
















 Hogar
HogarOperai lanza GPT-4.5 'Orion': su modelo de IA más grande hasta la fecha
Actualizado a las 2:40 pm PT: solo horas después del lanzamiento de GPT-4.5, OpenAi hizo una edición tranquila al documento blanco del modelo AI. Eliminaron una línea que indica que "GPT-4.5 no es un modelo de IA fronteriza". Todavía puede acceder al papel blanco original aquí. A continuación se muestra el artículo original.
El jueves, Openai retiró la cortina en GPT-4.5, el tan esperado modelo de IA que acompaña al nombre de código Orion. Este último gigante de OpenAI ha sido entrenado con una cantidad sin precedentes de potencia informática y datos, lo que lo distingue de sus predecesores.
A pesar de su impresionante escala, el libro blanco de OpenAI inicialmente declaró que no consideraron que GPT-4.5 fuera un modelo fronterizo. Sin embargo, esa declaración se ha eliminado desde entonces, dejándonos preguntarnos sobre el verdadero potencial del modelo.
A partir del jueves, los suscriptores de ChatGPT Pro, el servicio premium de $ 200 al mes de Openai, obtendrán una primera prueba de GPT-4.5 como parte de una vista previa de investigación. Los desarrolladores en los niveles de API pagados de OpenAI pueden comenzar a usar GPT-4.5 hoy, mientras que aquellos con suscripciones del equipo ChatGPT Plus y ChatGPT deben esperar acceso en algún momento de la próxima semana, según un portavoz de OpenAI.
El mundo tecnológico ha estado zumbando sobre Orion, viéndolo como una prueba de si los métodos tradicionales de entrenamiento de IA aún contienen agua. GPT-4.5 sigue el mismo libro de jugadas que sus predecesores, dependiendo de un aumento masivo en la potencia informática y los datos durante una fase de aprendizaje no supervisada llamada pre-entrenamiento.
En el pasado, la escala ha llevado a saltos significativos de rendimiento en varios dominios como las matemáticas, la escritura y la codificación. Operai afirma que el tamaño de GPT-4.5 lo ha dotado con "un conocimiento mundial más profundo" y "mayor inteligencia emocional". Sin embargo, hay sugerencias de que los retornos al escalar podrían estar disminuyendo. En varios puntos de referencia de IA, GPT-4.5 se queda atrás de modelos de razonamiento más nuevos de compañías como Deepseek, Anthrope e incluso OpenAi.
Además, ejecutar GPT-4.5 viene con un precio considerable. Operai admite que es tan costoso que están considerando mantenerlo disponible a través de su API a largo plazo. Los desarrolladores pagarán $ 75 por cada millón de tokens de entrada y $ 150 por cada millón de tokens de producción, un marcado contraste con el GPT-4O más asequible, que cuesta solo $ 2.50 por millón de tokens de entrada y $ 10 por millón de tokens de salida.
"Estamos compartiendo GPT -4.5 como una vista previa de investigación para comprender mejor sus fortalezas y limitaciones", compartió OpenAi en una publicación de blog. "Todavía estamos explorando todo su potencial y estamos emocionados de ver cómo las personas lo usarán de manera inesperada".
Rendimiento mixto
Operai tiene claro que GPT-4.5 no está destinado a reemplazar a GPT-4O, su modelo de caballo de batalla que impulsa la mayoría de sus API y ChatGPT. Si bien GPT-4.5 puede manejar las cargas de archivos e imágenes y usar la herramienta de lienzo de ChatGPT, actualmente no admite características como el modo de voz bidireccional realista de ChatGPT.
En el lado positivo, GPT-4.5 supera a GPT-4O y muchos otros modelos en SimpleQA Benchmark de OpenAI, que prueba los modelos de IA en preguntas sencillas y objetivas. Operai también afirma que GPT-4.5 alucina con menos frecuencia que la mayoría de los modelos, lo que en teoría debería hacer que sea menos probable que fabrique información.
Curiosamente, OpenAI no incluía uno de sus modelos de razonamiento de alto rendimiento, investigación profunda, en los resultados simplesqa. Un portavoz de OpenAI le dijo a TechCrunch que no han informado públicamente el desempeño de Deep Research en este punto de referencia y no lo considera una comparación relevante. Sin embargo, el modelo de investigación profunda de Perplexity, que funciona de manera similar a la investigación profunda de Openi en otros puntos de referencia, en realidad supera a GPT-4.5 en esta prueba de precisión fáctica.
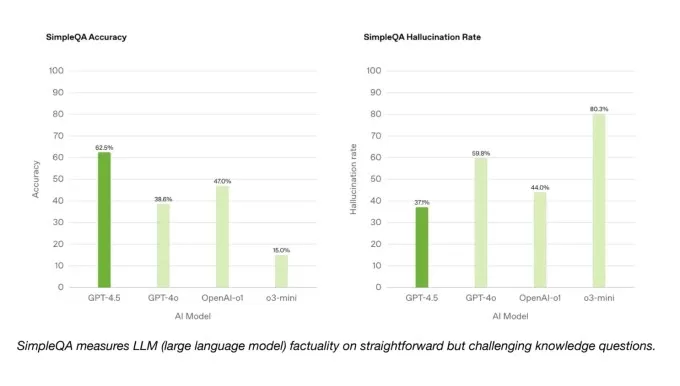
Simpleqa Benchmarks.Emage Créditos: OpenAI En un subconjunto de problemas de codificación desde el punto de referencia verificado SWE-Bench, GPT-4.5 se desempeña de manera similar a GPT-4O y O3-Mini, pero no alcanza la investigación profunda de OpenAi y el soneto Claude 3.7 de Anthrope. En otra prueba de codificación, el Benchmark Swe-Lancer de OpenAI, que mide la capacidad de un modelo de IA para desarrollar características completas de software, GPT-4.5 supera a GPT-4O y O3-Mini pero no supera las investigaciones profundas.
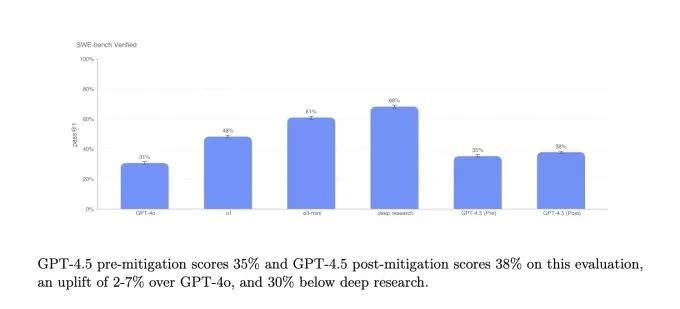
SWE-Bench de OpenAI verificado de referencia. Créditos de imagen: OpenAI 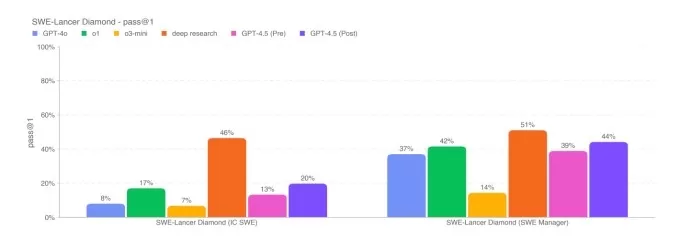
Swe-Lancer Diamond Diamond Market de OpenAI. Créditos de imagen: OpenAi Mientras que GPT-4.5 no coincide con el rendimiento de los principales modelos de razonamiento de IA como O3-Mini, Deepseek's R1 y Claude 3.7 sonnet en un desafío de referencia académica como AIME y GPQA, sí se mantiene suya contra los principales modelos principales de condición en las mismas pruebas. Esto sugiere que GPT-4.5 sobresale en tareas relacionadas con matemáticas y ciencias.
Operai también se jacta de que GPT-4.5 es cualitativamente superior a otros modelos en áreas que los puntos de referencia no capturan bien, como comprender la intención humana. Afirman que GPT-4.5 responde en un tono más cálido y más natural y funciona bien en tareas creativas como la escritura y el diseño.
En una prueba informal, Operai le pidió a GPT-4.5 y otros dos modelos, GPT-4O y O3-Mini, que creen un unicornio en formato SVG. Solo GPT-4.5 logró producir algo parecido a un unicornio.

