
















 Home
HomeMeta Defends Llama 4 Release, Cites Bugs as Cause of Mixed Quality Reports
Over the weekend, Meta, the powerhouse behind Facebook, Instagram, WhatsApp, and Quest VR, surprised everyone by unveiling their latest AI language model, Llama 4. Not just one, but three new versions were introduced, each boasting enhanced capabilities thanks to the "Mixture-of-Experts" architecture and a novel training approach called MetaP, which involves fixed hyperparameters. What's more, all three models come with expansive context windows, allowing them to process more information in a single interaction.
Despite the excitement of the release, the AI community's reaction has been lukewarm at best. On Saturday, Meta made two of these models, Llama 4 Scout and Llama 4 Maverick, available for download and use, but the response has been far from enthusiastic.
Llama 4 Sparks Confusion and Criticism Among AI Users
An unverified post on the 1point3acres forum, a popular Chinese language community in North America, found its way to the r/LocalLlama subreddit on Reddit. The post, allegedly from a researcher at Meta’s GenAI organization, claimed that Llama 4 underperformed on internal third-party benchmarks. It suggested that Meta's leadership had manipulated the results by blending test sets during post-training to meet various metrics and present a favorable outcome. The authenticity of this claim was met with skepticism, and Meta has yet to respond to inquiries from VentureBeat.
Yet, the doubts about Llama 4's performance didn't stop there. On X, user @cto_junior expressed disbelief at the model's performance, citing an independent test where Llama 4 Maverick scored a mere 16% on the aider polyglot benchmark, which tests coding tasks. This score is significantly lower than that of older, similarly sized models like DeepSeek V3 and Claude 3.7 Sonnet.
AI PhD and author Andriy Burkov also took to X to question the model's advertised 10 million-token context window for Llama 4 Scout, stating that it's "virtual" because the model wasn't trained on prompts longer than 256k tokens. He warned that sending longer prompts would likely result in low-quality outputs.
On the r/LocalLlama subreddit, user Dr_Karminski shared disappointment with Llama 4, comparing its poor performance to DeepSeek’s non-reasoning V3 model on tasks like simulating ball movements within a heptagon.
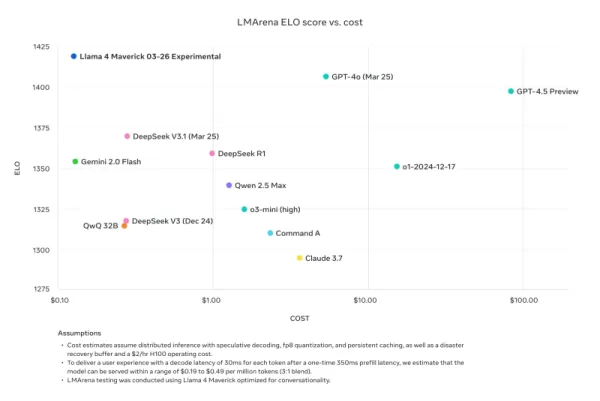
Nathan Lambert, a former Meta researcher and current Senior Research Scientist at AI2, criticized Meta's benchmark comparisons on his Interconnects Substack blog. He pointed out that the Llama 4 Maverick model used in Meta's promotional materials was different from the one publicly released, optimized instead for conversationality. Lambert noted the discrepancy, saying, "Sneaky. The results below are fake, and it is a major slight to Meta’s community to not release the model they used to create their major marketing push." He added that while the promotional model was "tanking the technical reputation of the release because its character is juvenile," the actual model available on other platforms was "quite smart and has a reasonable tone."
Meta Responds, Denying 'Training on Test Sets' and Citing Bugs in Implementation Due to Fast Rollout
In response to the criticism and accusations, Meta's VP and Head of GenAI, Ahmad Al-Dahle, took to X to address the concerns. He expressed enthusiasm for the community's engagement with Llama 4 but acknowledged reports of inconsistent quality across different services. He attributed these issues to the rapid rollout and the time needed for public implementations to stabilize. Al-Dahle firmly denied the allegations of training on test sets, emphasizing that the variable quality was due to implementation bugs rather than any misconduct. He reaffirmed Meta's belief in the significant advancements of the Llama 4 models and their commitment to working with the community to realize their potential.
However, the response did little to quell the community's frustrations, with many still reporting poor performance and demanding more technical documentation about the models' training processes. This release has faced more issues than previous Llama versions, raising questions about its development and rollout.
The timing of this release is notable, as it follows the departure of Joelle Pineau, Meta's VP of Research, who announced her exit on LinkedIn last week with gratitude for her time at the company. Pineau had also promoted the Llama 4 model family over the weekend.
As Llama 4 continues to be adopted by other inference providers with mixed results, it's clear that the initial release has not been the success Meta might have hoped for. The upcoming Meta LlamaCon on April 29, which will be the first gathering for third-party developers of the model family, is likely to be a hotbed of discussion and debate. We'll be keeping a close eye on developments, so stay tuned.
Related article
 Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Meta's natural gas surge may fuel South Dakota's power grid
Data centers have grown so massive that their electricity consumption now matches that of entire U.S. states. Consider Meta's Hyperion AI data center: once finished, it will consume as much power as South Dakota.Meta recently announced funding for se
Related Special Topic Recommendations
Business
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Meta's natural gas surge may fuel South Dakota's power grid
Data centers have grown so massive that their electricity consumption now matches that of entire U.S. states. Consider Meta's Hyperion AI data center: once finished, it will consume as much power as South Dakota.Meta recently announced funding for se
