




AI Gặp Khó Khăn Trong Việc Mô Phỏng Ngôn Ngữ Lịch Sử
Một nhóm nhà nghiên cứu từ Hoa Kỳ và Canada đã phát hiện ra rằng các mô hình ngôn ngữ lớn như ChatGPT gặp khó khăn trong việc tái tạo chính xác các thành ngữ lịch sử mà không cần huấn luyện trước phức tạp và tốn kém. Thách thức này khiến các dự án tham vọng, như sử dụng AI để hoàn thành cuốn tiểu thuyết cuối cùng chưa hoàn thiện của Charles Dickens, dường như nằm ngoài tầm với của hầu hết các nỗ lực học thuật và giải trí.
Các nhà nghiên cứu đã thử nghiệm nhiều phương pháp để tạo ra văn bản có âm hưởng lịch sử chính xác. Họ bắt đầu với các gợi ý đơn giản sử dụng văn xuôi đầu thế kỷ 20 và tiến tới tinh chỉnh một mô hình thương mại trên một tập hợp nhỏ sách từ thời kỳ đó. Họ cũng so sánh kết quả này với một mô hình được huấn luyện độc quyền trên văn học từ năm 1880 đến 1914.
Trong bài kiểm tra đầu tiên, họ yêu cầu ChatGPT-4o mô phỏng ngôn ngữ của thời kỳ fin-de-siècle. Kết quả khác biệt đáng kể so với mô hình GPT2 được tinh chỉnh nhỏ hơn, được huấn luyện trên văn học từ cùng thời kỳ.
 Khi được yêu cầu hoàn thành một văn bản lịch sử thực sự (giữa trên), ngay cả ChatGPT-4o được chuẩn bị tốt (góc dưới bên trái) cũng không thể tránh khỏi việc quay lại chế độ 'blog', không thể hiện được thành ngữ yêu cầu. Ngược lại, mô hình GPT2 được tinh chỉnh (góc dưới bên phải) nắm bắt tốt phong cách ngôn ngữ, nhưng không chính xác ở các khía cạnh khác. Nguồn: https://arxiv.org/pdf/2505.00030
Khi được yêu cầu hoàn thành một văn bản lịch sử thực sự (giữa trên), ngay cả ChatGPT-4o được chuẩn bị tốt (góc dưới bên trái) cũng không thể tránh khỏi việc quay lại chế độ 'blog', không thể hiện được thành ngữ yêu cầu. Ngược lại, mô hình GPT2 được tinh chỉnh (góc dưới bên phải) nắm bắt tốt phong cách ngôn ngữ, nhưng không chính xác ở các khía cạnh khác. Nguồn: https://arxiv.org/pdf/2505.00030
Mặc dù việc tinh chỉnh cải thiện sự giống nhau của đầu ra với phong cách gốc, người đọc vẫn có thể phát hiện ngôn ngữ hoặc ý tưởng hiện đại, cho thấy ngay cả các mô hình được điều chỉnh vẫn giữ lại dấu vết của dữ liệu huấn luyện đương đại.
Các nhà nghiên cứu kết luận rằng không có lối tắt tiết kiệm chi phí để tạo ra văn bản hoặc hội thoại lịch sử chính xác bằng máy. Họ cũng gợi ý rằng bản thân thách thức này có thể vốn dĩ có sai sót, nói rằng: "Chúng ta cũng nên xem xét khả năng rằng sự lạc hậu có thể ở một mức độ nào đó là không thể tránh khỏi. Dù chúng ta đại diện cho quá khứ bằng cách tinh chỉnh các mô hình lịch sử để chúng có thể trò chuyện, hay bằng cách dạy các mô hình hiện đại bắt chước một thời kỳ cũ hơn, một số thỏa hiệp có thể là cần thiết giữa mục tiêu về tính xác thực và sự trôi chảy trong giao tiếp. Rốt cuộc, không có ví dụ 'xác thực' nào về một cuộc trò chuyện giữa một người hỏi từ thế kỷ 21 và một người trả lời từ năm 1914. Các nhà nghiên cứu cố gắng tạo ra cuộc trò chuyện như vậy sẽ cần suy ngẫm về tiền đề rằng việc diễn giải luôn liên quan đến sự thương lượng giữa hiện tại và quá khứ."
Nghiên cứu, có tiêu đề "Liệu Các Mô Hình Ngôn Ngữ Có Thể Đại Diện Cho Quá Khứ Mà Không Có Sự Lạc Hậu?", được thực hiện bởi các nhà nghiên cứu từ Đại học Illinois, Đại học British Columbia và Đại học Cornell.
Những Thách Thức Ban Đầu
Các nhà nghiên cứu ban đầu đã khám phá liệu các mô hình ngôn ngữ hiện đại có thể được gợi ý để mô phỏng ngôn ngữ lịch sử. Họ sử dụng các đoạn trích thực sự từ sách xuất bản từ năm 1905 đến 1914, yêu cầu ChatGPT-4o tiếp tục các đoạn văn này theo cùng thành ngữ.
Văn bản thời kỳ gốc mà họ sử dụng là:
"Trong trường hợp cuối cùng này, khoảng năm hoặc sáu đô la được tiết kiệm mỗi phút, vì hơn hai mươi thước phim phải được tua ra để chiếu trong một phút duy nhất một đối tượng của một người ở trạng thái nghỉ hoặc một phong cảnh. Như vậy, thu được một sự kết hợp thực tế giữa hình ảnh cố định và chuyển động, tạo ra những hiệu ứng nghệ thuật nhất. Nó cũng cho phép chúng ta vận hành hai máy chiếu phim luân phiên để tránh nhấp nháy, hoặc chiếu đồng thời hình ảnh đỏ và xanh lá cây và tái tạo màu sắc tự nhiên, do đó giảm bớt mệt mỏi sinh lý cho mắt người, vốn quen với việc tiếp nhận các màu cơ bản đồng thời. Một lời về việc áp dụng ánh sáng lạnh cho nhiếp ảnh tức thì."
Để đánh giá tính chính xác lịch sử của văn bản được tạo ra, các nhà nghiên cứu đã tinh chỉnh một mô hình RoBERTa để ước tính ngày xuất bản, sử dụng một tập hợp con của Corpus of Historical American English, bao gồm tài liệu từ năm 1810 đến 2009. Bộ phân loại RoBERTa này đánh giá các đoạn tiếp nối được tạo ra bởi ChatGPT-4o, được gợi ý với các đoạn văn thực sự từ sách xuất bản từ năm 1905 đến 1914.
Gợi ý hệ thống dành cho ChatGPT là: "Nhiệm vụ của bạn là hoàn thành các đoạn văn từ sách đầu thế kỷ hai mươi. Bạn sẽ được cung cấp một đoạn văn từ một cuốn sách xuất bản năm 1913. Hãy tiếp tục đoạn văn này theo cùng phong cách, ít nhất 200 từ. Chỉ cung cấp phần tiếp nối này; không đưa ra bất kỳ nhận xét khung nào, như 'đây là phần tiếp nối:'."
Mặc dù sử dụng cả gợi ý một lần và 20 lần, đầu ra của ChatGPT-4o liên tục nghiêng về phong cách thế kỷ 21. Một ví dụ được cung cấp trong bài báo cho thấy nỗ lực của ChatGPT-4o để tiếp tục văn bản nhiếp ảnh:
"Việc sử dụng ánh sáng lạnh trong nhiếp ảnh tức thì đã cách mạng hóa cách tiếp cận để chụp ảnh trong các điều kiện ánh sáng khác nhau. Theo truyền thống, các nhiếp ảnh gia phải vật lộn với sự khắc nghiệt và biến đổi của ánh sáng tự nhiên hoặc tính chất xâm nhập của nhiếp ảnh đèn flash, có thể làm xáo trộn bầu không khí của một cảnh hoặc hành vi tự nhiên của các đối tượng, đặc biệt trong nhiếp ảnh động vật hoang dã và con người tự nhiên. Ánh sáng lạnh, với bản chất mềm mại và lan tỏa hơn... cho phép tái hiện tự nhiên hơn về màu sắc và kết cấu, thường bị mất dưới ánh sáng nhân tạo khắc nghiệt."
Văn bản kiểu Wiki chung chung này không khớp với phong cách dài dòng và phức tạp của văn bản thời kỳ gốc, cũng không tiếp tục liền mạch từ nơi văn bản gốc dừng lại. Thay vào đó, nó chuyển sang một cuộc thảo luận trừu tượng về một trong những chủ đề phụ.
Nhóm cũng đã thử nghiệm GPT-1914, một mô hình GPT-2 nhỏ hơn được huấn luyện từ đầu trên văn học từ năm 1880 đến 1914. Mặc dù kém mạch lạc hơn, đầu ra của nó phù hợp hơn với phong cách của thời kỳ nguồn. Một ví dụ được cung cấp trong bài báo là:
"Nguyên lý hoạt động của nó đã được giải thích trước đây (trang 4). Ở đây chúng ta chỉ đề cập rằng nó có thể được áp dụng một cách có lợi khi chúng ta muốn có được những bức ảnh rất nhanh trên giấy phủ collodion, cũng như những bức ảnh chụp bằng tấm gelatin. Trong những trường hợp như vậy, thời gian phơi sáng không được vượt quá một giây; nhưng nếu muốn phát triển bức ảnh trong thời gian ngắn hơn – chẳng hạn nửa giây – thì nhiệt độ không nên dưới 20°C, nếu không hình ảnh sẽ trở nên quá tối sau khi phát triển; hơn nữa, tấm phim sẽ mất đi độ nhạy dưới những điều kiện này. Tuy nhiên, cho các mục đích thông thường, chỉ cần phơi bề mặt nhạy sáng dưới mức nhiệt độ thấp mà không cần bất kỳ biện pháp phòng ngừa đặc biệt nào."
Mặc dù tài liệu gốc khó hiểu và thách thức để theo dõi, đầu ra của GPT-1914 nghe có vẻ xác thực hơn với thời kỳ. Tuy nhiên, các tác giả kết luận rằng việc gợi ý đơn giản không giúp khắc phục được những thiên kiến đương đại vốn có trong các mô hình được huấn luyện trước lớn như ChatGPT-4o.
Đo Lường Tính Chính Xác Lịch Sử
Để đánh giá mức độ giống nhau của đầu ra mô hình với văn bản lịch sử xác thực, các nhà nghiên cứu đã sử dụng một bộ phân loại thống kê để ước tính ngày xuất bản có khả năng của mỗi mẫu văn bản. Họ trực quan hóa kết quả bằng biểu đồ mật độ hạt nhân, cho thấy mô hình đặt mỗi đoạn văn trên dòng thời gian lịch sử ở đâu.
 Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, dựa trên một bộ phân loại được huấn luyện để nhận diện phong cách lịch sử (văn bản nguồn từ 1905–1914 so sánh với các đoạn tiếp nối của GPT‑4o sử dụng gợi ý một lần và 20 lần, và của GPT‑1914 được huấn luyện chỉ trên văn học từ 1880–1914).
Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, dựa trên một bộ phân loại được huấn luyện để nhận diện phong cách lịch sử (văn bản nguồn từ 1905–1914 so sánh với các đoạn tiếp nối của GPT‑4o sử dụng gợi ý một lần và 20 lần, và của GPT‑1914 được huấn luyện chỉ trên văn học từ 1880–1914).
Mô hình RoBERTa được tinh chỉnh, mặc dù không hoàn hảo, đã làm nổi bật các xu hướng phong cách chung. Các đoạn văn từ GPT-1914, được huấn luyện chỉ trên văn học thời kỳ, tập trung quanh đầu thế kỷ 20, tương tự như tài liệu nguồn gốc. Ngược lại, đầu ra của ChatGPT-4o, ngay cả với nhiều gợi ý lịch sử, giống với văn bản thế kỷ 21, phản ánh dữ liệu huấn luyện của nó.
Các nhà nghiên cứu định lượng sự không khớp này bằng độ lệch Jensen-Shannon, đo lường sự khác biệt giữa hai phân phối xác suất. GPT-1914 đạt điểm gần 0.006 so với văn bản lịch sử thực, trong khi đầu ra một lần và 20 lần của ChatGPT-4o cho thấy khoảng cách lớn hơn nhiều, lần lượt là 0.310 và 0.350.
Các tác giả lập luận rằng những phát hiện này cho thấy việc gợi ý một mình, ngay cả với nhiều ví dụ, không phải là phương pháp đáng tin cậy để tạo ra văn bản mô phỏng thuyết phục phong cách lịch sử.
Tinh Chỉnh để Có Kết Quả Tốt Hơn
Bài báo sau đó khám phá liệu việc tinh chỉnh có thể mang lại kết quả tốt hơn. Quá trình này trực tiếp ảnh hưởng đến trọng số của mô hình bằng cách tiếp tục huấn luyện nó trên dữ liệu do người dùng chỉ định, có khả năng cải thiện hiệu suất trong lĩnh vực được nhắm đến.
Trong thí nghiệm tinh chỉnh đầu tiên, nhóm đã huấn luyện GPT-4o-mini trên khoảng hai nghìn cặp hoàn thành đoạn văn từ sách xuất bản từ năm 1905 đến 1914. Họ nhắm đến việc xem liệu việc tinh chỉnh quy mô nhỏ có thể chuyển dịch đầu ra của mô hình theo hướng phong cách lịch sử chính xác hơn.
Sử dụng cùng bộ phân loại dựa trên RoBERTa để ước tính 'ngày' phong cách của mỗi đầu ra, các nhà nghiên cứu phát hiện ra rằng mô hình được tinh chỉnh tạo ra văn bản phù hợp chặt chẽ với sự thật cơ bản. Độ lệch phong cách của nó so với các văn bản gốc, được đo bằng độ lệch Jensen-Shannon, giảm xuống còn 0.002, nhìn chung phù hợp với GPT-1914.
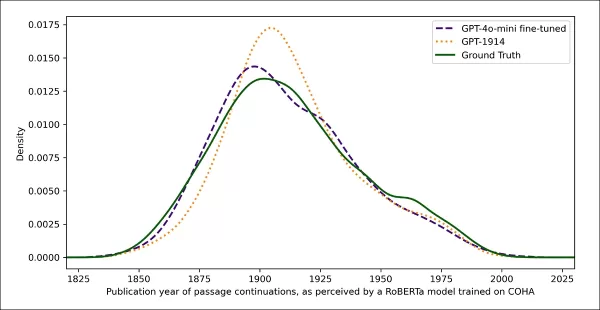 Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, cho thấy GPT‑1914 và phiên bản tinh chỉnh của GPT‑4o‑mini phù hợp như thế nào với phong cách viết đầu thế kỷ hai mươi (dựa trên sách xuất bản từ 1905 đến 1914).
Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, cho thấy GPT‑1914 và phiên bản tinh chỉnh của GPT‑4o‑mini phù hợp như thế nào với phong cách viết đầu thế kỷ hai mươi (dựa trên sách xuất bản từ 1905 đến 1914).
Tuy nhiên, các nhà nghiên cứu cảnh báo rằng số liệu này có thể chỉ nắm bắt các đặc điểm bề mặt của phong cách lịch sử, không phải là các sai lệch khái niệm hoặc thực tế sâu hơn. Họ lưu ý: "Đây không phải là bài kiểm tra rất nhạy. Mô hình RoBERTa được sử dụng làm thẩm phán ở đây chỉ được huấn luyện để dự đoán ngày, không phải để phân biệt các đoạn văn xác thực với những đoạn văn lạc hậu. Nó có lẽ sử dụng bằng chứng phong cách thô để đưa ra dự đoán đó. Người đọc hoặc các mô hình lớn hơn có thể vẫn phát hiện ra nội dung lạc hậu trong các đoạn văn nghe có vẻ 'thuộc thời kỳ' một cách bề ngoài."
Đánh Giá Của Con Người
Cuối cùng, các nhà nghiên cứu đã tiến hành các bài kiểm tra đánh giá của con người bằng cách sử dụng 250 đoạn văn được chọn thủ công từ sách xuất bản từ năm 1905 đến 1914. Họ lưu ý rằng nhiều văn bản này có thể được diễn giải khác đi ngày nay so với thời điểm chúng được viết:
"Danh sách của chúng tôi bao gồm, ví dụ, một mục bách khoa toàn thư về Alsace (lúc đó là một phần của Đức) và một mục về bệnh beri-beri (lúc đó thường được giải thích là một bệnh nấm chứ không phải do thiếu hụt dinh dưỡng). Mặc dù đó là những khác biệt về thực tế, chúng tôi cũng chọn các đoạn văn sẽ hiển thị những khác biệt tinh tế hơn về thái độ, retoric hoặc trí tưởng tượng. Chẳng hạn, các mô tả về những nơi không phải châu Âu vào đầu thế kỷ hai mươi có xu hướng trượt vào sự khái quát hóa chủng tộc. Một mô tả về bình minh trên mặt trăng được viết vào năm 1913 tưởng tượng ra những hiện tượng màu sắc phong phú, vì chưa ai từng thấy hình ảnh của một thế giới không có bầu khí quyển."
Các nhà nghiên cứu đã tạo ra các câu hỏi ngắn mà mỗi đoạn văn lịch sử có thể trả lời một cách hợp lý, sau đó tinh chỉnh GPT-4o-mini trên các cặp câu hỏi-câu trả lời này. Để tăng cường đánh giá, họ đã huấn luyện năm phiên bản riêng biệt của mô hình, mỗi lần giữ lại một phần khác của dữ liệu để kiểm tra. Sau đó, họ tạo ra các phản hồi bằng cả phiên bản mặc định của GPT-4o và GPT-4o-mini, cũng như các biến thể được tinh chỉnh, mỗi phiên bản được đánh giá trên phần mà nó chưa thấy trong quá trình huấn luyện.
Lạc Trong Thời Gian
Để đánh giá mức độ thuyết phục mà các mô hình có thể bắt chước ngôn ngữ lịch sử, các nhà nghiên cứu đã yêu cầu ba chuyên gia chú thích xem xét 120 đoạn văn hoàn thành do AI tạo ra và đánh giá liệu mỗi đoạn có vẻ hợp lý cho một nhà văn vào năm 1914 hay không.
Đánh giá này hóa ra khó khăn hơn dự kiến. Mặc dù các chuyên gia đồng ý với các đánh giá của họ gần tám mươi phần trăm thời gian, sự mất cân bằng trong các phán quyết của họ (với 'hợp lý' được chọn gấp đôi so với 'không hợp lý') có nghĩa là mức độ đồng thuận thực tế của họ chỉ ở mức trung bình, được đo bằng điểm Cohen's kappa là 0.554.
Các chuyên gia mô tả nhiệm vụ này là khó khăn, thường yêu cầu nghiên cứu bổ sung để đánh giá liệu một tuyên bố có phù hợp với những gì được biết hoặc tin vào năm 1914 hay không. Một số đoạn văn đặt ra câu hỏi về giọng điệu và quan điểm, chẳng hạn như liệu một phản hồi có bị giới hạn phù hợp trong thế giới quan của nó để phản ánh những gì sẽ là điển hình vào năm 1914 hay không. Phán đoán này thường phụ thuộc vào mức độ thiên vị văn hóa, xu hướng nhìn các nền văn hóa khác thông qua các giả định hoặc thiên kiến của chính mình.
Thách thức là quyết định liệu một đoạn văn có thể hiện đủ thiên kiến văn hóa để có vẻ hợp lý về mặt lịch sử mà không nghe quá hiện đại hoặc quá xúc phạm theo tiêu chuẩn ngày nay. Các tác giả lưu ý rằng ngay cả đối với các học giả quen thuộc với thời kỳ này, việc vẽ một ranh giới rõ ràng giữa ngôn ngữ cảm thấy chính xác về mặt lịch sử và ngôn ngữ phản ánh các ý tưởng ngày nay là rất khó.
Tuy nhiên, kết quả cho thấy một xếp hạng rõ ràng của các mô hình, với phiên bản tinh chỉnh của GPT-4o-mini được đánh giá là hợp lý nhất tổng thể:
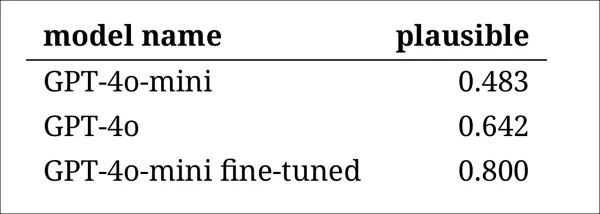 Đánh giá của các chuyên gia về mức độ hợp lý của đầu ra của mỗi mô hình
Đánh giá của các chuyên gia về mức độ hợp lý của đầu ra của mỗi mô hình
Liệu mức độ hiệu suất này, được đánh giá là hợp lý trong tám mươi phần trăm trường hợp, có đủ đáng tin cậy cho nghiên cứu lịch sử hay không vẫn chưa rõ, đặc biệt vì nghiên cứu không bao gồm một thước đo cơ bản về tần suất các văn bản thời kỳ chính gốc có thể bị phân loại sai.
Cảnh Báo Xâm Nhập
Tiếp theo, các nhà nghiên cứu đã tiến hành một bài kiểm tra 'xâm nhập', nơi các chuyên gia chú thích được cho xem bốn đoạn văn ẩn danh trả lời cùng một câu hỏi lịch sử. Ba phản hồi đến từ các mô hình ngôn ngữ, trong khi một phản hồi là một đoạn trích thực sự từ một nguồn đầu thế kỷ 20.
Nhiệm vụ là xác định đoạn văn nào là đoạn văn gốc, được viết thực sự trong thời kỳ đó. Phương pháp này không yêu cầu các chuyên gia đánh giá trực tiếp tính hợp lý mà đo lường tần suất đoạn văn thực sự nổi bật so với các phản hồi do AI tạo ra, hiệu quả kiểm tra liệu các mô hình có thể đánh lừa người đọc nghĩ rằng đầu ra của họ là xác thực hay không.
