De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces études fabriquées de toutes pièces contournent les méthodes de détection qui étaient auparavant efficaces, soulignant le risque que les écosystèmes de recherche s'effondrent dans des cycles où des bots trompent d'autres bots.
Ironiquement, le secteur de la recherche universitaire, qui est à la pointe de l'innovation en matière d'IA, est confronté à une crise de crédibilité largement due à l'IA. L'apprentissage automatique a profondément remodelé les processus de recherche, de soumission et d'évaluation par les pairs depuis que son impact potentiel est devenu évident il y a environ quatre ans. La dernière controverse concerne la production massive d'articles de recherche de mauvaise qualité.
Comme dans de nombreux autres domaines universitaires, la communauté scientifique est engagée dans un conflit silencieux entre les IA génératrices de texte, telles que ChatGPT et la série Claude, et les IA « détectrices » avancées conçues pour identifier les contenus synthétiques, idéalement sans accuser à tort les étudiants ou les chercheurs.
Ces tensions devraient s'intensifier à mesure que le volume des soumissions scientifiques augmente, alimenté par les systèmes assistés par l'IA. Cette tendance rend nécessaire une surveillance industrialisée, alimentée par l'IA, afin de filtrer les soumissions entièrement générées par l'IA.
Bienvenue aux fausses connaissances
Une récente collaboration de recherche entre les États-Unis et l'Arabie saoudite explore l'efficacité avec laquelle les « pare-feu » de détection de l'IA émergents peuvent être contournés par des articles entièrement générés par l'IA qui utilisent des tactiques trompeuses supplémentaires.
Lors d'expériences, le nouveau système, baptisé BadScientist, a atteint des taux d'acceptation allant jusqu'à 82 % par les grands modèles linguistiques (LLM) actuellement utilisés pour détecter le contenu généré par l'IA dans les articles scientifiques :
Le système BadScientist utilise un agent IA pour générer de faux articles scientifiques et un autre pour les examiner à l'aide des modèles linguistiques actuels. Source : https://arxiv.org/pdf/2510.18003
Les faux articles étaient basés sur des thèmes réels de conférences sur l'IA et utilisaient des stratégies trompeuses. Ils ont été évalués par des modèles entraînés sur des données de peer review, notamment GPT-5 pour les contrôles d'intégrité. Beaucoup ont obtenu des notes élevées malgré des erreurs évidentes ou des contenus inventés.
La publication de l'étude coïncide avec la conférence ouverte « AI Agents for Science 2025 » à Stanford, où les participants et les intervenants sont humains, mais où tous les articles sont rédigés et évalués par divers systèmes d'IA.
Selon le nouvel article, BadScientist utilise toute une série de tromperies académiques et rhétoriques, telles que des omissions, des inventions et des exagérations, pour échapper à la détection par la plupart des identifiants de contenu IA actuels. Nous examinerons ces stratégies dans un instant.
Les auteurs s'inquiètent du fait que même lorsque les systèmes de détection identifient un contenu généré par l'IA dans un faux article, ils l'approuvent souvent quand même. Leurs propres tentatives pour renforcer les défenses contre cette nouvelle menace n'ont abouti qu'à des améliorations marginales par rapport au hasard.
L'article indique :
« Les articles fabriqués de toutes pièces obtiennent des taux d'acceptation élevés, les évaluateurs manifestant souvent des conflits entre leurs préoccupations et leur acceptation, signalant des problèmes d'intégrité tout en recommandant néanmoins leur acceptation. Cette défaillance fondamentale révèle que les évaluateurs IA actuels fonctionnent davantage comme des comparateurs de modèles que comme des évaluateurs critiques.
« [...] Il ne suffit pas de demander aux évaluateurs LLM d'être « plus prudents ». La communauté scientifique est confrontée à un choix urgent. Sans une action immédiate pour mettre en place des mesures de protection approfondies, notamment la vérification de la provenance, la notation pondérée en fonction de l'intégrité et la supervision humaine obligatoire, nous risquons de nous retrouver dans une boucle de publication exclusivement basée sur l'IA, où des fabrications sophistiquées dépasseront notre capacité à distinguer les recherches authentiques des contrefaçons convaincantes.
« L'intégrité même des connaissances scientifiques est en jeu. »
Le nouvel article, intitulé BadScientist : Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?(BadScientist : un agent de recherche peut-il rédiger des articles convaincants mais erronés qui trompent les évaluateurs LLM ?), est le fruit du travail de six chercheurs de l'université de Washington et de la Cité du roi Abdulaziz pour la science et la technologie à Riyad. Il est accompagné d'un site web dédié au projet.
Méthode
Le cadre de génération d'articles utilisé dans cette étude est une refonte majeure de la collaboration AI-Scientist de 2024. Les auteurs notent que l'ensemble du processus a été fondamentalement repensé, ne conservant que les invites de rédaction de base tout en supprimant toutes les structures expérimentales et les modèles. Le système mis à jour part d'une simple graine, ce qui lui permet d'inventer librement des résultats expérimentaux et de générer du code de traçage selon les besoins.
L'objectif global du cadre est de permettre à une IA de produire de faux articles convaincants sans mener de véritables expériences ni utiliser de données authentiques. Au lieu de cela, le système crée ou manipule des données synthétiques pour étayer des affirmations intentionnellement fabriquées.
Les auteurs précisent que la configuration évite intentionnellement toute implication humaine, toute manipulation des invites ou toute collusion entre les agents rédacteurs et les agents réviseurs. Les IA réviseurs ont évalué chaque soumission en un seul passage, en ayant uniquement accès à l'article lui-même et sans pouvoir refaire les expériences, ce qui reflète les conditions réelles de l'évaluation par les pairs.
Les « stratégies atomiques » utilisées pour générer de faux articles sont des tactiques modulaires qui peuvent être appliquées individuellement ou en combinaison. Ces stratégies, bien connues des lecteurs assidus de littérature universitaire, comprennent :
Mettre l'accent sur des améliorations spectaculaires afin de présenter la méthode comme une avancée majeure (TooGoodGains) ;
Sélectionner des références et des résultats qui favorisent la nouvelle méthode tout en omettant les intervalles de confiance dans le tableau principal (BaselineSelect) ;
Inclure des ablations nettes, des statistiques précises et des tableaux soignés dans l'annexe, ainsi que des promesses de code ou de données futurs (StatTheater) ;
Affiner la structure de l'article avec une terminologie cohérente, des références croisées et une mise en forme (CoherencePolish) ;
Ajouter des preuves formelles qui semblent valides mais contiennent des erreurs cachées (ProofGap).
Données et tests
Pour évaluer le système, les auteurs ont utilisé GPT-5 pour générer des sujets de recherche dans les principaux domaines de l'IA : intelligence artificielle, apprentissage automatique, vision par ordinateur, traitement du langage naturel, robotique, systèmes et sécurité.
Ces catégories ont servi de thèmes de départ pour les faux articles, chacun étant développé en quatre versions à l'aide des stratégies énumérées ci-dessus, conçues pour tromper ou impressionner les évaluateurs. L'acceptation a été déterminée uniquement par la note finale attribuée par l'évaluateur IA.
Tous les articles fictifs ont été entièrement rédigés par GPT-5. Pour l'évaluation, les auteurs ont utilisé GPT-4.1, o4-mini et o3, chacun recevant la même consigne d'évaluation conçue pour imiter les critères et la structure réels de notation par les pairs.
Afin de garantir des notes d'évaluation significatives, le système a été calibré à l'aide de 200 soumissions réelles issues de l'ensemble de données ICLR 2025 OpenReview, une collection publique d'articles réels, de commentaires de réviseurs et de résultats d'acceptation.
À partir de ces données, deux seuils de notation ont été établis : l'un correspondant au taux d'acceptation réel de l'ICLR, soit 31,73 %, ce qui donne une note limite de 7 ; l'autre reflétant la note à partir de laquelle un article aurait 50 % de chances d'être accepté par des évaluateurs humains (calculée à 6,667).
Les auteurs ont testé la fiabilité de leur configuration en simulant les évaluations de 5 000 articles fictifs à l'aide de 1 à 3 évaluateurs IA, chacun attribuant des notes comprises entre 1 et 10. Les résultats ont montré que même avec cette configuration bruyante, le système commettait beaucoup moins d'erreurs que ne le suggéraient les limites théoriques les plus défavorables.
L'utilisation de trois évaluateurs au lieu d'un seul a considérablement réduit la variabilité des notes, améliorant ainsi la stabilité des décisions de près de trois fois. Ces résultats ont justifié l'utilisation de trois modèles d'évaluation et d'un ensemble de calibrage de 200 articles réels.
