
















 Lar
Lar
Modelo mundial de inteligência incorporada em nível de evento, inédito no mundo, põe fim ao aprendizado quadro a quadro para robôs
Em 29 de maio, a equipe da Variable Robot apresentou o WALL-WM, o primeiro modelo de mundo com inteligência incorporada do mundo baseado em “previsão em nível de evento”. Esse modelo rompe com os grandes modelos incorporados convencionais, que aprendem ações quadro a quadro ao longo do tempo, mudando, em vez disso, a unidade de previsão do modelo do mundo para eventos semânticos. Isso marca uma nova etapa na forma como os robôs compreendem e executam tarefas.

Na indústria atual de inteligência incorporada, os modelos convencionais de visão-linguagem-ação (VLA) normalmente utilizam uma imagem atual e uma instrução para prever um bloco de ação de duração fixa. Essa abordagem de treinamento quadro a quadro frequentemente faz com que os robôs se concentrem em movimentos físicos menores, perdendo de vista o objetivo final da ação. Quando confrontados com cenários como a troca de copos ou mesas, os robôs frequentemente falham devido à falta de generalização. Para resolver esse ponto fraco do setor, a equipe da Variable destacou em seu artigo acadêmico que as informações de texto, visão e ação existem naturalmente em diferentes escalas de tempo e geometrias múltiplas no mundo real. Forçá-las a um único espaço compartilhado pode facilmente prejudicar o prior geométrico pré-treinado.
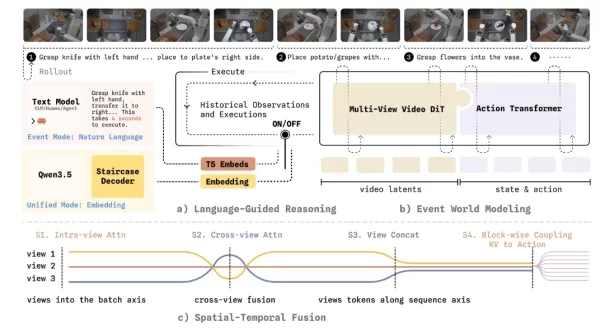
Para enfrentar esse desafio, o modelo de mundo WALL-WM introduz um mecanismo inovador de treinamento e execução centrado em eventos. Ele divide tarefas complexas em junções de eventos semanticamente claras, como alcançar, agarrar e mover. Em operação, o modelo não calcula mais rigidamente o próximo quadro de imagem. Em vez disso, ele primeiro simula como o mundo mudará devido ao próximo evento e, em seguida, traduz com precisão essa mudança visual na trajetória de movimento do braço robótico.
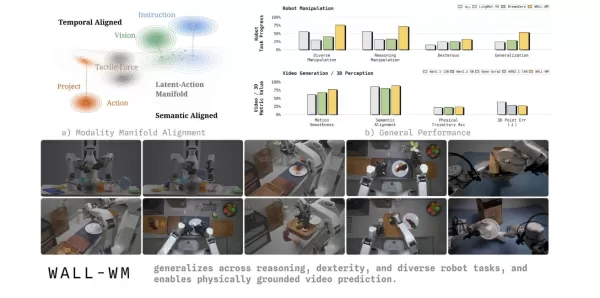
Para garantir que essa nova arquitetura possa ser implantada de forma confiável no mundo físico, a equipe do Variable Robot realizou uma série de reformulações de engenharia de ponta. O sistema suporta a alternância flexível entre o “modo de evento” (com saída de ação de comprimento variável) e o “modo unificado” (com controle de malha fechada em tempo real) nos mesmos pesos de base. Ele também alcança um acoplamento unidirecional entre modelos de vídeo e modelos de ação, evitando que valiosas informações dinâmicas prévias de vídeos da internet sejam prematuramente influenciadas pelos dados de ação. Para a percepção geométrica entre múltiplas câmeras, o modelo introduz máscaras de frustum e máscaras tubulares, forçando a IA a desenvolver uma correspondência geométrica tridimensional verdadeira entre as visões. Para lidar com a latência de decisão, ele emprega uma nova técnica de “decodificação em cadeia de pensamento escalonada” que reduz significativamente o atraso na decodificação, mantendo a interpretabilidade lógica.
Artigo relacionado
 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
Recomendações de tópicos especiais relacionados
Produtividade
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
Recomendações de tópicos especiais relacionados
Produtividade
 Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
 10 ferramentas
10 ferramentas
 xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai
Análise de dados
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
Em 29 de maio, a equipe da Variable Robot apresentou o WALL-WM, o primeiro modelo de mundo com inteligência incorporada do mundo baseado em “previsão em nível de evento”. Esse modelo rompe com os grandes modelos incorporados convencionais, que aprendem ações quadro a quadro ao longo do tempo, mudando, em vez disso, a unidade de previsão do modelo do mundo para eventos semânticos. Isso marca uma nova etapa na forma como os robôs compreendem e executam tarefas.
Na indústria atual de inteligência incorporada, os modelos convencionais de visão-linguagem-ação (VLA) normalmente utilizam uma imagem atual e uma instrução para prever um bloco de ação de duração fixa. Essa abordagem de treinamento quadro a quadro frequentemente faz com que os robôs se concentrem em movimentos físicos menores, perdendo de vista o objetivo final da ação. Quando confrontados com cenários como a troca de copos ou mesas, os robôs frequentemente falham devido à falta de generalização. Para resolver esse ponto fraco do setor, a equipe da Variable destacou em seu artigo acadêmico que as informações de texto, visão e ação existem naturalmente em diferentes escalas de tempo e geometrias múltiplas no mundo real. Forçá-las a um único espaço compartilhado pode facilmente prejudicar o prior geométrico pré-treinado.
Para enfrentar esse desafio, o modelo de mundo WALL-WM introduz um mecanismo inovador de treinamento e execução centrado em eventos. Ele divide tarefas complexas em junções de eventos semanticamente claras, como alcançar, agarrar e mover. Em operação, o modelo não calcula mais rigidamente o próximo quadro de imagem. Em vez disso, ele primeiro simula como o mundo mudará devido ao próximo evento e, em seguida, traduz com precisão essa mudança visual na trajetória de movimento do braço robótico.
Para garantir que essa nova arquitetura possa ser implantada de forma confiável no mundo físico, a equipe do Variable Robot realizou uma série de reformulações de engenharia de ponta. O sistema suporta a alternância flexível entre o “modo de evento” (com saída de ação de comprimento variável) e o “modo unificado” (com controle de malha fechada em tempo real) nos mesmos pesos de base. Ele também alcança um acoplamento unidirecional entre modelos de vídeo e modelos de ação, evitando que valiosas informações dinâmicas prévias de vídeos da internet sejam prematuramente influenciadas pelos dados de ação. Para a percepção geométrica entre múltiplas câmeras, o modelo introduz máscaras de frustum e máscaras tubulares, forçando a IA a desenvolver uma correspondência geométrica tridimensional verdadeira entre as visões. Para lidar com a latência de decisão, ele emprega uma nova técnica de “decodificação em cadeia de pensamento escalonada” que reduz significativamente o atraso na decodificação, mantendo a interpretabilidade lógica.










 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
 A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
 A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai













