
















 家
家Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入している。
90億パラメータは、最近報じられた数百万パラメータのマイクロモデル規模を上回るものの、NVIDIAはこれを当初の120億パラメータからの大幅な最適化と位置付けている。この改訂サイズは、単一の汎用NVIDIA A10 GPU上で動作するよう特別に設計されている。
NVIDIAのAIモデルポストトレーニング担当ディレクター、オレクシー・クチアエフ氏はXでの質問に対し次のように説明している:「120億パラメータモデルを90億に削減し、普及しているデプロイ用GPUであるA10に完全に適合させました。ハイブリッドアーキテクチャを採用しているため、より大きなバッチサイズを処理可能で、同規模の従来型トランスフォーマーモデルと比較して最大6倍の速度を達成します」
参考までに、多くの主要大規模言語モデルは700億以上のパラメータで動作します。パラメータとはモデルの動作を定義する内部設定であり、通常は数が多いほど能力が高いことを示しますが、同時に大幅な計算能力も必要とします。
本モデルは英語、ドイツ語、スペイン語、フランス語、イタリア語、日本語を含む複数言語に対応。拡張機能により韓国語、ポルトガル語、ロシア語、中国語もカバーする。指示の遂行からコード生成まで幅広いタスクに適している。
Nemotron-Nano-9B-V2およびその事前学習データセットは現在、Hugging FaceおよびNvidiaの自社モデルカタログを通じて利用可能です。
トランスフォーマーとマンバアーキテクチャの融合
このモデルは、Nvidiaの最新AI製品の基盤となるハイブリッドMamba-Transformerモデル群であるNemotron-Hを基盤として構築されています。
主流のLLMは通常、Transformerアーキテクチャとその注意機構のみに依存していますが、入力シーケンスの長さが増すにつれて、メモリと計算の面で非常に高価になる可能性があります。
カーネギーメロン大学およびプリンストン大学の研究者によって開発された Mamba アーキテクチャを利用した Nemotron-H モデルなどは、選択的状態空間モデル (SSM) を組み込んでいます。これらの SSM は、内部状態を維持することで、非常に長いシーケンスを効率的に管理します。
これらの層はシーケンス長に比例してスケーリングするため、標準的な自己注意機構と同等の計算オーバーヘッドなしに、はるかに長いコンテキストを処理できる。
ハイブリッドなマンバ-トランスフォーマー設計では、ほとんどの注意層を線形時間の状態空間層に置き換えることでコストを削減します。これにより、同等の精度を維持しながら、長い文脈を必要とするタスクにおいて最大2~3倍のスループット向上が可能です。
このアプローチはNvidiaだけのものではありません。AI2などの他のAI研究所も、マンバアーキテクチャに基づくモデルをリリースしています。
シンプルなコマンドで推論のオン/オフを切り替え
Nemotron-Nano-9B-v2は、会話型インタラクションと複雑な推論の両方を可能とする統一的なテキスト専用モデルとして設計され、完全にゼロから訓練されています。
デフォルトでは、システムは最終回答を生成する前に詳細な推論トレースを生成します。ユーザーは/thinkや/no_thinkといったシンプルなコマンドトークンでこの動作を制御できます。
また、このモデルは実行時の「推論予算」管理機能を導入しています。これにより開発者は、モデルが応答を返す前に内部推論に使用できるトークン数の上限を設定できます。
この仕組みは、顧客サポートチャットボットや自律エージェントなどのアプリケーションにおいて極めて重要な、応答遅延と精度のバランスを取ることを目的としています。
ベンチマークで示された高い性能
評価結果では、他の主要な小規模オープンモデルと競合する精度が実証されています。NeMo-Skillsスイートを用いた推論有効時のテストでは、Nemotron-Nano-9B-v2はAIME25で72.1%、MATH500で97.8%、GPQAで64.0%、LiveCodeBenchで71.1%のスコアを達成しました。
指示順守および長文脈ベンチマークでも高いスコアを記録:IFEvalで90.3%、RULER 128Kテストで78.9%を達成し、BFCL v3およびHLEベンチマークでも測定可能な改善が見られました。
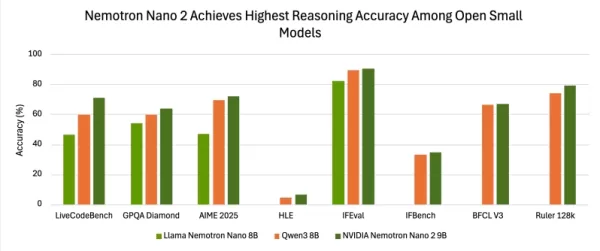
複数の評価において、Nano-9B-v2は比較対象として一般的なQwen3-8Bモデルよりも一貫して高い精度を示しています。
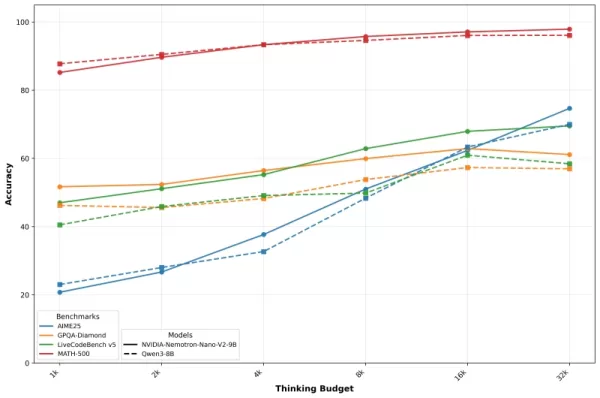
Nvidia は、推論に割り当てられるトークン数が増えるにつれてパフォーマンスが向上することを示す、精度対予算の曲線を用いてこれらの結果を発表しています。同社は、慎重な予算管理により、開発者は実稼働環境において品質と速度の両方を最適化できると述べています。
合成データセットで訓練
Nanoモデルとより広範なNemotron-Hファミリーの両方は、慎重に精選されたウェブデータ、独自ソース、合成トレーニングデータの混合で訓練されています。
トレーニングコーパスには、一般テキスト、コード、数学、科学文献、法律・金融文書に加え、アライメントに焦点を当てた質問応答データセットが含まれる。
Nvidia は、複雑なベンチマークタスクのパフォーマンス向上のために、他の大規模モデルによって生成された合成推論トレースの使用を確認しています。
ライセンスおよび商用利用
Nano-9B-v2モデルは、2025年6月に最終更新されたNvidiaオープンモデルライセンス契約に基づき公開されています。
このライセンスは寛容で企業向けであることを意図しています。Nvidiaは、モデルがそのまま商用利用可能であり、開発者が派生作品の作成と配布を自由にできることを明示しています。
重要な点として、Nvidiaはモデルが生成する出力物に対する所有権を一切主張せず、すべての権利と責任はモデルを利用する開発者または組織に帰属します。
企業開発者にとって、これは別途商用ライセンスを交渉したり、使用量・収益・ユーザー数に基づく料金を支払うことなく、モデルを即座に本番環境に展開できることを意味します。他プロバイダーの段階的オープンライセンスとは異なり、企業が一定規模に達した際に有料ライセンスを義務付ける条項は存在しません。
ただし、本契約には企業が遵守すべき重要な条件がいくつか含まれています:
- ガードレール:ユーザーは、特定の導入環境向けに適切かつ同等の代替手段を実装しない限り、組み込みの安全機構(「ガードレール」と呼ばれる)をバイパスまたは無効化できません。
- 再配布:モデルまたはその派生作品の再配布には、Nvidia Open Model Licenseの全文と適切な帰属表示(「Nvidia CorporationよりNvidia Open Model Licenseに基づきライセンス供与」)を含める必要があります。
- コンプライアンス:ユーザーは、米国輸出管理法など、適用されるすべての貿易規制および制限を遵守しなければなりません。
- 信頼できるAIに関する条項:使用は、責任ある導入と倫理的配慮に関する原則を網羅するNvidiaの信頼できるAIガイドラインに準拠しなければなりません。
- 訴訟条項:ユーザーがモデルに関連する侵害を主張して他者に対して著作権または特許訴訟を提起した場合、本ライセンスは自動的に終了します。
これらの条件は、商業規模を制限するのではなく、法的コンプライアンスと責任ある利用の確保に重点を置いています。企業は、製品開発、サービスの収益化、ユーザーベースの拡大について、Nvidiaに追加の許可を求める必要も、ロイヤルティを支払う必要もありません。代わりに、導入方法が安全性を尊重し、適切な帰属表示を行い、すべてのコンプライアンス義務を満たしていることを確認する必要があります。
市場ポジショニング
Nvidiaは、小規模な環境において推論能力と導入効率のバランスを必要とする開発者を、Nemotron-Nano-9B-v2のターゲットとしています。
ランタイム予算制御と推論切り替え機能は、システム構築者が精度と応答速度のトレードオフをより柔軟に管理できるように設計されています。
Hugging Face および Nvidia のモデルカタログでの提供開始は、幅広いアクセシビリティと実験・統合の促進を意図したものです。
NvidiaによるNemotron-Nano-9B-v2のリリースは、言語モデルにおける効率性と制御可能な推論への同社の継続的な注力を強調しています。
ハイブリッドアーキテクチャと高度な圧縮・トレーニング技術を融合させることで、Nvidiaは運用コストとレイテンシを削減しつつ高精度を維持するツールを開発者に提供することを目指しています。
関連記事
 NvidiaのOpenClaw派生版は、同社にとって最大の課題であるセキュリティ問題を解決する可能性がある
NVIDIAのCEO、ジェンセン・フアン氏は、あらゆる企業に「OpenClaw」戦略が必要だと考えており、NVIDIAはその提供準備が整っている。月曜日のGTC基調講演で、Huang氏は、Nvidiaが、話題を呼んだローカルAI自律エージェントを基に、エンタープライズグレードのプラットフォーム「NemoClaw」を構築したことを発表した。このオープンソース・プラットフォームは、本質的にはOpenC
ペンタゴン、Nvidia、Microsoft、AWSと契約を結び、機密ネットワークでAIの導入を進める
以前にGoogle、SpaceX、OpenAIと合意に達した後、米国国防総省は金曜日にNvidia、Microsoft、Amazon Web Services、Reflection AIとも契約を結び、これらの企業のAI技術やモデルを機密ネットワークで「合法的な運用目的」のために活用することを発表しました。同声明では、「これらの契約により、米軍をAIを優先した戦闘力として確立する取り組みが加速され、あらゆる戦闘分野において我々の兵士たちが意思決定上の優位性を維持する能力が強化されるだろう」と述
Nvidia GTCで「NemoClaw」とロボット「Olaf」が発表され、1兆ドル規模の投資計画が明らかに
プレイヤーを読み込み中…今週開催されたNvidiaのGTCカンファレンスで、CEOのジェンセン・フアン氏はトレードマークのレザージャケット姿で登壇し、2時間半にわたる基調講演を行った。その中で、2027年までにAIチップの売上高が1兆ドルに達すると予測し、あらゆる企業に「OpenClaw戦略」が必要だと宣言した。講演の締めくくりには、話が脱線しすぎてマイクを切られる羽目になったオラフ型ロボットが登
関連特集おすすめ
漫画制作
NvidiaのOpenClaw派生版は、同社にとって最大の課題であるセキュリティ問題を解決する可能性がある
NVIDIAのCEO、ジェンセン・フアン氏は、あらゆる企業に「OpenClaw」戦略が必要だと考えており、NVIDIAはその提供準備が整っている。月曜日のGTC基調講演で、Huang氏は、Nvidiaが、話題を呼んだローカルAI自律エージェントを基に、エンタープライズグレードのプラットフォーム「NemoClaw」を構築したことを発表した。このオープンソース・プラットフォームは、本質的にはOpenC
ペンタゴン、Nvidia、Microsoft、AWSと契約を結び、機密ネットワークでAIの導入を進める
以前にGoogle、SpaceX、OpenAIと合意に達した後、米国国防総省は金曜日にNvidia、Microsoft、Amazon Web Services、Reflection AIとも契約を結び、これらの企業のAI技術やモデルを機密ネットワークで「合法的な運用目的」のために活用することを発表しました。同声明では、「これらの契約により、米軍をAIを優先した戦闘力として確立する取り組みが加速され、あらゆる戦闘分野において我々の兵士たちが意思決定上の優位性を維持する能力が強化されるだろう」と述
Nvidia GTCで「NemoClaw」とロボット「Olaf」が発表され、1兆ドル規模の投資計画が明らかに
プレイヤーを読み込み中…今週開催されたNvidiaのGTCカンファレンスで、CEOのジェンセン・フアン氏はトレードマークのレザージャケット姿で登壇し、2時間半にわたる基調講演を行った。その中で、2027年までにAIチップの売上高が1兆ドルに達すると予測し、あらゆる企業に「OpenClaw戦略」が必要だと宣言した。講演の締めくくりには、話が脱線しすぎてマイクを切られる羽目になったオラフ型ロボットが登
関連特集おすすめ
漫画制作
 少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
 15 ツール
15 ツール
 xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入している。
90億パラメータは、最近報じられた数百万パラメータのマイクロモデル規模を上回るものの、NVIDIAはこれを当初の120億パラメータからの大幅な最適化と位置付けている。この改訂サイズは、単一の汎用NVIDIA A10 GPU上で動作するよう特別に設計されている。
NVIDIAのAIモデルポストトレーニング担当ディレクター、オレクシー・クチアエフ氏はXでの質問に対し次のように説明している:「120億パラメータモデルを90億に削減し、普及しているデプロイ用GPUであるA10に完全に適合させました。ハイブリッドアーキテクチャを採用しているため、より大きなバッチサイズを処理可能で、同規模の従来型トランスフォーマーモデルと比較して最大6倍の速度を達成します」
参考までに、多くの主要大規模言語モデルは700億以上のパラメータで動作します。パラメータとはモデルの動作を定義する内部設定であり、通常は数が多いほど能力が高いことを示しますが、同時に大幅な計算能力も必要とします。
本モデルは英語、ドイツ語、スペイン語、フランス語、イタリア語、日本語を含む複数言語に対応。拡張機能により韓国語、ポルトガル語、ロシア語、中国語もカバーする。指示の遂行からコード生成まで幅広いタスクに適している。
Nemotron-Nano-9B-V2およびその事前学習データセットは現在、Hugging FaceおよびNvidiaの自社モデルカタログを通じて利用可能です。
トランスフォーマーとマンバアーキテクチャの融合
このモデルは、Nvidiaの最新AI製品の基盤となるハイブリッドMamba-Transformerモデル群であるNemotron-Hを基盤として構築されています。
主流のLLMは通常、Transformerアーキテクチャとその注意機構のみに依存していますが、入力シーケンスの長さが増すにつれて、メモリと計算の面で非常に高価になる可能性があります。
カーネギーメロン大学およびプリンストン大学の研究者によって開発された Mamba アーキテクチャを利用した Nemotron-H モデルなどは、選択的状態空間モデル (SSM) を組み込んでいます。これらの SSM は、内部状態を維持することで、非常に長いシーケンスを効率的に管理します。
これらの層はシーケンス長に比例してスケーリングするため、標準的な自己注意機構と同等の計算オーバーヘッドなしに、はるかに長いコンテキストを処理できる。
ハイブリッドなマンバ-トランスフォーマー設計では、ほとんどの注意層を線形時間の状態空間層に置き換えることでコストを削減します。これにより、同等の精度を維持しながら、長い文脈を必要とするタスクにおいて最大2~3倍のスループット向上が可能です。
このアプローチはNvidiaだけのものではありません。AI2などの他のAI研究所も、マンバアーキテクチャに基づくモデルをリリースしています。
シンプルなコマンドで推論のオン/オフを切り替え
Nemotron-Nano-9B-v2は、会話型インタラクションと複雑な推論の両方を可能とする統一的なテキスト専用モデルとして設計され、完全にゼロから訓練されています。
デフォルトでは、システムは最終回答を生成する前に詳細な推論トレースを生成します。ユーザーは/thinkや/no_thinkといったシンプルなコマンドトークンでこの動作を制御できます。
また、このモデルは実行時の「推論予算」管理機能を導入しています。これにより開発者は、モデルが応答を返す前に内部推論に使用できるトークン数の上限を設定できます。
この仕組みは、顧客サポートチャットボットや自律エージェントなどのアプリケーションにおいて極めて重要な、応答遅延と精度のバランスを取ることを目的としています。
ベンチマークで示された高い性能
評価結果では、他の主要な小規模オープンモデルと競合する精度が実証されています。NeMo-Skillsスイートを用いた推論有効時のテストでは、Nemotron-Nano-9B-v2はAIME25で72.1%、MATH500で97.8%、GPQAで64.0%、LiveCodeBenchで71.1%のスコアを達成しました。
指示順守および長文脈ベンチマークでも高いスコアを記録:IFEvalで90.3%、RULER 128Kテストで78.9%を達成し、BFCL v3およびHLEベンチマークでも測定可能な改善が見られました。
複数の評価において、Nano-9B-v2は比較対象として一般的なQwen3-8Bモデルよりも一貫して高い精度を示しています。
Nvidia は、推論に割り当てられるトークン数が増えるにつれてパフォーマンスが向上することを示す、精度対予算の曲線を用いてこれらの結果を発表しています。同社は、慎重な予算管理により、開発者は実稼働環境において品質と速度の両方を最適化できると述べています。
合成データセットで訓練
Nanoモデルとより広範なNemotron-Hファミリーの両方は、慎重に精選されたウェブデータ、独自ソース、合成トレーニングデータの混合で訓練されています。
トレーニングコーパスには、一般テキスト、コード、数学、科学文献、法律・金融文書に加え、アライメントに焦点を当てた質問応答データセットが含まれる。
Nvidia は、複雑なベンチマークタスクのパフォーマンス向上のために、他の大規模モデルによって生成された合成推論トレースの使用を確認しています。
ライセンスおよび商用利用
Nano-9B-v2モデルは、2025年6月に最終更新されたNvidiaオープンモデルライセンス契約に基づき公開されています。
このライセンスは寛容で企業向けであることを意図しています。Nvidiaは、モデルがそのまま商用利用可能であり、開発者が派生作品の作成と配布を自由にできることを明示しています。
重要な点として、Nvidiaはモデルが生成する出力物に対する所有権を一切主張せず、すべての権利と責任はモデルを利用する開発者または組織に帰属します。
企業開発者にとって、これは別途商用ライセンスを交渉したり、使用量・収益・ユーザー数に基づく料金を支払うことなく、モデルを即座に本番環境に展開できることを意味します。他プロバイダーの段階的オープンライセンスとは異なり、企業が一定規模に達した際に有料ライセンスを義務付ける条項は存在しません。
ただし、本契約には企業が遵守すべき重要な条件がいくつか含まれています:
- ガードレール:ユーザーは、特定の導入環境向けに適切かつ同等の代替手段を実装しない限り、組み込みの安全機構(「ガードレール」と呼ばれる)をバイパスまたは無効化できません。
- 再配布:モデルまたはその派生作品の再配布には、Nvidia Open Model Licenseの全文と適切な帰属表示(「Nvidia CorporationよりNvidia Open Model Licenseに基づきライセンス供与」)を含める必要があります。
- コンプライアンス:ユーザーは、米国輸出管理法など、適用されるすべての貿易規制および制限を遵守しなければなりません。
- 信頼できるAIに関する条項:使用は、責任ある導入と倫理的配慮に関する原則を網羅するNvidiaの信頼できるAIガイドラインに準拠しなければなりません。
- 訴訟条項:ユーザーがモデルに関連する侵害を主張して他者に対して著作権または特許訴訟を提起した場合、本ライセンスは自動的に終了します。
これらの条件は、商業規模を制限するのではなく、法的コンプライアンスと責任ある利用の確保に重点を置いています。企業は、製品開発、サービスの収益化、ユーザーベースの拡大について、Nvidiaに追加の許可を求める必要も、ロイヤルティを支払う必要もありません。代わりに、導入方法が安全性を尊重し、適切な帰属表示を行い、すべてのコンプライアンス義務を満たしていることを確認する必要があります。
市場ポジショニング
Nvidiaは、小規模な環境において推論能力と導入効率のバランスを必要とする開発者を、Nemotron-Nano-9B-v2のターゲットとしています。
ランタイム予算制御と推論切り替え機能は、システム構築者が精度と応答速度のトレードオフをより柔軟に管理できるように設計されています。
Hugging Face および Nvidia のモデルカタログでの提供開始は、幅広いアクセシビリティと実験・統合の促進を意図したものです。
NvidiaによるNemotron-Nano-9B-v2のリリースは、言語モデルにおける効率性と制御可能な推論への同社の継続的な注力を強調しています。
ハイブリッドアーキテクチャと高度な圧縮・トレーニング技術を融合させることで、Nvidiaは運用コストとレイテンシを削減しつつ高精度を維持するツールを開発者に提供することを目指しています。










 NvidiaのOpenClaw派生版は、同社にとって最大の課題であるセキュリティ問題を解決する可能性がある
NVIDIAのCEO、ジェンセン・フアン氏は、あらゆる企業に「OpenClaw」戦略が必要だと考えており、NVIDIAはその提供準備が整っている。月曜日のGTC基調講演で、Huang氏は、Nvidiaが、話題を呼んだローカルAI自律エージェントを基に、エンタープライズグレードのプラットフォーム「NemoClaw」を構築したことを発表した。このオープンソース・プラットフォームは、本質的にはOpenC
NvidiaのOpenClaw派生版は、同社にとって最大の課題であるセキュリティ問題を解決する可能性がある
NVIDIAのCEO、ジェンセン・フアン氏は、あらゆる企業に「OpenClaw」戦略が必要だと考えており、NVIDIAはその提供準備が整っている。月曜日のGTC基調講演で、Huang氏は、Nvidiaが、話題を呼んだローカルAI自律エージェントを基に、エンタープライズグレードのプラットフォーム「NemoClaw」を構築したことを発表した。このオープンソース・プラットフォームは、本質的にはOpenC
 ペンタゴン、Nvidia、Microsoft、AWSと契約を結び、機密ネットワークでAIの導入を進める
以前にGoogle、SpaceX、OpenAIと合意に達した後、米国国防総省は金曜日にNvidia、Microsoft、Amazon Web Services、Reflection AIとも契約を結び、これらの企業のAI技術やモデルを機密ネットワークで「合法的な運用目的」のために活用することを発表しました。同声明では、「これらの契約により、米軍をAIを優先した戦闘力として確立する取り組みが加速され、あらゆる戦闘分野において我々の兵士たちが意思決定上の優位性を維持する能力が強化されるだろう」と述
ペンタゴン、Nvidia、Microsoft、AWSと契約を結び、機密ネットワークでAIの導入を進める
以前にGoogle、SpaceX、OpenAIと合意に達した後、米国国防総省は金曜日にNvidia、Microsoft、Amazon Web Services、Reflection AIとも契約を結び、これらの企業のAI技術やモデルを機密ネットワークで「合法的な運用目的」のために活用することを発表しました。同声明では、「これらの契約により、米軍をAIを優先した戦闘力として確立する取り組みが加速され、あらゆる戦闘分野において我々の兵士たちが意思決定上の優位性を維持する能力が強化されるだろう」と述
 Nvidia GTCで「NemoClaw」とロボット「Olaf」が発表され、1兆ドル規模の投資計画が明らかに
プレイヤーを読み込み中…今週開催されたNvidiaのGTCカンファレンスで、CEOのジェンセン・フアン氏はトレードマークのレザージャケット姿で登壇し、2時間半にわたる基調講演を行った。その中で、2027年までにAIチップの売上高が1兆ドルに達すると予測し、あらゆる企業に「OpenClaw戦略」が必要だと宣言した。講演の締めくくりには、話が脱線しすぎてマイクを切られる羽目になったオラフ型ロボットが登
Nvidia GTCで「NemoClaw」とロボット「Olaf」が発表され、1兆ドル規模の投資計画が明らかに
プレイヤーを読み込み中…今週開催されたNvidiaのGTCカンファレンスで、CEOのジェンセン・フアン氏はトレードマークのレザージャケット姿で登壇し、2時間半にわたる基調講演を行った。その中で、2027年までにAIチップの売上高が1兆ドルに達すると予測し、あらゆる企業に「OpenClaw戦略」が必要だと宣言した。講演の締めくくりには、話が脱線しすぎてマイクを切られる羽目になったオラフ型ロボットが登

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













