
















 Heim
Heim
Meta verteidigt LLAMA 4 Release, zitiert Fehler als Ursache für Berichte mit gemischter Qualität
Am Wochenende überraschte Meta, das Kraftpaket hinter Facebook, Instagram, WhatsApp und Quest VR, alle mit der Vorstellung ihres neuesten KI-Sprachmodells, Llama 4. Nicht nur eines, sondern drei neue Versionen wurden eingeführt, jede mit verbesserten Fähigkeiten dank der "Mixture-of-Experts"-Architektur und einem neuartigen Trainingsansatz namens MetaP, der feste Hyperparameter verwendet. Darüber hinaus verfügen alle drei Modelle über erweiterte Kontextfenster, die es ihnen ermöglichen, mehr Informationen in einer einzigen Interaktion zu verarbeiten.
Trotz der Aufregung um die Veröffentlichung war die Reaktion der KI-Community bestenfalls verhalten. Am Samstag stellte Meta zwei dieser Modelle, Llama 4 Scout und Llama 4 Maverick, zum Download und zur Nutzung bereit, aber die Resonanz war alles andere als enthusiastisch.
Llama 4 löst Verwirrung und Kritik unter KI-Nutzern aus
Ein unbestätigter Beitrag im 1point3acres-Forum, einer beliebten chinesischsprachigen Community in Nordamerika, fand seinen Weg in das r/LocalLlama-Subreddit auf Reddit. Der Beitrag, angeblich von einem Forscher der GenAI-Organisation von Meta, behauptete, dass Llama 4 bei internen Benchmarks von Drittanbietern schlecht abgeschnitten habe. Es wurde angedeutet, dass die Führung von Meta die Ergebnisse manipuliert habe, indem sie Testsets während des Post-Trainings vermischte, um verschiedene Metriken zu erfüllen und ein positives Ergebnis zu präsentieren. Die Authentizität dieser Behauptung wurde mit Skepsis aufgenommen, und Meta hat bisher nicht auf Anfragen von VentureBeat reagiert.
Doch die Zweifel an der Leistung von Llama 4 hörten damit nicht auf. Auf X äußerte der Nutzer @cto_junior Unglauben über die Leistung des Modells und verwies auf einen unabhängigen Test, bei dem Llama 4 Maverick im aider-Polyglot-Benchmark, der Programmieraufgaben testet, nur 16 % erreichte. Dieser Wert liegt deutlich unter dem älterer, ähnlich großer Modelle wie DeepSeek V3 und Claude 3.7 Sonnet.
KI-Doktor und Autor Andriy Burkov nutzte ebenfalls X, um das beworbene 10-Millionen-Token-Kontextfenster von Llama 4 Scout in Frage zu stellen und erklärte, es sei "virtuell", da das Modell nicht mit Prompts trainiert wurde, die länger als 256k Token sind. Er warnte, dass längere Prompts wahrscheinlich zu minderwertigen Ergebnissen führen würden.
Im r/LocalLlama-Subreddit äußerte der Nutzer Dr_Karminski Enttäuschung über Llama 4 und verglich dessen schlechte Leistung mit dem nicht-räsonierenden V3-Modell von DeepSeek bei Aufgaben wie der Simulation von Ballbewegungen in einem Heptagon.
Nathan Lambert, ein ehemaliger Meta-Forscher und aktueller Senior Research Scientist bei AI2, kritisierte Metas Benchmark-Vergleiche in seinem Interconnects-Substack-Blog. Er wies darauf hin, dass das in Metas Werbematerialien verwendete Llama 4 Maverick-Modell nicht dasselbe war wie das öffentlich freigegebene, sondern für Konversation optimiert wurde. Lambert bemerkte den Widerspruch und sagte: „Hinterlistig. Die untenstehenden Ergebnisse sind gefälscht, und es ist ein großer Affront gegen die Community von Meta, nicht das Modell zu veröffentlichen, das sie für ihre große Marketingkampagne verwendet haben.“ Er fügte hinzu, dass das beworbene Modell „den technischen Ruf der Veröffentlichung ruiniert, weil sein Charakter jugendlich ist“, während das tatsächlich auf anderen Plattformen verfügbare Modell „ziemlich klug ist und einen angemessenen Ton hat“.