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (11)
0/500
Comments (11)
0/500
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
Over the weekend, Meta, the powerhouse behind Facebook, Instagram, WhatsApp, and Quest VR, surprised everyone by unveiling their latest AI language model, Llama 4. Not just one, but three new versions were introduced, each boasting enhanced capabilities thanks to the "Mixture-of-Experts" architecture and a novel training approach called MetaP, which involves fixed hyperparameters. What's more, all three models come with expansive context windows, allowing them to process more information in a single interaction.
Despite the excitement of the release, the AI community's reaction has been lukewarm at best. On Saturday, Meta made two of these models, Llama 4 Scout and Llama 4 Maverick, available for download and use, but the response has been far from enthusiastic.
Llama 4 Sparks Confusion and Criticism Among AI Users
An unverified post on the 1point3acres forum, a popular Chinese language community in North America, found its way to the r/LocalLlama subreddit on Reddit. The post, allegedly from a researcher at Meta’s GenAI organization, claimed that Llama 4 underperformed on internal third-party benchmarks. It suggested that Meta's leadership had manipulated the results by blending test sets during post-training to meet various metrics and present a favorable outcome. The authenticity of this claim was met with skepticism, and Meta has yet to respond to inquiries from VentureBeat.
Yet, the doubts about Llama 4's performance didn't stop there. On X, user @cto_junior expressed disbelief at the model's performance, citing an independent test where Llama 4 Maverick scored a mere 16% on the aider polyglot benchmark, which tests coding tasks. This score is significantly lower than that of older, similarly sized models like DeepSeek V3 and Claude 3.7 Sonnet.
AI PhD and author Andriy Burkov also took to X to question the model's advertised 10 million-token context window for Llama 4 Scout, stating that it's "virtual" because the model wasn't trained on prompts longer than 256k tokens. He warned that sending longer prompts would likely result in low-quality outputs.
On the r/LocalLlama subreddit, user Dr_Karminski shared disappointment with Llama 4, comparing its poor performance to DeepSeek’s non-reasoning V3 model on tasks like simulating ball movements within a heptagon.
Nathan Lambert, a former Meta researcher and current Senior Research Scientist at AI2, criticized Meta's benchmark comparisons on his Interconnects Substack blog. He pointed out that the Llama 4 Maverick model used in Meta's promotional materials was different from the one publicly released, optimized instead for conversationality. Lambert noted the discrepancy, saying, "Sneaky. The results below are fake, and it is a major slight to Meta’s community to not release the model they used to create their major marketing push." He added that while the promotional model was "tanking the technical reputation of the release because its character is juvenile," the actual model available on other platforms was "quite smart and has a reasonable tone."
Meta Responds, Denying 'Training on Test Sets' and Citing Bugs in Implementation Due to Fast Rollout
In response to the criticism and accusations, Meta's VP and Head of GenAI, Ahmad Al-Dahle, took to X to address the concerns. He expressed enthusiasm for the community's engagement with Llama 4 but acknowledged reports of inconsistent quality across different services. He attributed these issues to the rapid rollout and the time needed for public implementations to stabilize. Al-Dahle firmly denied the allegations of training on test sets, emphasizing that the variable quality was due to implementation bugs rather than any misconduct. He reaffirmed Meta's belief in the significant advancements of the Llama 4 models and their commitment to working with the community to realize their potential.
However, the response did little to quell the community's frustrations, with many still reporting poor performance and demanding more technical documentation about the models' training processes. This release has faced more issues than previous Llama versions, raising questions about its development and rollout.
The timing of this release is notable, as it follows the departure of Joelle Pineau, Meta's VP of Research, who announced her exit on LinkedIn last week with gratitude for her time at the company. Pineau had also promoted the Llama 4 model family over the weekend.
As Llama 4 continues to be adopted by other inference providers with mixed results, it's clear that the initial release has not been the success Meta might have hoped for. The upcoming Meta LlamaCon on April 29, which will be the first gathering for third-party developers of the model family, is likely to be a hotbed of discussion and debate. We'll be keeping a close eye on developments, so stay tuned.










 Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
 Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
 Meta's natural gas surge may fuel South Dakota's power grid
Data centers have grown so massive that their electricity consumption now matches that of entire U.S. states. Consider Meta's Hyperion AI data center: once finished, it will consume as much power as South Dakota.Meta recently announced funding for se
Meta's natural gas surge may fuel South Dakota's power grid
Data centers have grown so massive that their electricity consumption now matches that of entire U.S. states. Consider Meta's Hyperion AI data center: once finished, it will consume as much power as South Dakota.Meta recently announced funding for se

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













