
















 Heim
HeimOpenAI startet GPT-4,5 'Orion': sein bisher größtes KI-Modell
Aktualisiert 14.40 Uhr PT: Nur wenige Stunden nach dem Start von GPT-4,5 machte Openai eine ruhige Bearbeitung des Whitepapiers des KI-Modells. Sie entfernten eine Linie, in der festgestellt wurde, dass "GPT-4,5 kein Grenz-AI-Modell ist". Sie können hier weiterhin auf das ursprüngliche weiße Papier zugreifen. Unten ist der ursprüngliche Artikel.
Am Donnerstag zog Openai den Vorhang auf GPT-4,5 zurück, das mit Spannung erwartete KI-Modell, das den Codenamen Orion enthält. Dieser jüngste Unscheitern von OpenAI wurde mit einer beispiellosen Menge an Rechenleistung und Daten geschult, wodurch sie von seinen Vorgängern abgehalten werden.
Trotz seiner beeindruckenden Skala erklärte Openais White Paper zunächst, dass sie GPT-4,5 nicht als ein Grenzmodell betrachteten. Diese Aussage wurde jedoch inzwischen entfernt, sodass wir uns über das wahre Potenzial des Modells wundern lassen.
Ab Donnerstag erhalten Abonnenten von Chatgpt Pro, OpenAIs Premium-Service von 200 US-Dollar pro Monat, im Rahmen einer Forschungsvorschau einen ersten Vorgeschmack auf GPT-4,5. Entwickler von OpenAIs kostenpflichtigen API-Ebenen können heute mit GPT-4,5 beginnen, während diejenigen mit Chatgpt Plus- und ChatGPT-Teamabonnements laut einem OpenAI-Sprecher irgendwann den Zugriff erwarten sollten.
Die Tech -Welt hat in Orion summt und sie als Test betrachtet, ob traditionelle KI -Trainingsmethoden immer noch Wasser enthalten. GPT-4,5 folgt dem gleichen Spielbuch wie seine Vorgänger und stützt sich auf eine massive Zunahme der Rechenleistung und Daten während einer unbeaufsichtigten Lernphase, die als Pre-Training bezeichnet wird.
In der Vergangenheit hat die Skalierung zu erheblichen Leistungssprung in verschiedenen Bereichen wie Mathematik, Schreiben und Codierung geführt. OpenAI behauptet, dass die Größe von GPT-4.5 es mit "einem tieferen Weltwissen" und "höherer emotionaler Intelligenz" ausgestattet hat. Es gibt jedoch Hinweise darauf, dass die Renditen durch die Skalierung möglicherweise abnehmen. Bei mehreren KI-Benchmarks bleibt GPT-4,5 hinter neueren Argumentationsmodellen von Unternehmen wie Deepseek, Anthropic und sogar Openai selbst zurück.
Darüber hinaus ist das Laufen von GPT-4,5 mit einem hohen Preis ausgestattet. Openai gibt zu, dass es so teuer ist, dass sie überlegen, ob sie auf lange Sicht über ihre API verfügbar bleiben sollen. Entwickler zahlen 75 US-Dollar für jede Million Input-Token und 150 US-Dollar für jede Million Output-Token, ein starker Kontrast zu den günstigeren GPT-4O, die nur 2,50 USD pro Million Eingangs-Token und 10 USD pro Million Output-Token kostet.
"Wir teilen GPT -4,5 als Forschungsvorschau, um die Stärken und Einschränkungen besser zu verstehen", teilte Openai in einem Blog -Beitrag mit. "Wir untersuchen immer noch sein volles Potenzial und freuen uns zu sehen, wie Menschen es auf unerwartete Weise nutzen werden."
Gemischte Leistung
OpenAI ist klar, dass GPT-4,5 GPT-4O nicht ersetzen soll, ihr Arbeitspferdmodell, das den größten Teil ihrer API und Chatgpt vorantreibt. Während GPT-4.5 Datei- und Image-Uploads verarbeiten und das Canvas-Tool von ChatGPT verwenden kann, unterstützt es derzeit keine Funktionen wie den realistischen Zwei-Wege-Sprachmodus von ChatGPT.
Auf der hellen Seite übertrifft GPT-4,5 GPT-4O und viele andere Modelle auf OpenAIs SimpleQA-Benchmark, die KI-Modelle auf einfachen, sachlichen Fragen testet. OpenAI behauptet auch, dass GPT-4,5 weniger häufig als die meisten Modelle halluziniert, was theoretisch weniger wahrscheinlich die Informationen erfunden sollte.
Interessanterweise enthielt OpenAI nicht eines seiner erstklassigen Argumentationsmodelle, Deep Research, in die SimpleQA-Ergebnisse. Ein OpenAI -Sprecher teilte TechCrunch mit, dass sie die Leistung von Deep Research in diesem Benchmark nicht öffentlich gemeldet haben und es nicht als relevanten Vergleich betrachten. Das Deep-Forschungsmodell von Verwirrlichkeit, das ähnlich wie die tiefen Forschung von Openai zu anderen Benchmarks entspricht, übertrifft jedoch GPT-4,5 bei diesem Test der sachlichen Genauigkeit.
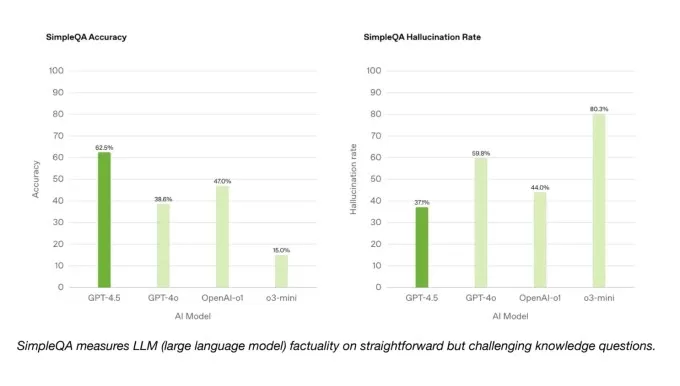
SimpleQa Benchmarks.IMAGE Credits: OpenAI Bei einer Untergruppe von Codierungsproblemen aus dem verifizierten Benchmark von SWE-Bench spielt GPT-4,5 ähnlich wie GPT-4O und O3-Mini, liegt jedoch nicht vor OpenAs tiefem Forschung und dem Claude 3.7-Sonett von Anthropic. Bei einem anderen Codierungstest, dem Swe-Lancer-Benchmark von OpenAI, der die Fähigkeit eines KI-Modells, vollständige Softwarefunktionen zu entwickeln, misst, übertrifft GPT-4,5 sowohl GPT-4O als auch O3-Mini, übertrifft jedoch nicht die tiefe Forschung.
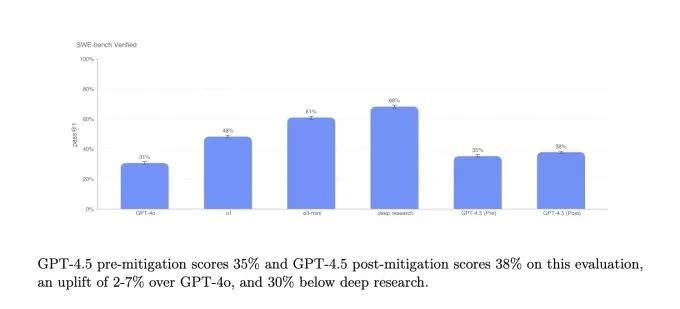
Openais SWE-Bench verifizierte Benchmark.image Credits: Openai 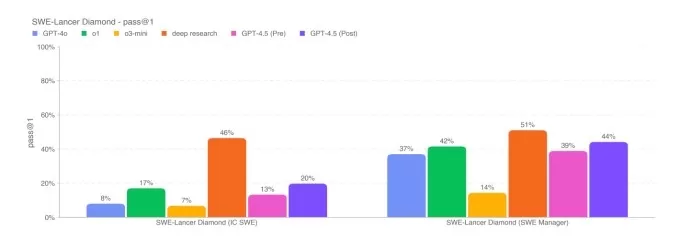
OpenAs Swe-Lancer Diamond Benchmark.image Credits: OpenAI Während GPT-4,5 nicht ganz der Leistung führender KI-Argumentationsmodelle wie O3-Mini, Deepseeks R1 und Claude 3.7 Sonett über die herausfordernden akademischen Benchmarks wie Aime und GPQA übereinstimmen, hält es sich selbst gegen führende Nicht-technische Modelle für die gleichen Tests. Dies deutet darauf hin, dass GPT-4,5 in Mathematik- und Wissenschaftsaufgaben auszeichnet.
OpenAI rühmt sich auch, dass GPT-4,5 anderen Modellen qualitativ überlegen ist, in Bereichen, die Benchmarks nicht gut erfassen, z. B. das Verständnis der menschlichen Absicht. Sie behaupten, dass GPT-4,5 in einem wärmeren, natürlicheren Ton reagiert und bei kreativen Aufgaben wie Schreiben und Design gut abschneidet.
In einem informellen Test bat Openai GPT-4,5 und zwei weitere Modelle, GPT-4O und O3-Mini, ein Einhorn im SVG-Format zu erstellen. Nur GPT-4,5 gelang es, etwas zu produzieren, das einem Einhorn ähnelt.

Links: GPT-4.5, Mitte: GPT-4O, rechts: O3-Mini.Image Credits: OpenAI In einem anderen Test veranlasste OpenAI GPT-4,5 und die anderen Modelle, auf die Eingabeaufforderung zu antworten: "Ich mache eine schwere Zeit nach dem Versagen eines Tests." Während GPT-4O und O3-Mini hilfreiche Informationen lieferten, war die Reaktion von GPT-4.5 die sozial angemesseneste.
"Wir freuen uns darauf, durch diese Veröffentlichung ein vollständigeres Bild der Fähigkeiten von GPT-44 zu erhalten", schrieb Openai in ihrem Blog-Beitrag, "weil wir erkennen, dass akademische Benchmarks nicht immer die nützliche Nützlichkeit der realen Welt widerspiegeln."

Emotionale Intelligenz von GPT-4.5 in Aktion.image Credits: OpenAI Skalierungsgesetze in Frage gestellt
OpenAI behauptet, dass GPT -4,5 "an der Grenze dessen, was im unbeaufsichtigten Lernen möglich ist", stammt. Seine Einschränkungen scheinen jedoch den wachsenden Verdacht der Experten zu unterstützen, dass die sogenannten Skalierungsgesetze der Voraussetzung ihre Grenzen erreichen könnten.
Ilya Sutskever, Mitbegründerin und ehemaliger Chefwissenschaftlerin, erklärte im Dezember, dass "wir Spitzendaten erreicht haben" und dass "die Voraussetzung, wie wir sie wissen, zweifellos enden werden". Seine Kommentare wiederholten die Bedenken, die KI -Investoren, Gründer und Forscher mit TechCrunch im November geteilt hatten.
Als Reaktion auf diese Herausforderungen hat sich die Branche - einschließlich Openai - den Argumentationsmodellen zugewandt, die länger dauern, um Aufgaben auszuführen, aber konsistentere Ergebnisse liefern. AI LABS ist der Ansicht, dass sie die Modellfunktionen erheblich verbessern können.
OpenAI plant, seine GPT-Serie schließlich mit ihrer "O" -Reminaturerie zu verschmelzen, beginnend mit GPT-5 später in diesem Jahr. Trotz seiner hohen Schulungskosten, Verzögerungen und nicht erfüllten internen Erwartungen kann GPT-4,5 die KI-Benchmark-Krone selbst nicht beanspruchen. Aber Openai sieht es wahrscheinlich als einen entscheidenden Schritt in Richtung etwas, das weitaus stärkerer ist.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Geschäft
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
 10 Tools
10 Tools
 xix.ai
Animationserstellung
AI-Anime-Generator für Donghua: Erstellen Sie Charaktere für Web-Romane und Comic-Avatare
xix.ai
Animationserstellung
AI-Anime-Generator für Donghua: Erstellen Sie Charaktere für Web-Romane und Comic-Avatare
Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai
Code
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

 Kommentare (62)
Kommentare (62)
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
Aktualisiert 14.40 Uhr PT: Nur wenige Stunden nach dem Start von GPT-4,5 machte Openai eine ruhige Bearbeitung des Whitepapiers des KI-Modells. Sie entfernten eine Linie, in der festgestellt wurde, dass "GPT-4,5 kein Grenz-AI-Modell ist". Sie können hier weiterhin auf das ursprüngliche weiße Papier zugreifen. Unten ist der ursprüngliche Artikel.
Am Donnerstag zog Openai den Vorhang auf GPT-4,5 zurück, das mit Spannung erwartete KI-Modell, das den Codenamen Orion enthält. Dieser jüngste Unscheitern von OpenAI wurde mit einer beispiellosen Menge an Rechenleistung und Daten geschult, wodurch sie von seinen Vorgängern abgehalten werden.
Trotz seiner beeindruckenden Skala erklärte Openais White Paper zunächst, dass sie GPT-4,5 nicht als ein Grenzmodell betrachteten. Diese Aussage wurde jedoch inzwischen entfernt, sodass wir uns über das wahre Potenzial des Modells wundern lassen.
Ab Donnerstag erhalten Abonnenten von Chatgpt Pro, OpenAIs Premium-Service von 200 US-Dollar pro Monat, im Rahmen einer Forschungsvorschau einen ersten Vorgeschmack auf GPT-4,5. Entwickler von OpenAIs kostenpflichtigen API-Ebenen können heute mit GPT-4,5 beginnen, während diejenigen mit Chatgpt Plus- und ChatGPT-Teamabonnements laut einem OpenAI-Sprecher irgendwann den Zugriff erwarten sollten.
Die Tech -Welt hat in Orion summt und sie als Test betrachtet, ob traditionelle KI -Trainingsmethoden immer noch Wasser enthalten. GPT-4,5 folgt dem gleichen Spielbuch wie seine Vorgänger und stützt sich auf eine massive Zunahme der Rechenleistung und Daten während einer unbeaufsichtigten Lernphase, die als Pre-Training bezeichnet wird.
In der Vergangenheit hat die Skalierung zu erheblichen Leistungssprung in verschiedenen Bereichen wie Mathematik, Schreiben und Codierung geführt. OpenAI behauptet, dass die Größe von GPT-4.5 es mit "einem tieferen Weltwissen" und "höherer emotionaler Intelligenz" ausgestattet hat. Es gibt jedoch Hinweise darauf, dass die Renditen durch die Skalierung möglicherweise abnehmen. Bei mehreren KI-Benchmarks bleibt GPT-4,5 hinter neueren Argumentationsmodellen von Unternehmen wie Deepseek, Anthropic und sogar Openai selbst zurück.
Darüber hinaus ist das Laufen von GPT-4,5 mit einem hohen Preis ausgestattet. Openai gibt zu, dass es so teuer ist, dass sie überlegen, ob sie auf lange Sicht über ihre API verfügbar bleiben sollen. Entwickler zahlen 75 US-Dollar für jede Million Input-Token und 150 US-Dollar für jede Million Output-Token, ein starker Kontrast zu den günstigeren GPT-4O, die nur 2,50 USD pro Million Eingangs-Token und 10 USD pro Million Output-Token kostet.
"Wir teilen GPT -4,5 als Forschungsvorschau, um die Stärken und Einschränkungen besser zu verstehen", teilte Openai in einem Blog -Beitrag mit. "Wir untersuchen immer noch sein volles Potenzial und freuen uns zu sehen, wie Menschen es auf unerwartete Weise nutzen werden."
Gemischte Leistung
OpenAI ist klar, dass GPT-4,5 GPT-4O nicht ersetzen soll, ihr Arbeitspferdmodell, das den größten Teil ihrer API und Chatgpt vorantreibt. Während GPT-4.5 Datei- und Image-Uploads verarbeiten und das Canvas-Tool von ChatGPT verwenden kann, unterstützt es derzeit keine Funktionen wie den realistischen Zwei-Wege-Sprachmodus von ChatGPT.
