
















 집
집OpenAi는 GPT-4.5 'Orion'을 출시합니다 : 현재까지 가장 큰 AI 모델
오후 2시 40 분 PT : GPT-4.5가 출시 된 지 몇 시간 만에 Openai는 AI 모델의 백서를 조용히 편집했습니다. 그들은 "GPT-4.5가 프론티어 AI 모델이 아니다"라는 라인을 제거했다. 여기에서는 여전히 원래 백서에 액세스 할 수 있습니다. 아래는 원본 기사입니다.
목요일에 Openai는 코드 이름 Orion이 진행되는 많은 기대 AI 모델 인 GPT-4.5의 커튼을 뒤로 당겼습니다. Openai 의이 최신 거대는 전례없는 양의 컴퓨팅 능력 및 데이터로 교육을 받았으며 전임자와 구별됩니다.
인상적인 규모에도 불구하고 Openai의 백서는 처음에 GPT-4.5를 프론티어 모델로 간주하지 않았다고 말했습니다. 그러나 그 진술은 이후에 제거되어 모델의 진정한 잠재력에 대해 궁금해하게됩니다.
목요일부터 OpenAi의 프리미엄 $ 200에서 1 개월 동안 서비스 인 Chatgpt Pro의 가입자는 연구 미리보기의 일환으로 GPT-4.5의 첫 맛을 얻을 것입니다. OpenAI 대변인에 따르면 OpenAI의 유료 API 계층의 개발자는 오늘 GPT-4.5를 사용하기 시작할 수있는 반면, 다음 주에 ChatGpt Plus 및 ChatGpt 팀 구독을 가진 사람들은 다음 주 언젠가 액세스 할 것으로 예상됩니다.
기술 세계는 오리온에 대해 윙윙 거리고 있으며, 전통적인 AI 훈련 방법이 여전히 물을 담고 있는지 여부를 테스트했습니다. GPT-4.5는 전임자와 동일한 플레이 북을 따르며, 미리 훈련이라는 감독되지 않은 학습 단계에서 컴퓨팅 능력과 데이터의 대규모 증가에 의존합니다.
과거에는 스케일링을 통해 수학, 작문 및 코딩과 같은 다양한 영역에서 상당한 성능이 도약했습니다. Openai는 GPT-4.5의 규모가 "더 깊은 세계 지식"과 "높은 감성 지능"을 부여했다고 주장합니다. 그러나 스케일링으로 인한 수익이 줄어들 수 있다는 힌트가 있습니다. 여러 AI 벤치 마크에서 GPT-4.5는 DeepSeek, Anthropic 및 OpenAi 자체와 같은 회사의 새로운 추론 모델보다 뒤떨어집니다.
또한 GPT-4.5를 실행하면 가격이 무거운 가격표가 제공됩니다. Openai는 너무 비싸서 장기적으로 API를 통해 사용할 수 있는지 고려하고 있다고 인정합니다. 개발자는 백만 입력 토큰마다 75 달러, 백만 출력 토큰마다 150 달러를 지불 할 것입니다. 이는 저렴한 GPT-4O와는 대조적으로 백만 달러당 2.50 달러, 출력 토큰 당 100 만 달러의 비용이 듭니다.
Openai는 블로그 게시물에서 "우리는 GPT -4.5를 연구 미리보기로 공유하고있다"고 블로그 게시물에서 공유했다. "우리는 여전히 잠재력을 최대한 활용하고 있으며 사람들이 어떻게 예상치 못한 방식으로 그것을 사용할 것인지를보고 기쁘게 생각합니다."
혼합 성능
Openai는 GPT-4.5가 대부분의 API와 ChatGpt를 운전하는 작업자 모델 인 GPT-4O를 대체하기위한 것이 아니라는 것이 분명합니다. GPT-4.5는 파일 및 이미지 업로드를 처리하고 chatgpt의 캔버스 도구를 사용할 수 있지만 현재 Chatgpt의 현실적인 양방향 음성 모드와 같은 기능을 지원하지 않습니다.