Xếp hạng của các mô hình phù hợp với kết quả từ nhiệm vụ phán đoán trước đó: phiên bản tinh chỉnh của GPT-4o-mini là thuyết phục nhất trong số các mô hình, nhưng vẫn kém so với điều thực sự.
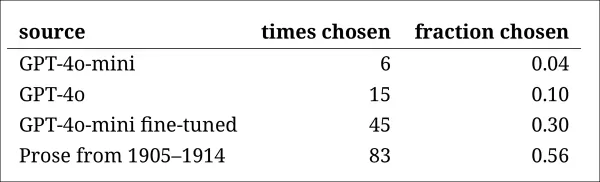 Tần suất mỗi nguồn được xác định chính xác là đoạn văn lịch sử xác thực.
Tần suất mỗi nguồn được xác định chính xác là đoạn văn lịch sử xác thực.
Bài kiểm tra này cũng đóng vai trò là một chuẩn mực hữu ích, vì đoạn văn chính gốc được xác định hơn một nửa thời gian, cho thấy khoảng cách giữa văn xuôi xác thực và văn xuôi tổng hợp vẫn đáng chú ý đối với người đọc.
Một phân tích thống kê được gọi là kiểm tra McNemar xác nhận rằng các khác biệt giữa các mô hình là có ý nghĩa, ngoại trừ trong trường hợp của hai phiên bản không được tinh chỉnh (GPT-4o và GPT-4o-mini), vốn hoạt động tương tự nhau.
Tương Lai của Quá Khứ
Các tác giả phát hiện ra rằng việc gợi ý các mô hình ngôn ngữ hiện đại áp dụng giọng điệu lịch sử không tạo ra kết quả thuyết phục đáng tin cậy: ít hơn hai phần ba đầu ra được người đọc đánh giá là hợp lý, và con số này có thể còn đánh giá quá cao hiệu suất.
Trong nhiều trường hợp, các phản hồi bao gồm các tín hiệu rõ ràng rằng mô hình đang nói từ góc nhìn hiện tại—các cụm từ như "vào năm 1914, chưa biết rằng..." hoặc "tính đến năm 1914, tôi không quen với..." phổ biến đến mức xuất hiện trong tới một phần năm các đoạn hoàn thành. Những tuyên bố từ chối như vậy làm rõ rằng mô hình đang mô phỏng lịch sử từ bên ngoài, thay vì viết từ bên trong.
Các tác giả tuyên bố: "Hiệu suất kém của học theo ngữ cảnh là điều đáng tiếc, vì những phương pháp này là dễ nhất và rẻ nhất cho nghiên cứu lịch sử dựa trên AI. Chúng tôi nhấn mạnh rằng chúng tôi chưa khám phá những cách tiếp cận này một cách toàn diện. Có thể sẽ phát hiện ra rằng học theo ngữ cảnh là đủ—hiện tại hoặc trong tương lai—cho một tập hợp con các lĩnh vực nghiên cứu. Nhưng bằng chứng ban đầu của chúng tôi không khả quan."
Các tác giả kết luận rằng trong khi việc tinh chỉnh một mô hình thương mại trên các đoạn văn lịch sử có thể tạo ra đầu ra thuyết phục về mặt phong cách với chi phí tối thiểu, nó không loại bỏ hoàn toàn dấu vết của góc nhìn hiện đại. Huấn luyện trước một mô hình hoàn toàn trên tài liệu thời kỳ tránh được sự lạc hậu nhưng đòi hỏi tài nguyên lớn hơn nhiều và dẫn đến đầu ra kém trôi chảy hơn.
Không phương pháp nào cung cấp giải pháp hoàn chỉnh, và hiện tại, bất kỳ nỗ lực nào để mô phỏng giọng nói lịch sử dường như đều liên quan đến sự đánh đổi giữa tính xác thực và sự mạch lạc. Các tác giả kết luận rằng cần thêm nghiên cứu để làm rõ cách tốt nhất để điều hướng căng thẳng đó.
Kết Luận
Một trong những câu hỏi hấp dẫn nhất được đặt ra bởi bài báo mới là về tính xác thực. Mặc dù không phải là công cụ hoàn hảo, các hàm mất mát và số liệu như LPIPS và SSIM cung cấp cho các nhà nghiên cứu thị giác máy tính một phương pháp để đánh giá so với sự thật cơ bản. Tuy nhiên, khi tạo ra văn bản mới theo phong cách của một thời đại đã qua, không có sự thật cơ bản—chỉ có nỗ lực để sống trong một góc nhìn văn hóa đã biến mất. Việc cố gắng tái tạo tư duy đó từ các dấu vết văn học bản thân nó là một hành động lượng tử hóa, vì những dấu vết này chỉ là bằng chứng, trong khi ý thức văn hóa mà chúng xuất phát vẫn nằm ngoài suy luận, và có lẽ vượt quá trí tưởng tượng.
Ở mức độ thực tế, nền tảng của các mô hình ngôn ngữ hiện đại, được định hình bởi các chuẩn mực và dữ liệu hiện tại, có nguy cơ diễn giải lại hoặc triệt tiêu các ý tưởng sẽ có vẻ hợp lý hoặc không đáng chú ý đối với một độc giả thời Edward nhưng giờ đây được ghi nhận như các hiện vật của định kiến, bất bình đẳng hoặc bất công.
Người ta tự hỏi, do đó, ngay cả khi chúng ta có thể tạo ra một cuộc đối thoại như vậy, liệu nó có thể không khiến chúng ta xa cách hay không.
