
















 家
家OpenaiはGPT-4.5「Orion」を起動します:これまでの最大のAIモデル
更新された午後2時40分PT:GPT-4.5の発売から数時間後、OpenaiはAIモデルのホワイトペーパーを静かに編集しました。彼らは、「GPT-4.5はフロンティアAIモデルではない」というラインを削除しました。ここで元のホワイトペーパーにアクセスできます。以下は元の記事です。
木曜日に、Openaiは、コード名Orionで行われる非常に予想されるAIモデルであるGPT-4.5でカーテンを引き戻しました。 Openaiのこの最新の巨人は、前例のない量のコンピューティングパワーとデータで訓練されており、前任者とは一線を画しています。
その印象的な規模にもかかわらず、Openaiのホワイトペーパーは当初、GPT-4.5はフロンティアモデルとは見なさなかったと述べました。しかし、その声明はその後削除され、モデルの真の可能性について疑問に思うようになりました。
木曜日から、Openaiのプレミアム200か月間のサービスであるChatGpt Proの購読者は、研究プレビューの一環としてGPT-4.5の最初の味を獲得します。 OpenAIの有料API層の開発者は、今日GPT-4.5の使用を開始できますが、OpenAIの広報担当者によると、ChatGpt PlusとChatGptチームのサブスクリプションを使用している人は来週のいつかアクセスを期待するはずです。
テクノロジーの世界はオリオンについて話題になっており、従来のAIトレーニング方法がまだ水を保持しているかどうかのテストと見なしています。 GPT-4.5は、前任者と同じプレイブックを追跡し、トレーニング前と呼ばれる監視されていない学習段階でのコンピューティングパワーとデータの大幅な増加に依存しています。
過去には、スケールアップにより、数学、執筆、コーディングなどのさまざまなドメインに大きなパフォーマンスが飛躍しました。 Openaiは、GPT-4.5のサイズが「より深い世界の知識」と「より高い感情的知性」を与えたと主張しています。しかし、スケールアップからのリターンが減少する可能性があるというヒントがあります。いくつかのAIベンチマークでは、GPT-4.5は、Deepseek、人類、さらにはOpenai自体などの企業からの新しい推論モデルに遅れをとっています。
さらに、GPT-4.5の実行には多額の値札が付いています。 Openaiは、それが非常に高価であると認めているため、長期的にAPIを通じて利用可能にするかどうかを検討しています。開発者は、入力トークンごとに75ドル、100万の出力トークンごとに150ドルを支払います。これは、より手頃な価格のGPT-4Oとはまったく対照的で、100万ドルあたり2.50ドル、100万ドルあたり10ドルかかります。
「私たちは、GPT -4.5を研究プレビューとして共有して、その強みと制限をよりよく理解するためです」とOpenaiはブログ投稿で共有しています。 「私たちはまだその可能性を最大限に発揮しており、人々が予想外の方法でそれをどのように使用するかを楽しみにしています。」
混合パフォーマンス
Openaiは、GPT-4.5がAPIとChatGPTの大部分を駆動する主力モデルであるGPT-4Oを置き換えることを意図していないことは明らかです。 GPT-4.5はファイルと画像のアップロードを処理し、ChatGPTのCanvasツールを使用できますが、現在、ChatGPTのリアルな双方向の音声モードなどの機能をサポートしていません。
明るい面では、GPT-4.5はGPT-4OとOpenAIのSimpleQAベンチマーク上の他の多くのモデルよりも優れています。また、Openaiは、GPT-4.5がほとんどのモデルよりも頻繁に幻覚の頻度が低いと主張しており、理論的には情報の製造の可能性が低くなるはずです。
