
















 Дом
Дом
Meta защищает релиз Llama 4, цитирует ошибки в качестве причины отчетов о смешанных качествах
В выходные Meta, компания, стоящая за Facebook, Instagram, WhatsApp и Quest VR, удивила всех, представив свою последнюю модель искусственного интеллекта Llama 4. Было представлено не одна, а три новых версии, каждая из которых обладает улучшенными возможностями благодаря архитектуре "Mixture-of-Experts" и новому подходу к обучению под названием MetaP, который включает фиксированные гиперпараметры. Более того, все три модели имеют расширенные контекстные окна, что позволяет им обрабатывать больше информации за одно взаимодействие.
Несмотря на ажиотаж вокруг выпуска, реакция сообщества ИИ была в лучшем случае прохладной. В субботу Meta сделала две из этих моделей, Llama 4 Scout и Llama 4 Maverick, доступными для загрузки и использования, но отклик был далеко не восторженным.
Llama 4 вызывает недоумение и критику среди пользователей ИИ
Непроверенный пост на форуме 1point3acres, популярном китайскоязычном сообществе в Северной Америке, попал на сабреддит r/LocalLlama в Reddit. Пост, предположительно от исследователя из организации Meta’s GenAI, утверждал, что Llama 4 показала низкие результаты на внутренних тестах третьих сторон. В нем говорилось, что руководство Meta манипулировало результатами, смешивая тестовые наборы во время пост-обучения, чтобы соответствовать различным метрикам и представить благоприятный результат. Подлинность этого утверждения вызвала скептицизм, и Meta пока не ответила на запросы VentureBeat.
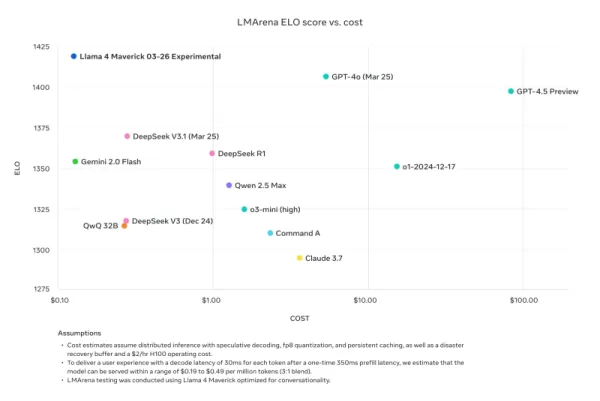
Однако сомнения в производительности Llama 4 на этом не закончились. В X пользователь @cto_junior выразил недоверие к производительности модели, ссылаясь на независимый тест, в котором Llama 4 Maverick набрала всего 16% в тесте aider polyglot benchmark, который проверяет задачи по программированию. Этот результат значительно ниже, чем у более старых моделей аналогичного размера, таких как DeepSeek V3 и Claude 3.7 Sonnet.
Доктор философии в области ИИ и автор Андрий Бурков также в X усомнился в заявленном 10-миллионном токенном контекстном окне для Llama 4 Scout, заявив, что оно "виртуальное", поскольку модель не обучалась на промптах длиннее 256 тысяч токенов. Он предупредил, что отправка более длинных промптов, скорее всего, приведет к низкокачественным результатам.
На сабреддите r/LocalLlama пользователь Dr_Karminski выразил разочарование в Llama 4, сравнивая ее низкую производительность с моделью DeepSeek V3 без рассуждений в задачах, таких как симуляция движения шара в гептагоне.
Натан Ламберт, бывший исследователь Meta и текущий старший научный сотрудник AI2, раскритиковал сравнения Meta с бенчмарками в своем блоге Interconnects Substack. Он указал, что модель Llama 4 Maverick, использованная в рекламных материалах Meta, отличается от той, что была публично выпущена, и была оптимизирована для разговорного стиля. Ламберт отметил это несоответствие, сказав: "Хитро. Результаты ниже фальшивые, и это серьезное пренебрежение к сообществу Meta, не выпустив модель, которую они использовали для своей крупной маркетинговой кампании." Он добавил, что, хотя рекламная модель "подрывает техническую репутацию релиза из-за своего инфантильного характера", реальная модель, доступная на других платформах, "довольно умная и имеет разумный тон."
Meta отвечает, отрицая "обучение на тестовых наборах" и ссылаясь на ошибки в реализации из-за быстрого выпуска
В ответ на критику и обвинения вице-президент и глава GenAI Meta Ахмад Аль-Дахле в X обратился к сообществу, чтобы развеять опасения. Он выразил энтузиазм по поводу вовлеченности сообщества в Llama 4, но признал сообщения о нестабильном качестве на разных сервисах. Он объяснил эти проблемы быстрым выпуском и временем, необходимым для стабилизации публичных реализаций. Аль-Дахле категорически опроверг обвинения в обучении на тестовых наборах, подчеркнув, что переменное качество связано с ошибками в реализации, а не с какими-либо нарушениями. Он подтвердил убежденность Meta в значительных достижениях моделей Llama 4 и их приверженность работе с сообществом для реализации их потенциала.
Однако этот ответ мало успокоил разочарование сообщества, многие по-прежнему сообщают о низкой производительности и требуют больше технической документации о процессах обучения моделей. Этот релиз столкнулся с большим количеством проблем, чем предыдущие версии Llama, что вызывает вопросы о его разработке и выпуске.
Время выпуска примечательно, поскольку оно последовало за уходом Джоэль Пино, вице-президента Meta по исследованиям, которая на прошлой неделе объявила о своем уходе в LinkedIn с благодарностью за время, проведенное в компании. Пино также продвигала семейство моделей Llama 4 в выходные.
Поскольку Llama 4 продолжает внедряться другими провайдерами с неоднозначными результатами, очевидно, что первоначальный релиз не стал тем успехом, на который могла надеяться Meta. Предстоящая конференция Meta LlamaCon 29 апреля, которая станет первым собранием для сторонних разработчиков семейства моделей, вероятно, будет полна обсуждений и споров. Мы будем внимательно следить за развитием событий, так что оставайтесь на связи.
Связанная статья
 Теперь Meta AI отвечает на сообщения покупателей на Facebook Marketplace
Facebook Marketplace внедряет новые функции Meta AI, в том числе автоматические ответы на запросы покупателей, как сообщила компания в четверг. Платформа также использует искусственный интеллект для у
Meta заключила контракт на поставку миллионов процессоров Amazon для искусственного интеллекта
Компания Amazon заключила важное партнерское соглашение с Meta, вновь сделав ставку на свои собственные чипы, разработанные по индивидуальному заказу. Как подтвердила Amazon в пятницу, Meta согласилас
Рост объемов добычи природного газа компанией Meta может обеспечить энергией энергосистему Южной Дакоты
Центры обработки данных стали настолько масштабными, что их потребление электроэнергии теперь сопоставимо с потреблением целых штатов США. Возьмем, к примеру, центр обработки данных Hyperion AI компан
Рекомендации по связанным специальным темам
Создание комиксов
Теперь Meta AI отвечает на сообщения покупателей на Facebook Marketplace
Facebook Marketplace внедряет новые функции Meta AI, в том числе автоматические ответы на запросы покупателей, как сообщила компания в четверг. Платформа также использует искусственный интеллект для у
Meta заключила контракт на поставку миллионов процессоров Amazon для искусственного интеллекта
Компания Amazon заключила важное партнерское соглашение с Meta, вновь сделав ставку на свои собственные чипы, разработанные по индивидуальному заказу. Как подтвердила Amazon в пятницу, Meta согласилас
Рост объемов добычи природного газа компанией Meta может обеспечить энергией энергосистему Южной Дакоты
Центры обработки данных стали настолько масштабными, что их потребление электроэнергии теперь сопоставимо с потреблением целых штатов США. Возьмем, к примеру, центр обработки данных Hyperion AI компан
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (11)
Комментарии (11)
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
В выходные Meta, компания, стоящая за Facebook, Instagram, WhatsApp и Quest VR, удивила всех, представив свою последнюю модель искусственного интеллекта Llama 4. Было представлено не одна, а три новых версии, каждая из которых обладает улучшенными возможностями благодаря архитектуре "Mixture-of-Experts" и новому подходу к обучению под названием MetaP, который включает фиксированные гиперпараметры. Более того, все три модели имеют расширенные контекстные окна, что позволяет им обрабатывать больше информации за одно взаимодействие.
Несмотря на ажиотаж вокруг выпуска, реакция сообщества ИИ была в лучшем случае прохладной. В субботу Meta сделала две из этих моделей, Llama 4 Scout и Llama 4 Maverick, доступными для загрузки и использования, но отклик был далеко не восторженным.
Llama 4 вызывает недоумение и критику среди пользователей ИИ
Непроверенный пост на форуме 1point3acres, популярном китайскоязычном сообществе в Северной Америке, попал на сабреддит r/LocalLlama в Reddit. Пост, предположительно от исследователя из организации Meta’s GenAI, утверждал, что Llama 4 показала низкие результаты на внутренних тестах третьих сторон. В нем говорилось, что руководство Meta манипулировало результатами, смешивая тестовые наборы во время пост-обучения, чтобы соответствовать различным метрикам и представить благоприятный результат. Подлинность этого утверждения вызвала скептицизм, и Meta пока не ответила на запросы VentureBeat.
Однако сомнения в производительности Llama 4 на этом не закончились. В X пользователь @cto_junior выразил недоверие к производительности модели, ссылаясь на независимый тест, в котором Llama 4 Maverick набрала всего 16% в тесте aider polyglot benchmark, который проверяет задачи по программированию. Этот результат значительно ниже, чем у более старых моделей аналогичного размера, таких как DeepSeek V3 и Claude 3.7 Sonnet.
Доктор философии в области ИИ и автор Андрий Бурков также в X усомнился в заявленном 10-миллионном токенном контекстном окне для Llama 4 Scout, заявив, что оно "виртуальное", поскольку модель не обучалась на промптах длиннее 256 тысяч токенов. Он предупредил, что отправка более длинных промптов, скорее всего, приведет к низкокачественным результатам.
На сабреддите r/LocalLlama пользователь Dr_Karminski выразил разочарование в Llama 4, сравнивая ее низкую производительность с моделью DeepSeek V3 без рассуждений в задачах, таких как симуляция движения шара в гептагоне.
Натан Ламберт, бывший исследователь Meta и текущий старший научный сотрудник AI2, раскритиковал сравнения Meta с бенчмарками в своем блоге Interconnects Substack. Он указал, что модель Llama 4 Maverick, использованная в рекламных материалах Meta, отличается от той, что была публично выпущена, и была оптимизирована для разговорного стиля. Ламберт отметил это несоответствие, сказав: "Хитро. Результаты ниже фальшивые, и это серьезное пренебрежение к сообществу Meta, не выпустив модель, которую они использовали для своей крупной маркетинговой кампании." Он добавил, что, хотя рекламная модель "подрывает техническую репутацию релиза из-за своего инфантильного характера", реальная модель, доступная на других платформах, "довольно умная и имеет разумный тон."
Meta отвечает, отрицая "обучение на тестовых наборах" и ссылаясь на ошибки в реализации из-за быстрого выпуска
В ответ на критику и обвинения вице-президент и глава GenAI Meta Ахмад Аль-Дахле в X обратился к сообществу, чтобы развеять опасения. Он выразил энтузиазм по поводу вовлеченности сообщества в Llama 4, но признал сообщения о нестабильном качестве на разных сервисах. Он объяснил эти проблемы быстрым выпуском и временем, необходимым для стабилизации публичных реализаций. Аль-Дахле категорически опроверг обвинения в обучении на тестовых наборах, подчеркнув, что переменное качество связано с ошибками в реализации, а не с какими-либо нарушениями. Он подтвердил убежденность Meta в значительных достижениях моделей Llama 4 и их приверженность работе с сообществом для реализации их потенциала.
Однако этот ответ мало успокоил разочарование сообщества, многие по-прежнему сообщают о низкой производительности и требуют больше технической документации о процессах обучения моделей. Этот релиз столкнулся с большим количеством проблем, чем предыдущие версии Llama, что вызывает вопросы о его разработке и выпуске.
Время выпуска примечательно, поскольку оно последовало за уходом Джоэль Пино, вице-президента Meta по исследованиям, которая на прошлой неделе объявила о своем уходе в LinkedIn с благодарностью за время, проведенное в компании. Пино также продвигала семейство моделей Llama 4 в выходные.
Поскольку Llama 4 продолжает внедряться другими провайдерами с неоднозначными результатами, очевидно, что первоначальный релиз не стал тем успехом, на который могла надеяться Meta. Предстоящая конференция Meta LlamaCon 29 апреля, которая станет первым собранием для сторонних разработчиков семейства моделей, вероятно, будет полна обсуждений и споров. Мы будем внимательно следить за развитием событий, так что оставайтесь на связи.










 Теперь Meta AI отвечает на сообщения покупателей на Facebook Marketplace
Facebook Marketplace внедряет новые функции Meta AI, в том числе автоматические ответы на запросы покупателей, как сообщила компания в четверг. Платформа также использует искусственный интеллект для у
Теперь Meta AI отвечает на сообщения покупателей на Facebook Marketplace
Facebook Marketplace внедряет новые функции Meta AI, в том числе автоматические ответы на запросы покупателей, как сообщила компания в четверг. Платформа также использует искусственный интеллект для у
 Meta заключила контракт на поставку миллионов процессоров Amazon для искусственного интеллекта
Компания Amazon заключила важное партнерское соглашение с Meta, вновь сделав ставку на свои собственные чипы, разработанные по индивидуальному заказу. Как подтвердила Amazon в пятницу, Meta согласилас
Meta заключила контракт на поставку миллионов процессоров Amazon для искусственного интеллекта
Компания Amazon заключила важное партнерское соглашение с Meta, вновь сделав ставку на свои собственные чипы, разработанные по индивидуальному заказу. Как подтвердила Amazon в пятницу, Meta согласилас
 Рост объемов добычи природного газа компанией Meta может обеспечить энергией энергосистему Южной Дакоты
Центры обработки данных стали настолько масштабными, что их потребление электроэнергии теперь сопоставимо с потреблением целых штатов США. Возьмем, к примеру, центр обработки данных Hyperion AI компан
Рост объемов добычи природного газа компанией Meta может обеспечить энергией энергосистему Южной Дакоты
Центры обработки данных стали настолько масштабными, что их потребление электроэнергии теперь сопоставимо с потреблением целых штатов США. Возьмем, к примеру, центр обработки данных Hyperion AI компан

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













