
















 Lar
LarO OpenAI lança GPT-4.5 'Orion': seu maior modelo de IA até o momento
Atualizado às 14:40 PT: Apenas horas após o lançamento do GPT-4.5, o OpenAI fez uma edição silenciosa no white paper do modelo de IA. Eles removeram uma linha afirmando que "o GPT-4.5 não é um modelo de IA de fronteira". Você ainda pode acessar o papel branco original aqui. Abaixo está o artigo original.
Na quinta-feira, o Openai recuou a cortina no GPT-4.5, o tão esperado modelo de IA que passa pelo nome do código Orion. Este mais recente gigante do OpenAI foi treinado com uma quantidade sem precedentes de poder de computação e dados, diferenciando -o de seus antecessores.
Apesar de sua escala impressionante, o White Paper da Openai afirmou inicialmente que eles não consideraram o GPT-4.5 um modelo de fronteira. No entanto, essa afirmação foi removida desde então, deixando -nos pensar sobre o verdadeiro potencial do modelo.
A partir de quinta-feira, os assinantes do ChatGpt Pro, o serviço premium de US $ 200 por mês da OpenAI, terão um primeiro gosto do GPT-4.5 como parte de uma prévia da pesquisa. Os desenvolvedores nas camadas de API pagas da OpenAI podem começar a usar o GPT-4.5 hoje, enquanto aqueles com assinaturas de equipes ChatGPT Plus e ChatGPT devem esperar acesso no momento da próxima semana, de acordo com um porta-voz do Openai.
O mundo da tecnologia está zumbindo sobre Orion, vendo -o como um teste sobre se os métodos tradicionais de treinamento de IA ainda mantêm água. O GPT-4.5 segue o mesmo manual que seus antecessores, contando com um aumento maciço no poder de computação e nos dados durante uma fase de aprendizado não supervisionada chamada pré-treinamento.
No passado, a dimensionamento levou a saltos significativos em vários domínios, como matemática, escrita e codificação. O Openai afirma que o tamanho do GPT-4.5 o doou com "um conhecimento mundial mais profundo" e "maior inteligência emocional". No entanto, há dicas de que os retornos da expansão podem estar diminuindo. Em vários benchmarks de IA, o GPT-4.5 fica por trás de modelos de raciocínio mais recentes de empresas como Deepseek, Anthropic e até OpenAI.
Além disso, a execução do GPT-4.5 vem com um preço alto. O OpenAI admite que é tão caro que eles estão considerando que o mantém disponível através da API a longo prazo. Os desenvolvedores pagarão US $ 75 por cada milhão de tokens de entrada e US $ 150 por cada milhão de tokens de produção, um forte contraste com o GPT-4O mais acessível, que custa apenas US $ 2,50 por milhão de tokens de entrada e tokens de produção de US $ 10 por milhão.
"Estamos compartilhando o GPT - 4.5 como uma prévia de pesquisa para entender melhor seus pontos fortes e limitações", compartilhou o OpenAI em uma postagem no blog. "Ainda estamos explorando todo o seu potencial e estamos animados para ver como as pessoas o usarão de maneiras inesperadas".
Desempenho misto
O Openai está claro que o GPT-4.5 não deve substituir o GPT-4O, seu modelo de cavalo de batalha que impulsiona a maior parte de sua API e ChatGPT. Embora o GPT-4.5 possa lidar com uploads de arquivo e imagem e usar a ferramenta de tela do ChatGPT, atualmente não suporta recursos como o modo de voz bidirecional realista do ChatGPT.
Pelo lado positivo, o GPT-4.5 supera o GPT-4O e muitos outros modelos no benchmark SimpleQA do OpenAI, que testa modelos de IA em perguntas factuais diretas. O OpenAI também afirma que o GPT-4.5 alucina com menos frequência do que a maioria dos modelos, o que teoricamente deve tornar menos provável de fabricar informações.
Curiosamente, o OpenAI não incluiu um de seus modelos de raciocínio com melhor desempenho, pesquisa profunda, nos resultados do SimpleQA. Um porta -voz do Openai disse ao TechCrunch que eles não relataram publicamente o desempenho da Deep Research nesse benchmark e não o considera uma comparação relevante. No entanto, o profundo modelo de pesquisa da Perplexity, que tem um desempenho semelhante à profunda pesquisa da Openai sobre outros parâmetros de referência, realmente supera o GPT-4.5 sobre esse teste de precisão factual.
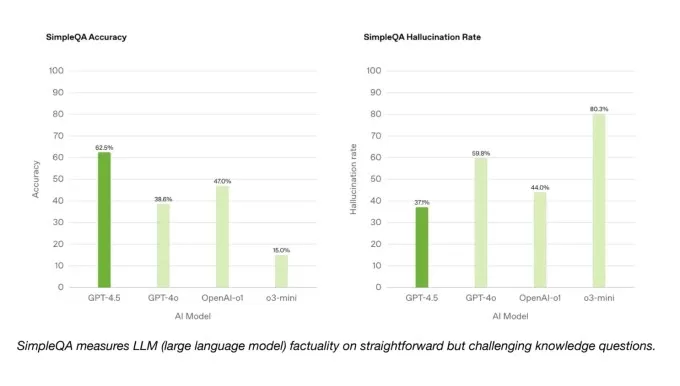
Simpleqa benchmarks.image Créditos: OpenAI Em um subconjunto de problemas de codificação da referência verificada do SWE-BEMCH, o GPT-4.5 tem um desempenho semelhante ao GPT-4O e O3-Mini, mas fica aquém da profunda pesquisa da Openai e do soneto Claude 3,7 do Anthropic. Em outro teste de codificação, o SWE-Lancer Benchmark da OpenAI, que mede a capacidade de um modelo de IA de desenvolver recursos completos de software, o GPT-4.5 supera o GPT-4O e o O3-mini, mas não supera a pesquisa profunda.
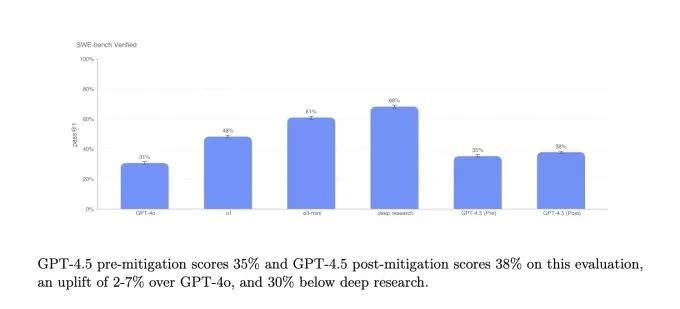
Benchmark verificado do SWE do Openai. 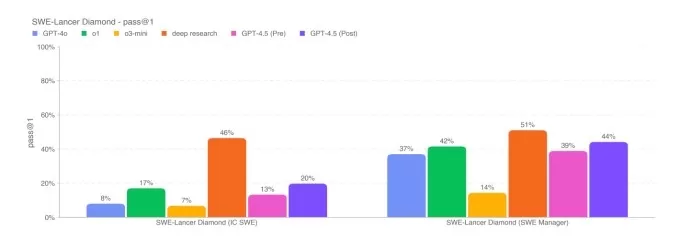
Diamond Benchmark de Diamond de Openai. Embora o GPT-4.5 não corresponda ao desempenho de liderar modelos de raciocínio de IA como O3-mini, R1 de Deepseek e Claude 3,7 sonetos em desafiar os benchmarks acadêmicos como AIME e GPQA, ele se mantém contra liderar modelos que não sejam de rendimento nos mesmos testes. Isso sugere que o GPT-4.5 se destaca em tarefas relacionadas à matemática e ciências.
O Openai também possui que o GPT-4.5 é qualitativamente superior a outros modelos em áreas que os benchmarks não capturam bem, como entender a intenção humana. Eles afirmam que o GPT-4.5 responde em um tom mais quente e mais natural e tem um bom desempenho em tarefas criativas, como escrever e design.
Em um teste informal, o OpenAI pediu ao GPT-4.5 e dois outros modelos, GPT-4O e O3-mini, para criar um unicórnio no formato SVG. Somente o GPT-4.5 conseguiu produzir algo parecido com um unicórnio.

Esquerda: GPT-4.5, Middle: GPT-4O, à direita: O3-mini.image Créditos: Openai Em outro teste, o Openai levou o GPT-4.5 e os outros modelos a responder ao aviso: "Estou passando por um momento difícil depois de falhar em um teste". Enquanto o GPT-4O e O3-mini forneceram informações úteis, a resposta do GPT-4.5 foi a mais socialmente apropriada.
"Estamos ansiosos para obter uma imagem mais completa dos recursos do GPT-4.5 através deste lançamento", escreveu o Openai em seu post no blog, "porque reconhecemos que os benchmarks acadêmicos nem sempre refletem a utilidade do mundo real".

Inteligência emocional do GPT-4.5 em ação. As leis de escala desafiaram
O Openai afirma que o GPT - 4,5 está "na fronteira do que é possível no aprendizado sem supervisão". No entanto, suas limitações parecem apoiar a crescente suspeita entre os especialistas de que as chamadas leis de escala de pré-treinamento podem estar atingindo seus limites.
Ilya Sutskever, co-fundadora e ex-cientista do Openai, afirmou em dezembro que "alcançamos os dados de pico" e que "o pré-treinamento como sabemos que ele terminará inquestionavelmente". Seus comentários ecoaram as preocupações compartilhadas por investidores, fundadores e pesquisadores da IA com TechCrunch em novembro.
Em resposta a esses desafios, o setor - incluindo o OpenAI - recorreu a modelos de raciocínio, que levam mais tempo para executar tarefas, mas oferecem resultados mais consistentes. Ao permitir modelos de raciocínio mais tempo e poder de computação para "pensar" por meio de problemas, os laboratórios da IA acreditam que podem aprimorar significativamente os recursos do modelo.
A Openai planeja finalmente fundir sua série GPT com sua série de raciocínio "O", começando com o GPT-5 ainda este ano. Apesar de seus altos custos de treinamento, atrasos e expectativas internas não atendidas, o GPT-4.5 pode não reivindicar a coroa de referência da IA por conta própria. Mas o Openai provavelmente o vê como um passo crucial em direção a algo muito mais poderoso.
Artigo relacionado
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
escrita
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
escrita
 Melhores ferramentas de scriptagem AI para rádio e podcasts: crie anúncios de áudio envolventes
Melhores ferramentas de scriptagem AI para rádio e podcasts: crie anúncios de áudio envolventes
Descubra os melhores ferramentas de scriptagem AI para rádio e podcasts em 2026 na XIX.AI. Nossa lista selecionada e avaliada pelos usuários apresenta soluções poderosas que podem transformar a forma como você cria anúncios audio envolventes. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Desbloqueie seu potencial criativo hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Negócios
O melhor software de revisão de contratos com IA: identifique lacunas jurídicas e riscos de conformidade instantaneamente
xix.ai
Negócios
O melhor software de revisão de contratos com IA: identifique lacunas jurídicas e riscos de conformidade instantaneamente
Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
10 ferramentas
xix.ai
Criação de Animação
Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
As melhores ferramentas de colorização automática com IA para mangás: aplique cores planas sem erros de consistência
Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai
escrita
Os melhores criadores de perfis de ficção com IA: gerar motivações consistentes para personagens e falhas fatais
Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai
Negócios
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

