
















 Maison
Maison
Deep Cogito dévoile quatre modèles de raisonnement hybrides open source dotés d'une intuition auto-améliorante
Deep Cogito, une start-up de recherche en IA basée à San Francisco et fondée par d'anciens ingénieurs de Google, a publié quatre nouveaux modèles linguistiques à grande échelle (LLM) « semi-ouverts ». Ces modèles s'attaquent à un défi majeur : apprendre à raisonner plus efficacement au fil du temps et devenir plus autonomes.
Collectivement connus sous le nom de famille Cogito v2, ces modèles comptent entre 70 et 671 milliards de paramètres. Ils sont mis à la disposition des développeurs et des entreprises spécialisés dans l'IA sous des licences mixtes permissives et entièrement ouvertes. La version comprend :
- Cogito v2-70B (dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (dense)
- Cogito v2-671B (MoE)
Les modèles Dense et MoE ont des objectifs distincts. Les variantes Dense (70B et 405B) activent tous les paramètres pour chaque entrée, ce qui les rend prévisibles et plus faciles à déployer sur diverses configurations matérielles.
Ils sont idéaux pour les tâches à faible latence, le réglage fin et les environnements avec une capacité GPU limitée. En revanche, les modèles MoE (109B et 671B) utilisent un mécanisme de routage clairsemé, n'activant qu'un sous-ensemble de sous-réseaux « experts » spécialisés par requête. Cette conception prend en charge des tailles de modèles totales beaucoup plus importantes sans augmenter proportionnellement les coûts de calcul.
Ainsi, les modèles MoE excellent dans l'inférence haute performance et la recherche de raisonnement complexe, offrant une précision de premier ordre avec des coûts d'exécution réduits. Dans la gamme Cogito v2, le modèle MoE 671B est le produit phare. Il utilise son échelle et son routage efficace pour égaler ou surpasser les principaux modèles ouverts sur les benchmarks, souvent avec des chaînes de raisonnement beaucoup plus courtes.
Les modèles sont désormais accessibles via Hugging Face pour une utilisation en entreprise et Unsloth pour un déploiement local. Pour ceux qui ne peuvent pas les héberger eux-mêmes, l'accès à l'API est fourni par Together AI, Baseten et RunPod.
Une version quantifiée FP8 (virgule flottante 8 bits) du modèle 671B est également disponible. En réduisant la précision des paramètres de 16 bits à 8 bits, cette version permet un déploiement matériel plus rapide, moins coûteux et plus accessible, tout en conservant généralement 95 à 99 % des performances d'origine. Cependant, la précision peut être légèrement réduite pour les tâches nécessitant une grande précision, telles que certains problèmes mathématiques ou de raisonnement.
Les quatre modèles Cogito v2 sont des systèmes de raisonnement hybrides : ils peuvent répondre instantanément ou, si nécessaire, engager une réflexion interne avant de répondre.
Cette réflexion n'est pas seulement une fonctionnalité au moment de l'inférence, elle fait partie intégrante du processus d'apprentissage lui-même.
Les modèles sont formés pour intérioriser leurs chemins de raisonnement. Les étapes qu'ils suivent pour parvenir à des solutions, leurs « pensées » internes, sont distillées dans les poids fondamentaux du modèle.
Au fil du temps, ils apprennent à distinguer les raisonnements productifs de ceux qui ne sont pas pertinents.
Comme expliqué dans le blog de Deep Cogito, les chercheurs découragent le modèle de « vagabonder davantage » pour trouver une réponse. Au contraire, ils l'encouragent à développer une intuition plus forte pour trouver le chemin de raisonnement le plus efficace.
Selon Deep Cogito, il en résulte un raisonnement à la fois plus rapide et plus efficace, qui se traduit par des gains de performance importants, même en mode de fonctionnement standard.
La voie vers une IA capable de s'améliorer
Bien que relativement nouveau dans la communauté de l'IA au sens large, Deep Cogito développe sa technologie depuis plus d'un an.
La société a été lancée en avril 2025 avec des modèles open source basés sur Llama 3.2 de Meta. Ces premiers modèles ont donné des résultats prometteurs, à la suite d'un tour de financement initial de 13 millions de dollars mené par Benchmark en novembre 2024. Eric Vishria, de Benchmark, a rejoint le conseil d'administration de la société.
Comme l'a déjà rapporté VentureBeat, les plus petits modèles Cogito v1 (3B et 8B) ont systématiquement surpassé les modèles Llama 3 comparables dans divers benchmarks, souvent avec des écarts significatifs.
Le PDG et cofondateur de Deep Cogito, Drishan Arora, ancien ingénieur en chef LLM chez Google, décrit la vision de l'entreprise comme la création de modèles qui affinent leur raisonnement à chaque itération, à l'instar de la manière dont AlphaGo s'est amélioré grâce à l'auto-apprentissage.
Au cœur de cette approche se trouve l'Iterated Distillation and Amplification (IDA), une méthode qui remplace les invites d'entraînement statiques par les propres connaissances évolutives du modèle.
Comprendre l'intuition des machines
La version Cogito v2 amplifie considérablement cette boucle d'auto-amélioration. L'idée de base est simple : le raisonnement doit être intégré à l'intelligence fondamentale du modèle, et non pas simplement activé lors de l'inférence.
Pour y parvenir, l'entreprise a mis en place un système dans lequel les modèles génèrent des chaînes de raisonnement pendant l'entraînement, puis apprennent à partir de leurs propres processus de réflexion intermédiaires.
Des benchmarks internes confirment des améliorations tangibles. Le modèle phare 671B MoE surpasse DeepSeek R1 dans les tâches de raisonnement, égalant ou dépassant son dernier modèle 0528 tout en utilisant des chaînes de raisonnement 60 % plus courtes en moyenne.
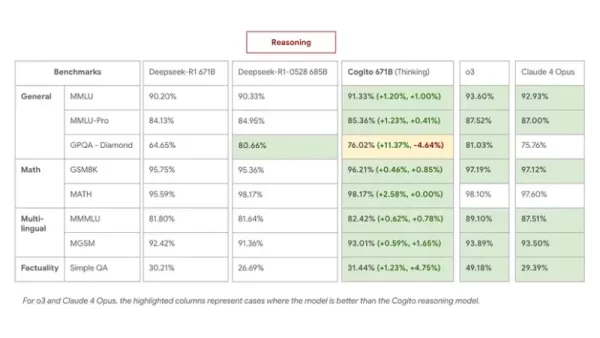
Sur des benchmarks tels que MMLU, GSM8K et MGSM, le Cogito 671B MoE est compétitif par rapport aux principaux modèles ouverts tels que Qwen1.5-72B et DeepSeek v3, se rapprochant du niveau de performance des modèles fermés tels que Claude 4 Opus et o3.
Voici les principales conclusions :
- En mode raisonnement, Cogito 671B MoE a égalé DeepSeek R1 0528 en matière de questions-réponses multilingues et de connaissances générales, et l'a surpassé en matière de stratégie et de déduction logique.
- En mode standard (sans raisonnement), il a surpassé DeepSeek v3 0324, démontrant que l'intuition distillée améliore les performances même sans étapes de raisonnement étendues.
- Réaliser le raisonnement en moins d'étapes présente des avantages pratiques : coûts d'inférence réduits et temps de réponse plus rapides pour les requêtes complexes.
Arora compare cela à la différence entre rechercher une destination et avoir déjà une idée précise de son emplacement.
« Comme les modèles Cogito développent une meilleure intuition pour la bonne trajectoire de recherche pendant l'inférence, leurs chaînes de raisonnement sont 60 % plus courtes que celles de DeepSeek R1 », a-t-il expliqué dans un article publié sur X.
Les points forts des modèles Deep Cogito : l'intuition machine en action
Des exemples tirés des tests internes de Cogito v2 illustrent cette capacité. Dans un problème mathématique, un utilisateur demande si un train roulant à 80 mph peut parcourir 240 miles en moins de 2,5 heures.
Alors que de nombreux modèles effectuent des calculs détaillés, étape par étape, et peuvent commettre des erreurs, Cogito 671B effectue une brève réflexion interne, calcule 240 ÷ 80 = 3 heures et conclut correctement que le train ne peut pas arriver à temps. Il utilise moins de 100 jetons internes, contre plus de 200 utilisés par DeepSeek R1 pour la même réponse.
Dans un exemple de raisonnement juridique concernant l'applicabilité d'une décision de la Cour suprême des États-Unis, le mode de raisonnement de Cogito applique une logique claire en deux étapes : déterminer d'abord si le cas hypothétique correspond au précédent, puis justifier sa conclusion. Ce raisonnement nuancé et interprétatif reste un défi pour de nombreux LLM.
Les modèles montrent également une meilleure gestion de l'ambiguïté. Sur des questions à plusieurs niveaux, comme la détermination des relations familiales (par exemple, « Alice est la mère de Bob, Bob est le père de Charlie. Quel est le lien entre Alice et Charlie ? »), les modèles Cogito v2 identifient correctement « grand-mère », même lorsque la formulation est légèrement modifiée, un point sur lequel les autres modèles ouverts butent souvent.
Atteindre l'efficacité à grande échelle
Il est remarquable que Deep Cogito déclare avoir formé ses huit modèles Cogito (y compris la série v1) pour un coût total inférieur à 3,5 millions de dollars, soit une fraction du budget à neuf chiffres déclaré pour certains modèles de pointe.
Ce budget a couvert la génération de données à grande échelle, le renforcement synthétique, l'infrastructure et plus de 1 000 expériences de formation.
Arora attribue cette rentabilité à un principe fondamental : la création de modèles plus intelligents dépend d'une meilleure compréhension fondamentale (« a priori »), et non pas simplement de l'apport d'un plus grand nombre de données.
En apprenant aux modèles à éviter les chemins de raisonnement redondants ou trompeurs, Cogito v2 offre des performances robustes sans augmenter le temps ou le coût d'inférence, ce qui constitue un avantage essentiel pour les services basés sur des API ou le déploiement de périphériques de pointe, où la latence et les coûts sont des facteurs clés.
Perspectives d'avenir : la feuille de route de Deep Cogito
Cogito v2 représente une étape itérative, et non un produit final. Arora décrit l'approche de l'entreprise comme une « ascension » : exécuter des modèles, tirer des enseignements de leur raisonnement, distiller ces leçons et répéter le cycle. Chaque version du modèle s'appuie sur la précédente.
Deep Cogito reste engagé dans l'open source pour tous ses modèles, actuels et futurs. Son travail a déjà reçu le soutien d'investisseurs tels qu'Eric Vishria de Benchmark et Aditya Agarwal de South Park Commons.
Parmi ses partenaires en matière d'infrastructure, on trouve Hugging Face, Together AI, RunPod, Baseten, l'équipe Llama de Meta et Unsloth.
Pour les développeurs, les chercheurs et les entreprises, les modèles sont disponibles dès aujourd'hui pour une utilisation locale, une comparaison multimodale et un ajustement spécifique à un domaine.
Pour la communauté open source de l'IA, Cogito v2 offre bien plus qu'une référence en matière de benchmark. Il présente un nouveau paradigme pour la construction de l'intelligence : un paradigme qui ne se concentre pas sur le fait de réfléchir plus, mais sur le fait d'apprendre à mieux réfléchir.
Article connexe
 Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Recommandations de sujets spéciaux liés
Création de bande dessinée
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (2)
commentaires (2)
![JamesCarter]()
Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
![WillieJones]()
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.
Deep Cogito, une start-up de recherche en IA basée à San Francisco et fondée par d'anciens ingénieurs de Google, a publié quatre nouveaux modèles linguistiques à grande échelle (LLM) « semi-ouverts ». Ces modèles s'attaquent à un défi majeur : apprendre à raisonner plus efficacement au fil du temps et devenir plus autonomes.
Collectivement connus sous le nom de famille Cogito v2, ces modèles comptent entre 70 et 671 milliards de paramètres. Ils sont mis à la disposition des développeurs et des entreprises spécialisés dans l'IA sous des licences mixtes permissives et entièrement ouvertes. La version comprend :
- Cogito v2-70B (dense)
- Cogito v2-109B (Mixture-of-Experts)
- Cogito v2-405B (dense)
- Cogito v2-671B (MoE)
Les modèles Dense et MoE ont des objectifs distincts. Les variantes Dense (70B et 405B) activent tous les paramètres pour chaque entrée, ce qui les rend prévisibles et plus faciles à déployer sur diverses configurations matérielles.
Ils sont idéaux pour les tâches à faible latence, le réglage fin et les environnements avec une capacité GPU limitée. En revanche, les modèles MoE (109B et 671B) utilisent un mécanisme de routage clairsemé, n'activant qu'un sous-ensemble de sous-réseaux « experts » spécialisés par requête. Cette conception prend en charge des tailles de modèles totales beaucoup plus importantes sans augmenter proportionnellement les coûts de calcul.
Ainsi, les modèles MoE excellent dans l'inférence haute performance et la recherche de raisonnement complexe, offrant une précision de premier ordre avec des coûts d'exécution réduits. Dans la gamme Cogito v2, le modèle MoE 671B est le produit phare. Il utilise son échelle et son routage efficace pour égaler ou surpasser les principaux modèles ouverts sur les benchmarks, souvent avec des chaînes de raisonnement beaucoup plus courtes.
Les modèles sont désormais accessibles via Hugging Face pour une utilisation en entreprise et Unsloth pour un déploiement local. Pour ceux qui ne peuvent pas les héberger eux-mêmes, l'accès à l'API est fourni par Together AI, Baseten et RunPod.
Une version quantifiée FP8 (virgule flottante 8 bits) du modèle 671B est également disponible. En réduisant la précision des paramètres de 16 bits à 8 bits, cette version permet un déploiement matériel plus rapide, moins coûteux et plus accessible, tout en conservant généralement 95 à 99 % des performances d'origine. Cependant, la précision peut être légèrement réduite pour les tâches nécessitant une grande précision, telles que certains problèmes mathématiques ou de raisonnement.
Les quatre modèles Cogito v2 sont des systèmes de raisonnement hybrides : ils peuvent répondre instantanément ou, si nécessaire, engager une réflexion interne avant de répondre.
Cette réflexion n'est pas seulement une fonctionnalité au moment de l'inférence, elle fait partie intégrante du processus d'apprentissage lui-même.
Les modèles sont formés pour intérioriser leurs chemins de raisonnement. Les étapes qu'ils suivent pour parvenir à des solutions, leurs « pensées » internes, sont distillées dans les poids fondamentaux du modèle.
Au fil du temps, ils apprennent à distinguer les raisonnements productifs de ceux qui ne sont pas pertinents.
Comme expliqué dans le blog de Deep Cogito, les chercheurs découragent le modèle de « vagabonder davantage » pour trouver une réponse. Au contraire, ils l'encouragent à développer une intuition plus forte pour trouver le chemin de raisonnement le plus efficace.
Selon Deep Cogito, il en résulte un raisonnement à la fois plus rapide et plus efficace, qui se traduit par des gains de performance importants, même en mode de fonctionnement standard.
La voie vers une IA capable de s'améliorer
Bien que relativement nouveau dans la communauté de l'IA au sens large, Deep Cogito développe sa technologie depuis plus d'un an.
La société a été lancée en avril 2025 avec des modèles open source basés sur Llama 3.2 de Meta. Ces premiers modèles ont donné des résultats prometteurs, à la suite d'un tour de financement initial de 13 millions de dollars mené par Benchmark en novembre 2024. Eric Vishria, de Benchmark, a rejoint le conseil d'administration de la société.
Comme l'a déjà rapporté VentureBeat, les plus petits modèles Cogito v1 (3B et 8B) ont systématiquement surpassé les modèles Llama 3 comparables dans divers benchmarks, souvent avec des écarts significatifs.
Le PDG et cofondateur de Deep Cogito, Drishan Arora, ancien ingénieur en chef LLM chez Google, décrit la vision de l'entreprise comme la création de modèles qui affinent leur raisonnement à chaque itération, à l'instar de la manière dont AlphaGo s'est amélioré grâce à l'auto-apprentissage.
Au cœur de cette approche se trouve l'Iterated Distillation and Amplification (IDA), une méthode qui remplace les invites d'entraînement statiques par les propres connaissances évolutives du modèle.
Comprendre l'intuition des machines
La version Cogito v2 amplifie considérablement cette boucle d'auto-amélioration. L'idée de base est simple : le raisonnement doit être intégré à l'intelligence fondamentale du modèle, et non pas simplement activé lors de l'inférence.
Pour y parvenir, l'entreprise a mis en place un système dans lequel les modèles génèrent des chaînes de raisonnement pendant l'entraînement, puis apprennent à partir de leurs propres processus de réflexion intermédiaires.
Des benchmarks internes confirment des améliorations tangibles. Le modèle phare 671B MoE surpasse DeepSeek R1 dans les tâches de raisonnement, égalant ou dépassant son dernier modèle 0528 tout en utilisant des chaînes de raisonnement 60 % plus courtes en moyenne.
Sur des benchmarks tels que MMLU, GSM8K et MGSM, le Cogito 671B MoE est compétitif par rapport aux principaux modèles ouverts tels que Qwen1.5-72B et DeepSeek v3, se rapprochant du niveau de performance des modèles fermés tels que Claude 4 Opus et o3.
Voici les principales conclusions :
- En mode raisonnement, Cogito 671B MoE a égalé DeepSeek R1 0528 en matière de questions-réponses multilingues et de connaissances générales, et l'a surpassé en matière de stratégie et de déduction logique.
- En mode standard (sans raisonnement), il a surpassé DeepSeek v3 0324, démontrant que l'intuition distillée améliore les performances même sans étapes de raisonnement étendues.
- Réaliser le raisonnement en moins d'étapes présente des avantages pratiques : coûts d'inférence réduits et temps de réponse plus rapides pour les requêtes complexes.
Arora compare cela à la différence entre rechercher une destination et avoir déjà une idée précise de son emplacement.
« Comme les modèles Cogito développent une meilleure intuition pour la bonne trajectoire de recherche pendant l'inférence, leurs chaînes de raisonnement sont 60 % plus courtes que celles de DeepSeek R1 », a-t-il expliqué dans un article publié sur X.
Les points forts des modèles Deep Cogito : l'intuition machine en action
Des exemples tirés des tests internes de Cogito v2 illustrent cette capacité. Dans un problème mathématique, un utilisateur demande si un train roulant à 80 mph peut parcourir 240 miles en moins de 2,5 heures.
Alors que de nombreux modèles effectuent des calculs détaillés, étape par étape, et peuvent commettre des erreurs, Cogito 671B effectue une brève réflexion interne, calcule 240 ÷ 80 = 3 heures et conclut correctement que le train ne peut pas arriver à temps. Il utilise moins de 100 jetons internes, contre plus de 200 utilisés par DeepSeek R1 pour la même réponse.
Dans un exemple de raisonnement juridique concernant l'applicabilité d'une décision de la Cour suprême des États-Unis, le mode de raisonnement de Cogito applique une logique claire en deux étapes : déterminer d'abord si le cas hypothétique correspond au précédent, puis justifier sa conclusion. Ce raisonnement nuancé et interprétatif reste un défi pour de nombreux LLM.
Les modèles montrent également une meilleure gestion de l'ambiguïté. Sur des questions à plusieurs niveaux, comme la détermination des relations familiales (par exemple, « Alice est la mère de Bob, Bob est le père de Charlie. Quel est le lien entre Alice et Charlie ? »), les modèles Cogito v2 identifient correctement « grand-mère », même lorsque la formulation est légèrement modifiée, un point sur lequel les autres modèles ouverts butent souvent.
Atteindre l'efficacité à grande échelle
Il est remarquable que Deep Cogito déclare avoir formé ses huit modèles Cogito (y compris la série v1) pour un coût total inférieur à 3,5 millions de dollars, soit une fraction du budget à neuf chiffres déclaré pour certains modèles de pointe.
Ce budget a couvert la génération de données à grande échelle, le renforcement synthétique, l'infrastructure et plus de 1 000 expériences de formation.
Arora attribue cette rentabilité à un principe fondamental : la création de modèles plus intelligents dépend d'une meilleure compréhension fondamentale (« a priori »), et non pas simplement de l'apport d'un plus grand nombre de données.
En apprenant aux modèles à éviter les chemins de raisonnement redondants ou trompeurs, Cogito v2 offre des performances robustes sans augmenter le temps ou le coût d'inférence, ce qui constitue un avantage essentiel pour les services basés sur des API ou le déploiement de périphériques de pointe, où la latence et les coûts sont des facteurs clés.
Perspectives d'avenir : la feuille de route de Deep Cogito
Cogito v2 représente une étape itérative, et non un produit final. Arora décrit l'approche de l'entreprise comme une « ascension » : exécuter des modèles, tirer des enseignements de leur raisonnement, distiller ces leçons et répéter le cycle. Chaque version du modèle s'appuie sur la précédente.
Deep Cogito reste engagé dans l'open source pour tous ses modèles, actuels et futurs. Son travail a déjà reçu le soutien d'investisseurs tels qu'Eric Vishria de Benchmark et Aditya Agarwal de South Park Commons.
Parmi ses partenaires en matière d'infrastructure, on trouve Hugging Face, Together AI, RunPod, Baseten, l'équipe Llama de Meta et Unsloth.
Pour les développeurs, les chercheurs et les entreprises, les modèles sont disponibles dès aujourd'hui pour une utilisation locale, une comparaison multimodale et un ajustement spécifique à un domaine.
Pour la communauté open source de l'IA, Cogito v2 offre bien plus qu'une référence en matière de benchmark. Il présente un nouveau paradigme pour la construction de l'intelligence : un paradigme qui ne se concentre pas sur le fait de réfléchir plus, mais sur le fait d'apprendre à mieux réfléchir.










 Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
 Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Interesting approach, but 'open-ish' sounds like a marketing gimmick. If the weights aren't fully open, how can the community truly verify their 'self-improving' claims? Feels like another startup trying to have its cake and eat it too. The intuition part is fascinating, though. 🤔
¿Modelos auto-mejorables? Parece prometedor, pero siempre me pregunto: ¿cómo verifican que la intuición emergente no genere sesgos peligrosos o alucinaciones más sofisticadas? 🤔 Sería bueno ver más transparencia en los datos de entrenamiento.













