
















 Home
Home
Deep Cogito Unveils Four Open-Source Hybrid Reasoning Models Featuring Self-Improving Intuition
Deep Cogito, a San Francisco-based AI research startup founded by former Google engineers, has released four new 'open-ish' large language models (LLMs). These models tackle a key challenge: learning to reason more effectively over time and become more capable autonomously.
Collectively known as the Cogito v2 family, these models range from 70 billion to 671 billion parameters. They are available to AI developers and companies under a mix of permissive and fully open licenses. The release includes:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Dense and MoE models serve distinct purposes. The dense variants (70B and 405B) activate all parameters for every input, making them predictable and easier to deploy across diverse hardware setups.
They are ideal for low-latency tasks, fine-tuning, and environments with constrained GPU capacity. In contrast, MoE models (109B and 671B) use a sparse routing mechanism, activating only a subset of specialized "expert" subnetworks per query. This design supports vastly larger total model sizes without proportionally increasing computational costs.
As such, MoE models excel at high-performance inference and complex reasoning research, delivering top-tier accuracy with lower runtime expense. Within the Cogito v2 lineup, the 671B MoE model is the flagship, using its scale and efficient routing to match or surpass leading open models on benchmarks—often with much shorter reasoning chains.
The models are now accessible via Hugging Face for enterprise use and Unsloth for local deployment. For those unable to self-host, API access is provided by Together AI, Baseten, and RunPod.
A quantized FP8 (8-bit floating point) version of the 671B model is also available. By reducing parameter precision from 16-bit to 8-bit, this version enables faster, cheaper, and more accessible hardware deployment, typically maintaining 95–99% of the original performance. However, accuracy may slightly degrade on tasks requiring high precision, such as certain math or reasoning problems.
All four Cogito v2 models are hybrid reasoning systems: they can answer instantly or, when necessary, engage in internal reflection before responding.
This reflection is not merely a inference-time feature—it is integral to the training process itself.
The models are trained to internalize their reasoning pathways. The steps they take to reach solutions—their internal "thoughts"—are distilled back into the model's foundational weights.
Over time, they learn to distinguish productive lines of reasoning from irrelevant ones.
As explained in Deep Cogito's blog, the researchers discourage the model from "meandering more" to find an answer. Instead, they encourage it to develop a stronger intuition for the most efficient reasoning path.
The outcome, Deep Cogito states, is reasoning that is both faster and more efficient, leading to broad performance gains even in standard operating mode.
The Path to Self-Improving AI
While relatively new to the broader AI community, Deep Cogito has been developing its technology for over a year.
The company launched from stealth in April 2025 with open-source models based on Meta's Llama 3.2. These initial models delivered promising results, following a $13 million seed funding round led by Benchmark in November 2024. Benchmark's Eric Vishria joined the company's board.
As previously covered by VentureBeat, the smallest Cogito v1 models (3B and 8B) consistently outperformed comparable Llama 3 models across various benchmarks, often by significant margins.
Deep Cogito's CEO and co-founder, Drishan Arora—a former lead LLM engineer at Google—describes the company's vision as building models that refine their reasoning with each iteration, akin to how AlphaGo improved through self-play.
At the core of this approach is Iterated Distillation and Amplification (IDA), a method that replaces static training prompts with the model's own evolving insights.
Understanding Machine Intuition
The Cogito v2 release scales this self-improvement loop dramatically. The foundational idea is straightforward: reasoning should be woven into the model's core intelligence, not just activated during inference.
To achieve this, the company implemented a system where models generate reasoning chains during training and then learn from their own intermediate thought processes.
Internal benchmarks confirm tangible improvements. The flagship 671B MoE model surpasses DeepSeek R1 on reasoning tasks, matching or exceeding its latest 0528 model while using reasoning chains 60% shorter on average.
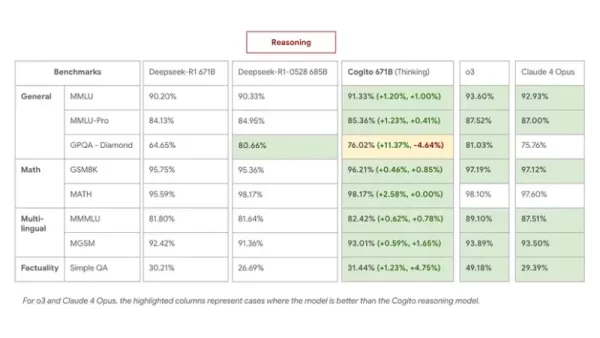
On benchmarks like MMLU, GSM8K, and MGSM, the Cogito 671B MoE performs competitively with leading open models such as Qwen1.5-72B and DeepSeek v3, nearing the performance level of closed models like Claude 4 Opus and o3.
Key findings include:
- In reasoning mode, Cogito 671B MoE matched DeepSeek R1 0528 on multilingual QA and general knowledge, and outperformed it in strategy and logical deduction.
- In standard (non-reasoning) mode, it exceeded DeepSeek v3 0324, demonstrating that the distilled intuition provides a performance boost even without extended reasoning steps.