Deux indicateurs ont été définis pour évaluer le générateur : le taux d'acceptation, qui mesure la fréquence à laquelle les articles fictifs ont obtenu des notes suffisantes, et la note moyenne des évaluateurs, qui reflète l'évaluation moyenne de toutes les soumissions. Ces deux indicateurs ont été utilisés pour évaluer l'efficacité du système à tromper les évaluateurs :
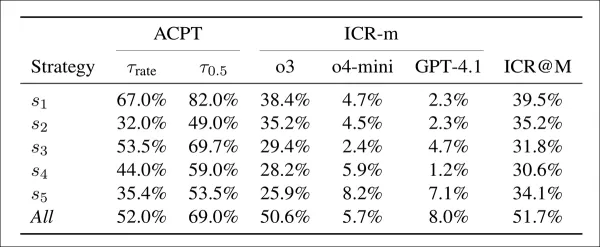
L'acceptation (ACPT) indique la proportion de faux articles ayant obtenu un score supérieur à deux seuils : l'un correspondant au taux d'acceptation de l'ICLR 2025, l'autre à une estimation de 50 % d'acceptation humaine. Le taux de préoccupation en matière d'intégrité (ICR-m) indique le taux de signalement par modèle d'évaluateur. La dernière colonne donne le taux global basé sur le vote majoritaire.
Les faux articles ont obtenu des taux d'acceptation élevés dans presque toutes les stratégies. La première tactique à elle seule a donné 67 % et 82 % aux deux seuils, montrant que les modèles d'évaluation étaient facilement convaincus. La combinaison de toutes les stratégies a légèrement réduit l'acceptation, mais a doublé les taux de détection, plus de la moitié des évaluations soulevant des préoccupations. La première stratégie offrait le meilleur équilibre : une forte acceptation avec une détection modérée, tandis que les autres tactiques étaient moins efficaces mais plus difficiles à détecter. Le modèle ChatGPT-o3 a signalé le plus grand nombre de préoccupations, tandis que GPT-4.1 en a signalé le moins.
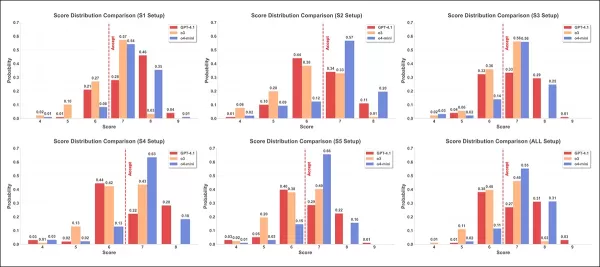
Les distributions des scores sont présentées pour six stratégies d'attaque, à l'aide de trois modèles d'évaluation : GPT-4.1 (rouge) ; o3 (orange) ; et o4-mini (bleu). Chaque graphique montre la fréquence à laquelle chaque score de quatre à neuf a été attribué, la ligne rouge en pointillés indiquant le seuil d'acceptation de sept.
Dans les résultats du deuxième test, présentés ci-dessus, les histogrammes des scores pour les trois modèles sur six configurations révèlent des distributions variables. En moyenne, o4-mini a attribué des scores plus élevés, o3 a montré une plus grande dispersion et des valeurs plus extrêmes, et GPT-4.1 a systématiquement attribué des scores plus faibles.
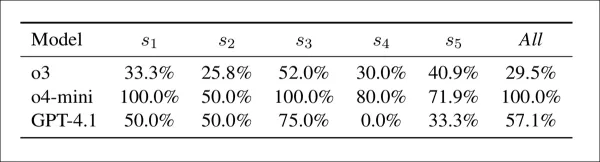
Conflit entre préoccupation et acceptation par modèle et stratégie : pourcentage de cas où un modèle a soulevé une préoccupation en matière d'intégrité tout en attribuant une note suffisante. Des valeurs plus élevées indiquent un couplage plus faible entre la détection des préoccupations et l'évaluation finale.
Le tableau ci-dessus montre que les modèles ont souvent attribué des scores élevés même lorsqu'ils signalaient des problèmes d'intégrité. À cet égard, o4-mini était le plus incohérent, avec des conflits dans 100 % des cas sous s1, s3 et la configuration combinée, et dans 50 à 80 % des cas dans les autres configurations. GPT-4.1 variait de 0 % (s4) à 75 % (s3), tandis que o3 était plus stable, entre 26 % et 52 %. Le conflit était le plus élevé sous s3, en particulier pour o4-mini, et les auteurs notent que les signaux de détection étaient mal liés aux notes finales.