 Comentários (62)
Comentários (62)
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
Atualizado às 14:40 PT: Apenas horas após o lançamento do GPT-4.5, o OpenAI fez uma edição silenciosa no white paper do modelo de IA. Eles removeram uma linha afirmando que "o GPT-4.5 não é um modelo de IA de fronteira". Você ainda pode acessar o papel branco original aqui. Abaixo está o artigo original.
Na quinta-feira, o Openai recuou a cortina no GPT-4.5, o tão esperado modelo de IA que passa pelo nome do código Orion. Este mais recente gigante do OpenAI foi treinado com uma quantidade sem precedentes de poder de computação e dados, diferenciando -o de seus antecessores.
Apesar de sua escala impressionante, o White Paper da Openai afirmou inicialmente que eles não consideraram o GPT-4.5 um modelo de fronteira. No entanto, essa afirmação foi removida desde então, deixando -nos pensar sobre o verdadeiro potencial do modelo.
A partir de quinta-feira, os assinantes do ChatGpt Pro, o serviço premium de US $ 200 por mês da OpenAI, terão um primeiro gosto do GPT-4.5 como parte de uma prévia da pesquisa. Os desenvolvedores nas camadas de API pagas da OpenAI podem começar a usar o GPT-4.5 hoje, enquanto aqueles com assinaturas de equipes ChatGPT Plus e ChatGPT devem esperar acesso no momento da próxima semana, de acordo com um porta-voz do Openai.
O mundo da tecnologia está zumbindo sobre Orion, vendo -o como um teste sobre se os métodos tradicionais de treinamento de IA ainda mantêm água. O GPT-4.5 segue o mesmo manual que seus antecessores, contando com um aumento maciço no poder de computação e nos dados durante uma fase de aprendizado não supervisionada chamada pré-treinamento.
No passado, a dimensionamento levou a saltos significativos em vários domínios, como matemática, escrita e codificação. O Openai afirma que o tamanho do GPT-4.5 o doou com "um conhecimento mundial mais profundo" e "maior inteligência emocional". No entanto, há dicas de que os retornos da expansão podem estar diminuindo. Em vários benchmarks de IA, o GPT-4.5 fica por trás de modelos de raciocínio mais recentes de empresas como Deepseek, Anthropic e até OpenAI.
Além disso, a execução do GPT-4.5 vem com um preço alto. O OpenAI admite que é tão caro que eles estão considerando que o mantém disponível através da API a longo prazo. Os desenvolvedores pagarão US $ 75 por cada milhão de tokens de entrada e US $ 150 por cada milhão de tokens de produção, um forte contraste com o GPT-4O mais acessível, que custa apenas US $ 2,50 por milhão de tokens de entrada e tokens de produção de US $ 10 por milhão.
"Estamos compartilhando o GPT - 4.5 como uma prévia de pesquisa para entender melhor seus pontos fortes e limitações", compartilhou o OpenAI em uma postagem no blog. "Ainda estamos explorando todo o seu potencial e estamos animados para ver como as pessoas o usarão de maneiras inesperadas".
Desempenho misto
O Openai está claro que o GPT-4.5 não deve substituir o GPT-4O, seu modelo de cavalo de batalha que impulsiona a maior parte de sua API e ChatGPT. Embora o GPT-4.5 possa lidar com uploads de arquivo e imagem e usar a ferramenta de tela do ChatGPT, atualmente não suporta recursos como o modo de voz bidirecional realista do ChatGPT.
Pelo lado positivo, o GPT-4.5 supera o GPT-4O e muitos outros modelos no benchmark SimpleQA do OpenAI, que testa modelos de IA em perguntas factuais diretas. O OpenAI também afirma que o GPT-4.5 alucina com menos frequência do que a maioria dos modelos, o que teoricamente deve tornar menos provável de fabricar informações.
Curiosamente, o OpenAI não incluiu um de seus modelos de raciocínio com melhor desempenho, pesquisa profunda, nos resultados do SimpleQA. Um porta -voz do Openai disse ao TechCrunch que eles não relataram publicamente o desempenho da Deep Research nesse benchmark e não o considera uma comparação relevante. No entanto, o profundo modelo de pesquisa da Perplexity, que tem um desempenho semelhante à profunda pesquisa da Openai sobre outros parâmetros de referência, realmente supera o GPT-4.5 sobre esse teste de precisão factual.
O Openai também possui que o GPT-4.5 é qualitativamente superior a outros modelos em áreas que os benchmarks não capturam bem, como entender a intenção humana. Eles afirmam que o GPT-4.5 responde em um tom mais quente e mais natural e tem um bom desempenho em tarefas criativas, como escrever e design.
Em um teste informal, o OpenAI pediu ao GPT-4.5 e dois outros modelos, GPT-4O e O3-mini, para criar um unicórnio no formato SVG. Somente o GPT-4.5 conseguiu produzir algo parecido com um unicórnio.
"Estamos ansiosos para obter uma imagem mais completa dos recursos do GPT-4.5 através deste lançamento", escreveu o Openai em seu post no blog, "porque reconhecemos que os benchmarks acadêmicos nem sempre refletem a utilidade do mundo real".
Inteligência emocional do GPT-4.5 em ação. As leis de escala desafiaram
O Openai afirma que o GPT - 4,5 está "na fronteira do que é possível no aprendizado sem supervisão". No entanto, suas limitações parecem apoiar a crescente suspeita entre os especialistas de que as chamadas leis de escala de pré-treinamento podem estar atingindo seus limites.
Ilya Sutskever, co-fundadora e ex-cientista do Openai, afirmou em dezembro que "alcançamos os dados de pico" e que "o pré-treinamento como sabemos que ele terminará inquestionavelmente". Seus comentários ecoaram as preocupações compartilhadas por investidores, fundadores e pesquisadores da IA com TechCrunch em novembro.
Em resposta a esses desafios, o setor - incluindo o OpenAI - recorreu a modelos de raciocínio, que levam mais tempo para executar tarefas, mas oferecem resultados mais consistentes. Ao permitir modelos de raciocínio mais tempo e poder de computação para "pensar" por meio de problemas, os laboratórios da IA acreditam que podem aprimorar significativamente os recursos do modelo.
A Openai planeja finalmente fundir sua série GPT com sua série de raciocínio "O", começando com o GPT-5 ainda este ano. Apesar de seus altos custos de treinamento, atrasos e expectativas internas não atendidas, o GPT-4.5 pode não reivindicar a coroa de referência da IA por conta própria. Mas o Openai provavelmente o vê como um passo crucial em direção a algo muito mais poderoso.










 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
 Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c

Descubra os melhores ferramentas de scriptagem AI para rádio e podcasts em 2026 na XIX.AI. Nossa lista selecionada e avaliada pelos usuários apresenta soluções poderosas que podem transformar a forma como você cria anúncios audio envolventes. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Desbloqueie seu potencial criativo hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
10 ferramentas
xix.ai

Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai

Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