興味深いことに、Openaiは、SimpleQAの結果に、そのトップパフォーマンスの推論モデル、ディープリサーチの1つを含めていませんでした。 Openaiの広報担当者はTechCrunchに、このベンチマークでDeep Researchのパフォーマンスを公に報告しておらず、関連する比較とは考えていないと語った。ただし、他のベンチマークに関するOpenaiの深い研究と同様に実行されるPerplexityの深い研究モデルは、実際にこの事実上の精度のテストでGPT-4.5を上回っています。
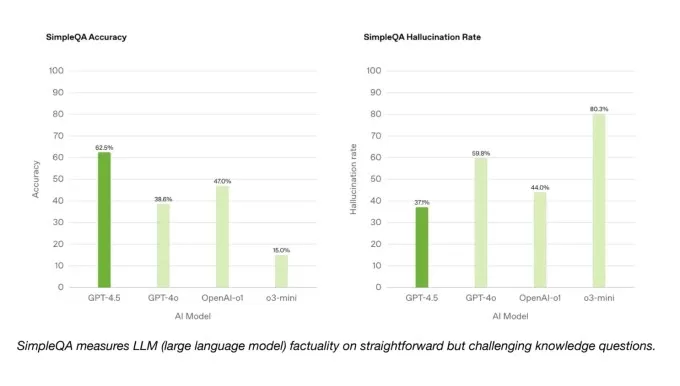
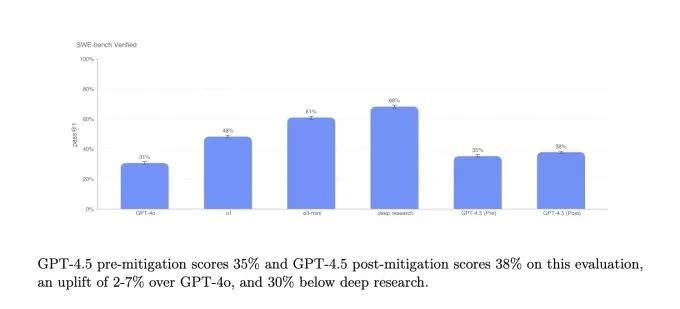
SimpleQA Benchmarks.Imageクレジット:Openai SWEベンチ検証ベンチマークからのコーディング問題のサブセットでは、GPT-4.5はGPT-4OおよびO3-MINIと同様に機能しますが、Openaiの深い研究と人類のClaude 3.7 Sonnetには及ばない。別のコーディングテストでは、完全なソフトウェア機能を開発するAIモデルの能力を測定するOpenAIのSWEランサーベンチマークでは、GPT-4.5はGPT-4OとO3-MINIの両方を上回りますが、深い研究を上回りません。
OpenaiのSWEベンチ検証benchmark.imageクレジット:Openai 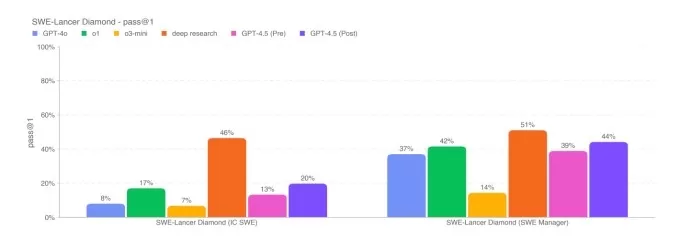
OpenaiのSWE-LANCER DIAMOND BENCHMARK.IMAGE CREDITS:Openai GPT-4.5は、AIAMEやGPQAなどの挑戦的なアカデミックベンチマークでO3-Mini、DeepseekのR1、Claude 3.7 Sonnetなどの主要なAI推論モデルのパフォーマンスとはまったく一致していませんが、同じテストでの主要な非合理的なモデルに対して独自に保持しています。これは、GPT-4.5が数学および科学関連のタスクに優れていることを示唆しています。
Openaiはまた、GPT-4.5が、人間の意図を理解するなど、ベンチマークがうまくキャプチャしない領域の他のモデルよりも定性的に優れていることを誇っています。彼らは、GPT-4.5がより暖かく、より自然なトーンで反応し、執筆やデザインなどの創造的なタスクでうまく機能すると主張しています。
非公式のテストで、OpenaiはGPT-4.5と他の2つのモデルであるGPT-4OとO3-MINIに、SVG形式でユニコーンを作成するように依頼しました。 GPT-4.5のみがユニコーンに似たものを生産することができました。

左:GPT-4.5、ミドル:GPT-4O、右:O3-mini.imageクレジット:Openai 別のテストで、OpenaiはGPT-4.5と他のモデルに「テストに失敗した後、苦労している」プロンプトに応答するように促しました。 GPT-4OとO3-MINIは有用な情報を提供しましたが、GPT-4.5の応答は最も社会的に適切でした。
「このリリースを通じてGPT-4.5の機能のより完全な写真を獲得できることを楽しみにしています」とOpenaiはブログ投稿に書いています。

GPT-4.5のAction.Image Credits:Openai スケーリング法は異議を申し立てました
Openaiは、GPT -4.5は「監視されていない学習で可能なことのフロンティアにある」と主張しています。しかし、その制限は、いわゆるトレーニングのスケーリング法が彼らの限界に達している可能性があるという専門家の間での疑いの高まりを支持しているようです。
Openaiの共同設立者で元チーフサイエンティストのIlya Sutskeverは、12月に「私たちはピークデータを達成した」と「疑いなく終わらせることがわかっているようにトレーニング前」と述べました。彼のコメントは、11月にTechCrunchのAI投資家、創業者、研究者が共有する懸念を反映しています。
これらの課題に対応して、Openaiを含む業界は、タスクを実行するのに時間がかかるが、より一貫した結果を提供するという推論モデルに目を向けています。推論モデルをより多くの時間と計算に問題を介して「考える」ことを許可することにより、AI Labsはモデル機能を大幅に強化できると考えています。