밝은면에서 GPT-4.5는 OpenAI의 SimpleQA 벤치 마크에서 GPT-4O 및 기타 많은 모델을 능가하며, 이는 AI 모델을 간단하고 사실적인 질문에 대해 테스트합니다. Openai는 또한 GPT-4.5가 대부분의 모델보다 덜 빈번하게 환각한다고 주장하며, 이론적으로 정보를 제작할 가능성이 줄어 듭니다.
흥미롭게도 OpenAi는 단순한 QA 결과에 최고 성능의 추론 모델 중 하나 인 Deep Research를 포함하지 않았습니다. Openai 대변인은 TechCrunch 에게이 벤치 마크에서 Deep Research의 성과를 공개적으로보고하지 않았으며이를 관련 비교로 생각하지 않는다고 말했습니다. 그러나 다른 벤치 마크에 대한 OpenAi의 깊은 연구와 유사하게 수행되는 Perplexity의 딥 리서치 모델은 실제로이 사실 정확도 테스트에서 GPT-4.5를 능가합니다.
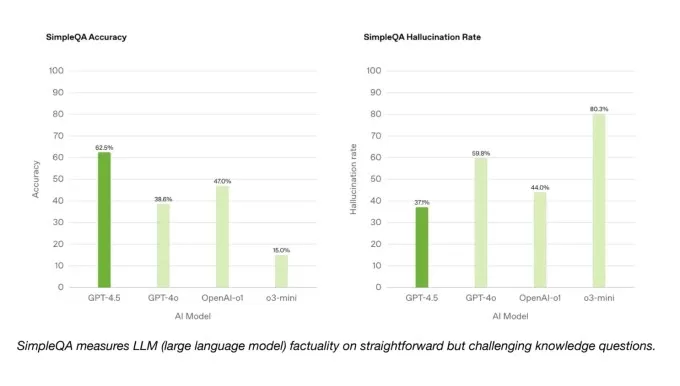
SimpleQA 벤치 마크.이 이미지 크레딧 : OpenAi SWE-Bench Verified Benchmark의 코딩 문제의 하위 집합에서 GPT-4.5는 GPT-4O 및 O3-MINI와 유사하게 수행하지만 OpenAi의 깊은 연구 및 Anthropic의 Claude 3.7 Sonnet에 미치지 못합니다. 또 다른 코딩 테스트에서 AI 모델의 전체 소프트웨어 기능을 개발하는 능력을 측정하는 OpenAi의 SWE-Lancer 벤치 마크는 GPT-4O와 O3-MINI를 능가하지만 깊은 연구를 능가하지 않습니다.
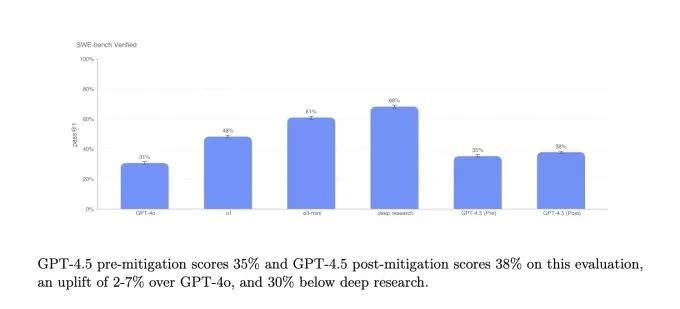
OpenAi의 SWE-Bench 확인 벤치 마크. 이미지 크레딧 : OpenAi 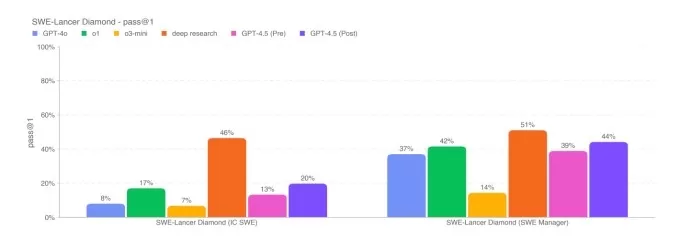
OpenAi의 SWE-Lancer Diamond Benchmark. Image Credits : OpenAi GPT-4.5는 AIME 및 GPQA와 같은 학업 벤치 마크에 대한 O3-MINI, DeepSeek 's R1 및 Claude 3.7 Sonnet과 같은 주요 AI 추론 모델의 성능과 일치하지 않지만 동일한 테스트에서 비 합리적 인 모델에 대해 자체적으로 보유하고 있습니다. 이것은 GPT-4.5가 수학 및 과학 관련 작업에서 탁월하다는 것을 시사합니다.