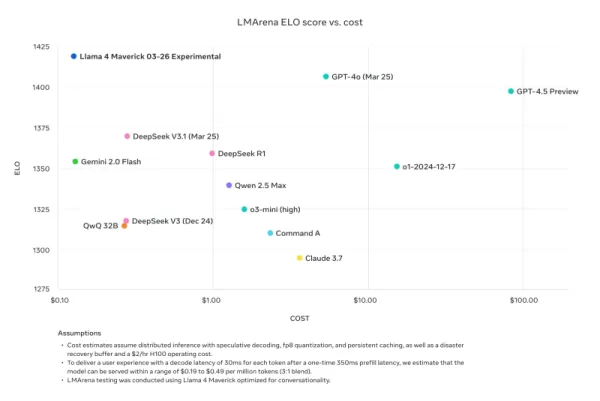
Meta reagiert, bestreitet „Training mit Testsets“ und verweist auf Fehler in der Implementierung aufgrund der schnellen Einführung
Als Reaktion auf die Kritik und Anschuldigungen ging Ahmad Al-Dahle, Vizepräsident und Leiter von GenAI bei Meta, auf X, um die Bedenken anzusprechen. Er zeigte sich begeistert von der Beteiligung der Community an Llama 4, räumte jedoch Berichte über uneinheitliche Qualität bei verschiedenen Diensten ein. Er führte diese Probleme auf die schnelle Einführung und die Zeit zurück, die für die Stabilisierung öffentlicher Implementierungen benötigt wird. Al-Dahle wies die Vorwürfe des Trainings mit Testsets entschieden zurück und betonte, dass die variable Qualität auf Implementierungsfehler und nicht auf Fehlverhalten zurückzuführen sei. Er bekräftigte Metas Glauben an die bedeutenden Fortschritte der Llama 4-Modelle und ihr Engagement, mit der Community zusammenzuarbeiten, um ihr Potenzial zu verwirklichen.
Die Antwort konnte die Frustrationen der Community jedoch kaum lindern, da viele weiterhin von schlechter Leistung berichteten und mehr technische Dokumentation über die Trainingsprozesse der Modelle forderten. Diese Veröffentlichung hatte mehr Probleme als frühere Llama-Versionen, was Fragen zu ihrer Entwicklung und Einführung aufwirft.
Das Timing dieser Veröffentlichung ist bemerkenswert, da sie auf den Abgang von Joelle Pineau folgt, der Vizepräsidentin für Forschung bei Meta, die letzte Woche auf LinkedIn ihren Ausstieg mit Dank für ihre Zeit im Unternehmen bekannt gab. Pineau hatte am Wochenende auch die Llama 4-Modellfamilie beworben.
Da Llama 4 weiterhin von anderen Inferenzanbietern mit gemischten Ergebnissen übernommen wird, ist klar, dass die anfängliche Veröffentlichung nicht der Erfolg war, den Meta sich erhofft haben könnte. Die bevorstehende Meta LlamaCon am 29. April, das erste Treffen für Drittentwickler der Modellfamilie, wird wahrscheinlich ein Brennpunkt für Diskussionen und Debatten sein. Wir werden die Entwicklungen genau im Auge behalten, also bleiben Sie dran.
Verwandter Artikel
 Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Der Erdgasboom bei Meta könnte das Stromnetz von South Dakota ankurbeln
Rechenzentren sind mittlerweile so riesig geworden, dass ihr Stromverbrauch dem ganzer US-Bundesstaaten entspricht. Man denke nur an das Hyperion-KI-Rechenzentrum von Meta: Nach seiner Fertigstellung
Empfehlungen zu verwandten Spezialthemen
Geschäft
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Der Erdgasboom bei Meta könnte das Stromnetz von South Dakota ankurbeln
Rechenzentren sind mittlerweile so riesig geworden, dass ihr Stromverbrauch dem ganzer US-Bundesstaaten entspricht. Man denke nur an das Hyperion-KI-Rechenzentrum von Meta: Nach seiner Fertigstellung
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
 10 Tools
10 Tools
 xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

 Kommentare (11)
Kommentare (11)
![PaulGonzalez]()
Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
![WalterHarris]()
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
![HenryBrown]()
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
![JohnWilson]()
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
![HarryRoberts]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
![ArthurJones]()
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙
Am Wochenende überraschte Meta, das Kraftpaket hinter Facebook, Instagram, WhatsApp und Quest VR, alle mit der Vorstellung ihres neuesten KI-Sprachmodells, Llama 4. Nicht nur eines, sondern drei neue Versionen wurden eingeführt, jede mit verbesserten Fähigkeiten dank der "Mixture-of-Experts"-Architektur und einem neuartigen Trainingsansatz namens MetaP, der feste Hyperparameter verwendet. Darüber hinaus verfügen alle drei Modelle über erweiterte Kontextfenster, die es ihnen ermöglichen, mehr Informationen in einer einzigen Interaktion zu verarbeiten.
