
















 Home
HomeOpenAI Launches GPT-4.5 'Orion': Its Biggest AI Model to Date
Updated 2:40 pm PT: Just hours after the launch of GPT-4.5, OpenAI made a quiet edit to the AI model's white paper. They removed a line stating that "GPT-4.5 is not a frontier AI model." You can still access the original white paper here. Below is the original article.
On Thursday, OpenAI pulled back the curtain on GPT-4.5, the much-anticipated AI model that goes by the code name Orion. This latest behemoth from OpenAI has been trained with an unprecedented amount of computing power and data, setting it apart from its predecessors.
Despite its impressive scale, OpenAI's white paper initially stated that they didn't consider GPT-4.5 to be a frontier model. However, that statement has since been removed, leaving us to wonder about the model's true potential.
Starting Thursday, subscribers to ChatGPT Pro, OpenAI's premium $200-a-month service, will get a first taste of GPT-4.5 as part of a research preview. Developers on OpenAI's paid API tiers can start using GPT-4.5 today, while those with ChatGPT Plus and ChatGPT Team subscriptions should expect access sometime next week, according to an OpenAI spokesperson.
The tech world has been buzzing about Orion, viewing it as a test of whether traditional AI training methods still hold water. GPT-4.5 follows the same playbook as its predecessors, relying on a massive increase in computing power and data during an unsupervised learning phase called pre-training.
In the past, scaling up has led to significant performance leaps across various domains like math, writing, and coding. OpenAI claims that GPT-4.5's size has endowed it with "a deeper world knowledge" and "higher emotional intelligence." Yet, there are hints that the returns from scaling up might be diminishing. On several AI benchmarks, GPT-4.5 lags behind newer reasoning models from companies like DeepSeek, Anthropic, and even OpenAI itself.
Moreover, running GPT-4.5 comes with a hefty price tag. OpenAI admits it's so expensive that they're considering whether to keep it available through their API in the long run. Developers will pay $75 for every million input tokens and $150 for every million output tokens, a stark contrast to the more affordable GPT-4o, which costs just $2.50 per million input tokens and $10 per million output tokens.
"We're sharing GPT‐4.5 as a research preview to better understand its strengths and limitations," OpenAI shared in a blog post. "We're still exploring its full potential and are excited to see how people will use it in unexpected ways."
Mixed performance
OpenAI is clear that GPT-4.5 isn't meant to replace GPT-4o, their workhorse model that drives most of their API and ChatGPT. While GPT-4.5 can handle file and image uploads and use ChatGPT's canvas tool, it currently doesn't support features like ChatGPT's realistic two-way voice mode.
On the bright side, GPT-4.5 outperforms GPT-4o and many other models on OpenAI's SimpleQA benchmark, which tests AI models on straightforward, factual questions. OpenAI also claims that GPT-4.5 hallucinates less frequently than most models, which should theoretically make it less likely to fabricate information.
Interestingly, OpenAI didn't include one of its top-performing reasoning models, deep research, in the SimpleQA results. An OpenAI spokesperson told TechCrunch that they haven't publicly reported deep research's performance on this benchmark and don't consider it a relevant comparison. However, Perplexity's Deep Research model, which performs similarly to OpenAI's deep research on other benchmarks, actually outscores GPT-4.5 on this test of factual accuracy.
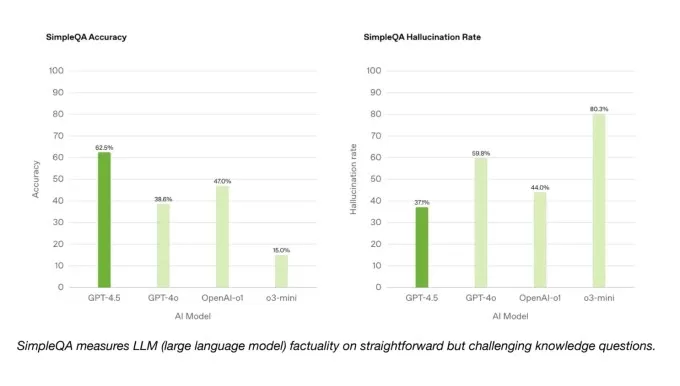
SimpleQA benchmarks.Image Credits:OpenAI On a subset of coding problems from the SWE-Bench Verified benchmark, GPT-4.5 performs similarly to GPT-4o and o3-mini but falls short of OpenAI's deep research and Anthropic's Claude 3.7 Sonnet. On another coding test, OpenAI's SWE-Lancer benchmark, which measures an AI model's ability to develop full software features, GPT-4.5 outperforms both GPT-4o and o3-mini but doesn't surpass deep research.
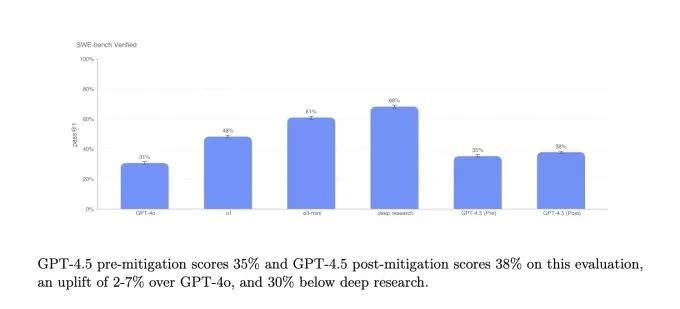
OpenAI’s Swe-Bench verified benchmark.Image Credits:OpenAI 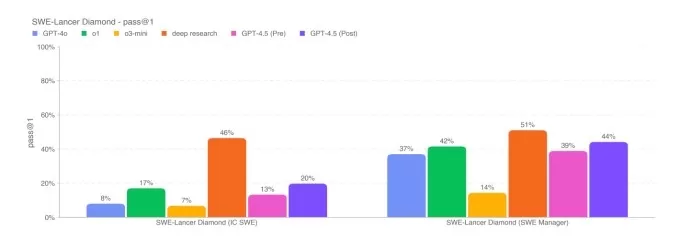
OpenAI’s SWe-Lancer Diamond benchmark.Image Credits:OpenAI While GPT-4.5 doesn't quite match the performance of leading AI reasoning models like o3-mini, DeepSeek's R1, and Claude 3.7 Sonnet on challenging academic benchmarks like AIME and GPQA, it does hold its own against leading non-reasoning models on the same tests. This suggests that GPT-4.5 excels in math- and science-related tasks.
OpenAI also boasts that GPT-4.5 is qualitatively superior to other models in areas that benchmarks don't capture well, such as understanding human intent. They claim that GPT-4.5 responds in a warmer, more natural tone and performs well on creative tasks like writing and design.
In an informal test, OpenAI asked GPT-4.5 and two other models, GPT-4o and o3-mini, to create a unicorn in SVG format. Only GPT-4.5 managed to produce something resembling a unicorn.

left: GPT-4.5, Middle: GPT-4o, RIGHT: o3-mini.Image Credits:OpenAI In another test, OpenAI prompted GPT-4.5 and the other models to respond to the prompt, "I'm going through a tough time after failing a test." While GPT-4o and o3-mini provided helpful information, GPT-4.5's response was the most socially appropriate.
"We look forward to gaining a more complete picture of GPT-4.5's capabilities through this release," OpenAI wrote in their blog post, "because we recognize that academic benchmarks don't always reflect real-world usefulness."

GPT-4.5’s emotional intelligence in action.Image Credits:OpenAI Scaling laws challenged
OpenAI claims that GPT‐4.5 is "at the frontier of what is possible in unsupervised learning." Yet, its limitations seem to support the growing suspicion among experts that the so-called scaling laws of pre-training might be reaching their limits.
Ilya Sutskever, OpenAI co-founder and former chief scientist, stated in December that "we've achieved peak data" and that "pre-training as we know it will unquestionably end." His comments echoed the concerns shared by AI investors, founders, and researchers with TechCrunch in November.
In response to these challenges, the industry—including OpenAI—has turned to reasoning models, which take longer to perform tasks but offer more consistent results. By allowing reasoning models more time and computing power to "think" through problems, AI labs believe they can significantly enhance model capabilities.
OpenAI plans to eventually merge its GPT series with its "o" reasoning series, starting with GPT-5 later this year. Despite its high training costs, delays, and unmet internal expectations, GPT-4.5 might not claim the AI benchmark crown on its own. But OpenAI likely sees it as a crucial step toward something far more powerful.
Related article
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
Animation Creation
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
Animation Creation
 AI Anime Generator for Donghua: Create Web Novel Characters & Comic Avatars
AI Anime Generator for Donghua: Create Web Novel Characters & Comic Avatars
Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
 10 tools
10 tools
 xix.ai
Comic Creation
Top AI Auto-Colorization Tools for Manga: Apply Flat Colors with Zero Consistency Errors
xix.ai
Comic Creation
Top AI Auto-Colorization Tools for Manga: Apply Flat Colors with Zero Consistency Errors
Discover the 2026 best AI auto-colorization tools for manga at XIX.AI. Our curated list features top-rated, game-changing solutions that apply flat colors with zero consistency errors, boosting your productivity. Explore free vs paid comparisons, real-world tests, and weekly updated rankings to find your perfect match. Unlock your AI edge today.
10 tools
xix.ai
writing
Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai
code
Best AI Code Reviewers: Automate Clean Code Compliance & Refactor Legacy Repo Files
Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai
Text-to-speech
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

