
















 首頁
首頁Deep Cogito 推出四款開源混合推理模型,具備自我提升的直覺能力
由前谷歌工程師創立的舊金山人工智慧研究新創公司Deep Cogito,近日發布四款新型「半開放式」大型語言模型(LLMs)。這些模型致力解決關鍵挑戰:學習隨時間推移更有效地進行推理,並逐步提升自主能力。
這組被統稱為Cogito v2家族的模型,參數規模從700億至6,710億不等。開發者與企業可透過混合授權模式取得使用權,包含寬鬆授權與完全開放授權。本次發布包含:
- Cogito v2-70B (Dense)
- Cogito v2-109B(專家混合模型)
- Cogito v2-405B(密集型)
- Cogito v2-671B (混合專家模型)
密集型與專家混合模型各具特色。密集型變體(70B與405B)對每項輸入皆啟用所有參數,使其預測結果更可預測,且更易部署於各類硬體環境。
此類模型適用於低延遲任務、微調及GPU資源受限的環境。相對地,MoE模型(109B與671B)採用稀疏路由機制,每則查詢僅激活特定子集的「專家」子網路。此設計能大幅擴展模型總體積,卻無需成比例增加運算成本。
因此,MoE 模型在高效能推論與複雜推理研究領域表現卓越,以較低執行時間成本實現頂尖準確度。在 Cogito v2 產品線中,671B MoE 模型作為旗艦產品,憑藉其規模與高效路由機制,在基準測試中媲美或超越領先的開放模型——且常以更短的推理鏈達成。
企業用戶現可透過 Hugging Face 存取模型,本地部署則可使用 Unsloth。無法自行託管的用戶可透過 Together AI、Baseten 及 RunPod 取得 API 存取權限。
671B模型另提供FP8量化版本(8位元浮點)。透過將參數精度從16位元降至8位元,此版本實現更快速、經濟且易於部署的硬體解決方案,通常能維持原始效能的95%至99%。然在需高精度的任務(如特定數學或推理問題)中,準確度可能略有下降。
四款Cogito v2模型皆屬混合推理系統:既能即時回應,亦能在必要時進行內部反思後再作答。
此反思機制不僅是推論階段的功能,更是訓練過程的內在組成部分。
模型經訓練後能將推理路徑內化,其推導解法的步驟——即內部「思考過程」——會被提煉回歸至模型的基礎權重中。
隨著時間推移,它們學會區分有效的推理路徑與無關的思路。
正如 Deep Cogito 部落格所述,研究人員不鼓勵模型「多繞彎路」尋找答案,而是引導其培養對最高效推理路徑的直覺。
Deep Cogito 指出,此舉使推理過程更快速高效,即使在標準運作模式下也能實現全面性能提升。
邁向自我提升人工智慧之路
儘管對廣大AI社群而言相對新穎,Deep Cogito其實已研發技術逾一年。
該公司於2025年4月正式亮相,推出基於Meta Llama 3.2的開源模型。這些初始模型在2024年11月獲得Benchmark領投的1300萬美元種子輪融資後,展現出令人鼓舞的成果。Benchmark合夥人Eric Vishria隨後加入公司董事會。
如VentureBeat先前報導,Cogito v1系列最小模型(30億與80億參數)在多項基準測試中持續超越同級Llama 3模型,優勢往往相當顯著。
Deep Cogito執行長暨共同創辦人Drishan Arora(前Google大型語言模型首席工程師)闡述公司願景:打造能透過迭代精進推理能力的模型,其運作原理類似AlphaGo透過自我對弈實現的自我提升。
此方法的核心在於「迭代蒸餾與強化」(IDA),該技術以模型自身演進的洞察力取代靜態訓練提示。
理解機器直覺
Cogito v2版本大幅擴展了此自我優化迴圈。其核心理念直截了當:推理能力應融入模型核心智能,而非僅在推論階段啟動。
為實現此目標,該公司建構了一套系統:模型在訓練過程中生成推理鏈,並從自身的中間思考過程學習。
內部基準測試證實了實質性提升。旗艦級671B MoE模型在推理任務上超越DeepSeek R1,其推理鏈平均長度縮短60%,卻能匹敵甚至超越DeepSeek最新的0528模型。
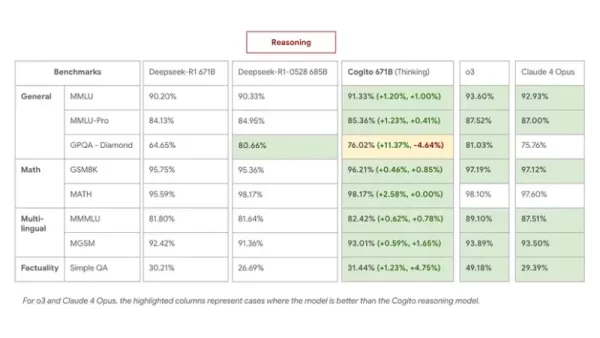
在MMLU、GSM8K及MGSM等基準測試中,Cogito 671B MoE模型與Qwen1.5-72B、DeepSeek v3等頂尖開源模型表現旗鼓相當,其效能已逼近Claude 4 Opus及o3等封閉模型水準。
關鍵發現包括:
- 在推理模式下,Cogito 671B MoE於多語言問答與常識領域與DeepSeek R1 0528持平,並在策略規劃與邏輯演繹方面表現更勝一籌。
- 在標準(非推理)模式下,其表現超越DeepSeek v3 0324,證明即使不經延伸推理步驟,蒸餾出的直覺仍能提升效能。
- 以更少步驟完成推理帶來實質效益:降低複雜查詢的推論成本與提升回應速度。
阿羅拉將此比喻為「搜尋目的地」與「已具備明確方位感」的差異。
他在X平台發文解釋:「由於Cogito模型在推理過程中能發展出更精準的搜尋軌跡直覺,其推理鏈比DeepSeek R1縮短了60%。」
Deep Cogito 模型的卓越之處:機器直覺的實踐
Cogito v2內部測試案例彰顯此能力。某數學題中,使用者詢問時速80英里的火車能否在2.5小時內行駛240英里。
多數模型需進行繁複的逐步計算且易出錯,而Cogito 671B僅經簡短內部推演,即計算出240 ÷ 80 = 3小時,正確推斷火車無法準時抵達。其內部運算符號使用量不足100個,相較之下DeepSeek R1得出相同結論時耗費逾200個符號。
在關於美國最高法院裁決適用性的法律推理範例中,Cogito的推理模式採用清晰的兩步邏輯:首先判定假設案例是否符合先例,繼而闡明結論依據。這種細膩的詮釋性推理仍是多數大型語言模型面臨的挑戰。
該模型在處理模糊性方面亦展現進步。面對多跳問題(如判定親屬關係:「愛麗絲是鮑伯的母親,鮑伯是查理的父親。愛麗絲對查理而言是誰?」),Cogito v2模型能精準識別「祖母」關係,即使表述稍作變動亦能正確判斷——此為其他開放模型常失誤之處。
實現大規模效率
值得注意的是,Deep Cogito 報告稱其八款 Cogito 模型(含 v1 系列)的總訓練成本低於 350 萬美元——僅為某些前沿模型所披露九位數預算的零頭。
此預算涵蓋了大規模數據生成、合成強化學習、基礎設施及逾千次訓練實驗。
阿羅拉將此成本效益歸因於核心原則:打造更智能的模型取決於更優異的基礎理解("先驗知識"),而非單純餵入更多數據。
透過教導模型避免冗餘或誤導性的推理路徑,Cogito v2 在不增加推論時間或成本的前提下實現穩健性能——這對以 API 為基礎的服務或邊緣裝置部署至關重要,因其延遲與成本是關鍵考量因素。
展望未來:Deep Cogito的路線圖
Cogito v2代表迭代進程而非終極產品。阿羅拉將公司方法比喻為「爬坡法」:運行模型、從推理中學習、提煉經驗、循環往復。每版模型皆在前代基礎上持續進化。
Deep Cogito 持續承諾將所有現有及未來模型開源。其研究成果已獲得 Benchmark 創投的 Eric Vishria 與 South Park Commons 的 Aditya Agarwal 等投資者支持。
基礎設施合作夥伴包括 Hugging Face、Together AI、RunPod、Baseten、Meta 的 Llama 團隊以及 Unsloth。
開發者、研究人員及企業用戶現可立即使用這些模型進行本地部署、多模態比對及領域專屬微調。
對開源人工智慧社群而言,Cogito v2不僅是基準里程碑,更提出建構智能的新範式:其核心不在於更努力思考,而在於學習如何更有效地思考。
相關文章
 Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
艾飛泰推出搭載GlassClaw助手的AI眼鏡,售價為4299元人民幣。
隨著人工智慧大型模型越來越多地應用於邊緣側硬體,智慧可穿戴裝置市場迎來了一位重要的新參與者。5月28日,艾邁斯半導體在澳門舉辦的2026年BEYOND博覽會上正式推出了“艾邁斯半導體AI眼鏡”,這一舉措標誌著語音和多模態人工智慧技術正在更深入地融入消費級裝置中。這款眼鏡售價為4,299元人民幣,在上市當天可享受折扣預訂,預售活動將於6月15日開始。這款專為提升工作效率和生活品質而設計的眼鏡,將強大的人工智慧計算能力整合在僅有40克重的超輕框架中。它們支援多達122種語言的實時翻譯功能,適用於電
相關專題推薦
代碼
Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
艾飛泰推出搭載GlassClaw助手的AI眼鏡,售價為4299元人民幣。
隨著人工智慧大型模型越來越多地應用於邊緣側硬體,智慧可穿戴裝置市場迎來了一位重要的新參與者。5月28日,艾邁斯半導體在澳門舉辦的2026年BEYOND博覽會上正式推出了“艾邁斯半導體AI眼鏡”,這一舉措標誌著語音和多模態人工智慧技術正在更深入地融入消費級裝置中。這款眼鏡售價為4,299元人民幣,在上市當天可享受折扣預訂,預售活動將於6月15日開始。這款專為提升工作效率和生活品質而設計的眼鏡,將強大的人工智慧計算能力整合在僅有40克重的超輕框架中。它們支援多達122種語言的實時翻譯功能,適用於電
相關專題推薦
代碼
 最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
 10 個工具
10 個工具
 xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

 評論 (2)
0/500
評論 (2)
0/500
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
由前谷歌工程師創立的舊金山人工智慧研究新創公司Deep Cogito,近日發布四款新型「半開放式」大型語言模型(LLMs)。這些模型致力解決關鍵挑戰:學習隨時間推移更有效地進行推理,並逐步提升自主能力。
這組被統稱為Cogito v2家族的模型,參數規模從700億至6,710億不等。開發者與企業可透過混合授權模式取得使用權,包含寬鬆授權與完全開放授權。本次發布包含:
- Cogito v2-70B (Dense)
- Cogito v2-109B(專家混合模型)
- Cogito v2-405B(密集型)
- Cogito v2-671B (混合專家模型)
密集型與專家混合模型各具特色。密集型變體(70B與405B)對每項輸入皆啟用所有參數,使其預測結果更可預測,且更易部署於各類硬體環境。
此類模型適用於低延遲任務、微調及GPU資源受限的環境。相對地,MoE模型(109B與671B)採用稀疏路由機制,每則查詢僅激活特定子集的「專家」子網路。此設計能大幅擴展模型總體積,卻無需成比例增加運算成本。
因此,MoE 模型在高效能推論與複雜推理研究領域表現卓越,以較低執行時間成本實現頂尖準確度。在 Cogito v2 產品線中,671B MoE 模型作為旗艦產品,憑藉其規模與高效路由機制,在基準測試中媲美或超越領先的開放模型——且常以更短的推理鏈達成。
企業用戶現可透過 Hugging Face 存取模型,本地部署則可使用 Unsloth。無法自行託管的用戶可透過 Together AI、Baseten 及 RunPod 取得 API 存取權限。
671B模型另提供FP8量化版本(8位元浮點)。透過將參數精度從16位元降至8位元,此版本實現更快速、經濟且易於部署的硬體解決方案,通常能維持原始效能的95%至99%。然在需高精度的任務(如特定數學或推理問題)中,準確度可能略有下降。
四款Cogito v2模型皆屬混合推理系統:既能即時回應,亦能在必要時進行內部反思後再作答。
此反思機制不僅是推論階段的功能,更是訓練過程的內在組成部分。
模型經訓練後能將推理路徑內化,其推導解法的步驟——即內部「思考過程」——會被提煉回歸至模型的基礎權重中。
隨著時間推移,它們學會區分有效的推理路徑與無關的思路。
正如 Deep Cogito 部落格所述,研究人員不鼓勵模型「多繞彎路」尋找答案,而是引導其培養對最高效推理路徑的直覺。
Deep Cogito 指出,此舉使推理過程更快速高效,即使在標準運作模式下也能實現全面性能提升。
邁向自我提升人工智慧之路
儘管對廣大AI社群而言相對新穎,Deep Cogito其實已研發技術逾一年。
該公司於2025年4月正式亮相,推出基於Meta Llama 3.2的開源模型。這些初始模型在2024年11月獲得Benchmark領投的1300萬美元種子輪融資後,展現出令人鼓舞的成果。Benchmark合夥人Eric Vishria隨後加入公司董事會。
如VentureBeat先前報導,Cogito v1系列最小模型(30億與80億參數)在多項基準測試中持續超越同級Llama 3模型,優勢往往相當顯著。
Deep Cogito執行長暨共同創辦人Drishan Arora(前Google大型語言模型首席工程師)闡述公司願景:打造能透過迭代精進推理能力的模型,其運作原理類似AlphaGo透過自我對弈實現的自我提升。
此方法的核心在於「迭代蒸餾與強化」(IDA),該技術以模型自身演進的洞察力取代靜態訓練提示。
理解機器直覺
Cogito v2版本大幅擴展了此自我優化迴圈。其核心理念直截了當:推理能力應融入模型核心智能,而非僅在推論階段啟動。
為實現此目標,該公司建構了一套系統:模型在訓練過程中生成推理鏈,並從自身的中間思考過程學習。
內部基準測試證實了實質性提升。旗艦級671B MoE模型在推理任務上超越DeepSeek R1,其推理鏈平均長度縮短60%,卻能匹敵甚至超越DeepSeek最新的0528模型。
在MMLU、GSM8K及MGSM等基準測試中,Cogito 671B MoE模型與Qwen1.5-72B、DeepSeek v3等頂尖開源模型表現旗鼓相當,其效能已逼近Claude 4 Opus及o3等封閉模型水準。
關鍵發現包括:
- 在推理模式下,Cogito 671B MoE於多語言問答與常識領域與DeepSeek R1 0528持平,並在策略規劃與邏輯演繹方面表現更勝一籌。
- 在標準(非推理)模式下,其表現超越DeepSeek v3 0324,證明即使不經延伸推理步驟,蒸餾出的直覺仍能提升效能。
- 以更少步驟完成推理帶來實質效益:降低複雜查詢的推論成本與提升回應速度。
阿羅拉將此比喻為「搜尋目的地」與「已具備明確方位感」的差異。
他在X平台發文解釋:「由於Cogito模型在推理過程中能發展出更精準的搜尋軌跡直覺,其推理鏈比DeepSeek R1縮短了60%。」
Deep Cogito 模型的卓越之處:機器直覺的實踐
Cogito v2內部測試案例彰顯此能力。某數學題中,使用者詢問時速80英里的火車能否在2.5小時內行駛240英里。
多數模型需進行繁複的逐步計算且易出錯,而Cogito 671B僅經簡短內部推演,即計算出240 ÷ 80 = 3小時,正確推斷火車無法準時抵達。其內部運算符號使用量不足100個,相較之下DeepSeek R1得出相同結論時耗費逾200個符號。
在關於美國最高法院裁決適用性的法律推理範例中,Cogito的推理模式採用清晰的兩步邏輯:首先判定假設案例是否符合先例,繼而闡明結論依據。這種細膩的詮釋性推理仍是多數大型語言模型面臨的挑戰。
該模型在處理模糊性方面亦展現進步。面對多跳問題(如判定親屬關係:「愛麗絲是鮑伯的母親,鮑伯是查理的父親。愛麗絲對查理而言是誰?」),Cogito v2模型能精準識別「祖母」關係,即使表述稍作變動亦能正確判斷——此為其他開放模型常失誤之處。
實現大規模效率
值得注意的是,Deep Cogito 報告稱其八款 Cogito 模型(含 v1 系列)的總訓練成本低於 350 萬美元——僅為某些前沿模型所披露九位數預算的零頭。
此預算涵蓋了大規模數據生成、合成強化學習、基礎設施及逾千次訓練實驗。
阿羅拉將此成本效益歸因於核心原則:打造更智能的模型取決於更優異的基礎理解("先驗知識"),而非單純餵入更多數據。
透過教導模型避免冗餘或誤導性的推理路徑,Cogito v2 在不增加推論時間或成本的前提下實現穩健性能——這對以 API 為基礎的服務或邊緣裝置部署至關重要,因其延遲與成本是關鍵考量因素。
展望未來:Deep Cogito的路線圖
Cogito v2代表迭代進程而非終極產品。阿羅拉將公司方法比喻為「爬坡法」:運行模型、從推理中學習、提煉經驗、循環往復。每版模型皆在前代基礎上持續進化。
Deep Cogito 持續承諾將所有現有及未來模型開源。其研究成果已獲得 Benchmark 創投的 Eric Vishria 與 South Park Commons 的 Aditya Agarwal 等投資者支持。
基礎設施合作夥伴包括 Hugging Face、Together AI、RunPod、Baseten、Meta 的 Llama 團隊以及 Unsloth。
開發者、研究人員及企業用戶現可立即使用這些模型進行本地部署、多模態比對及領域專屬微調。
對開源人工智慧社群而言,Cogito v2不僅是基準里程碑,更提出建構智能的新範式:其核心不在於更努力思考,而在於學習如何更有效地思考。










 Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
 Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
 艾飛泰推出搭載GlassClaw助手的AI眼鏡,售價為4299元人民幣。
隨著人工智慧大型模型越來越多地應用於邊緣側硬體,智慧可穿戴裝置市場迎來了一位重要的新參與者。5月28日,艾邁斯半導體在澳門舉辦的2026年BEYOND博覽會上正式推出了“艾邁斯半導體AI眼鏡”,這一舉措標誌著語音和多模態人工智慧技術正在更深入地融入消費級裝置中。這款眼鏡售價為4,299元人民幣,在上市當天可享受折扣預訂,預售活動將於6月15日開始。這款專為提升工作效率和生活品質而設計的眼鏡,將強大的人工智慧計算能力整合在僅有40克重的超輕框架中。它們支援多達122種語言的實時翻譯功能,適用於電
艾飛泰推出搭載GlassClaw助手的AI眼鏡,售價為4299元人民幣。
隨著人工智慧大型模型越來越多地應用於邊緣側硬體,智慧可穿戴裝置市場迎來了一位重要的新參與者。5月28日,艾邁斯半導體在澳門舉辦的2026年BEYOND博覽會上正式推出了“艾邁斯半導體AI眼鏡”,這一舉措標誌著語音和多模態人工智慧技術正在更深入地融入消費級裝置中。這款眼鏡售價為4,299元人民幣,在上市當天可享受折扣預訂,預售活動將於6月15日開始。這款專為提升工作效率和生活品質而設計的眼鏡,將強大的人工智慧計算能力整合在僅有40克重的超輕框架中。它們支援多達122種語言的實時翻譯功能,適用於電

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













