
















 家
家Deep Cogito、自己改善型直感を備えた4つのオープンソースハイブリッド推論モデルを発表
サンフランシスコに拠点を置くAI研究スタートアップDeep Cogito(元Googleエンジニアらが設立)は、4つの新たな「オープン系」大規模言語モデル(LLM)を公開した。これらのモデルは、時間経過とともに推論能力を効果的に向上させ、自律的に能力を高めるという核心的な課題に取り組む。
「Cogito v2ファミリー」として総称されるこれらのモデルは、700億から6,710億のパラメータ数を有する。AI開発者や企業向けに、許容範囲の広いライセンスと完全オープンライセンスの組み合わせで提供される。リリース内容は以下の通り:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
DenseモデルとMoEモデルはそれぞれ異なる目的を果たします。Denseモデル(70Bおよび405B)は入力ごとに全パラメータを活性化するため、予測可能性が高く、多様なハードウェア環境での展開が容易です。
低遅延タスク、微調整、GPU容量が制約される環境に最適です。一方、MoEモデル(109Bおよび671B)は疎なルーティング機構を採用し、クエリごとに特殊な「エキスパート」サブネットワークの一部のみを活性化します。この設計により、計算コストを比例的に増加させることなく、はるかに大規模なモデル総サイズをサポートします。
このためMoEモデルは高性能推論と複雑な推論研究に優れ、より低い実行コストでトップクラスの精度を実現します。Cogito v2ラインナップでは671B MoEモデルがフラッグシップであり、その規模と効率的なルーティングにより、主要なオープンモデルと同等またはそれ以上のベンチマーク性能を発揮します。多くの場合、推論チェーンを大幅に短縮しながらです。
本モデルは現在、企業利用向けにHugging Face経由、ローカル展開向けにUnsloth経由でアクセス可能です。自己ホスティングが困難な場合、Together AI、Baseten、RunPodによるAPIアクセスが提供されます。
671Bモデルの量子化FP8(8ビット浮動小数点)版も利用可能です。パラメータ精度を16ビットから8ビットに削減することで、より高速・低コスト・広範なハードウェア展開を実現し、通常は元の性能の95~99%を維持します。ただし、特定の数学問題や推論など高精度を要するタスクでは精度がわずかに低下する可能性があります。
4つのCogito v2モデルは全てハイブリッド推論システムです:即座に回答するか、必要に応じて内部で推論を実行してから応答します。
この内省は単なる推論時の機能ではなく、トレーニングプロセスそのものに不可欠な要素です。
モデルは推論経路を内面化するよう訓練されます。解決に至る過程で踏むステップ、つまり内部の「思考」が、モデルの基礎となる重みに再構築されるのです。
時間の経過とともに、生産的な推論の流れと無関係なものを区別することを学びます。
Deep Cogito のブログで説明されているように、研究者たちは、答えを見つけるためにモデルが「より蛇行する」ことを望んでいません。代わりに、最も効率的な推論経路に対するより強い直感を開発することを奨励しています。
その結果、Deep Cogito が述べているように、推論はより高速かつ効率的になり、標準的な動作モードでも幅広いパフォーマンスの向上につながります。
自己改善型AIへの道
Deep CogitoはAIコミュニティ全体では比較的新しい存在だが、技術開発は1年以上前から進められている。
同社は2025年4月、MetaのLlama 3.2を基盤としたオープンソースモデルを発表し、ステルスモードから脱却した。これらの初期モデルは有望な結果を示し、2024年11月にはBenchmarkが主導する1300万ドルのシード資金調達ラウンドを実施。BenchmarkのEric Vishriaが取締役に就任した。
VentureBeatが以前報じた通り、最小規模のCogito v1モデル(3Bと8B)は様々なベンチマークにおいて、同等のLlama 3モデルを常に上回る性能を示し、その差はしばしば顕著であった。
Deep CogitoのCEO兼共同創業者であるDrishan Arora(元GoogleのLLM主任エンジニア)は、同社のビジョンを「AlphaGoが自己対局を通じて進化したように、反復ごとに推論能力を洗練させるモデルの構築」と説明している。
このアプローチの中核となるのが、反復的蒸留と増幅(IDA)です。これは、静的なトレーニングプロンプトを、モデル自身の進化する洞察に置き換える手法です。
機械の直感を理解する
Cogito v2のリリースは、この自己改善ループを劇的に拡大する。その基礎となる考え方は単純明快だ:推論は推論時にのみ活性化されるのではなく、モデルのコアインテリジェンスに組み込まれるべきである。
これを実現するため、同社はモデルがトレーニング中に推論の連鎖を生成し、自らの中間思考プロセスから学習するシステムを実装した。
内部ベンチマークでは具体的な改善が確認されています。フラッグシップの671B MoEモデルは推論タスクにおいてDeepSeek R1を上回り、最新の0528モデルと同等またはそれ以上の性能を発揮しながら、平均で60%短い推論チェーンを使用しています。
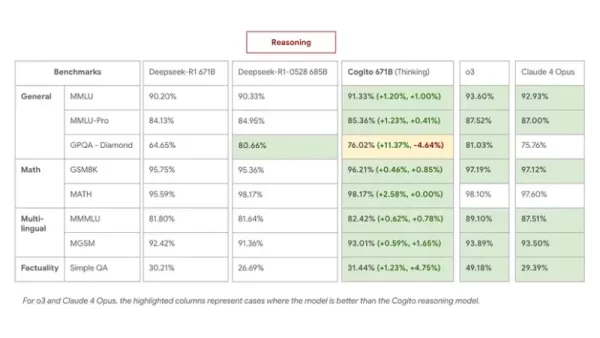
MMLU、GSM8K、MGSMなどのベンチマークでは、Cogito 671B MoEはQwen1.5-72BやDeepSeek v3といった主要なオープンモデルと競合し、Claude 4 Opusやo3などのクローズドモデルに迫る性能レベルを達成している。
主な知見は以下の通り:
- 推論モードにおいて、Cogito 671B MoEは多言語QAと一般知識ではDeepSeek R1 0528と同等の性能を示し、戦略的推論と論理的演繹ではそれを上回りました。
- 標準(推論なし)モードではDeepSeek v3 0324を上回り、拡張推論ステップがなくても蒸留された直感が性能向上をもたらすことを実証した。
- 推論を少ないステップで完了させることは、複雑なクエリに対する推論コストの削減と応答時間の短縮という実用的な利点をもたらす。
Arora は、これを目的地を検索することと、その場所がどこにあるかをすでに強く認識していることの違いに例えています。
「Cogitoモデルは推論中に適切な探索経路に対する優れた直感を発達させるため、その推論連鎖はDeepSeek R1よりも60%短い」と彼はXへの投稿で説明した。
Deep Cogitoモデルの優位性:機械直感の実践例
Cogito v2の内部テスト事例がこの能力を実証している。ある数学問題では、時速80マイルで走行する列車が240マイルを2.5時間未満で走破できるかユーザーが質問した。
多くのモデルが詳細な段階的計算を行い誤りを生じさせる中、Cogito 671Bは短い内部推論を経て240 ÷ 80 = 3時間を計算し、列車が時間内に到着できないと正しく結論づけた。この処理で使用した内部トークンは100未満であり、同じ解答にDeepSeek R1が使用した200以上を大幅に下回る。
米国最高裁判決の適用性に関する法的推論の例では、コギトの推論モードは明確な二段階論理を適用する:まず仮定事例が判例と一致するか判定し、次に結論を正当化する。このニュアンスのある解釈的推論は、多くのLLMにとって依然として課題である。
これらのモデルは曖昧性への対応も向上している。家族関係を特定する多段階質問(例:「アリスはボブの母、ボブはチャーリーの父。アリスはチャーリーにとって何者か?」)において、Cogito v2モデルは表現が微妙に変化しても「祖母」を正しく識別する——他のオープンモデルがしばしば躓く点である。
大規模環境での効率性実現
注目すべきは、Deep Cogitoが8つのCogitoモデル(v1シリーズを含む)の総トレーニングコストを350万ドル未満と報告している点だ。これは主要なフロンティアモデルの報告予算(9桁規模)のほんの一部に過ぎない。
この予算は、大規模なデータ生成、合成強化学習、インフラストラクチャ、そして1,000を超えるトレーニング実験をカバーした。
Arora は、この費用対効果を中核的な原則に起因すると考えています。よりスマートなモデルを構築するには、単にモデルに多くのデータを供給するだけでなく、より優れた基礎的な理解(「事前知識」)が不可欠であるということです。
冗長または誤解を招く推論経路を回避するようモデルを訓練することで、Cogito v2 は推論時間やコストを膨らませることなく堅牢なパフォーマンスを実現します。これは、レイテンシとコストが重要な考慮事項となる API ベースのサービスやエッジデバイスへの展開において、決定的な優位性となります。
今後の展望:Deep Cogitoのロードマップ
Cogito v2は最終製品ではなく、反復的な進化の一歩である。アローラは同社のアプローチを「ヒルクライミング」と表現する:モデルを実行し、その推論から学び、その教訓を抽出する——このサイクルを繰り返す。各モデルリリースは前身を基盤として構築される。
Deep Cogitoは現在および将来の全モデルについて、オープンソースへの取り組みを継続します。同社の取り組みは既に、Benchmarkのエリック・ヴィシュリアやSouth Park Commonsのアディティア・アガルワルといった投資家からの支持を得ています。
インフラストラクチャパートナーには、Hugging Face、Together AI、RunPod、Baseten、MetaのLlamaチーム、Unslothが含まれます。
開発者、研究者、企業向けに、これらのモデルは本日よりローカル利用、マルチモーダル比較、ドメイン特化型微調整が可能である。
オープンソースAIコミュニティにとって、Cogito v2は単なるベンチマークの到達点を超えた意義を持つ。それは知能構築の新たなパラダイムを提示する——より深く考えることではなく、より良く考える方法を学ぶことに焦点を当てたアプローチである。
関連記事
 Sunoの筆頭投資家:投稿の削除では著作権訴訟の抜け穴を塞げない
待望のAI音楽生成プラットフォーム「Suno」は、厳しい著作権をめぐる争いに直面しているが、同社の主要投資家による率直な発言が、相手側にとってまさに待ち望んでいた証拠を手にさせてしまった可能性がある。 Sunoの主要投資家であるMenlo Venturesのパートナー、C.C. Gong氏は先日、同社の現在の法的防御戦略と真っ向から矛盾するツイートを削除した。これまでの著作権訴訟において、Suno
「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
関連特集おすすめ
漫画制作
Sunoの筆頭投資家:投稿の削除では著作権訴訟の抜け穴を塞げない
待望のAI音楽生成プラットフォーム「Suno」は、厳しい著作権をめぐる争いに直面しているが、同社の主要投資家による率直な発言が、相手側にとってまさに待ち望んでいた証拠を手にさせてしまった可能性がある。 Sunoの主要投資家であるMenlo Venturesのパートナー、C.C. Gong氏は先日、同社の現在の法的防御戦略と真っ向から矛盾するツイートを削除した。これまでの著作権訴訟において、Suno
「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
関連特集おすすめ
漫画制作
 少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
 15 ツール
15 ツール
 xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

 コメント (2)
0/500
コメント (2)
0/500
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
サンフランシスコに拠点を置くAI研究スタートアップDeep Cogito(元Googleエンジニアらが設立)は、4つの新たな「オープン系」大規模言語モデル(LLM)を公開した。これらのモデルは、時間経過とともに推論能力を効果的に向上させ、自律的に能力を高めるという核心的な課題に取り組む。
「Cogito v2ファミリー」として総称されるこれらのモデルは、700億から6,710億のパラメータ数を有する。AI開発者や企業向けに、許容範囲の広いライセンスと完全オープンライセンスの組み合わせで提供される。リリース内容は以下の通り:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
DenseモデルとMoEモデルはそれぞれ異なる目的を果たします。Denseモデル(70Bおよび405B)は入力ごとに全パラメータを活性化するため、予測可能性が高く、多様なハードウェア環境での展開が容易です。
低遅延タスク、微調整、GPU容量が制約される環境に最適です。一方、MoEモデル(109Bおよび671B)は疎なルーティング機構を採用し、クエリごとに特殊な「エキスパート」サブネットワークの一部のみを活性化します。この設計により、計算コストを比例的に増加させることなく、はるかに大規模なモデル総サイズをサポートします。
このためMoEモデルは高性能推論と複雑な推論研究に優れ、より低い実行コストでトップクラスの精度を実現します。Cogito v2ラインナップでは671B MoEモデルがフラッグシップであり、その規模と効率的なルーティングにより、主要なオープンモデルと同等またはそれ以上のベンチマーク性能を発揮します。多くの場合、推論チェーンを大幅に短縮しながらです。
本モデルは現在、企業利用向けにHugging Face経由、ローカル展開向けにUnsloth経由でアクセス可能です。自己ホスティングが困難な場合、Together AI、Baseten、RunPodによるAPIアクセスが提供されます。
671Bモデルの量子化FP8(8ビット浮動小数点)版も利用可能です。パラメータ精度を16ビットから8ビットに削減することで、より高速・低コスト・広範なハードウェア展開を実現し、通常は元の性能の95~99%を維持します。ただし、特定の数学問題や推論など高精度を要するタスクでは精度がわずかに低下する可能性があります。
4つのCogito v2モデルは全てハイブリッド推論システムです:即座に回答するか、必要に応じて内部で推論を実行してから応答します。
この内省は単なる推論時の機能ではなく、トレーニングプロセスそのものに不可欠な要素です。
モデルは推論経路を内面化するよう訓練されます。解決に至る過程で踏むステップ、つまり内部の「思考」が、モデルの基礎となる重みに再構築されるのです。
時間の経過とともに、生産的な推論の流れと無関係なものを区別することを学びます。
Deep Cogito のブログで説明されているように、研究者たちは、答えを見つけるためにモデルが「より蛇行する」ことを望んでいません。代わりに、最も効率的な推論経路に対するより強い直感を開発することを奨励しています。
その結果、Deep Cogito が述べているように、推論はより高速かつ効率的になり、標準的な動作モードでも幅広いパフォーマンスの向上につながります。
自己改善型AIへの道
Deep CogitoはAIコミュニティ全体では比較的新しい存在だが、技術開発は1年以上前から進められている。
同社は2025年4月、MetaのLlama 3.2を基盤としたオープンソースモデルを発表し、ステルスモードから脱却した。これらの初期モデルは有望な結果を示し、2024年11月にはBenchmarkが主導する1300万ドルのシード資金調達ラウンドを実施。BenchmarkのEric Vishriaが取締役に就任した。
VentureBeatが以前報じた通り、最小規模のCogito v1モデル(3Bと8B)は様々なベンチマークにおいて、同等のLlama 3モデルを常に上回る性能を示し、その差はしばしば顕著であった。
Deep CogitoのCEO兼共同創業者であるDrishan Arora(元GoogleのLLM主任エンジニア)は、同社のビジョンを「AlphaGoが自己対局を通じて進化したように、反復ごとに推論能力を洗練させるモデルの構築」と説明している。
このアプローチの中核となるのが、反復的蒸留と増幅(IDA)です。これは、静的なトレーニングプロンプトを、モデル自身の進化する洞察に置き換える手法です。
機械の直感を理解する
Cogito v2のリリースは、この自己改善ループを劇的に拡大する。その基礎となる考え方は単純明快だ:推論は推論時にのみ活性化されるのではなく、モデルのコアインテリジェンスに組み込まれるべきである。
これを実現するため、同社はモデルがトレーニング中に推論の連鎖を生成し、自らの中間思考プロセスから学習するシステムを実装した。
内部ベンチマークでは具体的な改善が確認されています。フラッグシップの671B MoEモデルは推論タスクにおいてDeepSeek R1を上回り、最新の0528モデルと同等またはそれ以上の性能を発揮しながら、平均で60%短い推論チェーンを使用しています。
MMLU、GSM8K、MGSMなどのベンチマークでは、Cogito 671B MoEはQwen1.5-72BやDeepSeek v3といった主要なオープンモデルと競合し、Claude 4 Opusやo3などのクローズドモデルに迫る性能レベルを達成している。
主な知見は以下の通り:
- 推論モードにおいて、Cogito 671B MoEは多言語QAと一般知識ではDeepSeek R1 0528と同等の性能を示し、戦略的推論と論理的演繹ではそれを上回りました。
- 標準(推論なし)モードではDeepSeek v3 0324を上回り、拡張推論ステップがなくても蒸留された直感が性能向上をもたらすことを実証した。
- 推論を少ないステップで完了させることは、複雑なクエリに対する推論コストの削減と応答時間の短縮という実用的な利点をもたらす。
Arora は、これを目的地を検索することと、その場所がどこにあるかをすでに強く認識していることの違いに例えています。
「Cogitoモデルは推論中に適切な探索経路に対する優れた直感を発達させるため、その推論連鎖はDeepSeek R1よりも60%短い」と彼はXへの投稿で説明した。
Deep Cogitoモデルの優位性:機械直感の実践例
Cogito v2の内部テスト事例がこの能力を実証している。ある数学問題では、時速80マイルで走行する列車が240マイルを2.5時間未満で走破できるかユーザーが質問した。
多くのモデルが詳細な段階的計算を行い誤りを生じさせる中、Cogito 671Bは短い内部推論を経て240 ÷ 80 = 3時間を計算し、列車が時間内に到着できないと正しく結論づけた。この処理で使用した内部トークンは100未満であり、同じ解答にDeepSeek R1が使用した200以上を大幅に下回る。
米国最高裁判決の適用性に関する法的推論の例では、コギトの推論モードは明確な二段階論理を適用する:まず仮定事例が判例と一致するか判定し、次に結論を正当化する。このニュアンスのある解釈的推論は、多くのLLMにとって依然として課題である。
これらのモデルは曖昧性への対応も向上している。家族関係を特定する多段階質問(例:「アリスはボブの母、ボブはチャーリーの父。アリスはチャーリーにとって何者か?」)において、Cogito v2モデルは表現が微妙に変化しても「祖母」を正しく識別する——他のオープンモデルがしばしば躓く点である。
大規模環境での効率性実現
注目すべきは、Deep Cogitoが8つのCogitoモデル(v1シリーズを含む)の総トレーニングコストを350万ドル未満と報告している点だ。これは主要なフロンティアモデルの報告予算(9桁規模)のほんの一部に過ぎない。
この予算は、大規模なデータ生成、合成強化学習、インフラストラクチャ、そして1,000を超えるトレーニング実験をカバーした。
Arora は、この費用対効果を中核的な原則に起因すると考えています。よりスマートなモデルを構築するには、単にモデルに多くのデータを供給するだけでなく、より優れた基礎的な理解(「事前知識」)が不可欠であるということです。
冗長または誤解を招く推論経路を回避するようモデルを訓練することで、Cogito v2 は推論時間やコストを膨らませることなく堅牢なパフォーマンスを実現します。これは、レイテンシとコストが重要な考慮事項となる API ベースのサービスやエッジデバイスへの展開において、決定的な優位性となります。
今後の展望:Deep Cogitoのロードマップ
Cogito v2は最終製品ではなく、反復的な進化の一歩である。アローラは同社のアプローチを「ヒルクライミング」と表現する:モデルを実行し、その推論から学び、その教訓を抽出する——このサイクルを繰り返す。各モデルリリースは前身を基盤として構築される。
Deep Cogitoは現在および将来の全モデルについて、オープンソースへの取り組みを継続します。同社の取り組みは既に、Benchmarkのエリック・ヴィシュリアやSouth Park Commonsのアディティア・アガルワルといった投資家からの支持を得ています。
インフラストラクチャパートナーには、Hugging Face、Together AI、RunPod、Baseten、MetaのLlamaチーム、Unslothが含まれます。
開発者、研究者、企業向けに、これらのモデルは本日よりローカル利用、マルチモーダル比較、ドメイン特化型微調整が可能である。
オープンソースAIコミュニティにとって、Cogito v2は単なるベンチマークの到達点を超えた意義を持つ。それは知能構築の新たなパラダイムを提示する——より深く考えることではなく、より良く考える方法を学ぶことに焦点を当てたアプローチである。










 Sunoの筆頭投資家:投稿の削除では著作権訴訟の抜け穴を塞げない
待望のAI音楽生成プラットフォーム「Suno」は、厳しい著作権をめぐる争いに直面しているが、同社の主要投資家による率直な発言が、相手側にとってまさに待ち望んでいた証拠を手にさせてしまった可能性がある。 Sunoの主要投資家であるMenlo Venturesのパートナー、C.C. Gong氏は先日、同社の現在の法的防御戦略と真っ向から矛盾するツイートを削除した。これまでの著作権訴訟において、Suno
Sunoの筆頭投資家:投稿の削除では著作権訴訟の抜け穴を塞げない
待望のAI音楽生成プラットフォーム「Suno」は、厳しい著作権をめぐる争いに直面しているが、同社の主要投資家による率直な発言が、相手側にとってまさに待ち望んでいた証拠を手にさせてしまった可能性がある。 Sunoの主要投資家であるMenlo Venturesのパートナー、C.C. Gong氏は先日、同社の現在の法的防御戦略と真っ向から矛盾するツイートを削除した。これまでの著作権訴訟において、Suno
 「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
 ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













