
















 집
집딥 코지토, 자가 개선 직관을 특징으로 하는 4가지 오픈소스 하이브리드 추론 모델 공개
전 구글 엔지니어들이 설립한 샌프란시스코 기반 AI 연구 스타트업 딥 코지토(Deep Cogito)가 4종의 새로운 '오픈형' 대규모 언어 모델(LLM)을 공개했다. 이 모델들은 핵심 과제인 시간에 따른 효과적인 추론 능력 향상과 자율적 역량 강화를 해결한다.
코지토 v2 패밀리로 통칭되는 이 모델들은 700억에서 6,710억 개의 매개변수를 갖습니다. AI 개발자와 기업들은 허용적 라이선스와 완전 공개 라이선스가 혼합된 형태로 이를 이용할 수 있습니다. 공개된 모델은 다음과 같습니다:
- Cogito v2-70B (Dense)
- Cogito v2-109B (전문가 혼합 모델)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Dense 및 MoE 모델은 각각 다른 목적을 수행합니다. Dense 변형(70B 및 405B)은 모든 입력에 대해 모든 매개변수를 활성화하므로 예측 가능하며 다양한 하드웨어 환경에 배포하기 쉽습니다.
이들은 저지연 작업, 미세 조정, 제한된 GPU 용량을 가진 환경에 이상적입니다. 반면 MoE 모델(109B 및 671B)은 스파스 라우팅 메커니즘을 사용하여 쿼리당 특수화된 "전문가" 하위 네트워크의 일부만 활성화합니다. 이 설계는 계산 비용을 비례적으로 증가시키지 않으면서 훨씬 더 큰 총 모델 크기를 지원합니다.
따라서 MoE 모델은 고성능 추론 및 복잡한 추론 연구에 탁월하며, 더 낮은 실행 시간 비용으로 최상위 정확도를 제공합니다. Cogito v2 라인업 내에서 671B MoE 모델은 플래그십 모델로, 그 규모와 효율적인 라우팅을 활용하여 벤치마크에서 선도적인 오픈 모델과 동등하거나 이를 능가하는 성능을 보여줍니다. 종종 훨씬 더 짧은 추론 체인으로 이를 달성합니다.
해당 모델은 기업용으로 Hugging Face를 통해, 로컬 배포용으로 Unsloth를 통해 접근 가능합니다. 자체 호스팅이 어려운 경우 Together AI, Baseten, RunPod에서 API 접근을 제공합니다.
671B 모델의 양자화된 FP8(8비트 부동소수점) 버전도 제공됩니다. 매개변수 정밀도를 16비트에서 8비트로 낮춤으로써, 이 버전은 더 빠르고 저렴하며 접근성 높은 하드웨어 배포를 가능하게 하며, 일반적으로 원본 성능의 95~99%를 유지합니다. 다만 특정 수학 또는 추론 문제처럼 높은 정밀도가 요구되는 작업에서는 정확도가 약간 저하될 수 있습니다.
네 가지 Cogito v2 모델 모두 하이브리드 추론 시스템입니다: 즉각적으로 답변하거나, 필요 시 응답 전에 내부적인 성찰을 거칠 수 있습니다.
이러한 성찰은 단순히 추론 시점의 기능이 아닌, 훈련 과정 자체에 필수적인 요소입니다.
모델은 추론 경로를 내면화하도록 훈련됩니다. 해결책에 도달하기 위해 취하는 단계들, 즉 내부적인 "생각"이 모델의 기초 가중치로 다시 정제됩니다.
시간이 지남에 따라, 그들은 생산적인 추론과 무관한 추론을 구별하는 법을 배웁니다.
Deep Cogito의 블로그에서 설명한 바와 같이, 연구진은 모델이 답을 찾기 위해 "더 많은 우회"를 하는 것을 막습니다. 대신, 가장 효율적인 추론 경로에 대한 더 강력한 직관을 개발하도록 장려합니다.
Deep Cogito는 그 결과로 더 빠르고 효율적인 추론이 가능해져 표준 운영 모드에서도 전반적인 성능 향상을 가져온다고 밝혔습니다.
자기 개선형 AI로 가는 길
광범위한 AI 커뮤니티에는 비교적 새로운 존재이지만, Deep Cogito는 1년 이상 자사의 기술을 개발해 왔습니다.
이 회사는 2025년 4월 메타의 Llama 3.2 기반 오픈소스 모델로 비밀 개발을 마치고 공식 출범했다. 2024년 11월 벤치마크가 주도한 1,300만 달러 규모의 시드 펀딩을 유치한 후 출시된 초기 모델들은 유망한 결과를 보여줬다. 벤치마크의 에릭 비슈리아는 회사 이사회에 합류했다.
벤처비트가 이전에 보도한 바와 같이, 가장 작은 코지토 v1 모델(3B 및 8B)은 다양한 벤치마크에서 유사한 라마 3 모델을 지속적으로 능가했으며, 종종 상당한 차이로 앞섰습니다.
구글의 전 수석 LLM 엔지니어인 딥 코지토의 CEO 겸 공동 창립자 드리샨 아로라는 회사의 비전을 알파고가 자체 대국을 통해 발전한 방식과 유사하게, 반복할 때마다 추론 능력을 개선하는 모델 구축으로 설명합니다.
이 접근법의 핵심은 Iterated Distillation and Amplification(IDA)로, 정적인 훈련 프롬프트를 모델 자체의 진화하는 통찰력으로 대체하는 방법입니다.
머신의 직관을 이해하다
Cogito v2 릴리스는 이러한 자기 개선 루프를 획기적으로 확장합니다. 기본 개념은 간단합니다: 추론은 추론 중에 활성화될 뿐만 아니라 모델의 핵심 지능에 통합되어야 합니다.
이를 달성하기 위해, 회사는 모델이 훈련 중에 추론 체인을 생성한 다음 자체 중간 사고 과정에서 학습하는 시스템을 구현했습니다.
내부 벤치마크를 통해 가시적인 개선이 확인되었습니다. 플래그십 671B MoE 모델은 추론 작업에서 DeepSeek R1을 능가하며, 최신 0528 모델과 동등하거나 그 이상의 성능을 보였으며 평균적으로 60% 더 짧은 추론 체인을 사용했습니다.
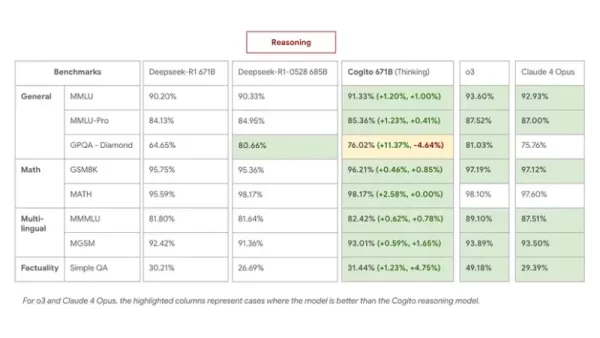
MMLU, GSM8K, MGSM과 같은 벤치마크에서 Cogito 671B MoE는 Qwen1.5-72B 및 DeepSeek v3와 같은 선도적인 오픈 모델과 경쟁력을 발휘하며, Claude 4 Opus 및 o3와 같은 폐쇄형 모델의 성능 수준에 근접합니다.
주요 결과는 다음과 같습니다:
- 추론 모드에서 Cogito 671B MoE는 다국어 QA 및 일반 지식 분야에서 DeepSeek R1 0528과 동등한 성능을 보였으며, 전략 및 논리적 추론에서는 이를 능가했습니다.
- 표준(비추론) 모드에서는 DeepSeek v3 0324를 능가하여, 확장된 추론 단계 없이도 추출된 직관이 성능 향상을 제공함을 입증했습니다.
- 추론을 더 적은 단계로 완료하면 복잡한 질의에 대해 추론 비용이 낮아지고 응답 시간이 빨라지는 등 실질적인 이점이 있습니다.
Arora는 이를 목적지를 검색하는 것과 이미 그 위치를 잘 알고 있는 것의 차이에 비유합니다.
그는 X에 게시한 글에서 "Cogito 모델은 추론 과정에서 올바른 검색 경로에 대한 더 나은 직관을 개발하기 때문에, 그들의 추론 체인은 DeepSeek R1보다 60% 더 짧다"고 설명했습니다.
Deep Cogito 모델의 탁월한 점: 기계 직관의 실제 적용
Cogito v2 내부 테스트 사례가 이 능력을 보여줍니다. 한 수학 문제에서 사용자는 시속 80마일로 달리는 기차가 2.5시간 이내에 240마일을 주파할 수 있는지 묻습니다.
많은 모델들이 상세한 단계별 계산을 수행하며 오류를 범할 수 있는 반면, Cogito 671B는 간략한 내부 반성을 거쳐 240 ÷ 80 = 3시간을 계산하고 기차가 제시간에 도착할 수 없다는 결론을 정확히 도출합니다. 동일한 답변을 위해 DeepSeek R1이 200개 이상의 내부 토큰을 사용한 것과 비교해 Cogito는 100개 미만의 토큰만을 사용합니다.
미국 대법원 판결의 적용 가능성에 관한 법적 추론 사례에서, Cogito의 추론 모드는 명확한 2단계 논리를 적용합니다: 먼저 가상의 사례가 선례와 일치하는지 판단한 후, 결론을 정당화합니다. 이러한 미묘한 해석적 추론은 많은 LLM에게 여전히 도전 과제입니다.
이 모델들은 모호성 처리 능력도 개선되었습니다. 가족 관계 파악과 같은 다단계 질문(예: "앨리스는 밥의 어머니이고, 밥은 찰리의 아버지입니다. 앨리스는 찰리에게 무엇인가요?")에서 Cogito v2 모델은 표현이 미묘하게 달라져도 "할머니"를 정확히 식별합니다. 이는 다른 오픈 모델들이 종종 실패하는 지점입니다.
대규모 효율성 달성
놀랍게도 Deep Cogito는 자사의 8개 Cogito 모델(v1 시리즈 포함) 전체를 총 350만 달러 미만의 비용으로 훈련했다고 보고합니다. 이는 일부 선도적인 프론티어 모델에 보고된 9자리 수 예산의 극히 일부에 불과합니다.
이 예산으로 방대한 데이터 생성, 합성 강화 학습, 인프라 구축 및 1,000회 이상의 훈련 실험을 수행했습니다.
Arora는 이러한 비용 효율성을 핵심 원칙에 기인한다고 설명합니다. 더 스마트한 모델 구축은 단순히 더 많은 데이터를 공급하는 것이 아니라, 더 나은 기초적 이해(“사전 지식”)에 달려 있다는 것입니다.
모델이 중복되거나 오해의 소지가 있는 추론 경로를 피하도록 가르침으로써, Cogito v2는 추론 시간이나 비용을 증가시키지 않으면서도 강력한 성능을 제공합니다. 이는 지연 시간과 비용이 핵심 고려 사항인 API 기반 서비스나 에지 디바이스 배포에 있어 중요한 이점입니다.
앞으로의 전망: 딥 코지토의 로드맵
Cogito v2는 최종 제품이 아닌 반복적 발전 단계입니다. 아로라는 회사의 접근 방식을 "언덕 오르기(hill climbing)"에 비유합니다: 모델을 실행하고, 그 추론에서 배우고, 그 교훈을 정제하며, 이 과정을 반복하는 것입니다. 각 모델 릴리스는 이전 버전을 기반으로 구축됩니다.
딥 코지토는 현재 및 향후 모든 모델에 대해 오픈소스 원칙을 고수할 것을 약속합니다. 벤치마크의 에릭 비슈리아, 사우스 파크 커먼즈의 아디티아 아가왈 등 투자자들의 지지를 이미 확보했습니다.
인프라 파트너로는 Hugging Face, Together AI, RunPod, Baseten, Meta의 Llama 팀, Unsloth 등이 포함됩니다.
개발자, 연구자, 기업을 위해 해당 모델들은 현재 로컬 사용, 다중 모드 비교, 도메인 특화 미세 조정을 위해 이용 가능합니다.
오픈소스 AI 커뮤니티에게 코지토 v2는 단순한 벤치마크 이정표 이상의 의미를 지닙니다. 이는 지능 구축을 위한 새로운 패러다임을 제시합니다: 더 열심히 생각하는 데 집중하기보다, 더 나은 사고 방식을 학습하는 데 초점을 맞춘 접근법입니다.
관련 기사
 클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
관련 특별 주제 추천
만화 창작
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
관련 특별 주제 추천
만화 창작
 소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
 15 도구
15 도구
 xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

 의견 (2)
0/500
의견 (2)
0/500
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
전 구글 엔지니어들이 설립한 샌프란시스코 기반 AI 연구 스타트업 딥 코지토(Deep Cogito)가 4종의 새로운 '오픈형' 대규모 언어 모델(LLM)을 공개했다. 이 모델들은 핵심 과제인 시간에 따른 효과적인 추론 능력 향상과 자율적 역량 강화를 해결한다.
코지토 v2 패밀리로 통칭되는 이 모델들은 700억에서 6,710억 개의 매개변수를 갖습니다. AI 개발자와 기업들은 허용적 라이선스와 완전 공개 라이선스가 혼합된 형태로 이를 이용할 수 있습니다. 공개된 모델은 다음과 같습니다:
- Cogito v2-70B (Dense)
- Cogito v2-109B (전문가 혼합 모델)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Dense 및 MoE 모델은 각각 다른 목적을 수행합니다. Dense 변형(70B 및 405B)은 모든 입력에 대해 모든 매개변수를 활성화하므로 예측 가능하며 다양한 하드웨어 환경에 배포하기 쉽습니다.
이들은 저지연 작업, 미세 조정, 제한된 GPU 용량을 가진 환경에 이상적입니다. 반면 MoE 모델(109B 및 671B)은 스파스 라우팅 메커니즘을 사용하여 쿼리당 특수화된 "전문가" 하위 네트워크의 일부만 활성화합니다. 이 설계는 계산 비용을 비례적으로 증가시키지 않으면서 훨씬 더 큰 총 모델 크기를 지원합니다.
따라서 MoE 모델은 고성능 추론 및 복잡한 추론 연구에 탁월하며, 더 낮은 실행 시간 비용으로 최상위 정확도를 제공합니다. Cogito v2 라인업 내에서 671B MoE 모델은 플래그십 모델로, 그 규모와 효율적인 라우팅을 활용하여 벤치마크에서 선도적인 오픈 모델과 동등하거나 이를 능가하는 성능을 보여줍니다. 종종 훨씬 더 짧은 추론 체인으로 이를 달성합니다.
해당 모델은 기업용으로 Hugging Face를 통해, 로컬 배포용으로 Unsloth를 통해 접근 가능합니다. 자체 호스팅이 어려운 경우 Together AI, Baseten, RunPod에서 API 접근을 제공합니다.
671B 모델의 양자화된 FP8(8비트 부동소수점) 버전도 제공됩니다. 매개변수 정밀도를 16비트에서 8비트로 낮춤으로써, 이 버전은 더 빠르고 저렴하며 접근성 높은 하드웨어 배포를 가능하게 하며, 일반적으로 원본 성능의 95~99%를 유지합니다. 다만 특정 수학 또는 추론 문제처럼 높은 정밀도가 요구되는 작업에서는 정확도가 약간 저하될 수 있습니다.
네 가지 Cogito v2 모델 모두 하이브리드 추론 시스템입니다: 즉각적으로 답변하거나, 필요 시 응답 전에 내부적인 성찰을 거칠 수 있습니다.
이러한 성찰은 단순히 추론 시점의 기능이 아닌, 훈련 과정 자체에 필수적인 요소입니다.
모델은 추론 경로를 내면화하도록 훈련됩니다. 해결책에 도달하기 위해 취하는 단계들, 즉 내부적인 "생각"이 모델의 기초 가중치로 다시 정제됩니다.
시간이 지남에 따라, 그들은 생산적인 추론과 무관한 추론을 구별하는 법을 배웁니다.
Deep Cogito의 블로그에서 설명한 바와 같이, 연구진은 모델이 답을 찾기 위해 "더 많은 우회"를 하는 것을 막습니다. 대신, 가장 효율적인 추론 경로에 대한 더 강력한 직관을 개발하도록 장려합니다.
Deep Cogito는 그 결과로 더 빠르고 효율적인 추론이 가능해져 표준 운영 모드에서도 전반적인 성능 향상을 가져온다고 밝혔습니다.
자기 개선형 AI로 가는 길
광범위한 AI 커뮤니티에는 비교적 새로운 존재이지만, Deep Cogito는 1년 이상 자사의 기술을 개발해 왔습니다.
이 회사는 2025년 4월 메타의 Llama 3.2 기반 오픈소스 모델로 비밀 개발을 마치고 공식 출범했다. 2024년 11월 벤치마크가 주도한 1,300만 달러 규모의 시드 펀딩을 유치한 후 출시된 초기 모델들은 유망한 결과를 보여줬다. 벤치마크의 에릭 비슈리아는 회사 이사회에 합류했다.
벤처비트가 이전에 보도한 바와 같이, 가장 작은 코지토 v1 모델(3B 및 8B)은 다양한 벤치마크에서 유사한 라마 3 모델을 지속적으로 능가했으며, 종종 상당한 차이로 앞섰습니다.
구글의 전 수석 LLM 엔지니어인 딥 코지토의 CEO 겸 공동 창립자 드리샨 아로라는 회사의 비전을 알파고가 자체 대국을 통해 발전한 방식과 유사하게, 반복할 때마다 추론 능력을 개선하는 모델 구축으로 설명합니다.
이 접근법의 핵심은 Iterated Distillation and Amplification(IDA)로, 정적인 훈련 프롬프트를 모델 자체의 진화하는 통찰력으로 대체하는 방법입니다.
머신의 직관을 이해하다
Cogito v2 릴리스는 이러한 자기 개선 루프를 획기적으로 확장합니다. 기본 개념은 간단합니다: 추론은 추론 중에 활성화될 뿐만 아니라 모델의 핵심 지능에 통합되어야 합니다.
이를 달성하기 위해, 회사는 모델이 훈련 중에 추론 체인을 생성한 다음 자체 중간 사고 과정에서 학습하는 시스템을 구현했습니다.
내부 벤치마크를 통해 가시적인 개선이 확인되었습니다. 플래그십 671B MoE 모델은 추론 작업에서 DeepSeek R1을 능가하며, 최신 0528 모델과 동등하거나 그 이상의 성능을 보였으며 평균적으로 60% 더 짧은 추론 체인을 사용했습니다.
MMLU, GSM8K, MGSM과 같은 벤치마크에서 Cogito 671B MoE는 Qwen1.5-72B 및 DeepSeek v3와 같은 선도적인 오픈 모델과 경쟁력을 발휘하며, Claude 4 Opus 및 o3와 같은 폐쇄형 모델의 성능 수준에 근접합니다.
주요 결과는 다음과 같습니다:
- 추론 모드에서 Cogito 671B MoE는 다국어 QA 및 일반 지식 분야에서 DeepSeek R1 0528과 동등한 성능을 보였으며, 전략 및 논리적 추론에서는 이를 능가했습니다.
- 표준(비추론) 모드에서는 DeepSeek v3 0324를 능가하여, 확장된 추론 단계 없이도 추출된 직관이 성능 향상을 제공함을 입증했습니다.
- 추론을 더 적은 단계로 완료하면 복잡한 질의에 대해 추론 비용이 낮아지고 응답 시간이 빨라지는 등 실질적인 이점이 있습니다.
Arora는 이를 목적지를 검색하는 것과 이미 그 위치를 잘 알고 있는 것의 차이에 비유합니다.
그는 X에 게시한 글에서 "Cogito 모델은 추론 과정에서 올바른 검색 경로에 대한 더 나은 직관을 개발하기 때문에, 그들의 추론 체인은 DeepSeek R1보다 60% 더 짧다"고 설명했습니다.
Deep Cogito 모델의 탁월한 점: 기계 직관의 실제 적용
Cogito v2 내부 테스트 사례가 이 능력을 보여줍니다. 한 수학 문제에서 사용자는 시속 80마일로 달리는 기차가 2.5시간 이내에 240마일을 주파할 수 있는지 묻습니다.