Auf der hellen Seite übertrifft GPT-4,5 GPT-4O und viele andere Modelle auf OpenAIs SimpleQA-Benchmark, die KI-Modelle auf einfachen, sachlichen Fragen testet. OpenAI behauptet auch, dass GPT-4,5 weniger häufig als die meisten Modelle halluziniert, was theoretisch weniger wahrscheinlich die Informationen erfunden sollte.
Interessanterweise enthielt OpenAI nicht eines seiner erstklassigen Argumentationsmodelle, Deep Research, in die SimpleQA-Ergebnisse. Ein OpenAI -Sprecher teilte TechCrunch mit, dass sie die Leistung von Deep Research in diesem Benchmark nicht öffentlich gemeldet haben und es nicht als relevanten Vergleich betrachten. Das Deep-Forschungsmodell von Verwirrlichkeit, das ähnlich wie die tiefen Forschung von Openai zu anderen Benchmarks entspricht, übertrifft jedoch GPT-4,5 bei diesem Test der sachlichen Genauigkeit.
OpenAI rühmt sich auch, dass GPT-4,5 anderen Modellen qualitativ überlegen ist, in Bereichen, die Benchmarks nicht gut erfassen, z. B. das Verständnis der menschlichen Absicht. Sie behaupten, dass GPT-4,5 in einem wärmeren, natürlicheren Ton reagiert und bei kreativen Aufgaben wie Schreiben und Design gut abschneidet.
In einem informellen Test bat Openai GPT-4,5 und zwei weitere Modelle, GPT-4O und O3-Mini, ein Einhorn im SVG-Format zu erstellen. Nur GPT-4,5 gelang es, etwas zu produzieren, das einem Einhorn ähnelt.
"Wir freuen uns darauf, durch diese Veröffentlichung ein vollständigeres Bild der Fähigkeiten von GPT-44 zu erhalten", schrieb Openai in ihrem Blog-Beitrag, "weil wir erkennen, dass akademische Benchmarks nicht immer die nützliche Nützlichkeit der realen Welt widerspiegeln."
Emotionale Intelligenz von GPT-4.5 in Aktion.image Credits: OpenAI Skalierungsgesetze in Frage gestellt
OpenAI behauptet, dass GPT -4,5 "an der Grenze dessen, was im unbeaufsichtigten Lernen möglich ist", stammt. Seine Einschränkungen scheinen jedoch den wachsenden Verdacht der Experten zu unterstützen, dass die sogenannten Skalierungsgesetze der Voraussetzung ihre Grenzen erreichen könnten.
Ilya Sutskever, Mitbegründerin und ehemaliger Chefwissenschaftlerin, erklärte im Dezember, dass "wir Spitzendaten erreicht haben" und dass "die Voraussetzung, wie wir sie wissen, zweifellos enden werden". Seine Kommentare wiederholten die Bedenken, die KI -Investoren, Gründer und Forscher mit TechCrunch im November geteilt hatten.
Als Reaktion auf diese Herausforderungen hat sich die Branche - einschließlich Openai - den Argumentationsmodellen zugewandt, die länger dauern, um Aufgaben auszuführen, aber konsistentere Ergebnisse liefern. AI LABS ist der Ansicht, dass sie die Modellfunktionen erheblich verbessern können.
OpenAI plant, seine GPT-Serie schließlich mit ihrer "O" -Reminaturerie zu verschmelzen, beginnend mit GPT-5 später in diesem Jahr. Trotz seiner hohen Schulungskosten, Verzögerungen und nicht erfüllten internen Erwartungen kann GPT-4,5 die KI-Benchmark-Krone selbst nicht beanspruchen. Aber Openai sieht es wahrscheinlich als einen entscheidenden Schritt in Richtung etwas, das weitaus stärkerer ist.










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um

Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai

Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













