
















 Maison
MaisonOpenAI lance GPT-4.5 'Orion': son plus grand modèle d'IA à ce jour
Mis à jour 14h40 PT: quelques heures seulement après le lancement de GPT-4.5, Openai a fait une modification silencieuse du livre blanc du modèle d'IA. Ils ont supprimé une ligne indiquant que "GPT-4.5 n'est pas un modèle Frontier AI". Vous pouvez toujours accéder au livre blanc d'origine ici. Vous trouverez ci-dessous l'article original.
Jeudi, Openai a retiré le rideau sur GPT-4.5, le modèle IA tant attendu qui passe par le nom de code Orion. Ce dernier géant d'Openai a été formé avec une quantité sans précédent de puissance et de données de calcul, la distinguant de ses prédécesseurs.
Malgré son échelle impressionnante, le livre blanc d'Openai a initialement déclaré qu'ils ne considéraient pas GPT-4.5 comme un modèle frontalier. Cependant, cette déclaration a depuis été supprimée, nous laissant nous demander le véritable potentiel du modèle.
À partir de jeudi, les abonnés à Chatgpt Pro, le service de 200 $ par mois d'Openai, obtiendront un premier goût de GPT-4.5 dans le cadre d'un aperçu de la recherche. Les développeurs sur les niveaux API payants d'OpenAI peuvent commencer à utiliser GPT-4.5 aujourd'hui, tandis que ceux qui ont des abonnements à l'équipe ChatGpt Plus et ChatGPT devraient s'attendre à l'accès la semaine prochaine, selon un porte-parole d'OpenAI.
Le monde de la technologie a bourdonné à propos d'Orion, le considérant comme un test pour savoir si les méthodes de formation d'IA traditionnelles détiennent toujours de l'eau. GPT-4.5 suit le même manuel de jeu que ses prédécesseurs, en s'appuyant sur une augmentation massive de la puissance de calcul et des données lors d'une phase d'apprentissage non supervisée appelée pré-formation.
Dans le passé, la mise à l'échelle a entraîné des pas de performance significatives dans divers domaines comme les mathématiques, l'écriture et le codage. OpenAI affirme que la taille de GPT-4.5 l'a dotée de "une connaissance mondiale plus profonde" et "une intelligence émotionnelle supérieure". Pourtant, il y a des indices que les rendements de la mise à l'échelle pourraient diminuer. Sur plusieurs repères d'IA, GPT-4.5 est à la traîne de nouveaux modèles de raisonnement de sociétés comme Deepseek, Anthropic et même Openai elle-même.
De plus, l'exécution du GPT-4.5 est livrée avec un prix élevé. Openai admet qu'il est si cher qu'ils envisagent de le garder disponible via leur API à long terme. Les développeurs paieront 75 $ pour chaque million de jetons d'entrée et 150 $ pour chaque million de jetons de production, un contraste frappant avec le GPT-4O plus abordable, qui ne coûte que 2,50 $ par million de jetons d'entrée et 10 $ par million de jetons de sortie.
"Nous partageons GPT - 4.5 comme aperçu de recherche pour mieux comprendre ses forces et ses limites", a expliqué Openai dans un article de blog. "Nous explorons toujours son plein potentiel et sommes ravis de voir comment les gens l'utiliseront de manière inattendue."
Performance mixte
Openai est clair que GPT-4.5 n'est pas destiné à remplacer GPT-4O, leur modèle de cheval de bataille qui anime la plupart de leur API et Chatgpt. Bien que GPT-4.5 puisse gérer les téléchargements de fichiers et d'images et utiliser l'outil Canvas de ChatGPT, il ne prend actuellement pas en charge les fonctionnalités telles que le mode vocal bidirectionnel réaliste de ChatGPT.
Du bon côté, GPT-4.5 surpasse GPT-4O et de nombreux autres modèles sur la référence SimpleQA d'OpenAI, qui teste les modèles AI sur des questions factuelles simples. OpenAI affirme également que GPT-4.5 hallucine moins fréquemment que la plupart des modèles, ce qui devrait théoriquement le rendre moins susceptible de fabriquer des informations.
Fait intéressant, OpenAI n'incluait pas l'un de ses modèles de raisonnement les plus performants, la recherche approfondie, dans les résultats SimpleQA. Un porte-parole d'OpenAI a déclaré à TechCrunch qu'il n'avait pas publié publiquement la performance de Deep Research sur cette référence et ne le considérait pas comme une comparaison pertinente. Cependant, le modèle de recherche en profondeur de Perplexity, qui se déroule de manière similaire à la recherche approfondie d'Openai sur d'autres repères, dépasse en fait GPT-4.5 sur ce test de précision factuelle.
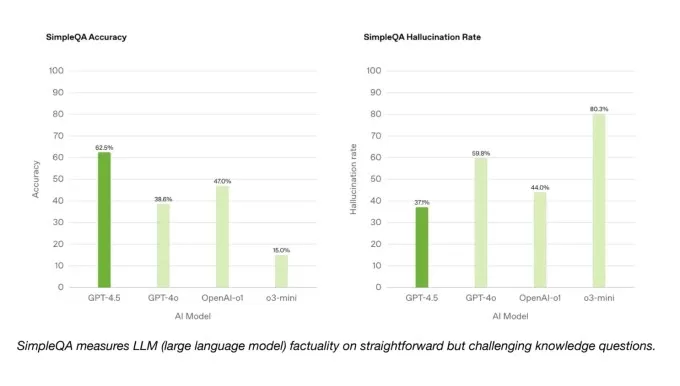
Benchmarks SimpleQA. Crédits d'image: OpenAI Sur un sous-ensemble de problèmes de codage de la référence vérifiée SWE-Bench, GPT-4.5 fonctionne de manière similaire à GPT-4O et O3-Mini mais ne fait pas de la recherche profonde d'Openai et du sonnet Claude 3.7 d'Anthropic. Lors d'un autre test de codage, la référence Swe-Lancer d'Openai, qui mesure la capacité d'un modèle d'IA à développer des fonctionnalités logicielles complètes, GPT-4.5 surpasse GPT-4O et O3-MINI mais ne dépasse pas la recherche approfondie.
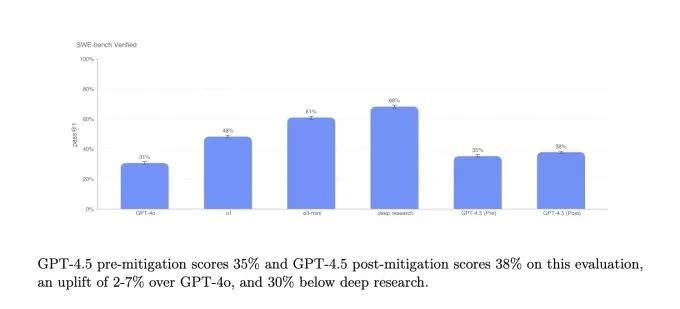
Benchmark Vérifié Swe d'Openai. Crédits d'image: OpenAI 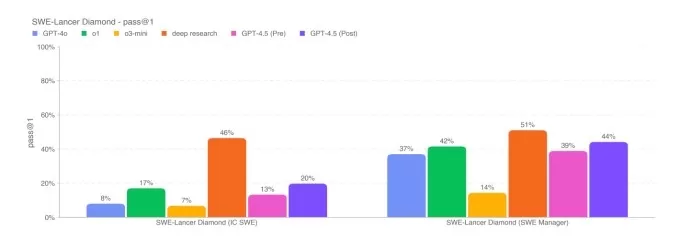
Benchmark Diamond Benchmark d'Openai. Crédits d'image: OpenAI Bien que le GPT-4.5 ne correspond pas tout à fait aux performances des principaux modèles de raisonnement AI comme O3-Mini, R1 de Deepseek et Claude 3.7 Sonnet sur les références académiques difficiles comme AIME et GPQA, il se tient à l'idée de principaux modèles non-saisonnants sur les mêmes tests. Cela suggère que GPT-4.5 excelle dans les tâches liées aux mathématiques et aux sciences.
OpenAI se vante également que le GPT-4.5 est qualitativement supérieur aux autres modèles dans les domaines que les références ne capturent pas bien, comme la compréhension de l'intention humaine. Ils affirment que GPT-4.5 répond dans un ton plus chaud et plus naturel et fonctionne bien sur des tâches créatives comme l'écriture et le design.
Dans un test informel, OpenAI a demandé à GPT-4.5 et deux autres modèles, GPT-4O et O3-MinI, pour créer une licorne au format SVG. Seul GPT-4.5 a réussi à produire quelque chose ressemblant à une licorne.

Gauche: GPT-4.5, milieu: GPT-4O, à droite: O3-MinI.Image Crédits: OpenAI Dans un autre test, OpenAI a incité GPT-4.5 et les autres modèles pour répondre à l'invite: "Je passe une période difficile après avoir échoué à un test." Alors que GPT-4O et O3-MINI ont fourni des informations utiles, la réponse de GPT-4.5 a été la plus appropriée socialement.
"Nous sommes impatients d'obtenir une image plus complète des capacités de GPT-4.5 grâce à cette version", a écrit Openai dans leur article de blog, "parce que nous reconnaissons que les références académiques ne reflètent pas toujours une utilité réelle."

L'intelligence émotionnelle de GPT-4.5 en action. Crédits d'image: Openai Les lois sur la mise à l'échelle contestées
OpenAI affirme que GPT - 4.5 est "à la frontière de ce qui est possible dans l'apprentissage non supervisé". Pourtant, ses limites semblent soutenir la suspicion croissante parmi les experts que les soi-disant lois à l'échelle de la pré-formation pourraient atteindre leurs limites.
Ilya Sutskever, co-fondatrice d'Openai et ancien scientifique en chef, a déclaré en décembre que "nous avons obtenu des données de pointe" et que "pré-formation comme nous le savons, il se terminera incontestablement". Ses commentaires ont fait écho aux préoccupations partagées par les investisseurs de l'IA, les fondateurs et les chercheurs avec TechCrunch en novembre.
En réponse à ces défis, l'industrie - notamment OpenAI - s'est tournée vers des modèles de raisonnement, qui prennent plus de temps pour effectuer des tâches mais offrent des résultats plus cohérents. En permettant aux modèles de raisonnement plus de temps et de calcul de la puissance de calcul pour «réfléchir» à travers des problèmes, les laboratoires AI pensent qu'ils peuvent améliorer considérablement les capacités du modèle.
Openai prévoit éventuellement de fusionner sa série GPT avec sa série de raisons "O", à commencer par GPT-5 plus tard cette année. Malgré ses coûts de formation élevés, ses retards et ses attentes internes non satisfaites, GPT-4.5 pourrait ne pas revendiquer la couronne de référence de l'IA en soi. Mais Openai le voit probablement comme une étape cruciale vers quelque chose de bien plus puissant.
Article connexe
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Édition d'images
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Édition d'images
 Generateurs d'art par intelligence artificielle pour storyboards de courts drames : personnages de fantasy et de romance urbaine
Generateurs d'art par intelligence artificielle pour storyboards de courts drames : personnages de fantasy et de romance urbaine
2026 : Découvrez les meilleurs générateurs d’art artificiel pour les storyboards de courts métrages. Notre liste sélectionnée présente des outils hautement réputés pour créer des personnages captivants dans les genres fantasy et romance urbaine. Comparez les options gratuites et payantes, consultez les résultats de tests réels et trouvez le partenaire créatif idéal pour vous. Recevez chaque semaine des classements mis à jour et des conseils d’experts de XIX.AI. Commencez dès aujourd’hui à visualiser votre histoire !
 10 outils
10 outils
 xix.ai
en écrivant
Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
xix.ai
en écrivant
Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai
Création d'animations
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

 commentaires (62)
commentaires (62)
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
Mis à jour 14h40 PT: quelques heures seulement après le lancement de GPT-4.5, Openai a fait une modification silencieuse du livre blanc du modèle d'IA. Ils ont supprimé une ligne indiquant que "GPT-4.5 n'est pas un modèle Frontier AI". Vous pouvez toujours accéder au livre blanc d'origine ici. Vous trouverez ci-dessous l'article original.
Jeudi, Openai a retiré le rideau sur GPT-4.5, le modèle IA tant attendu qui passe par le nom de code Orion. Ce dernier géant d'Openai a été formé avec une quantité sans précédent de puissance et de données de calcul, la distinguant de ses prédécesseurs.
Malgré son échelle impressionnante, le livre blanc d'Openai a initialement déclaré qu'ils ne considéraient pas GPT-4.5 comme un modèle frontalier. Cependant, cette déclaration a depuis été supprimée, nous laissant nous demander le véritable potentiel du modèle.
À partir de jeudi, les abonnés à Chatgpt Pro, le service de 200 $ par mois d'Openai, obtiendront un premier goût de GPT-4.5 dans le cadre d'un aperçu de la recherche. Les développeurs sur les niveaux API payants d'OpenAI peuvent commencer à utiliser GPT-4.5 aujourd'hui, tandis que ceux qui ont des abonnements à l'équipe ChatGpt Plus et ChatGPT devraient s'attendre à l'accès la semaine prochaine, selon un porte-parole d'OpenAI.
Le monde de la technologie a bourdonné à propos d'Orion, le considérant comme un test pour savoir si les méthodes de formation d'IA traditionnelles détiennent toujours de l'eau. GPT-4.5 suit le même manuel de jeu que ses prédécesseurs, en s'appuyant sur une augmentation massive de la puissance de calcul et des données lors d'une phase d'apprentissage non supervisée appelée pré-formation.
Dans le passé, la mise à l'échelle a entraîné des pas de performance significatives dans divers domaines comme les mathématiques, l'écriture et le codage. OpenAI affirme que la taille de GPT-4.5 l'a dotée de "une connaissance mondiale plus profonde" et "une intelligence émotionnelle supérieure". Pourtant, il y a des indices que les rendements de la mise à l'échelle pourraient diminuer. Sur plusieurs repères d'IA, GPT-4.5 est à la traîne de nouveaux modèles de raisonnement de sociétés comme Deepseek, Anthropic et même Openai elle-même.
De plus, l'exécution du GPT-4.5 est livrée avec un prix élevé. Openai admet qu'il est si cher qu'ils envisagent de le garder disponible via leur API à long terme. Les développeurs paieront 75 $ pour chaque million de jetons d'entrée et 150 $ pour chaque million de jetons de production, un contraste frappant avec le GPT-4O plus abordable, qui ne coûte que 2,50 $ par million de jetons d'entrée et 10 $ par million de jetons de sortie.
"Nous partageons GPT - 4.5 comme aperçu de recherche pour mieux comprendre ses forces et ses limites", a expliqué Openai dans un article de blog. "Nous explorons toujours son plein potentiel et sommes ravis de voir comment les gens l'utiliseront de manière inattendue."
Performance mixte
Openai est clair que GPT-4.5 n'est pas destiné à remplacer GPT-4O, leur modèle de cheval de bataille qui anime la plupart de leur API et Chatgpt. Bien que GPT-4.5 puisse gérer les téléchargements de fichiers et d'images et utiliser l'outil Canvas de ChatGPT, il ne prend actuellement pas en charge les fonctionnalités telles que le mode vocal bidirectionnel réaliste de ChatGPT.