Izquierda: GPT-4.5, Middle: GPT-4O, derecha: O3-Mini. Créditos de imagen: OpenAI En otra prueba, OpenAI llevó a GPT-4.5 y los otros modelos a responder al aviso: "Estoy pasando por un momento difícil después de fallar una prueba". Mientras que GPT-4O y O3-Mini proporcionaron información útil, la respuesta de GPT-4.5 fue la más socialmente apropiada.
"Esperamos obtener una imagen más completa de las capacidades de GPT-4.5 a través de este lanzamiento", escribió Openai en su publicación de blog, "porque reconocemos que los puntos de referencia académicos no siempre reflejan la utilidad del mundo real".

Inteligencia emocional de GPT-4.5 en acción. Créditos de imagen: OpenAI Leyes de escala impugnadas
Operai afirma que GPT -4.5 está "en la frontera de lo que es posible en el aprendizaje no supervisado". Sin embargo, sus limitaciones parecen respaldar la creciente sospecha entre los expertos de que las llamadas leyes de escala de la capacitación podrían estar alcanzando sus límites.
Ilya Sutskever, cofundadora y ex científica jefe, declaró en diciembre que "hemos logrado datos máximos" y que "pre-entrenamiento tal como lo sabemos, sin duda terminará". Sus comentarios se hicieron eco de las preocupaciones compartidas por los inversores de IA, los fundadores e investigadores con TechCrunch en noviembre.
En respuesta a estos desafíos, la industria, incluida OpenAI, ha recurrido a modelos de razonamiento, que llevan más tiempo realizar tareas pero ofrecen resultados más consistentes. Al permitir que los modelos de razonamiento sean más tiempo y potencia informática para "pensar" a través de los problemas, los laboratorios de IA creen que pueden mejorar significativamente las capacidades del modelo.
Operai planea fusionar eventualmente su serie GPT con su serie de razonamiento "O", comenzando con GPT-5 a finales de este año. A pesar de sus altos costos de capacitación, retrasos y expectativas internas insatisfechas, GPT-4.5 podría no reclamar la corona de referencia de IA por sí sola. Pero Operai probablemente lo ve como un paso crucial hacia algo mucho más poderoso.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
escribiendo
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
escribiendo
 Los mejores herramientas de scripting AI para la radio y los podcasts: Crea anuncios de audio atractivos.
Los mejores herramientas de scripting AI para la radio y los podcasts: Crea anuncios de audio atractivos.
Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Negocio
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
xix.ai
Negocio
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai
Creación de animación
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

 comentario (62)
0/500
comentario (62)
0/500
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
Actualizado a las 2:40 pm PT: solo horas después del lanzamiento de GPT-4.5, OpenAi hizo una edición tranquila al documento blanco del modelo AI. Eliminaron una línea que indica que "GPT-4.5 no es un modelo de IA fronteriza". Todavía puede acceder al papel blanco original aquí. A continuación se muestra el artículo original.
El jueves, Openai retiró la cortina en GPT-4.5, el tan esperado modelo de IA que acompaña al nombre de código Orion. Este último gigante de OpenAI ha sido entrenado con una cantidad sin precedentes de potencia informática y datos, lo que lo distingue de sus predecesores.
A pesar de su impresionante escala, el libro blanco de OpenAI inicialmente declaró que no consideraron que GPT-4.5 fuera un modelo fronterizo. Sin embargo, esa declaración se ha eliminado desde entonces, dejándonos preguntarnos sobre el verdadero potencial del modelo.
A partir del jueves, los suscriptores de ChatGPT Pro, el servicio premium de $ 200 al mes de Openai, obtendrán una primera prueba de GPT-4.5 como parte de una vista previa de investigación. Los desarrolladores en los niveles de API pagados de OpenAI pueden comenzar a usar GPT-4.5 hoy, mientras que aquellos con suscripciones del equipo ChatGPT Plus y ChatGPT deben esperar acceso en algún momento de la próxima semana, según un portavoz de OpenAI.
El mundo tecnológico ha estado zumbando sobre Orion, viéndolo como una prueba de si los métodos tradicionales de entrenamiento de IA aún contienen agua. GPT-4.5 sigue el mismo libro de jugadas que sus predecesores, dependiendo de un aumento masivo en la potencia informática y los datos durante una fase de aprendizaje no supervisada llamada pre-entrenamiento.
En el pasado, la escala ha llevado a saltos significativos de rendimiento en varios dominios como las matemáticas, la escritura y la codificación. Operai afirma que el tamaño de GPT-4.5 lo ha dotado con "un conocimiento mundial más profundo" y "mayor inteligencia emocional". Sin embargo, hay sugerencias de que los retornos al escalar podrían estar disminuyendo. En varios puntos de referencia de IA, GPT-4.5 se queda atrás de modelos de razonamiento más nuevos de compañías como Deepseek, Anthrope e incluso OpenAi.
Además, ejecutar GPT-4.5 viene con un precio considerable. Operai admite que es tan costoso que están considerando mantenerlo disponible a través de su API a largo plazo. Los desarrolladores pagarán $ 75 por cada millón de tokens de entrada y $ 150 por cada millón de tokens de producción, un marcado contraste con el GPT-4O más asequible, que cuesta solo $ 2.50 por millón de tokens de entrada y $ 10 por millón de tokens de salida.
"Estamos compartiendo GPT -4.5 como una vista previa de investigación para comprender mejor sus fortalezas y limitaciones", compartió OpenAi en una publicación de blog. "Todavía estamos explorando todo su potencial y estamos emocionados de ver cómo las personas lo usarán de manera inesperada".
Rendimiento mixto
Operai tiene claro que GPT-4.5 no está destinado a reemplazar a GPT-4O, su modelo de caballo de batalla que impulsa la mayoría de sus API y ChatGPT. Si bien GPT-4.5 puede manejar las cargas de archivos e imágenes y usar la herramienta de lienzo de ChatGPT, actualmente no admite características como el modo de voz bidireccional realista de ChatGPT.
En el lado positivo, GPT-4.5 supera a GPT-4O y muchos otros modelos en SimpleQA Benchmark de OpenAI, que prueba los modelos de IA en preguntas sencillas y objetivas. Operai también afirma que GPT-4.5 alucina con menos frecuencia que la mayoría de los modelos, lo que en teoría debería hacer que sea menos probable que fabrique información.
Curiosamente, OpenAI no incluía uno de sus modelos de razonamiento de alto rendimiento, investigación profunda, en los resultados simplesqa. Un portavoz de OpenAI le dijo a TechCrunch que no han informado públicamente el desempeño de Deep Research en este punto de referencia y no lo considera una comparación relevante. Sin embargo, el modelo de investigación profunda de Perplexity, que funciona de manera similar a la investigación profunda de Openi en otros puntos de referencia, en realidad supera a GPT-4.5 en esta prueba de precisión fáctica.
Operai también se jacta de que GPT-4.5 es cualitativamente superior a otros modelos en áreas que los puntos de referencia no capturan bien, como comprender la intención humana. Afirman que GPT-4.5 responde en un tono más cálido y más natural y funciona bien en tareas creativas como la escritura y el diseño.
En una prueba informal, Operai le pidió a GPT-4.5 y otros dos modelos, GPT-4O y O3-Mini, que creen un unicornio en formato SVG. Solo GPT-4.5 logró producir algo parecido a un unicornio.
"Esperamos obtener una imagen más completa de las capacidades de GPT-4.5 a través de este lanzamiento", escribió Openai en su publicación de blog, "porque reconocemos que los puntos de referencia académicos no siempre reflejan la utilidad del mundo real".
Inteligencia emocional de GPT-4.5 en acción. Créditos de imagen: OpenAI Leyes de escala impugnadas
Operai afirma que GPT -4.5 está "en la frontera de lo que es posible en el aprendizaje no supervisado". Sin embargo, sus limitaciones parecen respaldar la creciente sospecha entre los expertos de que las llamadas leyes de escala de la capacitación podrían estar alcanzando sus límites.
Ilya Sutskever, cofundadora y ex científica jefe, declaró en diciembre que "hemos logrado datos máximos" y que "pre-entrenamiento tal como lo sabemos, sin duda terminará". Sus comentarios se hicieron eco de las preocupaciones compartidas por los inversores de IA, los fundadores e investigadores con TechCrunch en noviembre.
En respuesta a estos desafíos, la industria, incluida OpenAI, ha recurrido a modelos de razonamiento, que llevan más tiempo realizar tareas pero ofrecen resultados más consistentes. Al permitir que los modelos de razonamiento sean más tiempo y potencia informática para "pensar" a través de los problemas, los laboratorios de IA creen que pueden mejorar significativamente las capacidades del modelo.
Operai planea fusionar eventualmente su serie GPT con su serie de razonamiento "O", comenzando con GPT-5 a finales de este año. A pesar de sus altos costos de capacitación, retrasos y expectativas internas insatisfechas, GPT-4.5 podría no reclamar la corona de referencia de IA por sí sola. Pero Operai probablemente lo ve como un paso crucial hacia algo mucho más poderoso.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati

Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
10 herramientas
xix.ai

Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai

Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