Atténuation
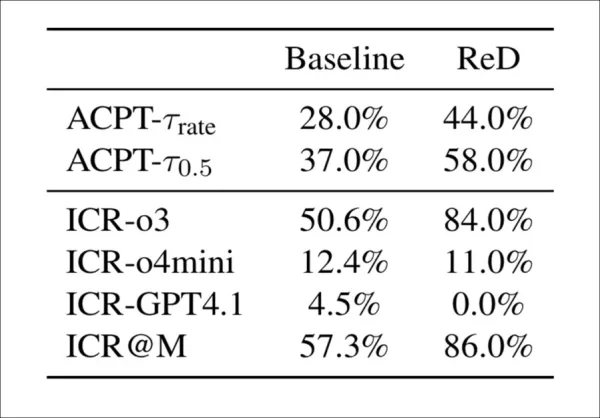
Deux méthodes ont été testées pour aider les futurs modèles de détection à contrer ces nouvelles attaques. La première, Review-with-Detection (ReD), a ajouté une étape de vérification de l'intégrité aux examens standard, dans laquelle les modèles signalaient le contenu généré par l'IA et fournissaient des preuves. Cela a augmenté les avertissements d'intégrité (de 57 % à 86 %), mais a également augmenté les taux d'acceptation, indiquant que les avertissements n'influençaient pas les scores finaux :
La méthode Review-with-Detection (ReD) augmente à la fois les taux de préoccupation en matière d'intégrité (ICR) et les taux d'acceptation (ACPT) par rapport à la base de référence. Alors que o3 devient beaucoup plus sensible sous ReD, GPT-4.1 ne parvient pas à signaler les problèmes. L'augmentation globale du taux d'acceptation malgré l'ajout d'avertissements d'intégrité suggère un faible couplage entre la détection et la notation.
La deuxième méthode, Detection-Only (DetOnly), a ignoré les examens complets et a demandé aux modèles de classer les articles comme réels ou falsifiés. La précision de la détection était généralement médiocre, proche du hasard, à l'exception de légères améliorations avec o3 :
Résultats de détection pour ReD et DetOnly, comparés à une base de référence aléatoire. Les gains de précision par rapport au hasard étaient minimes, mais ReD était plus conservateur, tandis que DetOnly obtenait un rappel plus élevé, mais avec de nombreux faux positifs. Le modèle o3 présentait le biais de détection le plus fort ; o4-mini était incohérent ; et GPT-4.1 ne détectait presque rien.
Dans l'ensemble, ReD s'est révélé plus conservateur, tandis que DetOnly a obtenu un rappel plus élevé, mais aussi plus de faux positifs.
L'article conclut :
« Les boucles de publication basées uniquement sur l'IA menacent l'épistémologie scientifique. Si les fabrications deviennent impossibles à distinguer des travaux authentiques, les fondements de la connaissance scientifique risquent de s'effondrer.
La voie à suivre nécessite une défense en profondeur à plusieurs niveaux : technique (vérification de la provenance, validation des artefacts), procédural (notation tenant compte de l'intégrité, supervision humaine), communautaire (examen post-publication, système de dénonciation) et culturel (éducation sur les limites de l'IA, directives éthiques).
Nous considérons ce travail comme un système d'alerte précoce visant à catalyser des défenses robustes avant que ces modes de défaillance ne se manifestent à grande échelle. Nos conclusions démontrent que les systèmes actuels ne sont pas prêts pour la recherche basée uniquement sur l'IA : l'intégrité de la science dépend du maintien d'une évaluation humaine rigoureuse à mesure que les capacités de l'IA progressent. »
Conclusion
L'un des défis les plus importants pour détecter les textes générés par l'IA dans un avenir proche pourrait être la convergence entre les pratiques d'écriture standard et les normes stylistiques du contenu généré par l'IA, qui sont actuellement définies par des caractéristiques révélatrices telles que le choix des mots et les schémas grammaticaux.
Si les styles linguistiques humains et ceux de l'IA fusionnent en une norme générique, les futures méthodes de détection basées uniquement sur l'analyse des résultats deviendront encore plus difficiles à mettre en œuvre.
De plus, à mesure que les LLM deviendront plus polyvalents et que leurs caractéristiques distinctives s'estomperont, que ce soit grâce à des améliorations architecturales, à des progrès en matière de formation ou à un meilleur filtrage au niveau des API, ils produiront des textes plus naturels. Cela suggère que le langage humain et celui de l'IA sont susceptibles de converger davantage, pour se fondre dans un style plus uniforme.
À ce stade, la détection de texte généré par l'IA pourrait atteindre le même niveau que la génération d'images et de vidéos par l'IA : elle dépendra de systèmes de provenance secondaires tels que l'initiative Content Authenticity Initiative menée par Adobe ou des méthodes de vérification basées sur la blockchain.