Du bon côté, GPT-4.5 surpasse GPT-4O et de nombreux autres modèles sur la référence SimpleQA d'OpenAI, qui teste les modèles AI sur des questions factuelles simples. OpenAI affirme également que GPT-4.5 hallucine moins fréquemment que la plupart des modèles, ce qui devrait théoriquement le rendre moins susceptible de fabriquer des informations.
Fait intéressant, OpenAI n'incluait pas l'un de ses modèles de raisonnement les plus performants, la recherche approfondie, dans les résultats SimpleQA. Un porte-parole d'OpenAI a déclaré à TechCrunch qu'il n'avait pas publié publiquement la performance de Deep Research sur cette référence et ne le considérait pas comme une comparaison pertinente. Cependant, le modèle de recherche en profondeur de Perplexity, qui se déroule de manière similaire à la recherche approfondie d'Openai sur d'autres repères, dépasse en fait GPT-4.5 sur ce test de précision factuelle.
OpenAI se vante également que le GPT-4.5 est qualitativement supérieur aux autres modèles dans les domaines que les références ne capturent pas bien, comme la compréhension de l'intention humaine. Ils affirment que GPT-4.5 répond dans un ton plus chaud et plus naturel et fonctionne bien sur des tâches créatives comme l'écriture et le design.
Dans un test informel, OpenAI a demandé à GPT-4.5 et deux autres modèles, GPT-4O et O3-MinI, pour créer une licorne au format SVG. Seul GPT-4.5 a réussi à produire quelque chose ressemblant à une licorne.
"Nous sommes impatients d'obtenir une image plus complète des capacités de GPT-4.5 grâce à cette version", a écrit Openai dans leur article de blog, "parce que nous reconnaissons que les références académiques ne reflètent pas toujours une utilité réelle."
L'intelligence émotionnelle de GPT-4.5 en action. Crédits d'image: Openai Les lois sur la mise à l'échelle contestées
OpenAI affirme que GPT - 4.5 est "à la frontière de ce qui est possible dans l'apprentissage non supervisé". Pourtant, ses limites semblent soutenir la suspicion croissante parmi les experts que les soi-disant lois à l'échelle de la pré-formation pourraient atteindre leurs limites.
Ilya Sutskever, co-fondatrice d'Openai et ancien scientifique en chef, a déclaré en décembre que "nous avons obtenu des données de pointe" et que "pré-formation comme nous le savons, il se terminera incontestablement". Ses commentaires ont fait écho aux préoccupations partagées par les investisseurs de l'IA, les fondateurs et les chercheurs avec TechCrunch en novembre.
En réponse à ces défis, l'industrie - notamment OpenAI - s'est tournée vers des modèles de raisonnement, qui prennent plus de temps pour effectuer des tâches mais offrent des résultats plus cohérents. En permettant aux modèles de raisonnement plus de temps et de calcul de la puissance de calcul pour «réfléchir» à travers des problèmes, les laboratoires AI pensent qu'ils peuvent améliorer considérablement les capacités du modèle.
Openai prévoit éventuellement de fusionner sa série GPT avec sa série de raisons "O", à commencer par GPT-5 plus tard cette année. Malgré ses coûts de formation élevés, ses retards et ses attentes internes non satisfaites, GPT-4.5 pourrait ne pas revendiquer la couronne de référence de l'IA en soi. Mais Openai le voit probablement comme une étape cruciale vers quelque chose de bien plus puissant.










 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
 Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc

2026 : Découvrez les meilleurs générateurs d’art artificiel pour les storyboards de courts métrages. Notre liste sélectionnée présente des outils hautement réputés pour créer des personnages captivants dans les genres fantasy et romance urbaine. Comparez les options gratuites et payantes, consultez les résultats de tests réels et trouvez le partenaire créatif idéal pour vous. Recevez chaque semaine des classements mis à jour et des conseils d’experts de XIX.AI. Commencez dès aujourd’hui à visualiser votre histoire !
10 outils
xix.ai

Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai

Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