많은 모델들이 상세한 단계별 계산을 수행하며 오류를 범할 수 있는 반면, Cogito 671B는 간략한 내부 반성을 거쳐 240 ÷ 80 = 3시간을 계산하고 기차가 제시간에 도착할 수 없다는 결론을 정확히 도출합니다. 동일한 답변을 위해 DeepSeek R1이 200개 이상의 내부 토큰을 사용한 것과 비교해 Cogito는 100개 미만의 토큰만을 사용합니다.
미국 대법원 판결의 적용 가능성에 관한 법적 추론 사례에서, Cogito의 추론 모드는 명확한 2단계 논리를 적용합니다: 먼저 가상의 사례가 선례와 일치하는지 판단한 후, 결론을 정당화합니다. 이러한 미묘한 해석적 추론은 많은 LLM에게 여전히 도전 과제입니다.
이 모델들은 모호성 처리 능력도 개선되었습니다. 가족 관계 파악과 같은 다단계 질문(예: "앨리스는 밥의 어머니이고, 밥은 찰리의 아버지입니다. 앨리스는 찰리에게 무엇인가요?")에서 Cogito v2 모델은 표현이 미묘하게 달라져도 "할머니"를 정확히 식별합니다. 이는 다른 오픈 모델들이 종종 실패하는 지점입니다.
대규모 효율성 달성
놀랍게도 Deep Cogito는 자사의 8개 Cogito 모델(v1 시리즈 포함) 전체를 총 350만 달러 미만의 비용으로 훈련했다고 보고합니다. 이는 일부 선도적인 프론티어 모델에 보고된 9자리 수 예산의 극히 일부에 불과합니다.
이 예산으로 방대한 데이터 생성, 합성 강화 학습, 인프라 구축 및 1,000회 이상의 훈련 실험을 수행했습니다.
Arora는 이러한 비용 효율성을 핵심 원칙에 기인한다고 설명합니다. 더 스마트한 모델 구축은 단순히 더 많은 데이터를 공급하는 것이 아니라, 더 나은 기초적 이해(“사전 지식”)에 달려 있다는 것입니다.
모델이 중복되거나 오해의 소지가 있는 추론 경로를 피하도록 가르침으로써, Cogito v2는 추론 시간이나 비용을 증가시키지 않으면서도 강력한 성능을 제공합니다. 이는 지연 시간과 비용이 핵심 고려 사항인 API 기반 서비스나 에지 디바이스 배포에 있어 중요한 이점입니다.
앞으로의 전망: 딥 코지토의 로드맵
Cogito v2는 최종 제품이 아닌 반복적 발전 단계입니다. 아로라는 회사의 접근 방식을 "언덕 오르기(hill climbing)"에 비유합니다: 모델을 실행하고, 그 추론에서 배우고, 그 교훈을 정제하며, 이 과정을 반복하는 것입니다. 각 모델 릴리스는 이전 버전을 기반으로 구축됩니다.
딥 코지토는 현재 및 향후 모든 모델에 대해 오픈소스 원칙을 고수할 것을 약속합니다. 벤치마크의 에릭 비슈리아, 사우스 파크 커먼즈의 아디티아 아가왈 등 투자자들의 지지를 이미 확보했습니다.
인프라 파트너로는 Hugging Face, Together AI, RunPod, Baseten, Meta의 Llama 팀, Unsloth 등이 포함됩니다.
개발자, 연구자, 기업을 위해 해당 모델들은 현재 로컬 사용, 다중 모드 비교, 도메인 특화 미세 조정을 위해 이용 가능합니다.
오픈소스 AI 커뮤니티에게 코지토 v2는 단순한 벤치마크 이정표 이상의 의미를 지닙니다. 이는 지능 구축을 위한 새로운 패러다임을 제시합니다: 더 열심히 생각하는 데 집중하기보다, 더 나은 사고 방식을 학습하는 데 초점을 맞춘 접근법입니다.










 클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
 하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