Openaiは、最終的にGPTシリーズを「O」推論シリーズと統合する予定で、今年後半にGPT-5から始まります。トレーニングコストが高く、遅延、内部の期待に満ちていないにもかかわらず、GPT-4.5はAIベンチマーククラウンを単独で請求しない場合があります。しかし、Openaiは、それをはるかに強力なものへの重要なステップと見なしている可能性があります。
関連記事
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
関連特集おすすめ
書き込み
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
関連特集おすすめ
書き込み
 ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
 10 ツール
10 ツール
 xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (62)
0/500
コメント (62)
0/500
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
更新された午後2時40分PT:GPT-4.5の発売から数時間後、OpenaiはAIモデルのホワイトペーパーを静かに編集しました。彼らは、「GPT-4.5はフロンティアAIモデルではない」というラインを削除しました。ここで元のホワイトペーパーにアクセスできます。以下は元の記事です。
木曜日に、Openaiは、コード名Orionで行われる非常に予想されるAIモデルであるGPT-4.5でカーテンを引き戻しました。 Openaiのこの最新の巨人は、前例のない量のコンピューティングパワーとデータで訓練されており、前任者とは一線を画しています。
その印象的な規模にもかかわらず、Openaiのホワイトペーパーは当初、GPT-4.5はフロンティアモデルとは見なさなかったと述べました。しかし、その声明はその後削除され、モデルの真の可能性について疑問に思うようになりました。
木曜日から、Openaiのプレミアム200か月間のサービスであるChatGpt Proの購読者は、研究プレビューの一環としてGPT-4.5の最初の味を獲得します。 OpenAIの有料API層の開発者は、今日GPT-4.5の使用を開始できますが、OpenAIの広報担当者によると、ChatGpt PlusとChatGptチームのサブスクリプションを使用している人は来週のいつかアクセスを期待するはずです。
テクノロジーの世界はオリオンについて話題になっており、従来のAIトレーニング方法がまだ水を保持しているかどうかのテストと見なしています。 GPT-4.5は、前任者と同じプレイブックを追跡し、トレーニング前と呼ばれる監視されていない学習段階でのコンピューティングパワーとデータの大幅な増加に依存しています。
過去には、スケールアップにより、数学、執筆、コーディングなどのさまざまなドメインに大きなパフォーマンスが飛躍しました。 Openaiは、GPT-4.5のサイズが「より深い世界の知識」と「より高い感情的知性」を与えたと主張しています。しかし、スケールアップからのリターンが減少する可能性があるというヒントがあります。いくつかのAIベンチマークでは、GPT-4.5は、Deepseek、人類、さらにはOpenai自体などの企業からの新しい推論モデルに遅れをとっています。
さらに、GPT-4.5の実行には多額の値札が付いています。 Openaiは、それが非常に高価であると認めているため、長期的にAPIを通じて利用可能にするかどうかを検討しています。開発者は、入力トークンごとに75ドル、100万の出力トークンごとに150ドルを支払います。これは、より手頃な価格のGPT-4Oとはまったく対照的で、100万ドルあたり2.50ドル、100万ドルあたり10ドルかかります。
「私たちは、GPT -4.5を研究プレビューとして共有して、その強みと制限をよりよく理解するためです」とOpenaiはブログ投稿で共有しています。 「私たちはまだその可能性を最大限に発揮しており、人々が予想外の方法でそれをどのように使用するかを楽しみにしています。」
混合パフォーマンス
Openaiは、GPT-4.5がAPIとChatGPTの大部分を駆動する主力モデルであるGPT-4Oを置き換えることを意図していないことは明らかです。 GPT-4.5はファイルと画像のアップロードを処理し、ChatGPTのCanvasツールを使用できますが、現在、ChatGPTのリアルな双方向の音声モードなどの機能をサポートしていません。
明るい面では、GPT-4.5はGPT-4OとOpenAIのSimpleQAベンチマーク上の他の多くのモデルよりも優れています。また、Openaiは、GPT-4.5がほとんどのモデルよりも頻繁に幻覚の頻度が低いと主張しており、理論的には情報の製造の可能性が低くなるはずです。
興味深いことに、Openaiは、SimpleQAの結果に、そのトップパフォーマンスの推論モデル、ディープリサーチの1つを含めていませんでした。 Openaiの広報担当者はTechCrunchに、このベンチマークでDeep Researchのパフォーマンスを公に報告しておらず、関連する比較とは考えていないと語った。ただし、他のベンチマークに関するOpenaiの深い研究と同様に実行されるPerplexityの深い研究モデルは、実際にこの事実上の精度のテストでGPT-4.5を上回っています。
Openaiはまた、GPT-4.5が、人間の意図を理解するなど、ベンチマークがうまくキャプチャしない領域の他のモデルよりも定性的に優れていることを誇っています。彼らは、GPT-4.5がより暖かく、より自然なトーンで反応し、執筆やデザインなどの創造的なタスクでうまく機能すると主張しています。
非公式のテストで、OpenaiはGPT-4.5と他の2つのモデルであるGPT-4OとO3-MINIに、SVG形式でユニコーンを作成するように依頼しました。 GPT-4.5のみがユニコーンに似たものを生産することができました。
「このリリースを通じてGPT-4.5の機能のより完全な写真を獲得できることを楽しみにしています」とOpenaiはブログ投稿に書いています。
GPT-4.5のAction.Image Credits:Openai スケーリング法は異議を申し立てました
Openaiは、GPT -4.5は「監視されていない学習で可能なことのフロンティアにある」と主張しています。しかし、その制限は、いわゆるトレーニングのスケーリング法が彼らの限界に達している可能性があるという専門家の間での疑いの高まりを支持しているようです。
Openaiの共同設立者で元チーフサイエンティストのIlya Sutskeverは、12月に「私たちはピークデータを達成した」と「疑いなく終わらせることがわかっているようにトレーニング前」と述べました。彼のコメントは、11月にTechCrunchのAI投資家、創業者、研究者が共有する懸念を反映しています。
これらの課題に対応して、Openaiを含む業界は、タスクを実行するのに時間がかかるが、より一貫した結果を提供するという推論モデルに目を向けています。推論モデルをより多くの時間と計算に問題を介して「考える」ことを許可することにより、AI Labsはモデル機能を大幅に強化できると考えています。
Openaiは、最終的にGPTシリーズを「O」推論シリーズと統合する予定で、今年後半にGPT-5から始まります。トレーニングコストが高く、遅延、内部の期待に満ちていないにもかかわらず、GPT-4.5はAIベンチマーククラウンを単独で請求しない場合があります。しかし、Openaiは、それをはるかに強力なものへの重要なステップと見なしている可能性があります。










 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
 グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ

XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













