
















 Heim
Heim
Das weltweit erste auf Ereignisebene basierende Weltmodell für verkörperte Intelligenz macht dem frameweisen Lernen für Roboter ein Ende
Am 29. Mai stellte das Team von Variable Robot WALL-WM vor, das weltweit erste Weltmodell mit verkörperter Intelligenz, das auf „Vorhersagen auf Ereignisebene“ basiert. Dieses Modell löst sich von herkömmlichen großen Modellen der verkörperten Intelligenz, die Aktionen im Laufe der Zeit Frame für Frame lernen, und verlagert stattdessen die Vorhersageeinheit des Weltmodells auf semantische Ereignisse. Es markiert eine neue Etappe in der Art und Weise, wie Roboter Aufgaben verstehen und ausführen.

In der aktuellen Branche der verkörperten Intelligenz verwenden gängige Vision-Language-Action-Modelle (VLA) in der Regel ein aktuelles Bild und eine Anweisung, um einen Aktionsblock fester Länge vorherzusagen. Dieser Frame-für-Frame-Trainingsansatz führt oft dazu, dass sich Roboter auf kleine körperliche Bewegungen konzentrieren und dabei das eigentliche Ziel der Aktion aus den Augen verlieren. In Szenarien wie dem Wechseln von Tassen oder Tischen scheitern Roboter häufig aufgrund mangelnder Generalisierungsfähigkeit. Um diesen Schwachpunkt der Branche anzugehen, wies das Variable-Team in seiner wissenschaftlichen Arbeit darauf hin, dass Text-, Bild- und Handlungsinformationen in der realen Welt naturgemäß auf unterschiedlichen Zeitskalen und in vielfältigen Geometrien existieren. Werden diese in einen einzigen gemeinsamen Raum gezwängt, kann dies leicht die vortrainierte geometrische Priorität beeinträchtigen.
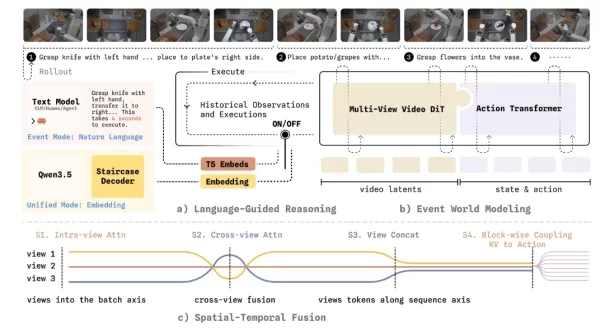
Um diese Herausforderung zu bewältigen, führt das WALL-WM-Weltmodell einen innovativen ereigniszentrierten Trainings- und Ausführungsmechanismus ein. Es zerlegt komplexe Aufgaben in semantisch klare Ereignisverbindungen wie Greifen, Ergreifen und Bewegen. Im Betrieb berechnet das Modell den nächsten Bildframe nicht mehr starr. Stattdessen simuliert es zunächst, wie sich die Welt durch das nächste Ereignis verändern wird, und übersetzt diese visuelle Veränderung dann präzise in die Bewegungsbahn des Roboterarms.
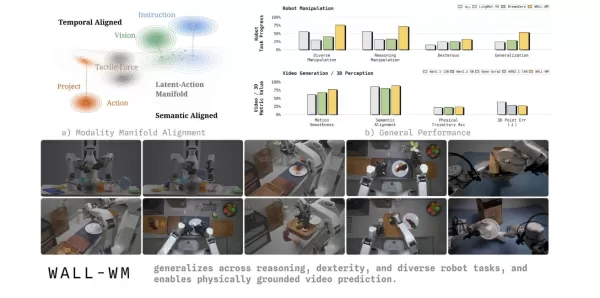
Um sicherzustellen, dass diese neue Architektur zuverlässig in der physischen Welt eingesetzt werden kann, führte das Variable-Robot-Team eine Reihe umfassender technischer Überarbeitungen durch. Das System unterstützt den flexiblen Wechsel zwischen dem „Ereignismodus“ (mit Aktionsausgabe variabler Länge) und dem „Unified-Modus“ (mit Echtzeit-Regelung) auf Basis derselben Grundgewichte. Außerdem erreicht es eine Einwegkopplung zwischen Videomodellen und Aktionsmodellen, wodurch verhindert wird, dass wertvolle dynamische Vorinformationen aus Internetvideos vorzeitig durch Aktionsdaten verzerrt werden. Für die geometrische Wahrnehmung über mehrere Kameras hinweg führt das Modell Frustum-Masken und röhrenförmige Masken ein, wodurch die KI gezwungen wird, eine sichtfeldübergreifende, echte dreidimensionale geometrische Entsprechung zu entwickeln. Um die Entscheidungslatenz zu verringern, wird eine neue „Stepped Chain-of-Thought Decoding“-Technik eingesetzt, die die Dekodierungsverzögerung deutlich reduziert und gleichzeitig die logische Interpretierbarkeit gewährleistet.
Verwandter Artikel
 Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Empfehlungen zu verwandten Spezialthemen
Geschäft
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Am 29. Mai stellte das Team von Variable Robot WALL-WM vor, das weltweit erste Weltmodell mit verkörperter Intelligenz, das auf „Vorhersagen auf Ereignisebene“ basiert. Dieses Modell löst sich von herkömmlichen großen Modellen der verkörperten Intelligenz, die Aktionen im Laufe der Zeit Frame für Frame lernen, und verlagert stattdessen die Vorhersageeinheit des Weltmodells auf semantische Ereignisse. Es markiert eine neue Etappe in der Art und Weise, wie Roboter Aufgaben verstehen und ausführen.
In der aktuellen Branche der verkörperten Intelligenz verwenden gängige Vision-Language-Action-Modelle (VLA) in der Regel ein aktuelles Bild und eine Anweisung, um einen Aktionsblock fester Länge vorherzusagen. Dieser Frame-für-Frame-Trainingsansatz führt oft dazu, dass sich Roboter auf kleine körperliche Bewegungen konzentrieren und dabei das eigentliche Ziel der Aktion aus den Augen verlieren. In Szenarien wie dem Wechseln von Tassen oder Tischen scheitern Roboter häufig aufgrund mangelnder Generalisierungsfähigkeit. Um diesen Schwachpunkt der Branche anzugehen, wies das Variable-Team in seiner wissenschaftlichen Arbeit darauf hin, dass Text-, Bild- und Handlungsinformationen in der realen Welt naturgemäß auf unterschiedlichen Zeitskalen und in vielfältigen Geometrien existieren. Werden diese in einen einzigen gemeinsamen Raum gezwängt, kann dies leicht die vortrainierte geometrische Priorität beeinträchtigen.
Um diese Herausforderung zu bewältigen, führt das WALL-WM-Weltmodell einen innovativen ereigniszentrierten Trainings- und Ausführungsmechanismus ein. Es zerlegt komplexe Aufgaben in semantisch klare Ereignisverbindungen wie Greifen, Ergreifen und Bewegen. Im Betrieb berechnet das Modell den nächsten Bildframe nicht mehr starr. Stattdessen simuliert es zunächst, wie sich die Welt durch das nächste Ereignis verändern wird, und übersetzt diese visuelle Veränderung dann präzise in die Bewegungsbahn des Roboterarms.
Um sicherzustellen, dass diese neue Architektur zuverlässig in der physischen Welt eingesetzt werden kann, führte das Variable-Robot-Team eine Reihe umfassender technischer Überarbeitungen durch. Das System unterstützt den flexiblen Wechsel zwischen dem „Ereignismodus“ (mit Aktionsausgabe variabler Länge) und dem „Unified-Modus“ (mit Echtzeit-Regelung) auf Basis derselben Grundgewichte. Außerdem erreicht es eine Einwegkopplung zwischen Videomodellen und Aktionsmodellen, wodurch verhindert wird, dass wertvolle dynamische Vorinformationen aus Internetvideos vorzeitig durch Aktionsdaten verzerrt werden. Für die geometrische Wahrnehmung über mehrere Kameras hinweg führt das Modell Frustum-Masken und röhrenförmige Masken ein, wodurch die KI gezwungen wird, eine sichtfeldübergreifende, echte dreidimensionale geometrische Entsprechung zu entwickeln. Um die Entscheidungslatenz zu verringern, wird eine neue „Stepped Chain-of-Thought Decoding“-Technik eingesetzt, die die Dekodierungsverzögerung deutlich reduziert und gleichzeitig die logische Interpretierbarkeit gewährleistet.










 Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
 OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
 Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai













