
















 Hogar
Hogar
Deep Cogito presenta cuatro modelos de razonamiento híbrido de código abierto con intuición automejorable
Deep Cogito, una empresa emergente dedicada a la investigación en inteligencia artificial con sede en San Francisco y fundada por antiguos ingenieros de Google, ha lanzado cuatro nuevos modelos de lenguaje grandes (LLM) «abiertos». Estos modelos abordan un reto clave: aprender a razonar de forma más eficaz con el tiempo y ser más capaces de forma autónoma.
Conocidos colectivamente como la familia Cogito v2, estos modelos tienen entre 70 000 y 671 000 millones de parámetros. Están disponibles para desarrolladores y empresas de IA bajo una combinación de licencias permisivas y totalmente abiertas. El lanzamiento incluye:
- Cogito v2-70B (Dense)
- Cogito v2-109B (mezcla de expertos)
- Cogito v2-405B (Denso)
- Cogito v2-671B (MoE)
Los modelos Dense y MoE tienen fines distintos. Las variantes Dense (70B y 405B) activan todos los parámetros para cada entrada, lo que las hace predecibles y más fáciles de implementar en diversas configuraciones de hardware.
Son ideales para tareas de baja latencia, ajuste fino y entornos con capacidad de GPU limitada. Por el contrario, los modelos MoE (109B y 671B) utilizan un mecanismo de enrutamiento disperso, activando solo un subconjunto de subredes «expertas» especializadas por consulta. Este diseño admite tamaños de modelo totales mucho mayores sin aumentar proporcionalmente los costes computacionales.
Por ello, los modelos MoE destacan en la inferencia de alto rendimiento y la investigación de razonamiento complejo, ya que ofrecen una precisión de primer nivel con un menor gasto de tiempo de ejecución. Dentro de la gama Cogito v2, el modelo MoE 671B es el buque insignia, ya que utiliza su escala y su enrutamiento eficiente para igualar o superar a los principales modelos abiertos en las pruebas de rendimiento, a menudo con cadenas de razonamiento mucho más cortas.
Ahora se puede acceder a los modelos a través de Hugging Face para uso empresarial y Unsloth para implementación local. Para aquellos que no pueden alojarlos por sí mismos, Together AI, Baseten y RunPod proporcionan acceso a la API.
También está disponible una versión cuantificada FP8 (8 bits en coma flotante) del modelo 671B. Al reducir la precisión de los parámetros de 16 a 8 bits, esta versión permite una implementación de hardware más rápida, económica y accesible, manteniendo normalmente entre el 95 % y el 99 % del rendimiento original. Sin embargo, la precisión puede verse ligeramente reducida en tareas que requieren una alta precisión, como ciertos problemas matemáticos o de razonamiento.
Los cuatro modelos Cogito v2 son sistemas de razonamiento híbridos: pueden responder al instante o, cuando es necesario, realizar una reflexión interna antes de responder.
Esta reflexión no es solo una característica del tiempo de inferencia, sino que forma parte integral del propio proceso de entrenamiento.
Los modelos están entrenados para interiorizar sus vías de razonamiento. Los pasos que dan para llegar a las soluciones, sus «pensamientos» internos, se destilan de nuevo en los pesos fundamentales del modelo.
Con el tiempo, aprenden a distinguir las líneas de razonamiento productivas de las irrelevantes.
Como se explica en el blog de Deep Cogito, los investigadores desalientan al modelo a «dar más vueltas» para encontrar una respuesta. En cambio, lo animan a desarrollar una intuición más fuerte para encontrar la vía de razonamiento más eficiente.
El resultado, según Deep Cogito, es un razonamiento más rápido y eficiente, lo que conduce a una mejora general del rendimiento, incluso en el modo de funcionamiento estándar.
El camino hacia la IA que se mejora a sí misma
Aunque es relativamente nueva para la comunidad de IA en general, Deep Cogito lleva más de un año desarrollando su tecnología.
La empresa salió del anonimato en abril de 2025 con modelos de código abierto basados en Llama 3.2 de Meta. Estos modelos iniciales dieron resultados prometedores, tras una ronda de financiación inicial de 13 millones de dólares liderada por Benchmark en noviembre de 2024. Eric Vishria, de Benchmark, se incorporó al consejo de administración de la empresa.
Como ya informó VentureBeat, los modelos Cogito v1 más pequeños (3B y 8B) superaron constantemente a los modelos Llama 3 comparables en diversas pruebas de rendimiento, a menudo por márgenes significativos.
El director ejecutivo y cofundador de Deep Cogito, Drishan Arora, antiguo ingeniero jefe de LLM en Google, describe la visión de la empresa como la creación de modelos que refinan su razonamiento con cada iteración, de forma similar a cómo AlphaGo mejoró a través del autoaprendizaje.
En el núcleo de este enfoque se encuentra la destilación y amplificación iterativas (IDA), un método que sustituye las indicaciones de entrenamiento estáticas por los propios conocimientos evolutivos del modelo.
Comprender la intuición de las máquinas
La versión Cogito v2 amplía drásticamente este bucle de mejora automática. La idea fundamental es sencilla: el razonamiento debe integrarse en la inteligencia central del modelo, no solo activarse durante la inferencia.
Para lograrlo, la empresa implementó un sistema en el que los modelos generan cadenas de razonamiento durante el entrenamiento y luego aprenden de sus propios procesos de pensamiento intermedios.
Las pruebas internas confirman mejoras tangibles. El modelo insignia 671B MoE supera a DeepSeek R1 en tareas de razonamiento, igualando o superando su último modelo 0528, mientras que utiliza cadenas de razonamiento un 60 % más cortas de media.
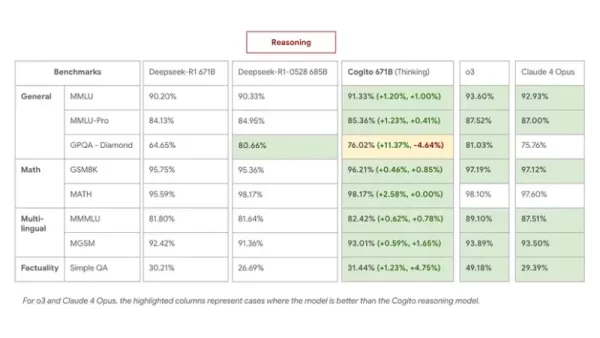
En pruebas comparativas como MMLU, GSM8K y MGSM, el Cogito 671B MoE compite con modelos abiertos líderes como Qwen1.5-72B y DeepSeek v3, acercándose al nivel de rendimiento de modelos cerrados como Claude 4 Opus y o3.
Las conclusiones principales son las siguientes:
- En el modo de razonamiento, Cogito 671B MoE igualó a DeepSeek R1 0528 en preguntas y respuestas multilingües y conocimientos generales, y lo superó en estrategia y deducción lógica.
- En el modo estándar (sin razonamiento), superó a DeepSeek v3 0324, lo que demuestra que la intuición destilada proporciona un aumento del rendimiento incluso sin pasos de razonamiento ampliados.
- Completar el razonamiento en menos pasos produce beneficios prácticos: menores costes de inferencia y tiempos de respuesta más rápidos para consultas complejas.
Arora compara esto con la diferencia entre buscar un destino y tener ya una idea clara de dónde se encuentra.
«Dado que los modelos Cogito desarrollan una mejor intuición para la trayectoria de búsqueda correcta durante la inferencia, sus cadenas de razonamiento son un 60 % más cortas que las de DeepSeek R1», explicó en una publicación en X.
Dónde destacan los modelos de Deep Cogito: la intuición de la máquina en acción
Los ejemplos de las pruebas internas de Cogito v2 ilustran esta capacidad. En un problema matemático, un usuario pregunta si un tren que viaja a 80 mph puede recorrer 240 millas en menos de 2,5 horas.
Mientras que muchos modelos realizan cálculos detallados paso a paso y pueden cometer errores, Cogito 671B completa una breve reflexión interna, calcula 240 ÷ 80 = 3 horas y concluye correctamente que el tren no puede llegar a tiempo. Utiliza menos de 100 tokens internos, en comparación con los más de 200 que utiliza DeepSeek R1 para la misma respuesta.
En un ejemplo de razonamiento jurídico sobre la aplicabilidad de una sentencia del Tribunal Supremo de los Estados Unidos, el modo de razonamiento de Cogito aplica una lógica clara en dos pasos: primero determina si el caso hipotético coincide con el precedente y, a continuación, justifica su conclusión. Este razonamiento matizado e interpretativo sigue siendo un reto para muchos LLM.
Los modelos también muestran una mejora en el manejo de la ambigüedad. En preguntas de múltiples saltos, como determinar las relaciones familiares (por ejemplo, «Alice es la madre de Bob, Bob es el padre de Charlie. ¿Qué es Alice para Charlie?»), los modelos Cogito v2 identifican correctamente «abuela», incluso cuando la redacción se altera sutilmente, un punto en el que otros modelos abiertos suelen tropezar.
Lograr la eficiencia a gran escala
Cabe destacar que Deep Cogito informa de que ha entrenado sus ocho modelos Cogito (incluida la serie v1) por un coste total inferior a 3,5 millones de dólares, una fracción del presupuesto de nueve cifras que se ha informado para algunos modelos punteros.
Este presupuesto cubrió la generación de datos a gran escala, el refuerzo sintético, la infraestructura y más de 1000 experimentos de entrenamiento.
Arora atribuye esta rentabilidad a un principio básico: la creación de modelos más inteligentes depende de una mejor comprensión fundamental («priores»), y no simplemente de alimentarlos con más datos.
Al enseñar a los modelos a evitar caminos de razonamiento redundantes o engañosos, Cogito v2 ofrece un rendimiento sólido sin aumentar el tiempo de inferencia ni el coste, lo que supone una ventaja fundamental para los servicios basados en API o la implementación de dispositivos periféricos, donde la latencia y el gasto son factores clave.
Mirando hacia el futuro: la hoja de ruta de Deep Cogito
Cogito v2 representa un paso iterativo, no un producto final. Arora describe el enfoque de la empresa como «escalada»: ejecutar modelos, aprender de su razonamiento, destilar esas lecciones y repetir el ciclo. Cada lanzamiento de modelo se basa en su predecesor.
Deep Cogito mantiene su compromiso con el código abierto para todos sus modelos, presentes y futuros. Su trabajo ya ha obtenido el apoyo de inversores como Eric Vishria, de Benchmark, y Aditya Agarwal, de South Park Commons.
Entre los socios de infraestructura se encuentran Hugging Face, Together AI, RunPod, Baseten, el equipo Llama de Meta y Unsloth.
Para los desarrolladores, investigadores y empresas, los modelos están disponibles hoy en día para su uso local, comparación multimodal y ajuste específico para cada dominio.
Para la comunidad de IA de código abierto, Cogito v2 ofrece más que un hito de referencia. Presenta un nuevo paradigma para la creación de inteligencia: uno que no se centra en pensar más, sino en aprender a pensar mejor.
Artículo relacionado
 El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
Claude Opus 4.7 sale al mercado apostando por la fiabilidad por encima de la inteligencia
Anthropic ha mantenido un ritmo frenético este año, lanzando nuevas funciones casi cada dos días. El tan esperado Claude Opus 4.7 acaba de salir oficialmente al mercado y, curiosamente, Anthropic fue
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
Recomendaciones de temas especiales relacionados
Creación de cómics
El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
Claude Opus 4.7 sale al mercado apostando por la fiabilidad por encima de la inteligencia
Anthropic ha mantenido un ritmo frenético este año, lanzando nuevas funciones casi cada dos días. El tan esperado Claude Opus 4.7 acaba de salir oficialmente al mercado y, curiosamente, Anthropic fue
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
Recomendaciones de temas especiales relacionados
Creación de cómics
 Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
 15 herramientas
15 herramientas
 xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

 comentario (2)
0/500
comentario (2)
0/500
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
Deep Cogito, una empresa emergente dedicada a la investigación en inteligencia artificial con sede en San Francisco y fundada por antiguos ingenieros de Google, ha lanzado cuatro nuevos modelos de lenguaje grandes (LLM) «abiertos». Estos modelos abordan un reto clave: aprender a razonar de forma más eficaz con el tiempo y ser más capaces de forma autónoma.
Conocidos colectivamente como la familia Cogito v2, estos modelos tienen entre 70 000 y 671 000 millones de parámetros. Están disponibles para desarrolladores y empresas de IA bajo una combinación de licencias permisivas y totalmente abiertas. El lanzamiento incluye:
- Cogito v2-70B (Dense)
- Cogito v2-109B (mezcla de expertos)
- Cogito v2-405B (Denso)
- Cogito v2-671B (MoE)
Los modelos Dense y MoE tienen fines distintos. Las variantes Dense (70B y 405B) activan todos los parámetros para cada entrada, lo que las hace predecibles y más fáciles de implementar en diversas configuraciones de hardware.
Son ideales para tareas de baja latencia, ajuste fino y entornos con capacidad de GPU limitada. Por el contrario, los modelos MoE (109B y 671B) utilizan un mecanismo de enrutamiento disperso, activando solo un subconjunto de subredes «expertas» especializadas por consulta. Este diseño admite tamaños de modelo totales mucho mayores sin aumentar proporcionalmente los costes computacionales.
Por ello, los modelos MoE destacan en la inferencia de alto rendimiento y la investigación de razonamiento complejo, ya que ofrecen una precisión de primer nivel con un menor gasto de tiempo de ejecución. Dentro de la gama Cogito v2, el modelo MoE 671B es el buque insignia, ya que utiliza su escala y su enrutamiento eficiente para igualar o superar a los principales modelos abiertos en las pruebas de rendimiento, a menudo con cadenas de razonamiento mucho más cortas.
Ahora se puede acceder a los modelos a través de Hugging Face para uso empresarial y Unsloth para implementación local. Para aquellos que no pueden alojarlos por sí mismos, Together AI, Baseten y RunPod proporcionan acceso a la API.
También está disponible una versión cuantificada FP8 (8 bits en coma flotante) del modelo 671B. Al reducir la precisión de los parámetros de 16 a 8 bits, esta versión permite una implementación de hardware más rápida, económica y accesible, manteniendo normalmente entre el 95 % y el 99 % del rendimiento original. Sin embargo, la precisión puede verse ligeramente reducida en tareas que requieren una alta precisión, como ciertos problemas matemáticos o de razonamiento.
Los cuatro modelos Cogito v2 son sistemas de razonamiento híbridos: pueden responder al instante o, cuando es necesario, realizar una reflexión interna antes de responder.
Esta reflexión no es solo una característica del tiempo de inferencia, sino que forma parte integral del propio proceso de entrenamiento.
Los modelos están entrenados para interiorizar sus vías de razonamiento. Los pasos que dan para llegar a las soluciones, sus «pensamientos» internos, se destilan de nuevo en los pesos fundamentales del modelo.
Con el tiempo, aprenden a distinguir las líneas de razonamiento productivas de las irrelevantes.
Como se explica en el blog de Deep Cogito, los investigadores desalientan al modelo a «dar más vueltas» para encontrar una respuesta. En cambio, lo animan a desarrollar una intuición más fuerte para encontrar la vía de razonamiento más eficiente.
El resultado, según Deep Cogito, es un razonamiento más rápido y eficiente, lo que conduce a una mejora general del rendimiento, incluso en el modo de funcionamiento estándar.
El camino hacia la IA que se mejora a sí misma
Aunque es relativamente nueva para la comunidad de IA en general, Deep Cogito lleva más de un año desarrollando su tecnología.
La empresa salió del anonimato en abril de 2025 con modelos de código abierto basados en Llama 3.2 de Meta. Estos modelos iniciales dieron resultados prometedores, tras una ronda de financiación inicial de 13 millones de dólares liderada por Benchmark en noviembre de 2024. Eric Vishria, de Benchmark, se incorporó al consejo de administración de la empresa.
Como ya informó VentureBeat, los modelos Cogito v1 más pequeños (3B y 8B) superaron constantemente a los modelos Llama 3 comparables en diversas pruebas de rendimiento, a menudo por márgenes significativos.
El director ejecutivo y cofundador de Deep Cogito, Drishan Arora, antiguo ingeniero jefe de LLM en Google, describe la visión de la empresa como la creación de modelos que refinan su razonamiento con cada iteración, de forma similar a cómo AlphaGo mejoró a través del autoaprendizaje.
En el núcleo de este enfoque se encuentra la destilación y amplificación iterativas (IDA), un método que sustituye las indicaciones de entrenamiento estáticas por los propios conocimientos evolutivos del modelo.
Comprender la intuición de las máquinas
La versión Cogito v2 amplía drásticamente este bucle de mejora automática. La idea fundamental es sencilla: el razonamiento debe integrarse en la inteligencia central del modelo, no solo activarse durante la inferencia.
Para lograrlo, la empresa implementó un sistema en el que los modelos generan cadenas de razonamiento durante el entrenamiento y luego aprenden de sus propios procesos de pensamiento intermedios.
Las pruebas internas confirman mejoras tangibles. El modelo insignia 671B MoE supera a DeepSeek R1 en tareas de razonamiento, igualando o superando su último modelo 0528, mientras que utiliza cadenas de razonamiento un 60 % más cortas de media.
En pruebas comparativas como MMLU, GSM8K y MGSM, el Cogito 671B MoE compite con modelos abiertos líderes como Qwen1.5-72B y DeepSeek v3, acercándose al nivel de rendimiento de modelos cerrados como Claude 4 Opus y o3.
Las conclusiones principales son las siguientes:
- En el modo de razonamiento, Cogito 671B MoE igualó a DeepSeek R1 0528 en preguntas y respuestas multilingües y conocimientos generales, y lo superó en estrategia y deducción lógica.
- En el modo estándar (sin razonamiento), superó a DeepSeek v3 0324, lo que demuestra que la intuición destilada proporciona un aumento del rendimiento incluso sin pasos de razonamiento ampliados.
- Completar el razonamiento en menos pasos produce beneficios prácticos: menores costes de inferencia y tiempos de respuesta más rápidos para consultas complejas.
Arora compara esto con la diferencia entre buscar un destino y tener ya una idea clara de dónde se encuentra.
«Dado que los modelos Cogito desarrollan una mejor intuición para la trayectoria de búsqueda correcta durante la inferencia, sus cadenas de razonamiento son un 60 % más cortas que las de DeepSeek R1», explicó en una publicación en X.
Dónde destacan los modelos de Deep Cogito: la intuición de la máquina en acción
Los ejemplos de las pruebas internas de Cogito v2 ilustran esta capacidad. En un problema matemático, un usuario pregunta si un tren que viaja a 80 mph puede recorrer 240 millas en menos de 2,5 horas.
Mientras que muchos modelos realizan cálculos detallados paso a paso y pueden cometer errores, Cogito 671B completa una breve reflexión interna, calcula 240 ÷ 80 = 3 horas y concluye correctamente que el tren no puede llegar a tiempo. Utiliza menos de 100 tokens internos, en comparación con los más de 200 que utiliza DeepSeek R1 para la misma respuesta.
En un ejemplo de razonamiento jurídico sobre la aplicabilidad de una sentencia del Tribunal Supremo de los Estados Unidos, el modo de razonamiento de Cogito aplica una lógica clara en dos pasos: primero determina si el caso hipotético coincide con el precedente y, a continuación, justifica su conclusión. Este razonamiento matizado e interpretativo sigue siendo un reto para muchos LLM.
Los modelos también muestran una mejora en el manejo de la ambigüedad. En preguntas de múltiples saltos, como determinar las relaciones familiares (por ejemplo, «Alice es la madre de Bob, Bob es el padre de Charlie. ¿Qué es Alice para Charlie?»), los modelos Cogito v2 identifican correctamente «abuela», incluso cuando la redacción se altera sutilmente, un punto en el que otros modelos abiertos suelen tropezar.
Lograr la eficiencia a gran escala
Cabe destacar que Deep Cogito informa de que ha entrenado sus ocho modelos Cogito (incluida la serie v1) por un coste total inferior a 3,5 millones de dólares, una fracción del presupuesto de nueve cifras que se ha informado para algunos modelos punteros.
Este presupuesto cubrió la generación de datos a gran escala, el refuerzo sintético, la infraestructura y más de 1000 experimentos de entrenamiento.
Arora atribuye esta rentabilidad a un principio básico: la creación de modelos más inteligentes depende de una mejor comprensión fundamental («priores»), y no simplemente de alimentarlos con más datos.
Al enseñar a los modelos a evitar caminos de razonamiento redundantes o engañosos, Cogito v2 ofrece un rendimiento sólido sin aumentar el tiempo de inferencia ni el coste, lo que supone una ventaja fundamental para los servicios basados en API o la implementación de dispositivos periféricos, donde la latencia y el gasto son factores clave.
Mirando hacia el futuro: la hoja de ruta de Deep Cogito
Cogito v2 representa un paso iterativo, no un producto final. Arora describe el enfoque de la empresa como «escalada»: ejecutar modelos, aprender de su razonamiento, destilar esas lecciones y repetir el ciclo. Cada lanzamiento de modelo se basa en su predecesor.
Deep Cogito mantiene su compromiso con el código abierto para todos sus modelos, presentes y futuros. Su trabajo ya ha obtenido el apoyo de inversores como Eric Vishria, de Benchmark, y Aditya Agarwal, de South Park Commons.
Entre los socios de infraestructura se encuentran Hugging Face, Together AI, RunPod, Baseten, el equipo Llama de Meta y Unsloth.
Para los desarrolladores, investigadores y empresas, los modelos están disponibles hoy en día para su uso local, comparación multimodal y ajuste específico para cada dominio.
Para la comunidad de IA de código abierto, Cogito v2 ofrece más que un hito de referencia. Presenta un nuevo paradigma para la creación de inteligencia: uno que no se centra en pensar más, sino en aprender a pensar mejor.










 El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
 Claude Opus 4.7 sale al mercado apostando por la fiabilidad por encima de la inteligencia
Anthropic ha mantenido un ritmo frenético este año, lanzando nuevas funciones casi cada dos días. El tan esperado Claude Opus 4.7 acaba de salir oficialmente al mercado y, curiosamente, Anthropic fue
Claude Opus 4.7 sale al mercado apostando por la fiabilidad por encima de la inteligencia
Anthropic ha mantenido un ritmo frenético este año, lanzando nuevas funciones casi cada dos días. El tan esperado Claude Opus 4.7 acaba de salir oficialmente al mercado y, curiosamente, Anthropic fue
 Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













