
















 首頁
首頁微軟研究揭示AI模型在軟體除錯中的局限性
來自OpenAI、Anthropic及其他領先AI實驗室的AI模型越來越常用於編碼任務。Google執行長Sundar Pichai於10月表示,AI在公司內生成25%的新程式碼,而Meta執行長Mark Zuckerberg則計劃在這家社群媒體巨頭中廣泛應用AI編碼工具。
然而,即使是表現最佳的模型,在修復軟體錯誤時仍難以達到經驗豐富的開發者輕鬆處理的水平。
微軟研發部門近期進行的微軟研究顯示,像Anthropic的Claude 3.7 Sonnet和OpenAI的o3-mini等模型,在SWE-bench Lite軟體開發基準測試中難以解決許多問題。研究結果顯示,儘管OpenAI等公司提出雄心勃勃的聲明,AI在編碼等領域仍無法與人類專業知識媲美。
研究人員測試了九種模型,作為配備除錯工具(包括Python除錯器)的“單一提示基礎代理”的基礎。該代理被要求處理來自SWE-bench Lite的300個精選軟體除錯挑戰。
結果顯示,即使使用先進模型,代理也很少能成功解決超過一半的任務。Claude 3.7 Sonnet以48.4%的成功率領先,其次是OpenAI的o1為30.2%,以及o3-mini為22.1%。
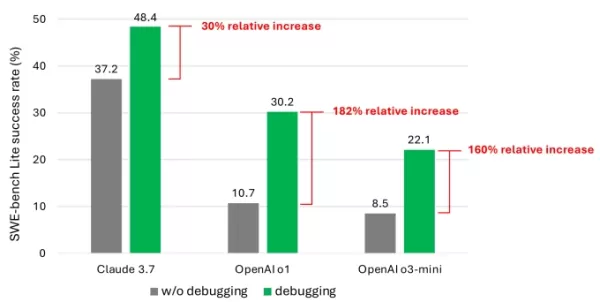
研究中的一張圖表,顯示模型從除錯工具中獲得的性能提升。圖片來源:微軟 為何成果不盡理想?一些模型難以有效使用可用的除錯工具,或無法辨識哪些工具適用於特定問題。研究人員指出,主要問題在於缺乏足夠的訓練數據,特別是捕捉“序列決策過程”的數據,如人類除錯軌跡。
“我們相信,訓練或微調這些模型可以提升其除錯能力,”研究人員寫道。“然而,這需要專門的數據,例如捕捉代理與除錯器互動以收集資訊後提出修復方案的軌跡數據。”
參加TechCrunch Sessions:AI
預訂您在我們頂尖AI行業活動的席位,講者來自OpenAI、Anthropic和Cohere。限時優惠,門票僅需292美元,即可享受全天專家講座、工作坊和 networking 機會。
在TechCrunch Sessions:AI展示
預訂您在TC Sessions:AI的席位,向超過1,200名決策者展示您的作品。展覽機會開放至5月9日或展位全數售罄為止。
這些發現並不令人意外。眾多研究顯示,AI生成的程式碼常因對程式設計邏輯理解的弱點而引入安全漏洞和錯誤。最近對知名AI編碼工具Devin的測試顯示,它僅能完成20個程式設計任務中的3個。
微軟的研究提供了對AI模型這一持續挑戰的最深入檢視之一。雖然這不太可能抑制投資者對AI編碼工具的興趣,但可能促使開發者及其領導者重新考慮過度依賴AI進行編碼任務。
值得注意的是,幾位科技領袖已反對AI將消除編碼工作的觀點。微軟共同創辦人Bill Gates、Replit執行長Amjad Masad、Okta執行長Todd McKinnon和IBM執行長Arvind Krishna均表示對程式設計作為一門職業的持久性充滿信心。
相關文章
 Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
巴里·迪勒:隨著通用人工智慧(AGI)日益臨近,對山姆·奧特曼的信任已無關緊要
儘管近期有報導指出相反的看法,但億萬富翁媒體大亨巴里·迪勒並不認為 OpenAI 執行長山姆·奧特曼不可信。迪勒本週在《華爾街日報》的「萬物未來」會議上發言時,為奧特曼辯護;奧特曼此前曾遭到部分前同事和董事會成員指控,指稱他偶爾會採取操縱和欺騙手段。身為奧特曼好友的迪勒,當時正回應一個關於人們是否應信任奧特曼、以確保人工智慧造福人類的問題。具體而言,提問者探討了被稱為「通用人工智慧」(AGI)的理
YouTube 將 AI 深度偽造偵測功能擴展至政治人物、政府官員及記者
週二,YouTube 宣布將其深度偽造(deepfake)偵測技術擴展至特定群體,包括政府官員、政治候選人及記者。該工具能識別由人工智慧生成的肖像,並允許試點計畫的參與者要求移除其認為違反 YouTube 政策且未經授權的內容。該偵測系統在經過前期測試階段後,去年首度向約 400 萬名 YouTube 合作夥伴計畫的創作者推出。與 YouTube 現有的版權內容識別系統(Content ID)類似
相關專題推薦
教育與學習
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
巴里·迪勒:隨著通用人工智慧(AGI)日益臨近,對山姆·奧特曼的信任已無關緊要
儘管近期有報導指出相反的看法,但億萬富翁媒體大亨巴里·迪勒並不認為 OpenAI 執行長山姆·奧特曼不可信。迪勒本週在《華爾街日報》的「萬物未來」會議上發言時,為奧特曼辯護;奧特曼此前曾遭到部分前同事和董事會成員指控,指稱他偶爾會採取操縱和欺騙手段。身為奧特曼好友的迪勒,當時正回應一個關於人們是否應信任奧特曼、以確保人工智慧造福人類的問題。具體而言,提問者探討了被稱為「通用人工智慧」(AGI)的理
YouTube 將 AI 深度偽造偵測功能擴展至政治人物、政府官員及記者
週二,YouTube 宣布將其深度偽造(deepfake)偵測技術擴展至特定群體,包括政府官員、政治候選人及記者。該工具能識別由人工智慧生成的肖像,並允許試點計畫的參與者要求移除其認為違反 YouTube 政策且未經授權的內容。該偵測系統在經過前期測試階段後,去年首度向約 400 萬名 YouTube 合作夥伴計畫的創作者推出。與 YouTube 現有的版權內容識別系統(Content ID)類似
相關專題推薦
教育與學習
 最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
 10 個工具
10 個工具
 xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai
數據分析
最佳 AI 數據可視化工具:從原始檔案自動生成互動式 BI 儀表板
立即前往 XIX.AI,探索 2026 年最佳 AI 數據可視化工具。我們精心挑選的頂級工具清單,能協助您從原始檔案中即時自動生成強大且互動式的商業智慧儀表板。透過實際測試與每週更新的排行榜,比較免費與付費選項的差異。立即釋放您數據的潛力。
10 個工具
xix.ai
社群媒體
適用於社群媒體的 AI 品牌套件:在所有管道上維持一致的品牌視覺形象
探索 2026 年最適合社群媒體的 AI 品牌設計套件。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,助您在所有管道上維持完美一致的品牌視覺形象。透過實際測試,比較免費與付費選項的差異。立即為您的品牌開啟視覺優勢。
10 個工具
xix.ai
聊天機器人
最佳 AI 女友應用程式與角色扮演用 AI 伴侶工具(2026 年指南)
探索 2026 年最新、評價最高的 AI 伴侶工具,體驗沉浸式的角色扮演與情感連結。XIX.AI 精心策劃的指南收錄了多款功能強大、顛覆傳統的應用程式,內容包含每週更新的排行榜、免費與付費版本的比較,以及實際使用測試。立即找到最適合您的選擇,開啟有意義的數位伴侶體驗。
10 個工具
xix.ai