Trotz der Aufregung um die Veröffentlichung war die Reaktion der KI-Community bestenfalls verhalten. Am Samstag stellte Meta zwei dieser Modelle, Llama 4 Scout und Llama 4 Maverick, zum Download und zur Nutzung bereit, aber die Resonanz war alles andere als enthusiastisch.
Llama 4 löst Verwirrung und Kritik unter KI-Nutzern aus
Ein unbestätigter Beitrag im 1point3acres-Forum, einer beliebten chinesischsprachigen Community in Nordamerika, fand seinen Weg in das r/LocalLlama-Subreddit auf Reddit. Der Beitrag, angeblich von einem Forscher der GenAI-Organisation von Meta, behauptete, dass Llama 4 bei internen Benchmarks von Drittanbietern schlecht abgeschnitten habe. Es wurde angedeutet, dass die Führung von Meta die Ergebnisse manipuliert habe, indem sie Testsets während des Post-Trainings vermischte, um verschiedene Metriken zu erfüllen und ein positives Ergebnis zu präsentieren. Die Authentizität dieser Behauptung wurde mit Skepsis aufgenommen, und Meta hat bisher nicht auf Anfragen von VentureBeat reagiert.
Doch die Zweifel an der Leistung von Llama 4 hörten damit nicht auf. Auf X äußerte der Nutzer @cto_junior Unglauben über die Leistung des Modells und verwies auf einen unabhängigen Test, bei dem Llama 4 Maverick im aider-Polyglot-Benchmark, der Programmieraufgaben testet, nur 16 % erreichte. Dieser Wert liegt deutlich unter dem älterer, ähnlich großer Modelle wie DeepSeek V3 und Claude 3.7 Sonnet.
KI-Doktor und Autor Andriy Burkov nutzte ebenfalls X, um das beworbene 10-Millionen-Token-Kontextfenster von Llama 4 Scout in Frage zu stellen und erklärte, es sei "virtuell", da das Modell nicht mit Prompts trainiert wurde, die länger als 256k Token sind. Er warnte, dass längere Prompts wahrscheinlich zu minderwertigen Ergebnissen führen würden.
Im r/LocalLlama-Subreddit äußerte der Nutzer Dr_Karminski Enttäuschung über Llama 4 und verglich dessen schlechte Leistung mit dem nicht-räsonierenden V3-Modell von DeepSeek bei Aufgaben wie der Simulation von Ballbewegungen in einem Heptagon.
Nathan Lambert, ein ehemaliger Meta-Forscher und aktueller Senior Research Scientist bei AI2, kritisierte Metas Benchmark-Vergleiche in seinem Interconnects-Substack-Blog. Er wies darauf hin, dass das in Metas Werbematerialien verwendete Llama 4 Maverick-Modell nicht dasselbe war wie das öffentlich freigegebene, sondern für Konversation optimiert wurde. Lambert bemerkte den Widerspruch und sagte: „Hinterlistig. Die untenstehenden Ergebnisse sind gefälscht, und es ist ein großer Affront gegen die Community von Meta, nicht das Modell zu veröffentlichen, das sie für ihre große Marketingkampagne verwendet haben.“ Er fügte hinzu, dass das beworbene Modell „den technischen Ruf der Veröffentlichung ruiniert, weil sein Charakter jugendlich ist“, während das tatsächlich auf anderen Plattformen verfügbare Modell „ziemlich klug ist und einen angemessenen Ton hat“.
Meta reagiert, bestreitet „Training mit Testsets“ und verweist auf Fehler in der Implementierung aufgrund der schnellen Einführung
Als Reaktion auf die Kritik und Anschuldigungen ging Ahmad Al-Dahle, Vizepräsident und Leiter von GenAI bei Meta, auf X, um die Bedenken anzusprechen. Er zeigte sich begeistert von der Beteiligung der Community an Llama 4, räumte jedoch Berichte über uneinheitliche Qualität bei verschiedenen Diensten ein. Er führte diese Probleme auf die schnelle Einführung und die Zeit zurück, die für die Stabilisierung öffentlicher Implementierungen benötigt wird. Al-Dahle wies die Vorwürfe des Trainings mit Testsets entschieden zurück und betonte, dass die variable Qualität auf Implementierungsfehler und nicht auf Fehlverhalten zurückzuführen sei. Er bekräftigte Metas Glauben an die bedeutenden Fortschritte der Llama 4-Modelle und ihr Engagement, mit der Community zusammenzuarbeiten, um ihr Potenzial zu verwirklichen.
