
















 Дом
Дом
Deep Cogito представляет четыре гибридные модели рассуждения с открытым исходным кодом, отличающиеся самосовершенствующейся интуицией
Deep Cogito, стартап из Сан-Франциско, занимающийся исследованиями в области искусственного интеллекта и основанный бывшими инженерами Google, выпустил четыре новых «открытых» больших языковых модели (LLM). Эти модели решают ключевую задачу: научиться более эффективно рассуждать с течением времени и становиться более способными к автономной работе.
Эти модели, известные под общим названием Cogito v2, имеют от 70 до 671 миллиарда параметров. Они доступны разработчикам искусственного интеллекта и компаниям на условиях смешанных разрешительных и полностью открытых лицензий. В релиз входят:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Модели Dense и MoE служат разным целям. Плотные варианты (70B и 405B) активируют все параметры для каждого ввода, что делает их предсказуемыми и упрощает развертывание на различных аппаратных конфигурациях.
Они идеально подходят для задач с низкой задержкой, тонкой настройки и сред с ограниченной мощностью GPU. В отличие от них, модели MoE (109B и 671B) используют механизм разреженной маршрутизации, активируя только подмножество специализированных «экспертных» подсетей для каждого запроса. Такая конструкция поддерживает гораздо большие общие размеры моделей без пропорционального увеличения вычислительных затрат.
Таким образом, модели MoE превосходны в высокопроизводительном выводе и исследовании сложных рассуждений, обеспечивая высочайшую точность при меньших затратах на выполнение. В линейке Cogito v2 модель 671B MoE является флагманской, используя свой масштаб и эффективную маршрутизацию, чтобы соответствовать или превосходить ведущие открытые модели по тестам — часто с гораздо более короткими цепочками рассуждений.
Модели теперь доступны через Hugging Face для корпоративного использования и Unsloth для локального развертывания. Для тех, кто не может самостоятельно хостить, доступ к API предоставляется Together AI, Baseten и RunPod.
Также доступна квантовая версия модели 671B с FP8 (8-битная плавающая запятая). За счет уменьшения точности параметров с 16 до 8 бит эта версия позволяет быстрее, дешевле и доступнее развертывать оборудование, при этом обычно сохраняя 95–99 % исходной производительности. Однако точность может немного снизиться при выполнении задач, требующих высокой точности, таких как определенные математические или логические задачи.
Все четыре модели Cogito v2 являются гибридными системами рассуждения: они могут отвечать мгновенно или, при необходимости, перед ответом проводить внутреннюю рефлексию.
Это размышление — не просто функция времени вывода, а неотъемлемая часть самого процесса обучения.
Модели обучаются интернализировать свои пути рассуждений. Шаги, которые они предпринимают для достижения решений — их внутренние «мысли» — возвращаются в основополагающие веса модели.
Со временем они учатся отличать продуктивные линии рассуждений от нерелевантных.
Как объясняется в блоге Deep Cogito, исследователи не поощряют модель «блуждать» в поисках ответа. Вместо этого они поощряют ее развивать более сильную интуицию для выбора наиболее эффективного пути рассуждения.
Результатом, по утверждению Deep Cogito, является более быстрое и эффективное мышление, что приводит к значительному повышению производительности даже в стандартном режиме работы.
Путь к самосовершенствующемуся ИИ
Хотя Deep Cogito является относительно новым игроком в широком сообществе ИИ, компания разрабатывает свою технологию уже более года.
Компания начала свою деятельность в апреле 2025 года с открытых моделей, основанных на Meta Llama 3.2. Эти первоначальные модели дали многообещающие результаты после раунда начального финансирования в размере 13 миллионов долларов, проведенного Benchmark в ноябре 2024 года. Эрик Вишрия из Benchmark вошел в совет директоров компании.
Как ранее сообщал VentureBeat, самые маленькие модели Cogito v1 (3B и 8B) стабильно превосходили сопоставимые модели Llama 3 по различным тестам, часто с значительным отрывом.
Генеральный директор и соучредитель Deep Cogito, Дришан Арора, бывший ведущий инженер LLM в Google, описывает видение компании как создание моделей, которые совершенствуют свое мышление с каждой итерацией, подобно тому, как AlphaGo совершенствовался через самоигра.
В основе этого подхода лежит итеративная дистилляция и амплификация (IDA), метод, который заменяет статические подсказки для обучения собственными развивающимися идеями модели.
Понимание интуиции машины
Версия Cogito v2 значительно расширяет этот цикл самосовершенствования. Основная идея проста: рассуждения должны быть вплетены в основной интеллект модели, а не просто активироваться во время вывода.
Для достижения этой цели компания внедрила систему, в которой модели генерируют цепочки рассуждений во время обучения, а затем учатся на основе своих собственных промежуточных мыслительных процессов.
Внутренние тесты подтверждают ощутимые улучшения. Флагманская модель 671B MoE превосходит DeepSeek R1 в задачах рассуждения, сравниваясь или превосходя ее последнюю модель 0528 при использовании цепочек рассуждений, которые в среднем на 60 % короче.
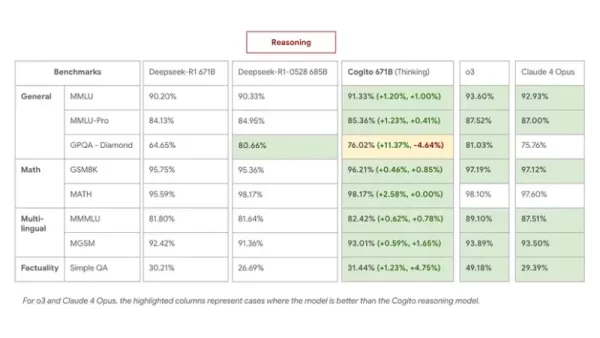
В тестах MMLU, GSM8K и MGSM Cogito 671B MoE демонстрирует конкурентоспособность с ведущими открытыми моделями, такими как Qwen1.5-72B и DeepSeek v3, приближаясь к уровню производительности закрытых моделей, таких как Claude 4 Opus и o3.
Ключевые выводы включают:
- В режиме рассуждений Cogito 671B MoE сравнялся с DeepSeek R1 0528 по многоязычному QA и общим знаниям, а также превзошел его в стратегии и логическом выводе.
- В стандартном режиме (без рассуждений) он превзошел DeepSeek v3 0324, продемонстрировав, что дистиллированная интуиция обеспечивает повышение производительности даже без расширенных шагов рассуждения.
- Завершение рассуждений за меньшее количество шагов дает практические преимущества: более низкие затраты на вывод и более быстрое время отклика на сложные запросы.
Арора сравнивает это с разницей между поиском места назначения и уже имеющимся четким представлением о том, где оно находится.
«Поскольку модели Cogito развивают лучшую интуицию для правильной траектории поиска во время вывода, их цепочки рассуждений на 60 % короче, чем у DeepSeek R1», — пояснил он в посте на X.
Преимущества моделей Deep Cogito: интуиция машины в действии
Примеры из внутреннего тестирования Cogito v2 иллюстрируют эту способность. В одной математической задаче пользователь спрашивает, может ли поезд, движущийся со скоростью 80 миль в час, преодолеть 240 миль менее чем за 2,5 часа.
В то время как многие модели выполняют подробные пошаговые вычисления и могут допускать ошибки, Cogito 671B выполняет краткое внутреннее размышление, вычисляет 240 ÷ 80 = 3 часа и правильно заключает, что поезд не сможет прибыть вовремя. Он использует менее 100 внутренних токенов по сравнению с более чем 200, используемыми DeepSeek R1 для того же ответа.
В примере юридического обоснования применимости решения Верховного суда США режим обоснования Cogito применяет четкую двухэтапную логику: сначала определяется, соответствует ли гипотетический случай прецеденту, а затем обосновывается его вывод. Это тонкое, интерпретативное обоснование остается проблемой для многих LLM.
Модели также демонстрируют улучшенную обработку неоднозначности. В многоступенчатых вопросах, таких как определение семейных отношений (например, «Элис — мать Боба, Боб — отец Чарли. Кем является Элис для Чарли?»), модели Cogito v2 правильно определяют «бабушка», даже когда формулировка слегка изменена — момент, в котором другие открытые модели часто затрудняются.
Достижение эффективности в масштабе
Примечательно, что Deep Cogito сообщает об обучении всех восьми своих моделей Cogito (включая серию v1) с общей стоимостью менее 3,5 миллионов долларов — это лишь часть от заявленных девятизначных бюджетов некоторых ведущих передовых моделей.
Этот бюджет покрыл расходы на обширную генерацию данных, синтетическое усиление, инфраструктуру и более 1000 экспериментов по обучению.
Арора объясняет эту экономическую эффективность основным принципом: создание более интеллектуальных моделей зависит от лучшего фундаментального понимания («априорных знаний»), а не просто от подачи им большего количества данных.
Обучая модели избегать избыточных или вводящих в заблуждение путей рассуждений, Cogito v2 обеспечивает надежную производительность без увеличения времени или стоимости вывода — это критически важное преимущество для сервисов на основе API или развертывания на периферийных устройствах, где задержка и затраты являются ключевыми факторами.
Взгляд в будущее: дорожная карта Deep Cogito
Cogito v2 представляет собой итеративный шаг, а не конечный продукт. Арора описывает подход компании как «подъем на гору»: запуск моделей, обучение на основе их рассуждений, извлечение уроков и повторение цикла. Каждая версия модели основана на своей предшественнице.
Deep Cogito по-прежнему привержена открытому исходному коду для всех своих моделей, как нынешних, так и будущих. Ее работа уже получила поддержку со стороны таких инвесторов, как Эрик Вишрия из Benchmark и Адитья Агарвал из South Park Commons.
Партнерами по инфраструктуре являются Hugging Face, Together AI, RunPod, Baseten, команда Meta Llama и Unsloth.
Для разработчиков, исследователей и предприятий модели доступны уже сегодня для локального использования, мультимодального сравнения и доработки под конкретные области.
Для сообщества разработчиков открытого программного обеспечения Cogito v2 — это не просто важная веха. Это новая парадигма создания интеллекта, ориентированная не на более интенсивное мышление, а на обучение более эффективному мышлению.
Связанная статья
 Игра «Xiaolongxia» от Tencent превзошла все ожидания: команда увеличила пропускную способность в 10 раз, принесла извинения и выплатила компенсации
Компания Tencent официально запустила WorkBuddy — универсального интеллектуального агента на базе искусственного интеллекта, что знаменует собой начало нового этапа в гонке за создание прикладных реше
Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Рекомендации по связанным специальным темам
Создание комиксов
Игра «Xiaolongxia» от Tencent превзошла все ожидания: команда увеличила пропускную способность в 10 раз, принесла извинения и выплатила компенсации
Компания Tencent официально запустила WorkBuddy — универсального интеллектуального агента на базе искусственного интеллекта, что знаменует собой начало нового этапа в гонке за создание прикладных реше
Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (2)
Комментарии (2)
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
Deep Cogito, стартап из Сан-Франциско, занимающийся исследованиями в области искусственного интеллекта и основанный бывшими инженерами Google, выпустил четыре новых «открытых» больших языковых модели (LLM). Эти модели решают ключевую задачу: научиться более эффективно рассуждать с течением времени и становиться более способными к автономной работе.
Эти модели, известные под общим названием Cogito v2, имеют от 70 до 671 миллиарда параметров. Они доступны разработчикам искусственного интеллекта и компаниям на условиях смешанных разрешительных и полностью открытых лицензий. В релиз входят:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Модели Dense и MoE служат разным целям. Плотные варианты (70B и 405B) активируют все параметры для каждого ввода, что делает их предсказуемыми и упрощает развертывание на различных аппаратных конфигурациях.
Они идеально подходят для задач с низкой задержкой, тонкой настройки и сред с ограниченной мощностью GPU. В отличие от них, модели MoE (109B и 671B) используют механизм разреженной маршрутизации, активируя только подмножество специализированных «экспертных» подсетей для каждого запроса. Такая конструкция поддерживает гораздо большие общие размеры моделей без пропорционального увеличения вычислительных затрат.
Таким образом, модели MoE превосходны в высокопроизводительном выводе и исследовании сложных рассуждений, обеспечивая высочайшую точность при меньших затратах на выполнение. В линейке Cogito v2 модель 671B MoE является флагманской, используя свой масштаб и эффективную маршрутизацию, чтобы соответствовать или превосходить ведущие открытые модели по тестам — часто с гораздо более короткими цепочками рассуждений.
Модели теперь доступны через Hugging Face для корпоративного использования и Unsloth для локального развертывания. Для тех, кто не может самостоятельно хостить, доступ к API предоставляется Together AI, Baseten и RunPod.
Также доступна квантовая версия модели 671B с FP8 (8-битная плавающая запятая). За счет уменьшения точности параметров с 16 до 8 бит эта версия позволяет быстрее, дешевле и доступнее развертывать оборудование, при этом обычно сохраняя 95–99 % исходной производительности. Однако точность может немного снизиться при выполнении задач, требующих высокой точности, таких как определенные математические или логические задачи.
Все четыре модели Cogito v2 являются гибридными системами рассуждения: они могут отвечать мгновенно или, при необходимости, перед ответом проводить внутреннюю рефлексию.
Это размышление — не просто функция времени вывода, а неотъемлемая часть самого процесса обучения.
Модели обучаются интернализировать свои пути рассуждений. Шаги, которые они предпринимают для достижения решений — их внутренние «мысли» — возвращаются в основополагающие веса модели.
Со временем они учатся отличать продуктивные линии рассуждений от нерелевантных.
Как объясняется в блоге Deep Cogito, исследователи не поощряют модель «блуждать» в поисках ответа. Вместо этого они поощряют ее развивать более сильную интуицию для выбора наиболее эффективного пути рассуждения.
Результатом, по утверждению Deep Cogito, является более быстрое и эффективное мышление, что приводит к значительному повышению производительности даже в стандартном режиме работы.
Путь к самосовершенствующемуся ИИ
Хотя Deep Cogito является относительно новым игроком в широком сообществе ИИ, компания разрабатывает свою технологию уже более года.
Компания начала свою деятельность в апреле 2025 года с открытых моделей, основанных на Meta Llama 3.2. Эти первоначальные модели дали многообещающие результаты после раунда начального финансирования в размере 13 миллионов долларов, проведенного Benchmark в ноябре 2024 года. Эрик Вишрия из Benchmark вошел в совет директоров компании.
Как ранее сообщал VentureBeat, самые маленькие модели Cogito v1 (3B и 8B) стабильно превосходили сопоставимые модели Llama 3 по различным тестам, часто с значительным отрывом.
Генеральный директор и соучредитель Deep Cogito, Дришан Арора, бывший ведущий инженер LLM в Google, описывает видение компании как создание моделей, которые совершенствуют свое мышление с каждой итерацией, подобно тому, как AlphaGo совершенствовался через самоигра.
В основе этого подхода лежит итеративная дистилляция и амплификация (IDA), метод, который заменяет статические подсказки для обучения собственными развивающимися идеями модели.
Понимание интуиции машины
Версия Cogito v2 значительно расширяет этот цикл самосовершенствования. Основная идея проста: рассуждения должны быть вплетены в основной интеллект модели, а не просто активироваться во время вывода.
Для достижения этой цели компания внедрила систему, в которой модели генерируют цепочки рассуждений во время обучения, а затем учатся на основе своих собственных промежуточных мыслительных процессов.
Внутренние тесты подтверждают ощутимые улучшения. Флагманская модель 671B MoE превосходит DeepSeek R1 в задачах рассуждения, сравниваясь или превосходя ее последнюю модель 0528 при использовании цепочек рассуждений, которые в среднем на 60 % короче.
В тестах MMLU, GSM8K и MGSM Cogito 671B MoE демонстрирует конкурентоспособность с ведущими открытыми моделями, такими как Qwen1.5-72B и DeepSeek v3, приближаясь к уровню производительности закрытых моделей, таких как Claude 4 Opus и o3.
Ключевые выводы включают:
- В режиме рассуждений Cogito 671B MoE сравнялся с DeepSeek R1 0528 по многоязычному QA и общим знаниям, а также превзошел его в стратегии и логическом выводе.
- В стандартном режиме (без рассуждений) он превзошел DeepSeek v3 0324, продемонстрировав, что дистиллированная интуиция обеспечивает повышение производительности даже без расширенных шагов рассуждения.
- Завершение рассуждений за меньшее количество шагов дает практические преимущества: более низкие затраты на вывод и более быстрое время отклика на сложные запросы.
Арора сравнивает это с разницей между поиском места назначения и уже имеющимся четким представлением о том, где оно находится.
«Поскольку модели Cogito развивают лучшую интуицию для правильной траектории поиска во время вывода, их цепочки рассуждений на 60 % короче, чем у DeepSeek R1», — пояснил он в посте на X.
Преимущества моделей Deep Cogito: интуиция машины в действии
Примеры из внутреннего тестирования Cogito v2 иллюстрируют эту способность. В одной математической задаче пользователь спрашивает, может ли поезд, движущийся со скоростью 80 миль в час, преодолеть 240 миль менее чем за 2,5 часа.
В то время как многие модели выполняют подробные пошаговые вычисления и могут допускать ошибки, Cogito 671B выполняет краткое внутреннее размышление, вычисляет 240 ÷ 80 = 3 часа и правильно заключает, что поезд не сможет прибыть вовремя. Он использует менее 100 внутренних токенов по сравнению с более чем 200, используемыми DeepSeek R1 для того же ответа.
В примере юридического обоснования применимости решения Верховного суда США режим обоснования Cogito применяет четкую двухэтапную логику: сначала определяется, соответствует ли гипотетический случай прецеденту, а затем обосновывается его вывод. Это тонкое, интерпретативное обоснование остается проблемой для многих LLM.
Модели также демонстрируют улучшенную обработку неоднозначности. В многоступенчатых вопросах, таких как определение семейных отношений (например, «Элис — мать Боба, Боб — отец Чарли. Кем является Элис для Чарли?»), модели Cogito v2 правильно определяют «бабушка», даже когда формулировка слегка изменена — момент, в котором другие открытые модели часто затрудняются.
Достижение эффективности в масштабе
Примечательно, что Deep Cogito сообщает об обучении всех восьми своих моделей Cogito (включая серию v1) с общей стоимостью менее 3,5 миллионов долларов — это лишь часть от заявленных девятизначных бюджетов некоторых ведущих передовых моделей.
Этот бюджет покрыл расходы на обширную генерацию данных, синтетическое усиление, инфраструктуру и более 1000 экспериментов по обучению.
Арора объясняет эту экономическую эффективность основным принципом: создание более интеллектуальных моделей зависит от лучшего фундаментального понимания («априорных знаний»), а не просто от подачи им большего количества данных.
Обучая модели избегать избыточных или вводящих в заблуждение путей рассуждений, Cogito v2 обеспечивает надежную производительность без увеличения времени или стоимости вывода — это критически важное преимущество для сервисов на основе API или развертывания на периферийных устройствах, где задержка и затраты являются ключевыми факторами.
Взгляд в будущее: дорожная карта Deep Cogito
Cogito v2 представляет собой итеративный шаг, а не конечный продукт. Арора описывает подход компании как «подъем на гору»: запуск моделей, обучение на основе их рассуждений, извлечение уроков и повторение цикла. Каждая версия модели основана на своей предшественнице.
Deep Cogito по-прежнему привержена открытому исходному коду для всех своих моделей, как нынешних, так и будущих. Ее работа уже получила поддержку со стороны таких инвесторов, как Эрик Вишрия из Benchmark и Адитья Агарвал из South Park Commons.
Партнерами по инфраструктуре являются Hugging Face, Together AI, RunPod, Baseten, команда Meta Llama и Unsloth.
Для разработчиков, исследователей и предприятий модели доступны уже сегодня для локального использования, мультимодального сравнения и доработки под конкретные области.
Для сообщества разработчиков открытого программного обеспечения Cogito v2 — это не просто важная веха. Это новая парадигма создания интеллекта, ориентированная не на более интенсивное мышление, а на обучение более эффективному мышлению.










 Игра «Xiaolongxia» от Tencent превзошла все ожидания: команда увеличила пропускную способность в 10 раз, принесла извинения и выплатила компенсации
Компания Tencent официально запустила WorkBuddy — универсального интеллектуального агента на базе искусственного интеллекта, что знаменует собой начало нового этапа в гонке за создание прикладных реше
Игра «Xiaolongxia» от Tencent превзошла все ожидания: команда увеличила пропускную способность в 10 раз, принесла извинения и выплатила компенсации
Компания Tencent официально запустила WorkBuddy — универсального интеллектуального агента на базе искусственного интеллекта, что знаменует собой начало нового этапа в гонке за создание прикладных реше
 Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
Главный инвестор Suno: удаление постов не устранит лазейку в законодательстве об авторском праве
Долгожданная платформа Suno, создающая музыку с помощью ИИ, столкнулась с серьезной судебной тяжбой по поводу авторских прав, а откровенное замечание ее главного инвестора, возможно, предоставило прот
 Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













