
















 Maison
Maison
Le premier modèle mondial d'intelligence incarnée au niveau des événements met fin à l'apprentissage image par image pour les robots
Le 29 mai, l'équipe de Variable Robot a dévoilé WALL-WM, le premier modèle du monde doté d'une intelligence incarnée au monde, fondé sur la « prédiction au niveau des événements ». Ce modèle s'affranchit des grands modèles incarnés conventionnels qui apprennent les actions image par image au fil du temps, en orientant plutôt l'unité de prédiction du modèle du monde vers des événements sémantiques. Il marque une nouvelle étape dans la manière dont les robots comprennent et exécutent les tâches.

Dans le secteur actuel de l’intelligence incarnée, les modèles VLA (vision-langage-action) dominants utilisent généralement une image et une instruction du moment pour prédire un bloc d’action de longueur fixe. Cette approche d’entraînement image par image conduit souvent les robots à se concentrer sur des mouvements physiques mineurs tout en perdant de vue l’objectif final de l’action. Face à des scénarios tels que le changement de tasses ou de tables, les robots échouent fréquemment en raison d’un manque de généralisation. Pour remédier à ce problème majeur du secteur, l’équipe de Variable a souligné dans son article scientifique que les informations textuelles, visuelles et d’action existent naturellement à différentes échelles de temps et dans des géométries multiples dans le monde réel. Les forcer à cohabiter dans un seul espace commun peut facilement endommager le modèle géométrique pré-entraîné.
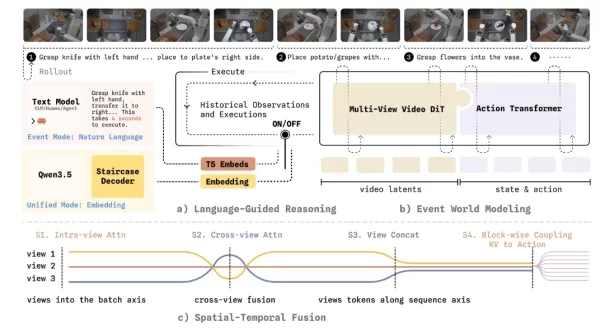
Pour relever ce défi, le modèle du monde WALL-WM introduit un mécanisme innovant d’entraînement et d’exécution centré sur les événements. Il décompose les tâches complexes en événements sémantiquement clairs, tels que tendre le bras, saisir et déplacer. En fonctionnement, le modèle ne calcule plus de manière rigide l'image suivante. Au lieu de cela, il simule d'abord comment le monde va changer en raison de l'événement suivant, puis traduit précisément ce changement visuel en trajectoire de mouvement du bras robotique.
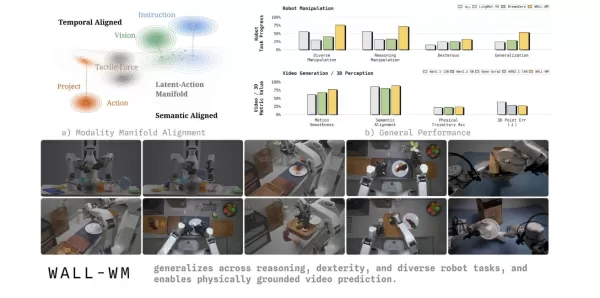
Pour garantir que cette nouvelle architecture puisse être déployée de manière fiable dans le monde physique, l'équipe de Variable Robot a procédé à une série de révisions techniques approfondies. Le système prend en charge une commutation flexible entre le « mode événement » (avec une sortie d'action de longueur variable) et le « mode unifié » (avec un contrôle en boucle fermée en temps réel) sur les mêmes poids de base. Il réalise également un couplage unidirectionnel entre les modèles vidéo et les modèles d’action, empêchant ainsi que les précieuses informations a priori dynamiques issues des vidéos Internet ne soient prématurément biaisées par les données d’action. Pour la perception géométrique à partir de plusieurs caméras, le modèle introduit des masques de frustum et des masques tubulaires, forçant l'IA à développer une correspondance géométrique tridimensionnelle réelle entre les différentes vues. Pour remédier à la latence de décision, il utilise une nouvelle technique de « décodage par chaîne de pensée par étapes » qui réduit considérablement le délai de décodage tout en conservant l'interprétabilité logique.
Article connexe
 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
Recommandations de sujets spéciaux liés
Entreprise
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Le 29 mai, l'équipe de Variable Robot a dévoilé WALL-WM, le premier modèle du monde doté d'une intelligence incarnée au monde, fondé sur la « prédiction au niveau des événements ». Ce modèle s'affranchit des grands modèles incarnés conventionnels qui apprennent les actions image par image au fil du temps, en orientant plutôt l'unité de prédiction du modèle du monde vers des événements sémantiques. Il marque une nouvelle étape dans la manière dont les robots comprennent et exécutent les tâches.
Dans le secteur actuel de l’intelligence incarnée, les modèles VLA (vision-langage-action) dominants utilisent généralement une image et une instruction du moment pour prédire un bloc d’action de longueur fixe. Cette approche d’entraînement image par image conduit souvent les robots à se concentrer sur des mouvements physiques mineurs tout en perdant de vue l’objectif final de l’action. Face à des scénarios tels que le changement de tasses ou de tables, les robots échouent fréquemment en raison d’un manque de généralisation. Pour remédier à ce problème majeur du secteur, l’équipe de Variable a souligné dans son article scientifique que les informations textuelles, visuelles et d’action existent naturellement à différentes échelles de temps et dans des géométries multiples dans le monde réel. Les forcer à cohabiter dans un seul espace commun peut facilement endommager le modèle géométrique pré-entraîné.
Pour relever ce défi, le modèle du monde WALL-WM introduit un mécanisme innovant d’entraînement et d’exécution centré sur les événements. Il décompose les tâches complexes en événements sémantiquement clairs, tels que tendre le bras, saisir et déplacer. En fonctionnement, le modèle ne calcule plus de manière rigide l'image suivante. Au lieu de cela, il simule d'abord comment le monde va changer en raison de l'événement suivant, puis traduit précisément ce changement visuel en trajectoire de mouvement du bras robotique.
Pour garantir que cette nouvelle architecture puisse être déployée de manière fiable dans le monde physique, l'équipe de Variable Robot a procédé à une série de révisions techniques approfondies. Le système prend en charge une commutation flexible entre le « mode événement » (avec une sortie d'action de longueur variable) et le « mode unifié » (avec un contrôle en boucle fermée en temps réel) sur les mêmes poids de base. Il réalise également un couplage unidirectionnel entre les modèles vidéo et les modèles d’action, empêchant ainsi que les précieuses informations a priori dynamiques issues des vidéos Internet ne soient prématurément biaisées par les données d’action. Pour la perception géométrique à partir de plusieurs caméras, le modèle introduit des masques de frustum et des masques tubulaires, forçant l'IA à développer une correspondance géométrique tridimensionnelle réelle entre les différentes vues. Pour remédier à la latence de décision, il utilise une nouvelle technique de « décodage par chaîne de pensée par étapes » qui réduit considérablement le délai de décodage tout en conservant l'interprétabilité logique.










 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
 Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai













