
















 首頁
首頁Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。
儘管90億參數規模仍高於近期報導的數百萬參數微型模型,但Nvidia強調此乃對原始120億參數的重大優化。經重新設計的模型體積,可完美運行於單顆廣泛普及的Nvidia A10 GPU之上。
NVIDIA人工智慧模型後訓練總監Oleksii Kuchiaev在X平台回應提問時解釋:「我們將120億參數模型精簡至90億參數,使其完美適配主流部署GPU A10。此模型採用混合架構,能處理更大批次規模,運算速度較同等規模傳統變壓器模型提升六倍。」
為便於理解,當前多數頂尖大型語言模型參數規模皆達七十億以上。參數即定義模型行為的內部設定,參數數量通常代表更強大的能力,但也需耗費顯著更高的運算資源。
該模型支援多種語言,包含英語、德語、西班牙語、法語、義大利語及日語。擴展功能更涵蓋韓語、葡萄牙語、俄語與中文。其適用範圍廣泛,從執行指令到生成程式碼皆游刃有餘。
Nemotron-Nano-9B-V2及其預訓練資料集現已於Hugging Face平台及Nvidia自有模型目錄開放取得。
融合Transformer與Mamba架構的創新設計
該模型基於 Nemotron-H 架構開發,此系列混合型 Mamba-Transformer 模型構成了 Nvidia 最新 AI 產品線的技術基石。
主流大型語言模型通常僅依賴Transformer架構及其注意力機制,但隨著輸入序列長度增加,此類機制在記憶體與運算成本方面可能變得難以承受。
Nemotron-H 模型及其他採用 Mamba 架構的模型(由卡內基梅隆大學與普林斯頓大學研究人員開創)整合了選擇性狀態空間模型(SSMs)。這些 SSMs 透過維持內部狀態,能有效管理極長序列。
此類層級能隨序列長度線性擴展,使其得以處理遠超標準自關注機制的長上下文,且無需承擔同等運算開銷。
混合式Mamba-Transformer架構透過以線性時間狀態空間層取代多數注意力層,有效降低運算成本。此設計在處理長上下文任務時,可提升2至3倍吞吐量,同時維持相近的準確度。
採用此方法的不僅是Nvidia;其他AI研究實驗室,例如AI2,也發布了基於Mamba架構的模型。
透過簡易指令啟用或停用推理功能
Nemotron-Nano-9B-v2 作為統一的純文本模型,兼具對話互動與複雜推理能力,且完全從零開始訓練。
系統預設會在生成最終答案前產出詳細推理軌跡,使用者可透過 /think 或 /no_think 等簡易指令控制此行為。
該模型同時導入運行時「思考預算」管理機制,允許開發者設定模型進行內部推理時可使用的最大標記數上限,超過此限即必須輸出回應。
此機制旨在平衡準確性與回應延遲,對於客戶支援聊天機器人或自主代理程式等應用至關重要。
基準測試展現強勁表現
評估結果顯示,本模型在準確度方面與其他頂尖小型開放模型不相上下。啟用推理功能並使用NeMo-Skills測試套件時,Nemotron-Nano-9B-v2在AIME25、MATH500、GPQA及LiveCodeBench基準測試中分別取得72.1%、97.8%、64.0%與71.1%的成績。
在指令遵循與長上下文基準測試中同樣表現優異:IFEval達90.3%、RULER 128K測試達78.9%,並在BFCL v3與HLE基準測試中取得可量化的額外提升。
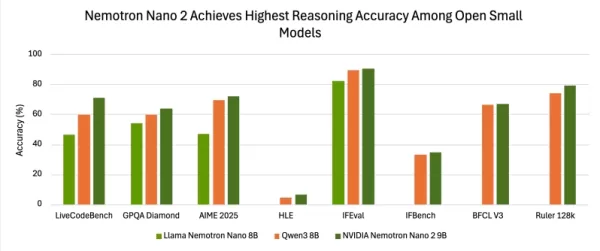
在多項評估中,Nano-9B-v2 的準確度始終高於常見對照模型 Qwen3-8B。
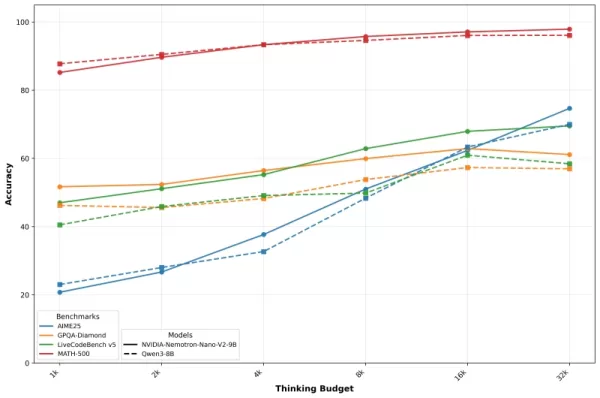
Nvidia透過精準度對預算曲線呈現這些結果,圖表清晰展示隨著推理代幣配額增加,效能如何逐步提升。該公司強調,精細的預算管控使開發者能在生產環境中同時優化品質與速度。
基於合成資料集訓練
Nano模型與更廣泛的Nemotron-H家族皆採用精心彙編的網路資料、專有來源及合成訓練資料混合訓練而成。
訓練語料庫涵蓋通用文本、程式碼、數學、科學文獻、法律與金融文件,以及專注於對齊問題的問答資料集。
Nvidia 確認採用其他大型模型生成的合成推理軌跡,以提升複雜基準任務的執行效能。
授權與商業用途
Nano-9B-v2模型依據Nvidia開放模型授權協議發佈,該協議最後更新於2025年6月。
此授權條款設計為寬鬆且企業友善。Nvidia明確聲明模型可直接商用,開發者可自由創建及分發衍生作品。
關鍵在於,Nvidia 不主張對模型產出內容擁有任何所有權,所有權利與責任均歸屬於使用該模型的開發者或組織。
對企業開發者而言,這意味著模型可立即投入生產環境,無需另行協商商業授權或支付基於使用量、營收或用戶數的費用。與其他供應商的分級開放授權不同,本協議不存在企業規模達標後觸發付費授權的條款。
然而協議仍包含企業必須遵守的幾項重要條款:
- 防護機制:使用者不得繞過或停用內建安全機制(稱為「防護欄」),除非針對其特定部署環境實施合適的等效替代方案。
- 再分發規範:任何模型或衍生作品的再分發行為,必須完整包含NVIDIA開放模型授權條款全文,並標註正確來源歸屬(「經NVIDIA公司依據NVIDIA開放模型授權條款授權」)。
- 合規要求:使用者須遵守所有適用貿易法規與限制,例如美國出口管制法律。
- 可信賴人工智慧條款:使用行為須符合Nvidia可信賴人工智慧指南,該指南涵蓋負責任部署原則與倫理考量。
- 訴訟條款:若使用者針對模型相關侵權行為,對其他方提起著作權或專利訴訟,本授權將自動終止。
這些條款著重確保法律合規與負責任使用,而非限制商業規模。企業無需為產品開發、服務變現或用戶擴展向英偉達申請額外許可或支付版稅,但必須確保部署實踐符合安全規範、提供正確署名並滿足所有合規義務。
市場定位
NVIDIA 推出 Nemotron-Nano-9B-v2,鎖定需在小型規模上平衡推理能力與部署效率的開發者。
其運算預算控制與推理切換功能,旨在賦予系統建構者更大彈性,以管理精準度與回應速度之間的權衡取捨。
該模型現已於Hugging Face及Nvidia模型目錄上架,彰顯其廣泛普及的意圖,旨在鼓勵實驗與整合應用。
Nvidia 推出 Nemotron-Nano-9B-v2,彰顯該公司持續聚焦於語言模型的效能與可控推理能力。
透過融合混合架構與先進壓縮及訓練技術,Nvidia 旨在為開發者提供兼具高精準度、降低運算成本與延遲的解決方案。
相關文章
 Nvidia 的 OpenClaw 變體或許能解決其最大的挑戰:安全性
Nvidia 執行長黃仁勳認為,每家公司都需要一套 OpenClaw 策略——而 Nvidia 已準備好提供這項解決方案。在週一的 GTC 主題演講中,黃仁勳宣布 NVIDIA 已打造出 NemoClaw,這是一個源自廣受歡迎的本地 AI 自主代理程式(OpenClaw)的企業級平台。這個開源平台本質上是整合了企業級安全與隱私功能的 OpenClaw。根據 Nvidia 的說法,目標是將 Open
五角大樓與英偉達、微軟和亞馬遜網路服務公司簽訂了協議,以便在機密網路中部署人工智慧技術。
在此前與谷歌、SpaceX和OpenAI達成協議之後,美國國防部於週五宣佈,它現已與Nvidia、微軟、亞馬遜網路服務和Reflection AI簽訂了合同,這些公司將會將其人工智慧技術和模型部署在保密網路上,用於“合法的操作用途”。宣告中還指出:“這些協議加速了將美國軍隊建設成為以人工智慧為核心作戰力量的程序,並將增強我們的戰士在所有戰爭領域保持決策優勢的能力。”這些協議的簽署,正值五角大樓試圖在與Anthropic就使用條款發生爭議後,多元化其人工智慧供應商的選擇。五角大樓希望無限制地使
Nvidia GTC 發表 NemoClaw、機器人奧拉夫,以及一兆美元的豪賭
正在載入播放器……執行長黃仁勳本週身穿招牌皮夾克登上 Nvidia GTC 大會的舞台,發表了一場長達兩小時半的主題演說。他在演說中預測,至 2027 年人工智慧晶片銷售額將達到 1 兆美元,並宣稱每家公司都需要一套「OpenClaw 策略」,最後則以一段語無倫次的 Olaf 機器人表演作為結尾,甚至不得不切斷其麥克風。 訊息不言而喻:Nvidia 希望成為一切的基石,從 AI 訓練到自動駕駛汽車
相關專題推薦
商業
Nvidia 的 OpenClaw 變體或許能解決其最大的挑戰:安全性
Nvidia 執行長黃仁勳認為,每家公司都需要一套 OpenClaw 策略——而 Nvidia 已準備好提供這項解決方案。在週一的 GTC 主題演講中,黃仁勳宣布 NVIDIA 已打造出 NemoClaw,這是一個源自廣受歡迎的本地 AI 自主代理程式(OpenClaw)的企業級平台。這個開源平台本質上是整合了企業級安全與隱私功能的 OpenClaw。根據 Nvidia 的說法,目標是將 Open
五角大樓與英偉達、微軟和亞馬遜網路服務公司簽訂了協議,以便在機密網路中部署人工智慧技術。
在此前與谷歌、SpaceX和OpenAI達成協議之後,美國國防部於週五宣佈,它現已與Nvidia、微軟、亞馬遜網路服務和Reflection AI簽訂了合同,這些公司將會將其人工智慧技術和模型部署在保密網路上,用於“合法的操作用途”。宣告中還指出:“這些協議加速了將美國軍隊建設成為以人工智慧為核心作戰力量的程序,並將增強我們的戰士在所有戰爭領域保持決策優勢的能力。”這些協議的簽署,正值五角大樓試圖在與Anthropic就使用條款發生爭議後,多元化其人工智慧供應商的選擇。五角大樓希望無限制地使
Nvidia GTC 發表 NemoClaw、機器人奧拉夫,以及一兆美元的豪賭
正在載入播放器……執行長黃仁勳本週身穿招牌皮夾克登上 Nvidia GTC 大會的舞台,發表了一場長達兩小時半的主題演說。他在演說中預測,至 2027 年人工智慧晶片銷售額將達到 1 兆美元,並宣稱每家公司都需要一套「OpenClaw 策略」,最後則以一段語無倫次的 Olaf 機器人表演作為結尾,甚至不得不切斷其麥克風。 訊息不言而喻:Nvidia 希望成為一切的基石,從 AI 訓練到自動駕駛汽車
相關專題推薦
商業
 頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
 10 個工具
10 個工具
 xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。
儘管90億參數規模仍高於近期報導的數百萬參數微型模型,但Nvidia強調此乃對原始120億參數的重大優化。經重新設計的模型體積,可完美運行於單顆廣泛普及的Nvidia A10 GPU之上。
NVIDIA人工智慧模型後訓練總監Oleksii Kuchiaev在X平台回應提問時解釋:「我們將120億參數模型精簡至90億參數,使其完美適配主流部署GPU A10。此模型採用混合架構,能處理更大批次規模,運算速度較同等規模傳統變壓器模型提升六倍。」
為便於理解,當前多數頂尖大型語言模型參數規模皆達七十億以上。參數即定義模型行為的內部設定,參數數量通常代表更強大的能力,但也需耗費顯著更高的運算資源。
該模型支援多種語言,包含英語、德語、西班牙語、法語、義大利語及日語。擴展功能更涵蓋韓語、葡萄牙語、俄語與中文。其適用範圍廣泛,從執行指令到生成程式碼皆游刃有餘。
Nemotron-Nano-9B-V2及其預訓練資料集現已於Hugging Face平台及Nvidia自有模型目錄開放取得。
融合Transformer與Mamba架構的創新設計
該模型基於 Nemotron-H 架構開發,此系列混合型 Mamba-Transformer 模型構成了 Nvidia 最新 AI 產品線的技術基石。
主流大型語言模型通常僅依賴Transformer架構及其注意力機制,但隨著輸入序列長度增加,此類機制在記憶體與運算成本方面可能變得難以承受。
Nemotron-H 模型及其他採用 Mamba 架構的模型(由卡內基梅隆大學與普林斯頓大學研究人員開創)整合了選擇性狀態空間模型(SSMs)。這些 SSMs 透過維持內部狀態,能有效管理極長序列。
此類層級能隨序列長度線性擴展,使其得以處理遠超標準自關注機制的長上下文,且無需承擔同等運算開銷。
混合式Mamba-Transformer架構透過以線性時間狀態空間層取代多數注意力層,有效降低運算成本。此設計在處理長上下文任務時,可提升2至3倍吞吐量,同時維持相近的準確度。
採用此方法的不僅是Nvidia;其他AI研究實驗室,例如AI2,也發布了基於Mamba架構的模型。
透過簡易指令啟用或停用推理功能
Nemotron-Nano-9B-v2 作為統一的純文本模型,兼具對話互動與複雜推理能力,且完全從零開始訓練。
系統預設會在生成最終答案前產出詳細推理軌跡,使用者可透過 /think 或 /no_think 等簡易指令控制此行為。
該模型同時導入運行時「思考預算」管理機制,允許開發者設定模型進行內部推理時可使用的最大標記數上限,超過此限即必須輸出回應。
此機制旨在平衡準確性與回應延遲,對於客戶支援聊天機器人或自主代理程式等應用至關重要。
基準測試展現強勁表現
評估結果顯示,本模型在準確度方面與其他頂尖小型開放模型不相上下。啟用推理功能並使用NeMo-Skills測試套件時,Nemotron-Nano-9B-v2在AIME25、MATH500、GPQA及LiveCodeBench基準測試中分別取得72.1%、97.8%、64.0%與71.1%的成績。
在指令遵循與長上下文基準測試中同樣表現優異:IFEval達90.3%、RULER 128K測試達78.9%,並在BFCL v3與HLE基準測試中取得可量化的額外提升。
在多項評估中,Nano-9B-v2 的準確度始終高於常見對照模型 Qwen3-8B。
Nvidia透過精準度對預算曲線呈現這些結果,圖表清晰展示隨著推理代幣配額增加,效能如何逐步提升。該公司強調,精細的預算管控使開發者能在生產環境中同時優化品質與速度。
基於合成資料集訓練
Nano模型與更廣泛的Nemotron-H家族皆採用精心彙編的網路資料、專有來源及合成訓練資料混合訓練而成。
訓練語料庫涵蓋通用文本、程式碼、數學、科學文獻、法律與金融文件,以及專注於對齊問題的問答資料集。
Nvidia 確認採用其他大型模型生成的合成推理軌跡,以提升複雜基準任務的執行效能。
授權與商業用途
Nano-9B-v2模型依據Nvidia開放模型授權協議發佈,該協議最後更新於2025年6月。
此授權條款設計為寬鬆且企業友善。Nvidia明確聲明模型可直接商用,開發者可自由創建及分發衍生作品。
關鍵在於,Nvidia 不主張對模型產出內容擁有任何所有權,所有權利與責任均歸屬於使用該模型的開發者或組織。
對企業開發者而言,這意味著模型可立即投入生產環境,無需另行協商商業授權或支付基於使用量、營收或用戶數的費用。與其他供應商的分級開放授權不同,本協議不存在企業規模達標後觸發付費授權的條款。
然而協議仍包含企業必須遵守的幾項重要條款:
- 防護機制:使用者不得繞過或停用內建安全機制(稱為「防護欄」),除非針對其特定部署環境實施合適的等效替代方案。
- 再分發規範:任何模型或衍生作品的再分發行為,必須完整包含NVIDIA開放模型授權條款全文,並標註正確來源歸屬(「經NVIDIA公司依據NVIDIA開放模型授權條款授權」)。
- 合規要求:使用者須遵守所有適用貿易法規與限制,例如美國出口管制法律。
- 可信賴人工智慧條款:使用行為須符合Nvidia可信賴人工智慧指南,該指南涵蓋負責任部署原則與倫理考量。
- 訴訟條款:若使用者針對模型相關侵權行為,對其他方提起著作權或專利訴訟,本授權將自動終止。
這些條款著重確保法律合規與負責任使用,而非限制商業規模。企業無需為產品開發、服務變現或用戶擴展向英偉達申請額外許可或支付版稅,但必須確保部署實踐符合安全規範、提供正確署名並滿足所有合規義務。
市場定位
NVIDIA 推出 Nemotron-Nano-9B-v2,鎖定需在小型規模上平衡推理能力與部署效率的開發者。
其運算預算控制與推理切換功能,旨在賦予系統建構者更大彈性,以管理精準度與回應速度之間的權衡取捨。
該模型現已於Hugging Face及Nvidia模型目錄上架,彰顯其廣泛普及的意圖,旨在鼓勵實驗與整合應用。
Nvidia 推出 Nemotron-Nano-9B-v2,彰顯該公司持續聚焦於語言模型的效能與可控推理能力。
透過融合混合架構與先進壓縮及訓練技術,Nvidia 旨在為開發者提供兼具高精準度、降低運算成本與延遲的解決方案。










 Nvidia 的 OpenClaw 變體或許能解決其最大的挑戰:安全性
Nvidia 執行長黃仁勳認為,每家公司都需要一套 OpenClaw 策略——而 Nvidia 已準備好提供這項解決方案。在週一的 GTC 主題演講中,黃仁勳宣布 NVIDIA 已打造出 NemoClaw,這是一個源自廣受歡迎的本地 AI 自主代理程式(OpenClaw)的企業級平台。這個開源平台本質上是整合了企業級安全與隱私功能的 OpenClaw。根據 Nvidia 的說法,目標是將 Open
Nvidia 的 OpenClaw 變體或許能解決其最大的挑戰:安全性
Nvidia 執行長黃仁勳認為,每家公司都需要一套 OpenClaw 策略——而 Nvidia 已準備好提供這項解決方案。在週一的 GTC 主題演講中,黃仁勳宣布 NVIDIA 已打造出 NemoClaw,這是一個源自廣受歡迎的本地 AI 自主代理程式(OpenClaw)的企業級平台。這個開源平台本質上是整合了企業級安全與隱私功能的 OpenClaw。根據 Nvidia 的說法,目標是將 Open
 五角大樓與英偉達、微軟和亞馬遜網路服務公司簽訂了協議,以便在機密網路中部署人工智慧技術。
在此前與谷歌、SpaceX和OpenAI達成協議之後,美國國防部於週五宣佈,它現已與Nvidia、微軟、亞馬遜網路服務和Reflection AI簽訂了合同,這些公司將會將其人工智慧技術和模型部署在保密網路上,用於“合法的操作用途”。宣告中還指出:“這些協議加速了將美國軍隊建設成為以人工智慧為核心作戰力量的程序,並將增強我們的戰士在所有戰爭領域保持決策優勢的能力。”這些協議的簽署,正值五角大樓試圖在與Anthropic就使用條款發生爭議後,多元化其人工智慧供應商的選擇。五角大樓希望無限制地使
五角大樓與英偉達、微軟和亞馬遜網路服務公司簽訂了協議,以便在機密網路中部署人工智慧技術。
在此前與谷歌、SpaceX和OpenAI達成協議之後,美國國防部於週五宣佈,它現已與Nvidia、微軟、亞馬遜網路服務和Reflection AI簽訂了合同,這些公司將會將其人工智慧技術和模型部署在保密網路上,用於“合法的操作用途”。宣告中還指出:“這些協議加速了將美國軍隊建設成為以人工智慧為核心作戰力量的程序,並將增強我們的戰士在所有戰爭領域保持決策優勢的能力。”這些協議的簽署,正值五角大樓試圖在與Anthropic就使用條款發生爭議後,多元化其人工智慧供應商的選擇。五角大樓希望無限制地使
 Nvidia GTC 發表 NemoClaw、機器人奧拉夫,以及一兆美元的豪賭
正在載入播放器……執行長黃仁勳本週身穿招牌皮夾克登上 Nvidia GTC 大會的舞台,發表了一場長達兩小時半的主題演說。他在演說中預測,至 2027 年人工智慧晶片銷售額將達到 1 兆美元,並宣稱每家公司都需要一套「OpenClaw 策略」,最後則以一段語無倫次的 Olaf 機器人表演作為結尾,甚至不得不切斷其麥克風。 訊息不言而喻:Nvidia 希望成為一切的基石,從 AI 訓練到自動駕駛汽車
Nvidia GTC 發表 NemoClaw、機器人奧拉夫,以及一兆美元的豪賭
正在載入播放器……執行長黃仁勳本週身穿招牌皮夾克登上 Nvidia GTC 大會的舞台,發表了一場長達兩小時半的主題演說。他在演說中預測,至 2027 年人工智慧晶片銷售額將達到 1 兆美元,並宣稱每家公司都需要一套「OpenClaw 策略」,最後則以一段語無倫次的 Olaf 機器人表演作為結尾,甚至不得不切斷其麥克風。 訊息不言而喻:Nvidia 希望成為一切的基石,從 AI 訓練到自動駕駛汽車

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