Die Antwort konnte die Frustrationen der Community jedoch kaum lindern, da viele weiterhin von schlechter Leistung berichteten und mehr technische Dokumentation über die Trainingsprozesse der Modelle forderten. Diese Veröffentlichung hatte mehr Probleme als frühere Llama-Versionen, was Fragen zu ihrer Entwicklung und Einführung aufwirft.
Das Timing dieser Veröffentlichung ist bemerkenswert, da sie auf den Abgang von Joelle Pineau folgt, der Vizepräsidentin für Forschung bei Meta, die letzte Woche auf LinkedIn ihren Ausstieg mit Dank für ihre Zeit im Unternehmen bekannt gab. Pineau hatte am Wochenende auch die Llama 4-Modellfamilie beworben.
Da Llama 4 weiterhin von anderen Inferenzanbietern mit gemischten Ergebnissen übernommen wird, ist klar, dass die anfängliche Veröffentlichung nicht der Erfolg war, den Meta sich erhofft haben könnte. Die bevorstehende Meta LlamaCon am 29. April, das erste Treffen für Drittentwickler der Modellfamilie, wird wahrscheinlich ein Brennpunkt für Diskussionen und Debatten sein. Wir werden die Entwicklungen genau im Auge behalten, also bleiben Sie dran.










 Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
 Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
 Der Erdgasboom bei Meta könnte das Stromnetz von South Dakota ankurbeln
Rechenzentren sind mittlerweile so riesig geworden, dass ihr Stromverbrauch dem ganzer US-Bundesstaaten entspricht. Man denke nur an das Hyperion-KI-Rechenzentrum von Meta: Nach seiner Fertigstellung
Der Erdgasboom bei Meta könnte das Stromnetz von South Dakota ankurbeln
Rechenzentren sind mittlerweile so riesig geworden, dass ihr Stromverbrauch dem ganzer US-Bundesstaaten entspricht. Man denke nur an das Hyperion-KI-Rechenzentrum von Meta: Nach seiner Fertigstellung

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Meta hat mal wieder die AI-Welt aufgemischt! Llama 4 klingt nach einem riesigen Schritt, aber die Meldungen über gemischte Qualität wegen Bugs sind irgendwie enttäuschend. 🤔 Finde es trotzdem cool, dass sie so transparent sind und die Probleme direkt ansprechen – das ist bei Tech-Giganten nicht immer selbstverständlich. Hoffentlich kriegen sie die Fehler schnell in den Griff, sonst könnte das Vertrauen in die Modelle leiden. Die MoE-Architektur an sich ist ja mega spannend!
Hmm, Meta's Llama 4-Release sorgt also für gemischte Qualitätsberichte und sie schieben es auf Bugs? Interessant. Kann es nicht einfach sein, dass das MoE-Design in der Praxis schwieriger zu beherrschen ist, als in der Theorie versprochen? Die Eile, mit der die großen Tech-Konzerne KI pushen, macht mich nachdenklich. Kommen diese 'Verbesserungen' überhaupt bei den normalen Anwendern an, wo es wirklich zählt? Irgendwie ein klassisches 'Release jetzt, Patch später'-Szenario... 🤔
Meta qui sort encore un modèle en catimini avec des bugs... Original cette stratégie de 'test en production' sur des millions d'utilisateurs 🙄 Ça me rappelle les mises à jour foireuses d'Instagram ! #BetaTestGéant
Meta's Llama 4 drop was wild! Three versions with that fancy Mixture-of-Experts setup? Sounds powerful, but those bugs they mentioned make me wonder if it’s ready for prime time. Anyone tried it yet? 🧐
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? Kinda feels like Meta rushed this out to beat the competition. Hope they patch it up soon! 🦙
Wow, Llama 4 sounds like a beast with that Mixture-of-Experts setup! But bugs causing mixed quality? That’s a bit concerning for a big player like Meta. Hope they iron it out soon, I’m curious to see how it stacks up against other models! 🦙