- Completing reasoning in fewer steps yields practical benefits: lower inference costs and faster response times for complex queries.
Arora likens this to the difference between searching for a destination and already having a strong sense of where it lies.
"Because Cogito models develop a better intuition for the right search trajectory during inference, their reasoning chains are 60% shorter than DeepSeek R1's," he explained in a post on X.
Where Deep Cogito's Models Excel: Machine Intuition in Action
Examples from Cogito v2's internal testing illustrate this capability. In one math problem, a user asks if a train traveling 80 mph can cover 240 miles in under 2.5 hours.
While many models perform detailed, step-by-step calculations and can make errors, Cogito 671B completes a brief internal reflection, calculates 240 ÷ 80 = 3 hours, and correctly concludes the train cannot arrive in time. It uses fewer than 100 internal tokens, compared to over 200 used by DeepSeek R1 for the same answer.
In a legal reasoning example about a U.S. Supreme Court ruling's applicability, Cogito's reasoning mode applies a clear, two-step logic: first determining if the hypothetical case matches the precedent, then justifying its conclusion. This nuanced, interpretive reasoning remains a challenge for many LLMs.
The models also show improved handling of ambiguity. On multi-hop questions like determining familial relationships (e.g., "Alice is Bob's mother, Bob is Charlie's father. What is Alice to Charlie?"), Cogito v2 models correctly identify "grandmother," even when phrasing is subtly altered—a point where other open models often stumble.
Achieving Efficiency at Scale
Remarkably, Deep Cogito reports training all eight of its Cogito models (including the v1 series) for a total cost under $3.5 million—a fraction of the reported nine-figure budgets for some leading frontier models.
This budget covered extensive data generation, synthetic reinforcement, infrastructure, and over 1,000 training experiments.
Arora attributes this cost-effectiveness to a core principle: building smarter models depends on better foundational understanding ("priors"), not simply feeding them more data.
By teaching models to avoid redundant or misleading reasoning paths, Cogito v2 delivers robust performance without inflating inference time or cost—a critical advantage for API-based services or edge-device deployment where latency and expense are key considerations.
Looking Ahead: Deep Cogito's Roadmap
Cogito v2 represents an iterative step, not a final product. Arora describes the company's approach as "hill climbing": running models, learning from their reasoning, distilling those lessons, and repeating the cycle. Each model release builds upon its predecessor.
Deep Cogito remains committed to open source for all its models, present and future. Its work has already garnered support from investors like Benchmark's Eric Vishria and South Park Commons’ Aditya Agarwal.
Infrastructure partners include Hugging Face, Together AI, RunPod, Baseten, Meta's Llama team, and Unsloth.
For developers, researchers, and enterprises, the models are available today for local use, multimodal comparison, and domain-specific fine-tuning.
For the open-source AI community, Cogito v2 offers more than a benchmark milestone. It presents a new paradigm for building intelligence: one focused not on thinking harder, but on learning how to think better.
Related article
 Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Related Special Topic Recommendations
Business
Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (2)
0/500
Comments (2)
0/500
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
Deep Cogito, a San Francisco-based AI research startup founded by former Google engineers, has released four new 'open-ish' large language models (LLMs). These models tackle a key challenge: learning to reason more effectively over time and become more capable autonomously.
Collectively known as the Cogito v2 family, these models range from 70 billion to 671 billion parameters. They are available to AI developers and companies under a mix of permissive and fully open licenses. The release includes:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Dense and MoE models serve distinct purposes. The dense variants (70B and 405B) activate all parameters for every input, making them predictable and easier to deploy across diverse hardware setups.
They are ideal for low-latency tasks, fine-tuning, and environments with constrained GPU capacity. In contrast, MoE models (109B and 671B) use a sparse routing mechanism, activating only a subset of specialized "expert" subnetworks per query. This design supports vastly larger total model sizes without proportionally increasing computational costs.
As such, MoE models excel at high-performance inference and complex reasoning research, delivering top-tier accuracy with lower runtime expense. Within the Cogito v2 lineup, the 671B MoE model is the flagship, using its scale and efficient routing to match or surpass leading open models on benchmarks—often with much shorter reasoning chains.
The models are now accessible via Hugging Face for enterprise use and Unsloth for local deployment. For those unable to self-host, API access is provided by Together AI, Baseten, and RunPod.
A quantized FP8 (8-bit floating point) version of the 671B model is also available. By reducing parameter precision from 16-bit to 8-bit, this version enables faster, cheaper, and more accessible hardware deployment, typically maintaining 95–99% of the original performance. However, accuracy may slightly degrade on tasks requiring high precision, such as certain math or reasoning problems.
All four Cogito v2 models are hybrid reasoning systems: they can answer instantly or, when necessary, engage in internal reflection before responding.
This reflection is not merely a inference-time feature—it is integral to the training process itself.
The models are trained to internalize their reasoning pathways. The steps they take to reach solutions—their internal "thoughts"—are distilled back into the model's foundational weights.
Over time, they learn to distinguish productive lines of reasoning from irrelevant ones.
