventana de contexto de 10 millones de tokens anunciada para Llama 4 Scout, afirmando que es "virtual" porque el modelo no fue entrenado con prompts más largos de 256k tokens. Advirtió que enviar prompts más largos probablemente resultaría en salidas de baja calidad.
En el subreddit r/LocalLlama, el usuario Dr_Karminski expresó decepción con Llama 4, comparando su pobre rendimiento con el modelo V3 sin razonamiento de DeepSeek en tareas como simular movimientos de pelotas dentro de un heptágono.
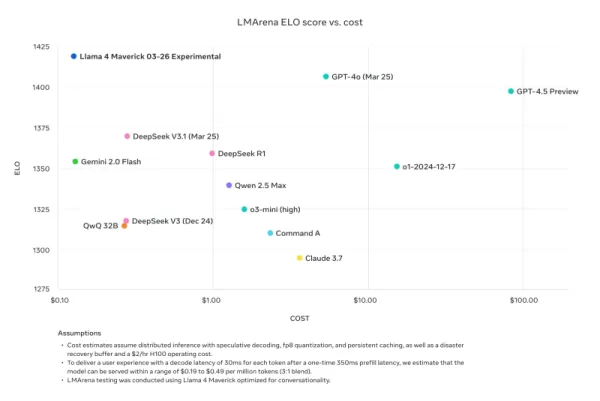
Nathan Lambert, exinvestigador de Meta y actual Científico Investigador Senior en AI2, criticó las comparaciones de benchmarks de Meta en su blog Interconnects Substack. Señaló que el modelo Llama 4 Maverick usado en los materiales promocionales de Meta era diferente al lanzado públicamente, optimizado en cambio para la conversacionalidad. Lambert notó la discrepancia, diciendo: "Astuto. Los resultados a continuación son falsos, y es un gran desaire a la comunidad de Meta no lanzar el modelo que usaron para crear su gran campaña de marketing." Añadió que mientras el modelo promocional estaba "dañando la reputación técnica del lanzamiento porque su carácter es juvenil," el modelo real disponible en otras plataformas era "bastante inteligente y tiene un tono razonable."
Meta Responde, Niega 'Entrenamiento en Conjuntos de Prueba' y Cita Errores en la Implementación Debido al Rápido Lanzamiento
En respuesta a las críticas y acusaciones, el VP y Jefe de GenAI de Meta, Ahmad Al-Dahle, recurrió a X para abordar las preocupaciones. Expresó entusiasmo por el compromiso de la comunidad con Llama 4, pero reconoció informes de calidad inconsistente en diferentes servicios. Atribuyó estos problemas al rápido lanzamiento y al tiempo necesario para que las implementaciones públicas se estabilicen. Al-Dahle negó firmemente las acusaciones de entrenamiento en conjuntos de prueba, enfatizando que la calidad variable se debía a errores de implementación en lugar de cualquier mala conducta. Reafirmó la creencia de Meta en los avances significativos de los modelos Llama 4 y su compromiso de trabajar con la comunidad para realizar su potencial.
Sin embargo, la respuesta hizo poco para calmar las frustraciones de la comunidad, con muchos aún reportando un rendimiento pobre y exigiendo más documentación técnica sobre los procesos de entrenamiento de los modelos. Este lanzamiento ha enfrentado más problemas que las versiones anteriores de Llama, generando preguntas sobre su desarrollo y lanzamiento.
El momento de este lanzamiento es notable, ya que sigue a la salida de Joelle Pineau, VP de Investigación de Meta, quien anunció su salida en LinkedIn la semana pasada con gratitud por su tiempo en la empresa. Pineau también había promocionado la familia de modelos Llama 4 durante el fin de semana.
A medida que Llama 4 sigue siendo adoptado por otros proveedores de inferencia con resultados mixtos, está claro que el lanzamiento inicial no ha sido el éxito que Meta podría haber esperado. La próxima Meta LlamaCon el 29 de abril, que será la primera reunión para desarrolladores de terceros de la familia de modelos, probablemente será un hervidero de discusión y debate. Estaremos atentos a los desarrollos, así que mantente informado.
Artículo relacionado
 Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
El auge del gas natural de Meta podría impulsar la red eléctrica de Dakota del Sur
Los centros de datos han alcanzado tal magnitud que su consumo eléctrico equivale ahora al de estados enteros de EE. UU. Tomemos como ejemplo el centro de datos Hyperion AI de Meta: una vez terminado,
Recomendaciones de temas especiales relacionados
Creación de cómics
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
El auge del gas natural de Meta podría impulsar la red eléctrica de Dakota del Sur
Los centros de datos han alcanzado tal magnitud que su consumo eléctrico equivale ahora al de estados enteros de EE. UU. Tomemos como ejemplo el centro de datos Hyperion AI de Meta: una vez terminado,
Recomendaciones de temas especiales relacionados
Creación de cómics
 Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
 15 herramientas
15 herramientas
 xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

 comentario (11)
0/500
comentario (11)
0/500
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
Durante el fin de semana, Meta, la potencia detrás de Facebook, Instagram, WhatsApp y Quest VR, sorprendió a todos al presentar su último modelo de lenguaje de IA, Llama 4. No solo uno, sino tres nuevas versiones fueron introducidas, cada una con capacidades mejoradas gracias a la arquitectura "Mixture-of-Experts" y un nuevo enfoque de entrenamiento llamado MetaP, que implica hiperparámetros fijos. Además, todos los modelos vienen con ventanas de contexto expansivas, permitiéndoles procesar más información en una sola interacción.
A pesar de la emoción del lanzamiento, la reacción de la comunidad de IA ha sido, en el mejor de los casos, tibia. El sábado, Meta puso a disposición para descarga y uso dos de estos modelos, Llama 4 Scout y Llama 4 Maverick, pero la respuesta ha estado lejos de ser entusiasta.
Llama 4 Genera Confusión y Críticas Entre Usuarios de IA
Una publicación no verificada en el foro 1point3acres, una comunidad popular en chino en América del Norte, llegó al subreddit r/LocalLlama en Reddit. La publicación, supuestamente de un investigador de la organización GenAI de Meta, afirmaba que Llama 4 tuvo un desempeño inferior en pruebas internas de terceros. Sugería que el liderazgo de Meta manipuló los resultados mezclando conjuntos de pruebas durante el post-entrenamiento para cumplir con varias métricas y presentar un resultado favorable. La autenticidad de esta afirmación fue recibida con escepticismo, y Meta aún no ha respondido a las consultas de VentureBeat.
Sin embargo, las dudas sobre el rendimiento de Llama 4 no terminaron ahí. En X, el usuario @cto_junior expresó incredulidad sobre el rendimiento del modelo, citando una prueba independiente donde Llama 4 Maverick obtuvo solo un 16% en el benchmark aider polyglot, que evalúa tareas de codificación. Esta puntuación es significativamente menor que la de modelos más antiguos de tamaño similar como DeepSeek V3 y Claude 3.7 Sonnet.
El doctor en IA y autor Andriy Burkov también recurrió a X para cuestionar la ventana de contexto de 10 millones de tokens anunciada para Llama 4 Scout, afirmando que es "virtual" porque el modelo no fue entrenado con prompts más largos de 256k tokens. Advirtió que enviar prompts más largos probablemente resultaría en salidas de baja calidad.
En el subreddit r/LocalLlama, el usuario Dr_Karminski expresó decepción con Llama 4, comparando su pobre rendimiento con el modelo V3 sin razonamiento de DeepSeek en tareas como simular movimientos de pelotas dentro de un heptágono.
Nathan Lambert, exinvestigador de Meta y actual Científico Investigador Senior en AI2, criticó las comparaciones de benchmarks de Meta en su blog Interconnects Substack. Señaló que el modelo Llama 4 Maverick usado en los materiales promocionales de Meta era diferente al lanzado públicamente, optimizado en cambio para la conversacionalidad. Lambert notó la discrepancia, diciendo: "Astuto. Los resultados a continuación son falsos, y es un gran desaire a la comunidad de Meta no lanzar el modelo que usaron para crear su gran campaña de marketing." Añadió que mientras el modelo promocional estaba "dañando la reputación técnica del lanzamiento porque su carácter es juvenil," el modelo real disponible en otras plataformas era "bastante inteligente y tiene un tono razonable."
Meta Responde, Niega 'Entrenamiento en Conjuntos de Prueba' y Cita Errores en la Implementación Debido al Rápido Lanzamiento
En respuesta a las críticas y acusaciones, el VP y Jefe de GenAI de Meta, Ahmad Al-Dahle, recurrió a X para abordar las preocupaciones. Expresó entusiasmo por el compromiso de la comunidad con Llama 4, pero reconoció informes de calidad inconsistente en diferentes servicios. Atribuyó estos problemas al rápido lanzamiento y al tiempo necesario para que las implementaciones públicas se estabilicen. Al-Dahle negó firmemente las acusaciones de entrenamiento en conjuntos de prueba, enfatizando que la calidad variable se debía a errores de implementación en lugar de cualquier mala conducta. Reafirmó la creencia de Meta en los avances significativos de los modelos Llama 4 y su compromiso de trabajar con la comunidad para realizar su potencial.
Sin embargo, la respuesta hizo poco para calmar las frustraciones de la comunidad, con muchos aún reportando un rendimiento pobre y exigiendo más documentación técnica sobre los procesos de entrenamiento de los modelos. Este lanzamiento ha enfrentado más problemas que las versiones anteriores de Llama, generando preguntas sobre su desarrollo y lanzamiento.
El momento de este lanzamiento es notable, ya que sigue a la salida de Joelle Pineau, VP de Investigación de Meta, quien anunció su salida en LinkedIn la semana pasada con gratitud por su tiempo en la empresa. Pineau también había promocionado la familia de modelos Llama 4 durante el fin de semana.
A medida que Llama 4 sigue siendo adoptado por otros proveedores de inferencia con resultados mixtos, está claro que el lanzamiento inicial no ha sido el éxito que Meta podría haber esperado. La próxima Meta LlamaCon el 29 de abril, que será la primera reunión para desarrolladores de terceros de la familia de modelos, probablemente será un hervidero de discusión y debate. Estaremos atentos a los desarrollos, así que mantente informado.










 Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
 Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
 El auge del gas natural de Meta podría impulsar la red eléctrica de Dakota del Sur
Los centros de datos han alcanzado tal magnitud que su consumo eléctrico equivale ahora al de estados enteros de EE. UU. Tomemos como ejemplo el centro de datos Hyperion AI de Meta: una vez terminado,
El auge del gas natural de Meta podría impulsar la red eléctrica de Dakota del Sur
Los centros de datos han alcanzado tal magnitud que su consumo eléctrico equivale ahora al de estados enteros de EE. UU. Tomemos como ejemplo el centro de datos Hyperion AI de Meta: una vez terminado,

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