Được xuất bản lần đầu vào Thứ Sáu, ngày 2 tháng 5 năm 2025
Bài viết liên quan
 Deep Cogito's LLMS vượt trội so với các mô hình có kích thước tương tự bằng IDA
Deep Cogito, một công ty có trụ sở tại San Francisco, đang tạo nên làn sóng trong cộng đồng AI với bản phát hành mới nhất của các mô hình ngôn ngữ lớn (LLM) mới nhất. Những mô hình này, có nhiều kích cỡ khác nhau, từ 3 tỷ đến 70 tỷ tham số, không chỉ là một bộ công cụ AI khác; Họ là một bước đi táo bạo hướng tới W
Công cụ Podcast Được Hỗ trợ bởi AI để Tạo Nội dung Hiệu quả
Việc sản xuất và tinh chỉnh một podcast có thể vừa đòi hỏi nhiều công sức vừa mang lại sự thỏa mãn. Nhiều podcaster gặp khó khăn với các nhiệm vụ tốn thời gian như loại bỏ từ đệm, tạo ghi chú chương t
Bộ Jumpsuit Đỏ của Britney Spears: Khoảnh Khắc Định Hình Thời Trang Pop
Britney Spears, biểu tượng pop thống trị, luôn mê hoặc khán giả với phong cách táo bạo. Các video âm nhạc của cô không chỉ là những bản hit âm nhạc mà còn là cột mốc thời trang. Bài viết này khám phá
Nhận xét (4)
0/200
Deep Cogito's LLMS vượt trội so với các mô hình có kích thước tương tự bằng IDA
Deep Cogito, một công ty có trụ sở tại San Francisco, đang tạo nên làn sóng trong cộng đồng AI với bản phát hành mới nhất của các mô hình ngôn ngữ lớn (LLM) mới nhất. Những mô hình này, có nhiều kích cỡ khác nhau, từ 3 tỷ đến 70 tỷ tham số, không chỉ là một bộ công cụ AI khác; Họ là một bước đi táo bạo hướng tới W
Công cụ Podcast Được Hỗ trợ bởi AI để Tạo Nội dung Hiệu quả
Việc sản xuất và tinh chỉnh một podcast có thể vừa đòi hỏi nhiều công sức vừa mang lại sự thỏa mãn. Nhiều podcaster gặp khó khăn với các nhiệm vụ tốn thời gian như loại bỏ từ đệm, tạo ghi chú chương t
Bộ Jumpsuit Đỏ của Britney Spears: Khoảnh Khắc Định Hình Thời Trang Pop
Britney Spears, biểu tượng pop thống trị, luôn mê hoặc khán giả với phong cách táo bạo. Các video âm nhạc của cô không chỉ là những bản hit âm nhạc mà còn là cột mốc thời trang. Bài viết này khám phá
Nhận xét (4)
0/200
![GaryJones]() GaryJones
GaryJones
 15:40:05 GMT+07:00 Ngày 04 tháng 8 năm 2025
15:40:05 GMT+07:00 Ngày 04 tháng 8 năm 2025
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐


 0
0
![StephenRamirez]() StephenRamirez
18:35:39 GMT+07:00 Ngày 31 tháng 7 năm 2025
StephenRamirez
18:35:39 GMT+07:00 Ngày 31 tháng 7 năm 2025
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
![DavidGonzalez]() DavidGonzalez
08:19:05 GMT+07:00 Ngày 28 tháng 7 năm 2025
DavidGonzalez
08:19:05 GMT+07:00 Ngày 28 tháng 7 năm 2025
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
![PaulSanchez]() PaulSanchez
08:18:39 GMT+07:00 Ngày 28 tháng 7 năm 2025
PaulSanchez
08:18:39 GMT+07:00 Ngày 28 tháng 7 năm 2025
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0
Một nhóm nhà nghiên cứu từ Hoa Kỳ và Canada đã phát hiện ra rằng các mô hình ngôn ngữ lớn như ChatGPT gặp khó khăn trong việc tái tạo chính xác các thành ngữ lịch sử mà không cần huấn luyện trước phức tạp và tốn kém. Thách thức này khiến các dự án tham vọng, như sử dụng AI để hoàn thành cuốn tiểu thuyết cuối cùng chưa hoàn thiện của Charles Dickens, dường như nằm ngoài tầm với của hầu hết các nỗ lực học thuật và giải trí.
Các nhà nghiên cứu đã thử nghiệm nhiều phương pháp để tạo ra văn bản có âm hưởng lịch sử chính xác. Họ bắt đầu với các gợi ý đơn giản sử dụng văn xuôi đầu thế kỷ 20 và tiến tới tinh chỉnh một mô hình thương mại trên một tập hợp nhỏ sách từ thời kỳ đó. Họ cũng so sánh kết quả này với một mô hình được huấn luyện độc quyền trên văn học từ năm 1880 đến 1914.
Trong bài kiểm tra đầu tiên, họ yêu cầu ChatGPT-4o mô phỏng ngôn ngữ của thời kỳ fin-de-siècle. Kết quả khác biệt đáng kể so với mô hình GPT2 được tinh chỉnh nhỏ hơn, được huấn luyện trên văn học từ cùng thời kỳ.
Khi được yêu cầu hoàn thành một văn bản lịch sử thực sự (giữa trên), ngay cả ChatGPT-4o được chuẩn bị tốt (góc dưới bên trái) cũng không thể tránh khỏi việc quay lại chế độ 'blog', không thể hiện được thành ngữ yêu cầu. Ngược lại, mô hình GPT2 được tinh chỉnh (góc dưới bên phải) nắm bắt tốt phong cách ngôn ngữ, nhưng không chính xác ở các khía cạnh khác. Nguồn: https://arxiv.org/pdf/2505.00030
Mặc dù việc tinh chỉnh cải thiện sự giống nhau của đầu ra với phong cách gốc, người đọc vẫn có thể phát hiện ngôn ngữ hoặc ý tưởng hiện đại, cho thấy ngay cả các mô hình được điều chỉnh vẫn giữ lại dấu vết của dữ liệu huấn luyện đương đại.
Các nhà nghiên cứu kết luận rằng không có lối tắt tiết kiệm chi phí để tạo ra văn bản hoặc hội thoại lịch sử chính xác bằng máy. Họ cũng gợi ý rằng bản thân thách thức này có thể vốn dĩ có sai sót, nói rằng: "Chúng ta cũng nên xem xét khả năng rằng sự lạc hậu có thể ở một mức độ nào đó là không thể tránh khỏi. Dù chúng ta đại diện cho quá khứ bằng cách tinh chỉnh các mô hình lịch sử để chúng có thể trò chuyện, hay bằng cách dạy các mô hình hiện đại bắt chước một thời kỳ cũ hơn, một số thỏa hiệp có thể là cần thiết giữa mục tiêu về tính xác thực và sự trôi chảy trong giao tiếp. Rốt cuộc, không có ví dụ 'xác thực' nào về một cuộc trò chuyện giữa một người hỏi từ thế kỷ 21 và một người trả lời từ năm 1914. Các nhà nghiên cứu cố gắng tạo ra cuộc trò chuyện như vậy sẽ cần suy ngẫm về tiền đề rằng việc diễn giải luôn liên quan đến sự thương lượng giữa hiện tại và quá khứ."
Nghiên cứu, có tiêu đề "Liệu Các Mô Hình Ngôn Ngữ Có Thể Đại Diện Cho Quá Khứ Mà Không Có Sự Lạc Hậu?", được thực hiện bởi các nhà nghiên cứu từ Đại học Illinois, Đại học British Columbia và Đại học Cornell.
Những Thách Thức Ban Đầu
Các nhà nghiên cứu ban đầu đã khám phá liệu các mô hình ngôn ngữ hiện đại có thể được gợi ý để mô phỏng ngôn ngữ lịch sử. Họ sử dụng các đoạn trích thực sự từ sách xuất bản từ năm 1905 đến 1914, yêu cầu ChatGPT-4o tiếp tục các đoạn văn này theo cùng thành ngữ.
Văn bản thời kỳ gốc mà họ sử dụng là:
"Trong trường hợp cuối cùng này, khoảng năm hoặc sáu đô la được tiết kiệm mỗi phút, vì hơn hai mươi thước phim phải được tua ra để chiếu trong một phút duy nhất một đối tượng của một người ở trạng thái nghỉ hoặc một phong cảnh. Như vậy, thu được một sự kết hợp thực tế giữa hình ảnh cố định và chuyển động, tạo ra những hiệu ứng nghệ thuật nhất. Nó cũng cho phép chúng ta vận hành hai máy chiếu phim luân phiên để tránh nhấp nháy, hoặc chiếu đồng thời hình ảnh đỏ và xanh lá cây và tái tạo màu sắc tự nhiên, do đó giảm bớt mệt mỏi sinh lý cho mắt người, vốn quen với việc tiếp nhận các màu cơ bản đồng thời. Một lời về việc áp dụng ánh sáng lạnh cho nhiếp ảnh tức thì."
Để đánh giá tính chính xác lịch sử của văn bản được tạo ra, các nhà nghiên cứu đã tinh chỉnh một mô hình RoBERTa để ước tính ngày xuất bản, sử dụng một tập hợp con của Corpus of Historical American English, bao gồm tài liệu từ năm 1810 đến 2009. Bộ phân loại RoBERTa này đánh giá các đoạn tiếp nối được tạo ra bởi ChatGPT-4o, được gợi ý với các đoạn văn thực sự từ sách xuất bản từ năm 1905 đến 1914.
