
















 Hogar
Hogar
El primer modelo mundial de inteligencia incorporada a nivel de eventos pone fin al aprendizaje fotograma a fotograma para los robots
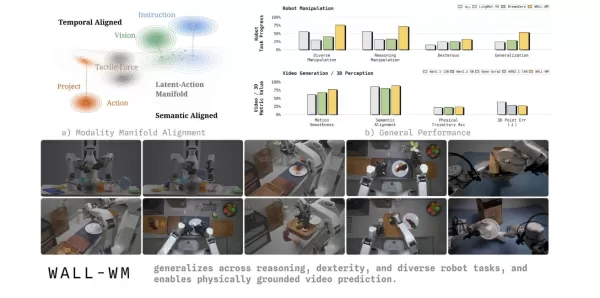
El 29 de mayo, el equipo de Variable Robot presentó WALL-WM, el primer modelo del mundo de inteligencia incorporada basado en la «predicción a nivel de eventos». Este modelo se aleja de los grandes modelos de inteligencia incorporada convencionales, que aprenden acciones fotograma a fotograma a lo largo del tiempo, y cambia la unidad de predicción del modelo del mundo a eventos semánticos. Esto marca una nueva etapa en la forma en que los robots comprenden y llevan a cabo tareas.

En la industria actual de la inteligencia incorporada, los modelos dominantes de visión-lenguaje-acción (VLA) suelen tomar una imagen y una instrucción actuales para predecir un bloque de acción de longitud fija. Este enfoque de entrenamiento fotograma a fotograma a menudo hace que los robots se centren en movimientos físicos menores, perdiendo de vista el objetivo final de la acción. Cuando se enfrentan a situaciones como el cambio de tazas o mesas, los robots suelen fallar debido a la falta de generalización. Para abordar este punto débil del sector, el equipo de Variable señaló en su artículo académico que la información de texto, visión y acción existe de forma natural en diferentes escalas temporales y geometrías múltiples en el mundo real. Forzarlas a un único espacio compartido puede dañar fácilmente el prior geométrico preentrenado.
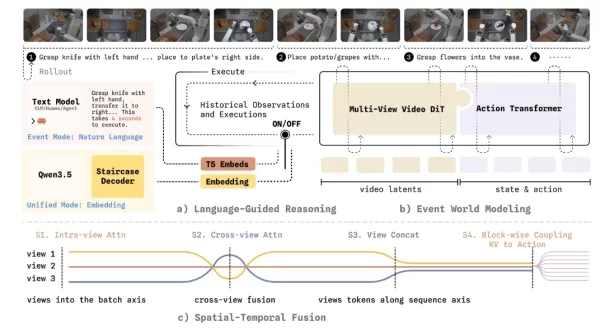
Para hacer frente a este reto, el modelo de mundo WALL-WM introduce un innovador mecanismo de entrenamiento y ejecución centrado en eventos. Desglosa tareas complejas en eventos semánticamente claros, como alcanzar, agarrar y mover. En funcionamiento, el modelo ya no calcula de forma rígida el siguiente fotograma de la imagen. En su lugar, primero simula cómo cambiará el mundo debido al siguiente evento y, a continuación, traduce con precisión ese cambio visual en la trayectoria de movimiento del brazo robótico.
Para garantizar que esta nueva arquitectura pueda implementarse de forma fiable en el mundo físico, el equipo de Variable Robot llevó a cabo una serie de revisiones de ingeniería exhaustivas. El sistema admite el cambio flexible entre el «modo de eventos» (con salida de acciones de longitud variable) y el «modo unificado» (con control de bucle cerrado en tiempo real) sobre los mismos pesos base. También logra un acoplamiento unidireccional entre los modelos de vídeo y los modelos de acción, lo que evita que los valiosos datos dinámicos previos de los vídeos de Internet se vean sesgados prematuramente por los datos de acción. Para la percepción geométrica a través de múltiples cámaras, el modelo introduce máscaras de frustum y máscaras tubulares, lo que obliga a la IA a desarrollar una correspondencia geométrica tridimensional verdadera entre vistas. Para abordar la latencia en la toma de decisiones, emplea una nueva técnica de «decodificación por cadena de pensamiento escalonada» que reduce significativamente el retraso en la decodificación al tiempo que mantiene la interpretabilidad lógica.
Artículo relacionado
 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Recomendaciones de temas especiales relacionados
Negocio
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
El 29 de mayo, el equipo de Variable Robot presentó WALL-WM, el primer modelo del mundo de inteligencia incorporada basado en la «predicción a nivel de eventos». Este modelo se aleja de los grandes modelos de inteligencia incorporada convencionales, que aprenden acciones fotograma a fotograma a lo largo del tiempo, y cambia la unidad de predicción del modelo del mundo a eventos semánticos. Esto marca una nueva etapa en la forma en que los robots comprenden y llevan a cabo tareas.
En la industria actual de la inteligencia incorporada, los modelos dominantes de visión-lenguaje-acción (VLA) suelen tomar una imagen y una instrucción actuales para predecir un bloque de acción de longitud fija. Este enfoque de entrenamiento fotograma a fotograma a menudo hace que los robots se centren en movimientos físicos menores, perdiendo de vista el objetivo final de la acción. Cuando se enfrentan a situaciones como el cambio de tazas o mesas, los robots suelen fallar debido a la falta de generalización. Para abordar este punto débil del sector, el equipo de Variable señaló en su artículo académico que la información de texto, visión y acción existe de forma natural en diferentes escalas temporales y geometrías múltiples en el mundo real. Forzarlas a un único espacio compartido puede dañar fácilmente el prior geométrico preentrenado.
Para hacer frente a este reto, el modelo de mundo WALL-WM introduce un innovador mecanismo de entrenamiento y ejecución centrado en eventos. Desglosa tareas complejas en eventos semánticamente claros, como alcanzar, agarrar y mover. En funcionamiento, el modelo ya no calcula de forma rígida el siguiente fotograma de la imagen. En su lugar, primero simula cómo cambiará el mundo debido al siguiente evento y, a continuación, traduce con precisión ese cambio visual en la trayectoria de movimiento del brazo robótico.
Para garantizar que esta nueva arquitectura pueda implementarse de forma fiable en el mundo físico, el equipo de Variable Robot llevó a cabo una serie de revisiones de ingeniería exhaustivas. El sistema admite el cambio flexible entre el «modo de eventos» (con salida de acciones de longitud variable) y el «modo unificado» (con control de bucle cerrado en tiempo real) sobre los mismos pesos base. También logra un acoplamiento unidireccional entre los modelos de vídeo y los modelos de acción, lo que evita que los valiosos datos dinámicos previos de los vídeos de Internet se vean sesgados prematuramente por los datos de acción. Para la percepción geométrica a través de múltiples cámaras, el modelo introduce máscaras de frustum y máscaras tubulares, lo que obliga a la IA a desarrollar una correspondencia geométrica tridimensional verdadera entre vistas. Para abordar la latencia en la toma de decisiones, emplea una nueva técnica de «decodificación por cadena de pensamiento escalonada» que reduce significativamente el retraso en la decodificación al tiempo que mantiene la interpretabilidad lógica.










 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
 OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