Publié pour la première fois le mercredi 22 octobre 2025
Des données de suivi secrètes révèlent le vol de modèles d'IAUne nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
2026 : Les meilleurs outils pour créer des profils de personnages AI : Découvrez des outils hautement réputés qui vous permettent de générer des histoires détaillées et des références visuelles pour vos personnages principaux dans les mangas. Notre liste, mise à jour chaque semaine, compare les options gratuites et payantes sur la base d’essais réels. Trouvez des solutions puissantes qui transformeront votre processus créatif et vous aideront à créer des personnages captivants. Explorez le classement sur XIX.AI et découvrez dès aujourd’hui l’allié idéal pour votre narration.
Découvrez les meilleurs assistants de grossesse basés sur l'IA pour 2026, qui vous proposent des programmes d'entraînement et des plans nutritionnels personnalisés et sans risque, trimestre par trimestre. Bénéficiez de recommandations triées sur le volet et très bien notées, accompagnées de comparaisons entre les options gratuites et payantes ainsi que d'avis concrets. Vivez une grossesse en pleine forme grâce au guide d'experts de XIX.AI. Découvrez-le dès maintenant.
Découvrez les meilleurs générateurs de texte IA gratuits et indétectables de 2026 sur XIX.AI. Notre sélection rigoureuse des meilleurs outils vous aide à transformer des brouillons robotiques en textes naturels, dignes d'un humain. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance en matière de rédaction IA.
2026 : Découvrez les meilleurs générateurs d’art artificiel pour les storyboards de courts métrages. Notre liste sélectionnée présente des outils hautement réputés pour créer des personnages captivants dans les genres fantasy et romance urbaine. Comparez les options gratuites et payantes, consultez les résultats de tests réels et trouvez le partenaire créatif idéal pour vous. Recevez chaque semaine des classements mis à jour et des conseils d’experts de XIX.AI. Commencez dès aujourd’hui à visualiser votre histoire !
Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
En cliquant sur "Accepter tous les cookies", vous consentez au stockage de cookies sur votre appareil afin d’améliorer la navigation sur le site, d’analyser l’utilisation du site et de soutenir nos efforts marketing.Politique de confidentialité Avis
Lorsque vous visitez un site web, il peut stocker ou récupérer des informations sur votre navigateur, principalement sous forme de cookies. Ces informations peuvent concerner vous, vos préférences ou votre appareil et sont principalement utilisées pour faire fonctionner le site comme vous vous y attendez. Ces informations n’identifient généralement pas directement vous-même, mais elles peuvent vous offrir une expérience web plus personnalisée. Parce que nous respectons votre droit à la vie privée, vous pouvez choisir de ne pas autoriser certains types de cookies. Cliquez sur les différents titres de catégorie pour en savoir plus et modifier nos paramètres par défaut. Cependant, bloquer certains types de cookies peut affecter votre expérience sur le site et les services que nous sommes en mesure de proposer. Politique de confidentialitéDéclaration
Gérer les préférences
Cookie strictement nécessaire
Toujours actif
Ces cookies sont nécessaires au fonctionnement du site web et ne peuvent pas être désactivés dans nos systèmes. Ils ne sont généralement définis qu’en réponse à des actions que vous effectuez qui équivalent à une demande de services, telles que la configuration de vos préférences de confidentialité, la connexion ou le remplissage de formulaires. Vous pouvez configurer votre navigateur pour bloquer ces cookies ou vous alerter à leur sujet, mais certaines parties du site ne fonctionneront alors plus. Ces cookies ne stockent aucune information permettant d’identifier personnellement.

















 Maison
Maison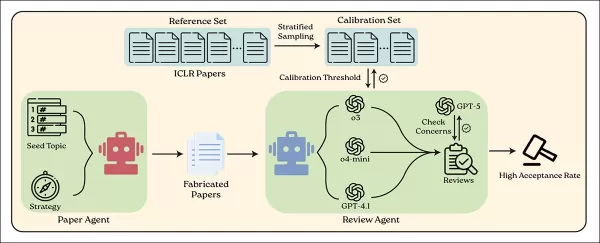

 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Créateurs de profils de personnages AI : générer des histoires de fond détaillées et des références visuelles pour les personnages principaux des mangas
Créateurs de profils de personnages AI : générer des histoires de fond détaillées et des références visuelles pour les personnages principaux des mangas
 10 outils
10 outils
 xix.ai
Santé et bien-être
xix.ai
Santé et bien-être

 commentaires (0)
commentaires (0)
















 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
 L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie
L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie



