As explained in Deep Cogito's blog, the researchers discourage the model from "meandering more" to find an answer. Instead, they encourage it to develop a stronger intuition for the most efficient reasoning path.
The outcome, Deep Cogito states, is reasoning that is both faster and more efficient, leading to broad performance gains even in standard operating mode.
The Path to Self-Improving AI
While relatively new to the broader AI community, Deep Cogito has been developing its technology for over a year.
The company launched from stealth in April 2025 with open-source models based on Meta's Llama 3.2. These initial models delivered promising results, following a $13 million seed funding round led by Benchmark in November 2024. Benchmark's Eric Vishria joined the company's board.
As previously covered by VentureBeat, the smallest Cogito v1 models (3B and 8B) consistently outperformed comparable Llama 3 models across various benchmarks, often by significant margins.
Deep Cogito's CEO and co-founder, Drishan Arora—a former lead LLM engineer at Google—describes the company's vision as building models that refine their reasoning with each iteration, akin to how AlphaGo improved through self-play.
At the core of this approach is Iterated Distillation and Amplification (IDA), a method that replaces static training prompts with the model's own evolving insights.
Understanding Machine Intuition
The Cogito v2 release scales this self-improvement loop dramatically. The foundational idea is straightforward: reasoning should be woven into the model's core intelligence, not just activated during inference.
To achieve this, the company implemented a system where models generate reasoning chains during training and then learn from their own intermediate thought processes.
Internal benchmarks confirm tangible improvements. The flagship 671B MoE model surpasses DeepSeek R1 on reasoning tasks, matching or exceeding its latest 0528 model while using reasoning chains 60% shorter on average.
On benchmarks like MMLU, GSM8K, and MGSM, the Cogito 671B MoE performs competitively with leading open models such as Qwen1.5-72B and DeepSeek v3, nearing the performance level of closed models like Claude 4 Opus and o3.
Key findings include:
- In reasoning mode, Cogito 671B MoE matched DeepSeek R1 0528 on multilingual QA and general knowledge, and outperformed it in strategy and logical deduction.
- In standard (non-reasoning) mode, it exceeded DeepSeek v3 0324, demonstrating that the distilled intuition provides a performance boost even without extended reasoning steps.
- Completing reasoning in fewer steps yields practical benefits: lower inference costs and faster response times for complex queries.
Arora likens this to the difference between searching for a destination and already having a strong sense of where it lies.
"Because Cogito models develop a better intuition for the right search trajectory during inference, their reasoning chains are 60% shorter than DeepSeek R1's," he explained in a post on X.
Where Deep Cogito's Models Excel: Machine Intuition in Action
Examples from Cogito v2's internal testing illustrate this capability. In one math problem, a user asks if a train traveling 80 mph can cover 240 miles in under 2.5 hours.
While many models perform detailed, step-by-step calculations and can make errors, Cogito 671B completes a brief internal reflection, calculates 240 ÷ 80 = 3 hours, and correctly concludes the train cannot arrive in time. It uses fewer than 100 internal tokens, compared to over 200 used by DeepSeek R1 for the same answer.
In a legal reasoning example about a U.S. Supreme Court ruling's applicability, Cogito's reasoning mode applies a clear, two-step logic: first determining if the hypothetical case matches the precedent, then justifying its conclusion. This nuanced, interpretive reasoning remains a challenge for many LLMs.
The models also show improved handling of ambiguity. On multi-hop questions like determining familial relationships (e.g., "Alice is Bob's mother, Bob is Charlie's father. What is Alice to Charlie?"), Cogito v2 models correctly identify "grandmother," even when phrasing is subtly altered—a point where other open models often stumble.
Achieving Efficiency at Scale
Remarkably, Deep Cogito reports training all eight of its Cogito models (including the v1 series) for a total cost under $3.5 million—a fraction of the reported nine-figure budgets for some leading frontier models.
This budget covered extensive data generation, synthetic reinforcement, infrastructure, and over 1,000 training experiments.
Arora attributes this cost-effectiveness to a core principle: building smarter models depends on better foundational understanding ("priors"), not simply feeding them more data.
By teaching models to avoid redundant or misleading reasoning paths, Cogito v2 delivers robust performance without inflating inference time or cost—a critical advantage for API-based services or edge-device deployment where latency and expense are key considerations.
Looking Ahead: Deep Cogito's Roadmap
Cogito v2 represents an iterative step, not a final product. Arora describes the company's approach as "hill climbing": running models, learning from their reasoning, distilling those lessons, and repeating the cycle. Each model release builds upon its predecessor.
Deep Cogito remains committed to open source for all its models, present and future. Its work has already garnered support from investors like Benchmark's Eric Vishria and South Park Commons’ Aditya Agarwal.
Infrastructure partners include Hugging Face, Together AI, RunPod, Baseten, Meta's Llama team, and Unsloth.
For developers, researchers, and enterprises, the models are available today for local use, multimodal comparison, and domain-specific fine-tuning.
For the open-source AI community, Cogito v2 offers more than a benchmark milestone. It presents a new paradigm for building intelligence: one focused not on thinking harder, but on learning how to think better.










 Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
 Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