 評論 (6)
0/500
評論 (6)
0/500
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
來自OpenAI、Anthropic及其他領先AI實驗室的AI模型越來越常用於編碼任務。Google執行長Sundar Pichai於10月表示,AI在公司內生成25%的新程式碼,而Meta執行長Mark Zuckerberg則計劃在這家社群媒體巨頭中廣泛應用AI編碼工具。
然而,即使是表現最佳的模型,在修復軟體錯誤時仍難以達到經驗豐富的開發者輕鬆處理的水平。
微軟研發部門近期進行的微軟研究顯示,像Anthropic的Claude 3.7 Sonnet和OpenAI的o3-mini等模型,在SWE-bench Lite軟體開發基準測試中難以解決許多問題。研究結果顯示,儘管OpenAI等公司提出雄心勃勃的聲明,AI在編碼等領域仍無法與人類專業知識媲美。
研究人員測試了九種模型,作為配備除錯工具(包括Python除錯器)的“單一提示基礎代理”的基礎。該代理被要求處理來自SWE-bench Lite的300個精選軟體除錯挑戰。
結果顯示,即使使用先進模型,代理也很少能成功解決超過一半的任務。Claude 3.7 Sonnet以48.4%的成功率領先,其次是OpenAI的o1為30.2%,以及o3-mini為22.1%。
為何成果不盡理想?一些模型難以有效使用可用的除錯工具,或無法辨識哪些工具適用於特定問題。研究人員指出,主要問題在於缺乏足夠的訓練數據,特別是捕捉“序列決策過程”的數據,如人類除錯軌跡。
“我們相信,訓練或微調這些模型可以提升其除錯能力,”研究人員寫道。“然而,這需要專門的數據,例如捕捉代理與除錯器互動以收集資訊後提出修復方案的軌跡數據。”
參加TechCrunch Sessions:AI
預訂您在我們頂尖AI行業活動的席位,講者來自OpenAI、Anthropic和Cohere。限時優惠,門票僅需292美元,即可享受全天專家講座、工作坊和 networking 機會。
在TechCrunch Sessions:AI展示
預訂您在TC Sessions:AI的席位,向超過1,200名決策者展示您的作品。展覽機會開放至5月9日或展位全數售罄為止。
這些發現並不令人意外。眾多研究顯示,AI生成的程式碼常因對程式設計邏輯理解的弱點而引入安全漏洞和錯誤。最近對知名AI編碼工具Devin的測試顯示,它僅能完成20個程式設計任務中的3個。
微軟的研究提供了對AI模型這一持續挑戰的最深入檢視之一。雖然這不太可能抑制投資者對AI編碼工具的興趣,但可能促使開發者及其領導者重新考慮過度依賴AI進行編碼任務。
值得注意的是,幾位科技領袖已反對AI將消除編碼工作的觀點。微軟共同創辦人Bill Gates、Replit執行長Amjad Masad、Okta執行長Todd McKinnon和IBM執行長Arvind Krishna均表示對程式設計作為一門職業的持久性充滿信心。









 Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
 巴里·迪勒:隨著通用人工智慧(AGI)日益臨近,對山姆·奧特曼的信任已無關緊要
儘管近期有報導指出相反的看法,但億萬富翁媒體大亨巴里·迪勒並不認為 OpenAI 執行長山姆·奧特曼不可信。迪勒本週在《華爾街日報》的「萬物未來」會議上發言時,為奧特曼辯護;奧特曼此前曾遭到部分前同事和董事會成員指控,指稱他偶爾會採取操縱和欺騙手段。身為奧特曼好友的迪勒,當時正回應一個關於人們是否應信任奧特曼、以確保人工智慧造福人類的問題。具體而言,提問者探討了被稱為「通用人工智慧」(AGI)的理
巴里·迪勒:隨著通用人工智慧(AGI)日益臨近,對山姆·奧特曼的信任已無關緊要
儘管近期有報導指出相反的看法,但億萬富翁媒體大亨巴里·迪勒並不認為 OpenAI 執行長山姆·奧特曼不可信。迪勒本週在《華爾街日報》的「萬物未來」會議上發言時,為奧特曼辯護;奧特曼此前曾遭到部分前同事和董事會成員指控,指稱他偶爾會採取操縱和欺騙手段。身為奧特曼好友的迪勒,當時正回應一個關於人們是否應信任奧特曼、以確保人工智慧造福人類的問題。具體而言,提問者探討了被稱為「通用人工智慧」(AGI)的理
 YouTube 將 AI 深度偽造偵測功能擴展至政治人物、政府官員及記者
週二,YouTube 宣布將其深度偽造(deepfake)偵測技術擴展至特定群體,包括政府官員、政治候選人及記者。該工具能識別由人工智慧生成的肖像,並允許試點計畫的參與者要求移除其認為違反 YouTube 政策且未經授權的內容。該偵測系統在經過前期測試階段後,去年首度向約 400 萬名 YouTube 合作夥伴計畫的創作者推出。與 YouTube 現有的版權內容識別系統(Content ID)類似
YouTube 將 AI 深度偽造偵測功能擴展至政治人物、政府官員及記者
週二,YouTube 宣布將其深度偽造(deepfake)偵測技術擴展至特定群體,包括政府官員、政治候選人及記者。該工具能識別由人工智慧生成的肖像,並允許試點計畫的參與者要求移除其認為違反 YouTube 政策且未經授權的內容。該偵測系統在經過前期測試階段後,去年首度向約 400 萬名 YouTube 合作夥伴計畫的創作者推出。與 YouTube 現有的版權內容識別系統(Content ID)類似

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最佳 AI 數據可視化工具。我們精心挑選的頂級工具清單,能協助您從原始檔案中即時自動生成強大且互動式的商業智慧儀表板。透過實際測試與每週更新的排行榜,比較免費與付費選項的差異。立即釋放您數據的潛力。
10 個工具
xix.ai

探索 2026 年最適合社群媒體的 AI 品牌設計套件。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,助您在所有管道上維持完美一致的品牌視覺形象。透過實際測試,比較免費與付費選項的差異。立即為您的品牌開啟視覺優勢。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 伴侶工具,體驗沉浸式的角色扮演與情感連結。XIX.AI 精心策劃的指南收錄了多款功能強大、顛覆傳統的應用程式,內容包含每週更新的排行榜、免費與付費版本的比較,以及實際使用測試。立即找到最適合您的選擇,開啟有意義的數位伴侶體驗。
10 個工具
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