OpenAi는 또한 GPT-4.5가 벤치 마크가 인간의 의도를 이해하는 것과 같이 잘 캡처하지 않는 영역의 다른 모델보다 질적으로 우수하다는 것을 자랑합니다. 그들은 GPT-4.5가 더 따뜻하고 자연스러운 톤으로 반응하며 글쓰기와 디자인과 같은 창의적인 작업에서 잘 수행한다고 주장합니다.
비공식 테스트에서 OpenAI는 GPT-4.5와 다른 두 가지 모델 인 GPT-4O와 O3-MINI에게 SVG 형식의 유니콘을 만들도록 요청했습니다. GPT-4.5만이 유니콘과 비슷한 것을 생산할 수있었습니다.

왼쪽 : GPT-4.5, 중간 : GPT-4O, 오른쪽 : O3-MINI.IMAGE 크레딧 : OpenAi 다른 테스트에서 OpenAi는 GPT-4.5와 다른 모델이 프롬프트에 응답하라는 메시지를 표시했습니다. "테스트에 실패한 후 힘든 시간을 거칩니다." GPT-4O와 O3-MINI는 유용한 정보를 제공했지만 GPT-4.5의 반응이 가장 사회적으로 적절했습니다.
Openai는 "우리는이 릴리스를 통해 GPT-4.5의 기능에 대한보다 완전한 그림을 얻을 수 있기를 기대합니다."Openai는 블로그 게시물에 다음과 같이 썼습니다.

GPT-4.5의 감정 지능 행동. 이미지 크레딧 : OpenAi 스케일링 법률 도전
Openai는 GPT -4.5가 "감독되지 않은 학습에서 가능한 것의 국경에있다"고 주장했다. 그러나 그 한계는 사전 훈련의 소위 스케일링 법칙이 그들의 한계에 도달 할 수 있다는 전문가들 사이의 의심이 커지는 것을 뒷받침하는 것으로 보인다.
Openai의 공동 창립자이자 전 최고 과학자 인 Ilya Sutskever는 12 월에 "우리는 피크 데이터를 달성했으며"우리는 그것이 의심 할 여지없이 끝날 것입니다. "라고 말했습니다. 그의 의견은 11 월에 AI 투자자, 설립자 및 연구원이 TechCrunch의 연구원이 공유 한 우려를 반영했습니다.
이러한 과제에 대한 응답으로 OpenAI를 포함한 업계는 추론 모델로 바뀌었고, 이는 작업을 수행하는 데 시간이 더 걸리지 만보다 일관된 결과를 제공합니다. AI Labs는 추론 모델에 더 많은 시간과 컴퓨팅 능력을 "생각"할 수 있도록함으로써 모델 기능을 크게 향상시킬 수 있다고 생각합니다.
OpenAI는 올해 말 GPT-5부터 시작하여 GPT 시리즈를 "O"추론 시리즈와 합병 할 계획입니다. 높은 교육 비용, 지연 및 충족되지 않은 내부 기대에도 불구하고 GPT-4.5는 AI 벤치 마크 크라운을 자체적으로 주장하지 않을 수 있습니다. 그러나 Openai는 그것을 훨씬 더 강력한 것을 향한 중요한 단계로 볼 수 있습니다.
관련 기사
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
관련 특별 주제 추천
사업
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
관련 특별 주제 추천
사업
 최고의 AI 계약서 검토 소프트웨어: 법적 허점과 규정 준수 위험을 즉시 파악하세요
최고의 AI 계약서 검토 소프트웨어: 법적 허점과 규정 준수 위험을 즉시 파악하세요
XIX.AI에서 2026년 최고의 AI 계약서 검토 소프트웨어를 만나보세요. 엄선된 최고 평점 목록에는 법적 허점과 규정 준수 위험을 즉시 파악하는 강력한 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 안전하고 효율적인 계약서 분석을 위한 획기적인 솔루션을 찾아보세요. 지금 바로 이 결정적인 가이드를 확인해 보세요.
 10 도구
10 도구
 xix.ai
애니메이션 제작
동화를 위한 AI 애니메이션 생성기: 웹 소설 캐릭터 및 코믹 아바타 제작하기
xix.ai
애니메이션 제작
동화를 위한 AI 애니메이션 생성기: 웹 소설 캐릭터 및 코믹 아바타 제작하기
2026년 최고의 동화용 AI 애니메이션 제작 도구를 발견해 보세요. 저희가 엄선한 이 목록에는 멋진 웹소설 캐릭터와 코믹 아바타를 만들 수 있는 강력한 도구들이 포함되어 있습니다. 무료 옵션과 유료 옵션을 실제 사용 테스트를 통해 비교해 보세요. XIX.AI에서 여러분에게 가장 적합한 창작 도구를 찾아내고 오늘 바로 여러분의 이야기를 현실로 만들어 보세요.
10 도구
xix.ai
만화 창작
만화용 최고의 AI 자동 채색 도구: 일관성 오류 없이 플랫 컬러 적용하기
XIX.AI에서 2026년 최고의 만화 AI 자동 채색 도구를 만나보세요. 저희가 엄선한 이 목록에는 일관성 오류 없이 평면 색상을 적용하여 생산성을 높여주는, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인하여 여러분에게 딱 맞는 도구를 찾아보세요. 지금 바로 AI의 힘을 경험해 보세요.
10 도구
xix.ai
글쓰기
최고의 AI 소설 캐릭터 생성기: 일관된 캐릭터 동기와 치명적인 결점 생성
깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
10 도구
xix.ai
사업
최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai
암호
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

 의견 (62)
0/500
의견 (62)
0/500
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
오후 2시 40 분 PT : GPT-4.5가 출시 된 지 몇 시간 만에 Openai는 AI 모델의 백서를 조용히 편집했습니다. 그들은 "GPT-4.5가 프론티어 AI 모델이 아니다"라는 라인을 제거했다. 여기에서는 여전히 원래 백서에 액세스 할 수 있습니다. 아래는 원본 기사입니다.
목요일에 Openai는 코드 이름 Orion이 진행되는 많은 기대 AI 모델 인 GPT-4.5의 커튼을 뒤로 당겼습니다. Openai 의이 최신 거대는 전례없는 양의 컴퓨팅 능력 및 데이터로 교육을 받았으며 전임자와 구별됩니다.
인상적인 규모에도 불구하고 Openai의 백서는 처음에 GPT-4.5를 프론티어 모델로 간주하지 않았다고 말했습니다. 그러나 그 진술은 이후에 제거되어 모델의 진정한 잠재력에 대해 궁금해하게됩니다.
목요일부터 OpenAi의 프리미엄 $ 200에서 1 개월 동안 서비스 인 Chatgpt Pro의 가입자는 연구 미리보기의 일환으로 GPT-4.5의 첫 맛을 얻을 것입니다. OpenAI 대변인에 따르면 OpenAI의 유료 API 계층의 개발자는 오늘 GPT-4.5를 사용하기 시작할 수있는 반면, 다음 주에 ChatGpt Plus 및 ChatGpt 팀 구독을 가진 사람들은 다음 주 언젠가 액세스 할 것으로 예상됩니다.
기술 세계는 오리온에 대해 윙윙 거리고 있으며, 전통적인 AI 훈련 방법이 여전히 물을 담고 있는지 여부를 테스트했습니다. GPT-4.5는 전임자와 동일한 플레이 북을 따르며, 미리 훈련이라는 감독되지 않은 학습 단계에서 컴퓨팅 능력과 데이터의 대규모 증가에 의존합니다.
과거에는 스케일링을 통해 수학, 작문 및 코딩과 같은 다양한 영역에서 상당한 성능이 도약했습니다. Openai는 GPT-4.5의 규모가 "더 깊은 세계 지식"과 "높은 감성 지능"을 부여했다고 주장합니다. 그러나 스케일링으로 인한 수익이 줄어들 수 있다는 힌트가 있습니다. 여러 AI 벤치 마크에서 GPT-4.5는 DeepSeek, Anthropic 및 OpenAi 자체와 같은 회사의 새로운 추론 모델보다 뒤떨어집니다.
또한 GPT-4.5를 실행하면 가격이 무거운 가격표가 제공됩니다. Openai는 너무 비싸서 장기적으로 API를 통해 사용할 수 있는지 고려하고 있다고 인정합니다. 개발자는 백만 입력 토큰마다 75 달러, 백만 출력 토큰마다 150 달러를 지불 할 것입니다. 이는 저렴한 GPT-4O와는 대조적으로 백만 달러당 2.50 달러, 출력 토큰 당 100 만 달러의 비용이 듭니다.
Openai는 블로그 게시물에서 "우리는 GPT -4.5를 연구 미리보기로 공유하고있다"고 블로그 게시물에서 공유했다. "우리는 여전히 잠재력을 최대한 활용하고 있으며 사람들이 어떻게 예상치 못한 방식으로 그것을 사용할 것인지를보고 기쁘게 생각합니다."
혼합 성능
Openai는 GPT-4.5가 대부분의 API와 ChatGpt를 운전하는 작업자 모델 인 GPT-4O를 대체하기위한 것이 아니라는 것이 분명합니다. GPT-4.5는 파일 및 이미지 업로드를 처리하고 chatgpt의 캔버스 도구를 사용할 수 있지만 현재 Chatgpt의 현실적인 양방향 음성 모드와 같은 기능을 지원하지 않습니다.
밝은면에서 GPT-4.5는 OpenAI의 SimpleQA 벤치 마크에서 GPT-4O 및 기타 많은 모델을 능가하며, 이는 AI 모델을 간단하고 사실적인 질문에 대해 테스트합니다. Openai는 또한 GPT-4.5가 대부분의 모델보다 덜 빈번하게 환각한다고 주장하며, 이론적으로 정보를 제작할 가능성이 줄어 듭니다.
흥미롭게도 OpenAi는 단순한 QA 결과에 최고 성능의 추론 모델 중 하나 인 Deep Research를 포함하지 않았습니다. Openai 대변인은 TechCrunch 에게이 벤치 마크에서 Deep Research의 성과를 공개적으로보고하지 않았으며이를 관련 비교로 생각하지 않는다고 말했습니다. 그러나 다른 벤치 마크에 대한 OpenAi의 깊은 연구와 유사하게 수행되는 Perplexity의 딥 리서치 모델은 실제로이 사실 정확도 테스트에서 GPT-4.5를 능가합니다.