Gợi ý hệ thống dành cho ChatGPT là: "Nhiệm vụ của bạn là hoàn thành các đoạn văn từ sách đầu thế kỷ hai mươi. Bạn sẽ được cung cấp một đoạn văn từ một cuốn sách xuất bản năm 1913. Hãy tiếp tục đoạn văn này theo cùng phong cách, ít nhất 200 từ. Chỉ cung cấp phần tiếp nối này; không đưa ra bất kỳ nhận xét khung nào, như 'đây là phần tiếp nối:'."
Mặc dù sử dụng cả gợi ý một lần và 20 lần, đầu ra của ChatGPT-4o liên tục nghiêng về phong cách thế kỷ 21. Một ví dụ được cung cấp trong bài báo cho thấy nỗ lực của ChatGPT-4o để tiếp tục văn bản nhiếp ảnh:
"Việc sử dụng ánh sáng lạnh trong nhiếp ảnh tức thì đã cách mạng hóa cách tiếp cận để chụp ảnh trong các điều kiện ánh sáng khác nhau. Theo truyền thống, các nhiếp ảnh gia phải vật lộn với sự khắc nghiệt và biến đổi của ánh sáng tự nhiên hoặc tính chất xâm nhập của nhiếp ảnh đèn flash, có thể làm xáo trộn bầu không khí của một cảnh hoặc hành vi tự nhiên của các đối tượng, đặc biệt trong nhiếp ảnh động vật hoang dã và con người tự nhiên. Ánh sáng lạnh, với bản chất mềm mại và lan tỏa hơn... cho phép tái hiện tự nhiên hơn về màu sắc và kết cấu, thường bị mất dưới ánh sáng nhân tạo khắc nghiệt."
Văn bản kiểu Wiki chung chung này không khớp với phong cách dài dòng và phức tạp của văn bản thời kỳ gốc, cũng không tiếp tục liền mạch từ nơi văn bản gốc dừng lại. Thay vào đó, nó chuyển sang một cuộc thảo luận trừu tượng về một trong những chủ đề phụ.
Nhóm cũng đã thử nghiệm GPT-1914, một mô hình GPT-2 nhỏ hơn được huấn luyện từ đầu trên văn học từ năm 1880 đến 1914. Mặc dù kém mạch lạc hơn, đầu ra của nó phù hợp hơn với phong cách của thời kỳ nguồn. Một ví dụ được cung cấp trong bài báo là:
"Nguyên lý hoạt động của nó đã được giải thích trước đây (trang 4). Ở đây chúng ta chỉ đề cập rằng nó có thể được áp dụng một cách có lợi khi chúng ta muốn có được những bức ảnh rất nhanh trên giấy phủ collodion, cũng như những bức ảnh chụp bằng tấm gelatin. Trong những trường hợp như vậy, thời gian phơi sáng không được vượt quá một giây; nhưng nếu muốn phát triển bức ảnh trong thời gian ngắn hơn – chẳng hạn nửa giây – thì nhiệt độ không nên dưới 20°C, nếu không hình ảnh sẽ trở nên quá tối sau khi phát triển; hơn nữa, tấm phim sẽ mất đi độ nhạy dưới những điều kiện này. Tuy nhiên, cho các mục đích thông thường, chỉ cần phơi bề mặt nhạy sáng dưới mức nhiệt độ thấp mà không cần bất kỳ biện pháp phòng ngừa đặc biệt nào."
Mặc dù tài liệu gốc khó hiểu và thách thức để theo dõi, đầu ra của GPT-1914 nghe có vẻ xác thực hơn với thời kỳ. Tuy nhiên, các tác giả kết luận rằng việc gợi ý đơn giản không giúp khắc phục được những thiên kiến đương đại vốn có trong các mô hình được huấn luyện trước lớn như ChatGPT-4o.
Đo Lường Tính Chính Xác Lịch Sử
Để đánh giá mức độ giống nhau của đầu ra mô hình với văn bản lịch sử xác thực, các nhà nghiên cứu đã sử dụng một bộ phân loại thống kê để ước tính ngày xuất bản có khả năng của mỗi mẫu văn bản. Họ trực quan hóa kết quả bằng biểu đồ mật độ hạt nhân, cho thấy mô hình đặt mỗi đoạn văn trên dòng thời gian lịch sử ở đâu.
Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, dựa trên một bộ phân loại được huấn luyện để nhận diện phong cách lịch sử (văn bản nguồn từ 1905–1914 so sánh với các đoạn tiếp nối của GPT‑4o sử dụng gợi ý một lần và 20 lần, và của GPT‑1914 được huấn luyện chỉ trên văn học từ 1880–1914).
Mô hình RoBERTa được tinh chỉnh, mặc dù không hoàn hảo, đã làm nổi bật các xu hướng phong cách chung. Các đoạn văn từ GPT-1914, được huấn luyện chỉ trên văn học thời kỳ, tập trung quanh đầu thế kỷ 20, tương tự như tài liệu nguồn gốc. Ngược lại, đầu ra của ChatGPT-4o, ngay cả với nhiều gợi ý lịch sử, giống với văn bản thế kỷ 21, phản ánh dữ liệu huấn luyện của nó.
Các nhà nghiên cứu định lượng sự không khớp này bằng độ lệch Jensen-Shannon, đo lường sự khác biệt giữa hai phân phối xác suất. GPT-1914 đạt điểm gần 0.006 so với văn bản lịch sử thực, trong khi đầu ra một lần và 20 lần của ChatGPT-4o cho thấy khoảng cách lớn hơn nhiều, lần lượt là 0.310 và 0.350.
Các tác giả lập luận rằng những phát hiện này cho thấy việc gợi ý một mình, ngay cả với nhiều ví dụ, không phải là phương pháp đáng tin cậy để tạo ra văn bản mô phỏng thuyết phục phong cách lịch sử.
Tinh Chỉnh để Có Kết Quả Tốt Hơn
Bài báo sau đó khám phá liệu việc tinh chỉnh có thể mang lại kết quả tốt hơn. Quá trình này trực tiếp ảnh hưởng đến trọng số của mô hình bằng cách tiếp tục huấn luyện nó trên dữ liệu do người dùng chỉ định, có khả năng cải thiện hiệu suất trong lĩnh vực được nhắm đến.
Trong thí nghiệm tinh chỉnh đầu tiên, nhóm đã huấn luyện GPT-4o-mini trên khoảng hai nghìn cặp hoàn thành đoạn văn từ sách xuất bản từ năm 1905 đến 1914. Họ nhắm đến việc xem liệu việc tinh chỉnh quy mô nhỏ có thể chuyển dịch đầu ra của mô hình theo hướng phong cách lịch sử chính xác hơn.
Sử dụng cùng bộ phân loại dựa trên RoBERTa để ước tính 'ngày' phong cách của mỗi đầu ra, các nhà nghiên cứu phát hiện ra rằng mô hình được tinh chỉnh tạo ra văn bản phù hợp chặt chẽ với sự thật cơ bản. Độ lệch phong cách của nó so với các văn bản gốc, được đo bằng độ lệch Jensen-Shannon, giảm xuống còn 0.002, nhìn chung phù hợp với GPT-1914.
Ngày xuất bản ước tính cho văn bản thực và văn bản được tạo ra, cho thấy GPT‑1914 và phiên bản tinh chỉnh của GPT‑4o‑mini phù hợp như thế nào với phong cách viết đầu thế kỷ hai mươi (dựa trên sách xuất bản từ 1905 đến 1914).
Tuy nhiên, các nhà nghiên cứu cảnh báo rằng số liệu này có thể chỉ nắm bắt các đặc điểm bề mặt của phong cách lịch sử, không phải là các sai lệch khái niệm hoặc thực tế sâu hơn. Họ lưu ý: "Đây không phải là bài kiểm tra rất nhạy. Mô hình RoBERTa được sử dụng làm thẩm phán ở đây chỉ được huấn luyện để dự đoán ngày, không phải để phân biệt các đoạn văn xác thực với những đoạn văn lạc hậu. Nó có lẽ sử dụng bằng chứng phong cách thô để đưa ra dự đoán đó. Người đọc hoặc các mô hình lớn hơn có thể vẫn phát hiện ra nội dung lạc hậu trong các đoạn văn nghe có vẻ 'thuộc thời kỳ' một cách bề ngoài."
Đánh Giá Của Con Người
Cuối cùng, các nhà nghiên cứu đã tiến hành các bài kiểm tra đánh giá của con người bằng cách sử dụng 250 đoạn văn được chọn thủ công từ sách xuất bản từ năm 1905 đến 1914. Họ lưu ý rằng nhiều văn bản này có thể được diễn giải khác đi ngày nay so với thời điểm chúng được viết:
"Danh sách của chúng tôi bao gồm, ví dụ, một mục bách khoa toàn thư về Alsace (lúc đó là một phần của Đức) và một mục về bệnh beri-beri (lúc đó thường được giải thích là một bệnh nấm chứ không phải do thiếu hụt dinh dưỡng). Mặc dù đó là những khác biệt về thực tế, chúng tôi cũng chọn các đoạn văn sẽ hiển thị những khác biệt tinh tế hơn về thái độ, retoric hoặc trí tưởng tượng. Chẳng hạn, các mô tả về những nơi không phải châu Âu vào đầu thế kỷ hai mươi có xu hướng trượt vào sự khái quát hóa chủng tộc. Một mô tả về bình minh trên mặt trăng được viết vào năm 1913 tưởng tượng ra những hiện tượng màu sắc phong phú, vì chưa ai từng thấy hình ảnh của một thế giới không có bầu khí quyển."
Các nhà nghiên cứu đã tạo ra các câu hỏi ngắn mà mỗi đoạn văn lịch sử có thể trả lời một cách hợp lý, sau đó tinh chỉnh GPT-4o-mini trên các cặp câu hỏi-câu trả lời này. Để tăng cường đánh giá, họ đã huấn luyện năm phiên bản riêng biệt của mô hình, mỗi lần giữ lại một phần khác của dữ liệu để kiểm tra. Sau đó, họ tạo ra các phản hồi bằng cả phiên bản mặc định của GPT-4o và GPT-4o-mini, cũng như các biến thể được tinh chỉnh, mỗi phiên bản được đánh giá trên phần mà nó chưa thấy trong quá trình huấn luyện.
Lạc Trong Thời Gian
Để đánh giá mức độ thuyết phục mà các mô hình có thể bắt chước ngôn ngữ lịch sử, các nhà nghiên cứu đã yêu cầu ba chuyên gia chú thích xem xét 120 đoạn văn hoàn thành do AI tạo ra và đánh giá liệu mỗi đoạn có vẻ hợp lý cho một nhà văn vào năm 1914 hay không.
Đánh giá này hóa ra khó khăn hơn dự kiến. Mặc dù các chuyên gia đồng ý với các đánh giá của họ gần tám mươi phần trăm thời gian, sự mất cân bằng trong các phán quyết của họ (với 'hợp lý' được chọn gấp đôi so với 'không hợp lý') có nghĩa là mức độ đồng thuận thực tế của họ chỉ ở mức trung bình, được đo bằng điểm Cohen's kappa là 0.554.
Các chuyên gia mô tả nhiệm vụ này là khó khăn, thường yêu cầu nghiên cứu bổ sung để đánh giá liệu một tuyên bố có phù hợp với những gì được biết hoặc tin vào năm 1914 hay không. Một số đoạn văn đặt ra câu hỏi về giọng điệu và quan điểm, chẳng hạn như liệu một phản hồi có bị giới hạn phù hợp trong thế giới quan của nó để phản ánh những gì sẽ là điển hình vào năm 1914 hay không. Phán đoán này thường phụ thuộc vào mức độ thiên vị văn hóa, xu hướng nhìn các nền văn hóa khác thông qua các giả định hoặc thiên kiến của chính mình.
Thách thức là quyết định liệu một đoạn văn có thể hiện đủ thiên kiến văn hóa để có vẻ hợp lý về mặt lịch sử mà không nghe quá hiện đại hoặc quá xúc phạm theo tiêu chuẩn ngày nay. Các tác giả lưu ý rằng ngay cả đối với các học giả quen thuộc với thời kỳ này, việc vẽ một ranh giới rõ ràng giữa ngôn ngữ cảm thấy chính xác về mặt lịch sử và ngôn ngữ phản ánh các ý tưởng ngày nay là rất khó.
Tuy nhiên, kết quả cho thấy một xếp hạng rõ ràng của các mô hình, với phiên bản tinh chỉnh của GPT-4o-mini được đánh giá là hợp lý nhất tổng thể:
Đánh giá của các chuyên gia về mức độ hợp lý của đầu ra của mỗi mô hình
Liệu mức độ hiệu suất này, được đánh giá là hợp lý trong tám mươi phần trăm trường hợp, có đủ đáng tin cậy cho nghiên cứu lịch sử hay không vẫn chưa rõ, đặc biệt vì nghiên cứu không bao gồm một thước đo cơ bản về tần suất các văn bản thời kỳ chính gốc có thể bị phân loại sai.
Cảnh Báo Xâm Nhập
Tiếp theo, các nhà nghiên cứu đã tiến hành một bài kiểm tra 'xâm nhập', nơi các chuyên gia chú thích được cho xem bốn đoạn văn ẩn danh trả lời cùng một câu hỏi lịch sử. Ba phản hồi đến từ các mô hình ngôn ngữ, trong khi một phản hồi là một đoạn trích thực sự từ một nguồn đầu thế kỷ 20.
Nhiệm vụ là xác định đoạn văn nào là đoạn văn gốc, được viết thực sự trong thời kỳ đó. Phương pháp này không yêu cầu các chuyên gia đánh giá trực tiếp tính hợp lý mà đo lường tần suất đoạn văn thực sự nổi bật so với các phản hồi do AI tạo ra, hiệu quả kiểm tra liệu các mô hình có thể đánh lừa người đọc nghĩ rằng đầu ra của họ là xác thực hay không.
Xếp hạng của các mô hình phù hợp với kết quả từ nhiệm vụ phán đoán trước đó: phiên bản tinh chỉnh của GPT-4o-mini là thuyết phục nhất trong số các mô hình, nhưng vẫn kém so với điều thực sự.
Tần suất mỗi nguồn được xác định chính xác là đoạn văn lịch sử xác thực.
Bài kiểm tra này cũng đóng vai trò là một chuẩn mực hữu ích, vì đoạn văn chính gốc được xác định hơn một nửa thời gian, cho thấy khoảng cách giữa văn xuôi xác thực và văn xuôi tổng hợp vẫn đáng chú ý đối với người đọc.
Một phân tích thống kê được gọi là kiểm tra McNemar xác nhận rằng các khác biệt giữa các mô hình là có ý nghĩa, ngoại trừ trong trường hợp của hai phiên bản không được tinh chỉnh (GPT-4o và GPT-4o-mini), vốn hoạt động tương tự nhau.
Tương Lai của Quá Khứ
Các tác giả phát hiện ra rằng việc gợi ý các mô hình ngôn ngữ hiện đại áp dụng giọng điệu lịch sử không tạo ra kết quả thuyết phục đáng tin cậy: ít hơn hai phần ba đầu ra được người đọc đánh giá là hợp lý, và con số này có thể còn đánh giá quá cao hiệu suất.
Trong nhiều trường hợp, các phản hồi bao gồm các tín hiệu rõ ràng rằng mô hình đang nói từ góc nhìn hiện tại—các cụm từ như "vào năm 1914, chưa biết rằng..." hoặc "tính đến năm 1914, tôi không quen với..." phổ biến đến mức xuất hiện trong tới một phần năm các đoạn hoàn thành. Những tuyên bố từ chối như vậy làm rõ rằng mô hình đang mô phỏng lịch sử từ bên ngoài, thay vì viết từ bên trong.
Các tác giả tuyên bố: "Hiệu suất kém của học theo ngữ cảnh là điều đáng tiếc, vì những phương pháp này là dễ nhất và rẻ nhất cho nghiên cứu lịch sử dựa trên AI. Chúng tôi nhấn mạnh rằng chúng tôi chưa khám phá những cách tiếp cận này một cách toàn diện. Có thể sẽ phát hiện ra rằng học theo ngữ cảnh là đủ—hiện tại hoặc trong tương lai—cho một tập hợp con các lĩnh vực nghiên cứu. Nhưng bằng chứng ban đầu của chúng tôi không khả quan."
Các tác giả kết luận rằng trong khi việc tinh chỉnh một mô hình thương mại trên các đoạn văn lịch sử có thể tạo ra đầu ra thuyết phục về mặt phong cách với chi phí tối thiểu, nó không loại bỏ hoàn toàn dấu vết của góc nhìn hiện đại. Huấn luyện trước một mô hình hoàn toàn trên tài liệu thời kỳ tránh được sự lạc hậu nhưng đòi hỏi tài nguyên lớn hơn nhiều và dẫn đến đầu ra kém trôi chảy hơn.
Không phương pháp nào cung cấp giải pháp hoàn chỉnh, và hiện tại, bất kỳ nỗ lực nào để mô phỏng giọng nói lịch sử dường như đều liên quan đến sự đánh đổi giữa tính xác thực và sự mạch lạc. Các tác giả kết luận rằng cần thêm nghiên cứu để làm rõ cách tốt nhất để điều hướng căng thẳng đó.
Kết Luận
Một trong những câu hỏi hấp dẫn nhất được đặt ra bởi bài báo mới là về tính xác thực. Mặc dù không phải là công cụ hoàn hảo, các hàm mất mát và số liệu như LPIPS và SSIM cung cấp cho các nhà nghiên cứu thị giác máy tính một phương pháp để đánh giá so với sự thật cơ bản. Tuy nhiên, khi tạo ra văn bản mới theo phong cách của một thời đại đã qua, không có sự thật cơ bản—chỉ có nỗ lực để sống trong một góc nhìn văn hóa đã biến mất. Việc cố gắng tái tạo tư duy đó từ các dấu vết văn học bản thân nó là một hành động lượng tử hóa, vì những dấu vết này chỉ là bằng chứng, trong khi ý thức văn hóa mà chúng xuất phát vẫn nằm ngoài suy luận, và có lẽ vượt quá trí tưởng tượng.
Ở mức độ thực tế, nền tảng của các mô hình ngôn ngữ hiện đại, được định hình bởi các chuẩn mực và dữ liệu hiện tại, có nguy cơ diễn giải lại hoặc triệt tiêu các ý tưởng sẽ có vẻ hợp lý hoặc không đáng chú ý đối với một độc giả thời Edward nhưng giờ đây được ghi nhận như các hiện vật của định kiến, bất bình đẳng hoặc bất công.
Người ta tự hỏi, do đó, ngay cả khi chúng ta có thể tạo ra một cuộc đối thoại như vậy, liệu nó có thể không khiến chúng ta xa cách hay không.
Được xuất bản lần đầu vào Thứ Sáu, ngày 2 tháng 5 năm 2025










 Deep Cogito's LLMS vượt trội so với các mô hình có kích thước tương tự bằng IDA
Deep Cogito, một công ty có trụ sở tại San Francisco, đang tạo nên làn sóng trong cộng đồng AI với bản phát hành mới nhất của các mô hình ngôn ngữ lớn (LLM) mới nhất. Những mô hình này, có nhiều kích cỡ khác nhau, từ 3 tỷ đến 70 tỷ tham số, không chỉ là một bộ công cụ AI khác; Họ là một bước đi táo bạo hướng tới W
Deep Cogito's LLMS vượt trội so với các mô hình có kích thước tương tự bằng IDA
Deep Cogito, một công ty có trụ sở tại San Francisco, đang tạo nên làn sóng trong cộng đồng AI với bản phát hành mới nhất của các mô hình ngôn ngữ lớn (LLM) mới nhất. Những mô hình này, có nhiều kích cỡ khác nhau, từ 3 tỷ đến 70 tỷ tham số, không chỉ là một bộ công cụ AI khác; Họ là một bước đi táo bạo hướng tới W
 Công cụ Podcast Được Hỗ trợ bởi AI để Tạo Nội dung Hiệu quả
Việc sản xuất và tinh chỉnh một podcast có thể vừa đòi hỏi nhiều công sức vừa mang lại sự thỏa mãn. Nhiều podcaster gặp khó khăn với các nhiệm vụ tốn thời gian như loại bỏ từ đệm, tạo ghi chú chương t
Công cụ Podcast Được Hỗ trợ bởi AI để Tạo Nội dung Hiệu quả
Việc sản xuất và tinh chỉnh một podcast có thể vừa đòi hỏi nhiều công sức vừa mang lại sự thỏa mãn. Nhiều podcaster gặp khó khăn với các nhiệm vụ tốn thời gian như loại bỏ từ đệm, tạo ghi chú chương t
 Bộ Jumpsuit Đỏ của Britney Spears: Khoảnh Khắc Định Hình Thời Trang Pop
Britney Spears, biểu tượng pop thống trị, luôn mê hoặc khán giả với phong cách táo bạo. Các video âm nhạc của cô không chỉ là những bản hit âm nhạc mà còn là cột mốc thời trang. Bài viết này khám phá
15:40:05 GMT+07:00 Ngày 04 tháng 8 năm 2025
Bộ Jumpsuit Đỏ của Britney Spears: Khoảnh Khắc Định Hình Thời Trang Pop
Britney Spears, biểu tượng pop thống trị, luôn mê hoặc khán giả với phong cách táo bạo. Các video âm nhạc của cô không chỉ là những bản hit âm nhạc mà còn là cột mốc thời trang. Bài viết này khám phá
15:40:05 GMT+07:00 Ngày 04 tháng 8 năm 2025
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
0
18:35:39 GMT+07:00 Ngày 31 tháng 7 năm 2025
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
08:19:05 GMT+07:00 Ngày 28 tháng 7 năm 2025
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
08:18:39 GMT+07:00 Ngày 28 tháng 7 năm 2025
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0