 Comments (62)
0/500
Comments (62)
0/500
![JonathanMiller]()
Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
![GeorgeCarter]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
![BruceWilson]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
![BruceBrown]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
![JeffreyRamirez]()
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
![RalphPerez]()
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.
Updated 2:40 pm PT: Just hours after the launch of GPT-4.5, OpenAI made a quiet edit to the AI model's white paper. They removed a line stating that "GPT-4.5 is not a frontier AI model." You can still access the original white paper here. Below is the original article.
On Thursday, OpenAI pulled back the curtain on GPT-4.5, the much-anticipated AI model that goes by the code name Orion. This latest behemoth from OpenAI has been trained with an unprecedented amount of computing power and data, setting it apart from its predecessors.
Despite its impressive scale, OpenAI's white paper initially stated that they didn't consider GPT-4.5 to be a frontier model. However, that statement has since been removed, leaving us to wonder about the model's true potential.
Starting Thursday, subscribers to ChatGPT Pro, OpenAI's premium $200-a-month service, will get a first taste of GPT-4.5 as part of a research preview. Developers on OpenAI's paid API tiers can start using GPT-4.5 today, while those with ChatGPT Plus and ChatGPT Team subscriptions should expect access sometime next week, according to an OpenAI spokesperson.
The tech world has been buzzing about Orion, viewing it as a test of whether traditional AI training methods still hold water. GPT-4.5 follows the same playbook as its predecessors, relying on a massive increase in computing power and data during an unsupervised learning phase called pre-training.
In the past, scaling up has led to significant performance leaps across various domains like math, writing, and coding. OpenAI claims that GPT-4.5's size has endowed it with "a deeper world knowledge" and "higher emotional intelligence." Yet, there are hints that the returns from scaling up might be diminishing. On several AI benchmarks, GPT-4.5 lags behind newer reasoning models from companies like DeepSeek, Anthropic, and even OpenAI itself.
Moreover, running GPT-4.5 comes with a hefty price tag. OpenAI admits it's so expensive that they're considering whether to keep it available through their API in the long run. Developers will pay $75 for every million input tokens and $150 for every million output tokens, a stark contrast to the more affordable GPT-4o, which costs just $2.50 per million input tokens and $10 per million output tokens.
"We're sharing GPT‐4.5 as a research preview to better understand its strengths and limitations," OpenAI shared in a blog post. "We're still exploring its full potential and are excited to see how people will use it in unexpected ways."
Mixed performance
OpenAI is clear that GPT-4.5 isn't meant to replace GPT-4o, their workhorse model that drives most of their API and ChatGPT. While GPT-4.5 can handle file and image uploads and use ChatGPT's canvas tool, it currently doesn't support features like ChatGPT's realistic two-way voice mode.
On the bright side, GPT-4.5 outperforms GPT-4o and many other models on OpenAI's SimpleQA benchmark, which tests AI models on straightforward, factual questions. OpenAI also claims that GPT-4.5 hallucinates less frequently than most models, which should theoretically make it less likely to fabricate information.
Interestingly, OpenAI didn't include one of its top-performing reasoning models, deep research, in the SimpleQA results. An OpenAI spokesperson told TechCrunch that they haven't publicly reported deep research's performance on this benchmark and don't consider it a relevant comparison. However, Perplexity's Deep Research model, which performs similarly to OpenAI's deep research on other benchmarks, actually outscores GPT-4.5 on this test of factual accuracy.
OpenAI also boasts that GPT-4.5 is qualitatively superior to other models in areas that benchmarks don't capture well, such as understanding human intent. They claim that GPT-4.5 responds in a warmer, more natural tone and performs well on creative tasks like writing and design.
In an informal test, OpenAI asked GPT-4.5 and two other models, GPT-4o and o3-mini, to create a unicorn in SVG format. Only GPT-4.5 managed to produce something resembling a unicorn.
"We look forward to gaining a more complete picture of GPT-4.5's capabilities through this release," OpenAI wrote in their blog post, "because we recognize that academic benchmarks don't always reflect real-world usefulness."
GPT-4.5’s emotional intelligence in action.Image Credits:OpenAI Scaling laws challenged
OpenAI claims that GPT‐4.5 is "at the frontier of what is possible in unsupervised learning." Yet, its limitations seem to support the growing suspicion among experts that the so-called scaling laws of pre-training might be reaching their limits.
Ilya Sutskever, OpenAI co-founder and former chief scientist, stated in December that "we've achieved peak data" and that "pre-training as we know it will unquestionably end." His comments echoed the concerns shared by AI investors, founders, and researchers with TechCrunch in November.
In response to these challenges, the industry—including OpenAI—has turned to reasoning models, which take longer to perform tasks but offer more consistent results. By allowing reasoning models more time and computing power to "think" through problems, AI labs believe they can significantly enhance model capabilities.
OpenAI plans to eventually merge its GPT series with its "o" reasoning series, starting with GPT-5 later this year. Despite its high training costs, delays, and unmet internal expectations, GPT-4.5 might not claim the AI benchmark crown on its own. But OpenAI likely sees it as a crucial step toward something far more powerful.










 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
 Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont

Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI auto-colorization tools for manga at XIX.AI. Our curated list features top-rated, game-changing solutions that apply flat colors with zero consistency errors, boosting your productivity. Explore free vs paid comparisons, real-world tests, and weekly updated rankings to find your perfect match. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai

Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai

Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Warum ändern die heimlich die Beschreibung? 🤔 Das klingt nach Marketing-Spielchen. GPT-4.5 ist bestimmt stark, aber solche Änderungen machen mich misstrauisch. Wird da etwa die Leistung übertrieben dargestellt?
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re tweaking behind the scenes. 🤔
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky edit to the white paper? Shady move, OpenAI. Makes me wonder what else they're hiding. Still, I'm hyped to see what this model can do! 😎
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows—why hide that it’s not a frontier model? 🤔 Makes me wonder what OpenAI’s cooking behind the scenes!
Wow, GPT-4.5 Orion sounds massive! But that sneaky white paper edit? Shady move, OpenAI. Makes me wonder what else they’re hiding. 🤔 Still, can’t wait to see what this beast can do!
Wow, GPT-4.5 Orion sounds like a beast! But that sneaky white paper edit raises some eyebrows 🤔. Why hide that it’s not a frontier model? Smells like they’re dodging some big questions about what this thing can really do.