OpenAi는 또한 GPT-4.5가 벤치 마크가 인간의 의도를 이해하는 것과 같이 잘 캡처하지 않는 영역의 다른 모델보다 질적으로 우수하다는 것을 자랑합니다. 그들은 GPT-4.5가 더 따뜻하고 자연스러운 톤으로 반응하며 글쓰기와 디자인과 같은 창의적인 작업에서 잘 수행한다고 주장합니다.
비공식 테스트에서 OpenAI는 GPT-4.5와 다른 두 가지 모델 인 GPT-4O와 O3-MINI에게 SVG 형식의 유니콘을 만들도록 요청했습니다. GPT-4.5만이 유니콘과 비슷한 것을 생산할 수있었습니다.
Openai는 "우리는이 릴리스를 통해 GPT-4.5의 기능에 대한보다 완전한 그림을 얻을 수 있기를 기대합니다."Openai는 블로그 게시물에 다음과 같이 썼습니다.
GPT-4.5의 감정 지능 행동. 이미지 크레딧 : OpenAi 스케일링 법률 도전
Openai는 GPT -4.5가 "감독되지 않은 학습에서 가능한 것의 국경에있다"고 주장했다. 그러나 그 한계는 사전 훈련의 소위 스케일링 법칙이 그들의 한계에 도달 할 수 있다는 전문가들 사이의 의심이 커지는 것을 뒷받침하는 것으로 보인다.
Openai의 공동 창립자이자 전 최고 과학자 인 Ilya Sutskever는 12 월에 "우리는 피크 데이터를 달성했으며"우리는 그것이 의심 할 여지없이 끝날 것입니다. "라고 말했습니다. 그의 의견은 11 월에 AI 투자자, 설립자 및 연구원이 TechCrunch의 연구원이 공유 한 우려를 반영했습니다.
이러한 과제에 대한 응답으로 OpenAI를 포함한 업계는 추론 모델로 바뀌었고, 이는 작업을 수행하는 데 시간이 더 걸리지 만보다 일관된 결과를 제공합니다. AI Labs는 추론 모델에 더 많은 시간과 컴퓨팅 능력을 "생각"할 수 있도록함으로써 모델 기능을 크게 향상시킬 수 있다고 생각합니다.
OpenAI는 올해 말 GPT-5부터 시작하여 GPT 시리즈를 "O"추론 시리즈와 합병 할 계획입니다. 높은 교육 비용, 지연 및 충족되지 않은 내부 기대에도 불구하고 GPT-4.5는 AI 벤치 마크 크라운을 자체적으로 주장하지 않을 수 있습니다. 그러나 Openai는 그것을 훨씬 더 강력한 것을 향한 중요한 단계로 볼 수 있습니다.










 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
 그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크

XIX.AI에서 2026년 최고의 AI 계약서 검토 소프트웨어를 만나보세요. 엄선된 최고 평점 목록에는 법적 허점과 규정 준수 위험을 즉시 파악하는 강력한 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 안전하고 효율적인 계약서 분석을 위한 획기적인 솔루션을 찾아보세요. 지금 바로 이 결정적인 가이드를 확인해 보세요.
10 도구
xix.ai

2026년 최고의 동화용 AI 애니메이션 제작 도구를 발견해 보세요. 저희가 엄선한 이 목록에는 멋진 웹소설 캐릭터와 코믹 아바타를 만들 수 있는 강력한 도구들이 포함되어 있습니다. 무료 옵션과 유료 옵션을 실제 사용 테스트를 통해 비교해 보세요. XIX.AI에서 여러분에게 가장 적합한 창작 도구를 찾아내고 오늘 바로 여러분의 이야기를 현실로 만들어 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 만화 AI 자동 채색 도구를 만나보세요. 저희가 엄선한 이 목록에는 일관성 오류 없이 평면 색상을 적용하여 생산성을 높여주는, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인하여 여러분에게 딱 맞는 도구를 찾아보세요. 지금 바로 AI의 힘을 경험해 보세요.
10 도구
xix.ai

깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













