
















 Home
Home
Global First Event-Level Embodied Intelligence World Model Ends Frame-by-Frame Learning for Robots
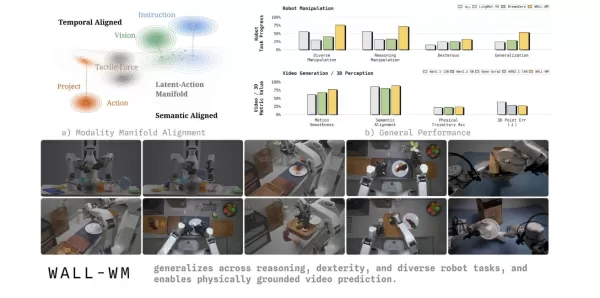
On May 29, the Variable Robot team unveiled WALL-WM, the world’s first embodied intelligence world model built on “event-level prediction.” This model breaks free from conventional embodied large models that learn actions frame by frame over time, instead switching the world model’s prediction unit to semantic events. It marks a new stage in how robots understand and carry out tasks.

In the current embodied intelligence industry, mainstream vision-language-action (VLA) models typically take a current image and instruction to predict a fixed-length action block. This frame-by-frame training approach often causes robots to focus on minor physical movements while losing sight of the action’s ultimate goal. When faced with scenarios like changing cups or tables, robots frequently fail due to a lack of generalization. To address this industry pain point, the Variable team pointed out in their academic paper that text, vision, and action information naturally exist at different time scales and manifold geometries in the real world. Forcing them into a single shared space can easily damage the pre-trained geometric prior.
To tackle this challenge, the WALL-WM world model introduces an innovative event-centered training and execution mechanism. It breaks down complex tasks into semantically clear event joints, such as reaching, grasping, and moving. In operation, the model no longer rigidly computes the next image frame. Instead, it first simulates how the world will change due to the next event, then precisely translates that visual change into the robotic arm’s motion trajectory.
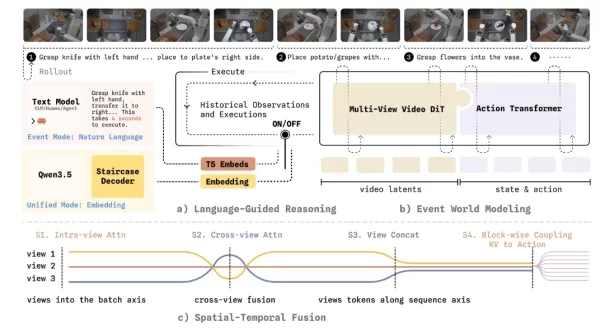
To ensure this new architecture can be reliably deployed in the physical world, the Variable Robot team carried out a series of hardcore engineering overhauls. The system supports flexible switching between “event mode” (with variable-length action output) and “unified mode” (with real-time closed-loop control) on the same base weights. It also achieves one-way coupling between video models and action models, preventing valuable dynamic priors from internet videos from being prematurely biased by action data. For geometric perception across multiple cameras, the model introduces frustum masks and tubular masks, forcing the AI to develop cross-view true three-dimensional geometric correspondence. To address decision latency, it employs a new “stepped chain-of-thought decoding” technique that significantly reduces decoding delay while maintaining logical interpretability.
Related article
 OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Productivity
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Productivity
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
 10 tools
10 tools
 xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
On May 29, the Variable Robot team unveiled WALL-WM, the world’s first embodied intelligence world model built on “event-level prediction.” This model breaks free from conventional embodied large models that learn actions frame by frame over time, instead switching the world model’s prediction unit to semantic events. It marks a new stage in how robots understand and carry out tasks.
In the current embodied intelligence industry, mainstream vision-language-action (VLA) models typically take a current image and instruction to predict a fixed-length action block. This frame-by-frame training approach often causes robots to focus on minor physical movements while losing sight of the action’s ultimate goal. When faced with scenarios like changing cups or tables, robots frequently fail due to a lack of generalization. To address this industry pain point, the Variable team pointed out in their academic paper that text, vision, and action information naturally exist at different time scales and manifold geometries in the real world. Forcing them into a single shared space can easily damage the pre-trained geometric prior.
To tackle this challenge, the WALL-WM world model introduces an innovative event-centered training and execution mechanism. It breaks down complex tasks into semantically clear event joints, such as reaching, grasping, and moving. In operation, the model no longer rigidly computes the next image frame. Instead, it first simulates how the world will change due to the next event, then precisely translates that visual change into the robotic arm’s motion trajectory.
To ensure this new architecture can be reliably deployed in the physical world, the Variable Robot team carried out a series of hardcore engineering overhauls. The system supports flexible switching between “event mode” (with variable-length action output) and “unified mode” (with real-time closed-loop control) on the same base weights. It also achieves one-way coupling between video models and action models, preventing valuable dynamic priors from internet videos from being prematurely biased by action data. For geometric perception across multiple cameras, the model introduces frustum masks and tubular masks, forcing the AI to develop cross-view true three-dimensional geometric correspondence. To address decision latency, it employs a new “stepped chain-of-thought decoding” technique that significantly reduces decoding delay while maintaining logical interpretability.










 OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
 Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai













