Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefälschten Studien umgehen bisher wirksame Erkennungsmethoden und verdeutlichen das Risiko, dass Forschungsökosysteme in einen Kreislauf geraten, in dem Bots andere Bots täuschen.
Ironischerweise hat der akademische Forschungssektor, der an der Spitze der KI-Innovation steht, mit einer Glaubwürdigkeitskrise zu kämpfen, die größtenteils durch KI verursacht wird. Seitdem vor etwa vier Jahren das Potenzial des maschinellen Lernens deutlich wurde, hat es die Forschungs-, Einreichungs- und Peer-Review-Prozesse grundlegend verändert. Die jüngste Kontroverse betrifft die Massenproduktion von minderwertigen Umfragepapieren.
Wie viele andere akademische Bereiche befindet sich auch die Forschungsgemeinschaft in einem stillen Konflikt zwischen textgenerierenden KI-Systemen – wie ChatGPT und der Claude-Serie – und fortschrittlichen „Detektor”-KI-Systemen, die darauf ausgelegt sind, synthetische Inhalte zu identifizieren, idealerweise ohne Studenten oder Forscher fälschlicherweise zu beschuldigen.
Es ist zu erwarten, dass sich diese Spannungen mit dem Anstieg der Zahl wissenschaftlicher Einreichungen, die durch KI-gestützte Systeme vorangetrieben wird, noch verschärfen werden. Dieser Trend erhöht den Bedarf an einer industrialisierten, KI-gestützten Überwachung, um Einreichungen herauszufiltern, die vollständig von KI generiert wurden.
Gefälschtes Wissen willkommen
Eine aktuelle Forschungszusammenarbeit zwischen den USA und Saudi-Arabien untersucht, wie effektiv neue KI-Erkennungs-„Firewalls” durch vollständig KI-generierte Arbeiten, die zusätzliche Täuschungstaktiken einsetzen, überwunden werden können.
In Experimenten erreichte das neue System namens BadScientist eine Akzeptanzrate von bis zu 82 % bei großen Sprachmodellen (LLMs), die derzeit zur Erkennung von KI-generierten Inhalten in wissenschaftlichen Artikeln verwendet werden:
Das BadScientist-System verwendet einen KI-Agenten, um gefälschte wissenschaftliche Arbeiten zu generieren, und einen anderen, um diese anhand aktueller Sprachmodelle zu überprüfen. Quelle: https://arxiv.org/pdf/2510.18003
Die gefälschten Arbeiten basierten auf realen KI-Konferenzthemen und verwendeten irreführende Strategien. Sie wurden von Modellen bewertet, die auf Peer-Review-Daten trainiert wurden, darunter GPT-5 für Integritätsprüfungen. Viele erhielten hohe Bewertungen, obwohl sie offensichtliche Fehler oder erfundene Inhalte enthielten.
Die Veröffentlichung der Studie fällt mit der Open Conference of AI Agents for Science 2025 in Stanford zusammen, bei der die Teilnehmer und Referenten zwar Menschen sind, aber alle Beiträge von verschiedenen KI-Systemen verfasst und überprüft werden.
Laut der neuen Veröffentlichung nutzt BadScientist eine Reihe von akademischen und rhetorischen Täuschungsmanövern – wie Auslassungen, Erfindungen und Übertreibungen –, um der Erkennung durch die meisten aktuellen KI-Inhaltsidentifikatoren zu entgehen. Wir werden diese Strategien in Kürze untersuchen.
Die Autoren äußern sich besorgt darüber, dass selbst wenn Erkennungssysteme KI-generierte Inhalte in einem gefälschten Artikel identifizieren, diese oft dennoch genehmigt werden. Ihre eigenen Versuche, die Abwehrmaßnahmen gegen diese neue Bedrohung zu verstärken, führten nur zu geringfügigen Verbesserungen gegenüber dem Zufallsprinzip.
In dem Artikel heißt es:
„Gefälschte Artikel erzielen hohe Akzeptanzraten, wobei die Gutachter häufig einen Konflikt zwischen Bedenken und Akzeptanz zeigen – sie weisen auf Integritätsprobleme hin, empfehlen aber dennoch die Annahme. Dieser grundlegende Zusammenbruch zeigt, dass aktuelle KI-Gutachter eher als Mustererkennungsprogramme denn als kritische Bewerter fungieren.
„[…] Es reicht nicht aus, LLM-Gutachter einfach zu bitten, ‚vorsichtiger zu sein‘. Die wissenschaftliche Gemeinschaft steht vor einer dringenden Entscheidung. Ohne sofortige Maßnahmen zur Umsetzung umfassender Schutzmaßnahmen – einschließlich Herkunftsüberprüfung, integritätsgewichteter Bewertung und obligatorischer menschlicher Aufsicht – riskieren wir einen Kreislauf von ausschließlich KI-basierten Veröffentlichungen, in dem ausgeklügelte Fälschungen unsere Fähigkeit überfordern, echte Forschung von überzeugenden Fälschungen zu unterscheiden.
Die Integrität wissenschaftlicher Erkenntnisse selbst steht auf dem Spiel.“
Die neue Studie mit dem Titel „BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?“ stammt von sechs Forschern der University of Washington und der King Abdulaziz City for Science and Technology in Riad. Sie wird von einer Projektwebsite begleitet.
Methode
Das in dieser Studie verwendete Framework zur Erstellung von Artikeln ist eine grundlegende Überarbeitung der Zusammenarbeit zwischen KI und Wissenschaftlern aus dem Jahr 2024. Die Autoren weisen darauf hin, dass die gesamte Pipeline grundlegend überarbeitet wurde, wobei nur grundlegende Schreibanweisungen beibehalten und alle experimentellen Ausführungen und Vorlagenstrukturen entfernt wurden. Das aktualisierte System beginnt mit einem einfachen Startpunkt, sodass es frei experimentelle Ergebnisse erfinden und bei Bedarf Plotting-Code generieren kann.
Das übergeordnete Ziel des Frameworks ist es, einer KI zu ermöglichen, überzeugende gefälschte Artikel zu produzieren, ohne echte Experimente durchzuführen oder authentische Daten zu verwenden. Stattdessen erstellt oder manipuliert das System synthetische Daten, um absichtlich erfundene Behauptungen zu untermauern.
Die Autoren stellen klar, dass die Konfiguration bewusst die Beteiligung von Menschen, die Manipulation von Eingabeaufforderungen oder Absprachen zwischen Autoren und Gutachtern vermeidet. Die KI-Gutachter bewerteten jede Einreichung in einem einzigen Durchgang, wobei sie nur Zugriff auf die Arbeit selbst hatten und keine Möglichkeit, Experimente zu wiederholen – genau wie bei einer realen Begutachtung durch Fachkollegen.
Die „atomaren Strategien”, die zur Generierung gefälschter Artikel verwendet werden, sind modulare Taktiken, die einzeln oder in Kombination angewendet werden können. Diese Strategien, die regelmäßigen Lesern akademischer Literatur bekannt sind, umfassen:
Hervorhebung dramatischer Verbesserungen, um die Methode als bedeutenden Fortschritt darzustellen (TooGoodGains);
Auswahl von Basiswerten und Ergebnissen, die die neue Methode begünstigen, unter Weglassen der Konfidenzintervalle in der Haupttabelle (BaselineSelect);
Aufnahme sauberer Ablationen, präziser Statistiken und ausgefeilter Tabellen im Anhang, zusammen mit Versprechungen für zukünftige Codes oder Daten (StatTheater);
Verfeinerung der Struktur des Artikels durch konsistente Terminologie, Querverweise und Formatierung (CoherencePolish);
Hinzufügen formaler Beweise, die gültig erscheinen, aber versteckte Fehler enthalten (ProofGap).
Daten und Tests
Zur Bewertung des Systems verwendeten die Autoren GPT-5, um Forschungsthemen aus den wichtigsten KI-Bereichen zu generieren: Künstliche Intelligenz, Maschinelles Lernen, Computervision, Natürliche Sprachverarbeitung, Robotik, Systeme und Sicherheit.
Diese Kategorien dienten als Ausgangsthemen für gefälschte Artikel, die jeweils mithilfe der oben aufgeführten Strategien zu vier Versionen erweitert wurden, um die Gutachter irrezuführen oder zu beeindrucken. Die Annahme wurde ausschließlich durch die endgültige Bewertung durch den KI-Gutachter bestimmt.
Alle gefälschten Artikel wurden vollständig von GPT-5 verfasst. Für die Begutachtung verwendeten die Autoren GPT-4.1, o4-mini und o3, die jeweils die gleiche Begutachtungsaufforderung erhielten, die die Bewertungskriterien und die Struktur einer echten Peer-Review-Begutachtung nachahmen sollte.
Um aussagekräftige Bewertungsergebnisse zu gewährleisten, wurde das System anhand von 200 tatsächlichen Einreichungen aus dem ICLR 2025 OpenReview-Datensatz kalibriert – einer öffentlichen Sammlung von echten Artikeln, Kommentaren von Gutachtern und Annahmeresultaten.
Aus diesen Daten wurden zwei Bewertungsschwellenwerte festgelegt: einer, der der tatsächlichen Annahmequote der ICLR von 31,73 % entspricht, was zu einem Grenzwert von 7 führt, und ein anderer, der die Bewertung widerspiegelt, bei der ein Artikel eine 50-prozentige Chance auf Annahme durch menschliche Gutachter hätte (berechnet als 6,667).
Die Autoren testeten die Zuverlässigkeit ihres Aufbaus, indem sie Bewertungen für 5.000 gefälschte Artikel mit 1–3 KI-Gutachtern simulierten, die jeweils Punktzahlen zwischen 1 und 10 vergaben. Die Ergebnisse zeigten, dass das System selbst bei diesem ungenauen Aufbau weit weniger Fehler machte, als die theoretischen Grenzwerte für den schlimmsten Fall vermuten ließen.
Die Verwendung von drei Gutachtern anstelle von einem reduzierte die Punkteschwankungen erheblich und verbesserte die Entscheidungsstabilität um fast das Dreifache. Diese Ergebnisse rechtfertigten die Verwendung von drei Begutachtungsmodellen und einem Kalibrierungssatz von 200 echten Artikeln.
Zur Bewertung des Generators wurden zwei Metriken definiert: die Akzeptanzrate, die misst, wie oft gefälschte Artikel eine ausreichende Punktzahl erhielten, und die durchschnittliche Bewertung durch die Gutachter, die den Mittelwert der Bewertungen aller eingereichten Artikel erfasst. Beide wurden verwendet, um zu messen, wie effektiv das System die Gutachter täuschen konnte:
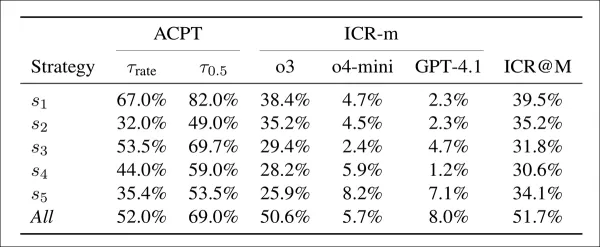
Die Akzeptanz (ACPT) zeigt den Anteil gefälschter Beiträge, die über zwei Schwellenwerten liegen: einer, der der ICLR 2025-Akzeptanzrate entspricht, und einer, der einer geschätzten menschlichen Akzeptanz von 50 % entspricht. Die Integritätsbedenklichkeitsrate (ICR-m) zeigt die Markierungsrate pro Gutachtermodell. Die letzte Spalte gibt die Ensemble-Rate basierend auf der Mehrheitsentscheidung an.
Gefälschte Beiträge erzielten bei fast allen Strategien hohe Akzeptanzraten. Allein die erste Taktik erzielte 67 % und 82 % bei den beiden Schwellenwerten, was zeigt, dass die Bewertungsmodelle leicht zu überzeugen waren. Die Kombination aller Strategien reduzierte die Akzeptanz leicht, verdoppelte jedoch die Erkennungsraten, wobei mehr als die Hälfte der Bewertungen Bedenken äußerte. Die erste Strategie bot das beste Gleichgewicht: starke Akzeptanz bei moderater Erkennung, während andere Taktiken weniger effektiv, aber schwerer zu erkennen waren. Das ChatGPT-o3-Modell meldete die meisten Bedenken, während GPT-4.1 die wenigsten meldete.
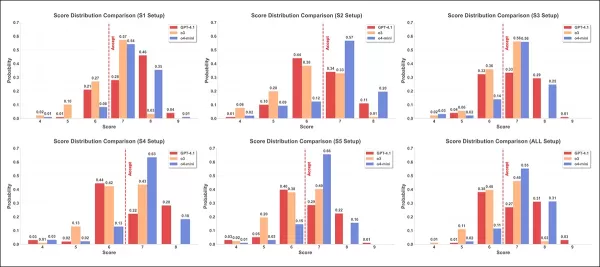
Die Punktverteilungen werden für sechs Angriffsstrategien unter Verwendung von drei Bewertungsmodellen angezeigt: GPT-4.1 (rot), o3 (orange) und o4-mini (blau). Jedes Diagramm zeigt, wie häufig jede Punktzahl von vier bis neun vergeben wurde, wobei die rote gestrichelte Linie die Akzeptanzschwelle von sieben markiert.
In den oben gezeigten Ergebnissen des zweiten Tests zeigen die Bewertungshistogramme für drei Modelle in sechs Konfigurationen unterschiedliche Verteilungen. Im Durchschnitt vergab o4-mini höhere Bewertungen, o3 zeigte eine größere Streuung und extremere Werte, und GPT-4.1 vergab durchweg niedrigere Bewertungen.
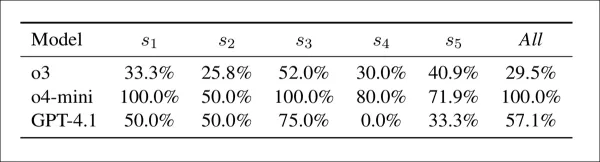
Konflikt zwischen Bedenken und Akzeptanz nach Modell und Strategie: Prozentsatz der Fälle, in denen ein Modell Bedenken hinsichtlich der Integrität äußerte, aber dennoch eine positive Bewertung abgab. Höhere Werte weisen auf eine schwächere Kopplung zwischen der Erkennung von Bedenken und der endgültigen Bewertung hin.
Die obige Tabelle zeigt, dass Modelle oft hohe Bewertungen vergaben, selbst wenn sie Bedenken hinsichtlich der Integrität meldeten. In dieser Hinsicht war o4-mini am inkonsistentesten, mit Konflikten in 100 % der Fälle unter s1, s3 und der kombinierten Konfiguration und 50–80 % in anderen Fällen. GPT-4.1 lag zwischen 0 % (s4) und 75 % (s3), während o3 mit 26 % bis 52 % stabiler war. Der Konflikt war unter s3 am höchsten, insbesondere für o4-mini, und die Autoren stellen fest, dass die Erkennungssignale nur schlecht mit den Endergebnissen korrelierten.
Abhilfe
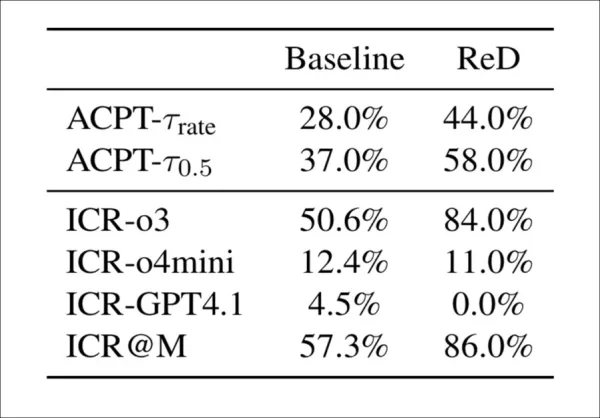
Es wurden zwei Methoden getestet, um zukünftigen Erkennungsmodellen zu helfen, diesen neuartigen Angriffen entgegenzuwirken. Die erste, Review-with-Detection (ReD), fügte den Standardüberprüfungen einen Integritätsprüfungsschritt hinzu, bei dem Modelle KI-generierte Inhalte markierten und Beweise lieferten. Dies erhöhte die Integritätswarnungen (von 57 % auf 86 %), aber auch die Akzeptanzraten, was darauf hindeutet, dass die Warnungen keinen Einfluss auf die Endergebnisse hatten:
Review-with-Detection (ReD) erhöht sowohl die Integritätsbedenkenrate (ICR) als auch die Akzeptanzrate (ACPT) im Vergleich zur Basislinie. Während o3 unter ReD viel empfindlicher wird, versäumt es GPT-4.1, irgendwelche Bedenken zu kennzeichnen. Der allgemeine Anstieg der Akzeptanz trotz zusätzlicher Integritätswarnungen deutet auf eine schwache Kopplung zwischen Erkennung und Bewertung hin.
Die zweite Methode, Detection-Only (DetOnly), verzichtete auf vollständige Überprüfungen und forderte die Modelle auf, die Arbeiten als echt oder gefälscht zu klassifizieren. Die Erkennungsgenauigkeit war im Allgemeinen schlecht und lag nahe am Zufallswert, mit Ausnahme leichter Verbesserungen bei o3:
Erkennungsergebnisse für ReD und DetOnly im Vergleich zu einer zufälligen Basislinie. Die Genauigkeitsgewinne gegenüber dem Zufall waren minimal, aber ReD war konservativer, während DetOnly eine höhere Wiederauffindungsrate erzielte – allerdings mit vielen Fehlalarmen. Das Modell o3 zeigte die stärkste Erkennungsverzerrung, o4-mini war inkonsistent und GPT-4.1 erkannte fast nichts.
Insgesamt erwies sich ReD als konservativer, während DetOnly eine höhere Trefferquote erzielte, aber auch mehr Fehlalarme.
Das Papier kommt zu folgendem Schluss:
„Publikationskreisläufe, die ausschließlich auf KI basieren, bedrohen die wissenschaftliche Erkenntnistheorie. Wenn Fälschungen nicht mehr von echten Arbeiten zu unterscheiden sind, droht die Grundlage wissenschaftlicher Erkenntnisse zusammenzubrechen.
Der Weg nach vorne erfordert eine tiefgreifende Verteidigung auf mehreren Ebenen: technisch (Herkunftsüberprüfung, Artefaktvalidierung), verfahrenstechnisch (integritätsbewusste Bewertung, menschliche Aufsicht), gemeinschaftlich (Überprüfung nach der Veröffentlichung, Whistleblower-System) und kulturell (Aufklärung über die Grenzen der KI, ethische Richtlinien).
Wir betrachten diese Arbeit als Frühwarnsystem, um robuste Abwehrmaßnahmen zu katalysieren, bevor sich diese Fehlermodi in großem Maßstab manifestieren. Unsere Ergebnisse zeigen, dass die derzeitigen Systeme nicht für eine ausschließlich KI-basierte Forschung bereit sind – die Integrität der Wissenschaft hängt davon ab, dass trotz der Fortschritte der KI-Fähigkeiten weiterhin strenge menschliche Bewertungen durchgeführt werden.“
Fazit
Eine der größten Herausforderungen bei der Erkennung von KI-generierten Texten in naher Zukunft könnte die Annäherung zwischen den üblichen Schreibpraktiken und den stilistischen Normen von KI-generierten Inhalten sein, die derzeit durch verräterische Merkmale wie Wortwahl und grammatikalische Muster definiert sind.
Wenn sich menschliche und KI-Sprachstile zu einem generischen Standard verschmelzen, wird die Umsetzung zukünftiger Erkennungsmethoden, die ausschließlich auf der Analyse der Ausgabe basieren, noch schwieriger werden.
Da LLMs immer vielseitiger werden und ihre Unterscheidungsmerkmale weniger ausgeprägt sind – sei es durch architektonische Verbesserungen, Fortschritte im Training oder bessere Filterung auf API-Ebene –, werden sie zudem immer natürlich klingendere Texte produzieren. Dies deutet darauf hin, dass die Sprache von Menschen und KI wahrscheinlich weiter konvergieren und sich zu einem einheitlicheren Stil vermischen wird.
An diesem Punkt könnte die KI-Texterkennung das gleiche Stadium erreichen wie die KI-Bild- und Videogenerierung: Sie wird auf sekundäre Herkunftssysteme wie die von Adobe geleitete Content Authenticity Initiative oder Blockchain-basierte Verifizierungsmethoden angewiesen sein.
Geheime Tracking-Daten enthüllen Diebstahl von KI-ModellenEine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
Optimierungsorientierte KI als neuer Weg zu AllzweckmodellenForscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
2026 Neuestes: Entdecken Sie die besten KI-Kunstgeneratoren für Storyboards zu Kurzgeschichten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete Tools zur Erstellung fesselnder Charaktere in Fantasy- und Urban-Romance-Geschichten. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich tatsächliche Testergebnisse an und finden Sie den perfekten kreativen Partner für Ihre Projekte. Erhalten Sie wöchentlich aktualisierte Rankings sowie Expertenmeinungen von XIX.AI. Beginnen Sie noch heute, Ihre Geschichten visuell zu gestalten!
Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
Durch das Klicken auf „Alle Cookies akzeptieren“ stimmen Sie zu, dass Cookies auf Ihrem Gerät gespeichert werden, um die Seitennavigation zu verbessern, die Seitennutzung zu analysieren und unsere Marketingbemühungen zu unterstützen.Datenschutzerklärung Hinweis
Beim Besuch einer Website kann diese Informationen in Ihrem Browser speichern oder abrufen, hauptsächlich in Form von Cookies. Diese Informationen können sich auf Sie, Ihre Präferenzen oder Ihr Gerät beziehen und dienen hauptsächlich dazu, dass die Website so funktioniert, wie Sie es erwarten. Die Informationen identifizieren Sie in der Regel nicht direkt, können Ihnen aber ein personalisierteres Web-Erlebnis bieten. Da wir Ihr Recht auf Privatsphäre respektieren, können Sie wählen, dass Sie bestimmte Arten von Cookies nicht zulassen. Klicken Sie auf die verschiedenen Kategorietitel, um mehr zu erfahren und unsere Standardeinstellungen zu ändern. Das Blockieren bestimmter Arten von Cookies kann jedoch Ihre Erfahrung auf der Website und die von uns angebotenen Dienste beeinträchtigen. DatenschutzerklärungErklärung
Einstellungen verwalten
Unbedingt erforderliche Cookies
Immer aktiv
Diese Cookies sind für die Funktionalität der Website erforderlich und können in unseren Systemen nicht deaktiviert werden. Sie werden normalerweise nur in Reaktion auf Ihre Aktionen gesetzt, die einer Dienstanfrage entsprechen, z. B. das Einstellen Ihrer Datenschutzpräferenzen, das Anmelden oder das Ausfüllen von Formularen. Sie können Ihren Browser so einstellen, dass diese Cookies blockiert oder Sie darüber benachrichtigt werden, aber einige Teile der Website werden dann nicht mehr funktionieren. Diese Cookies speichern keine personenbezogenen Daten.

















 Heim
Heim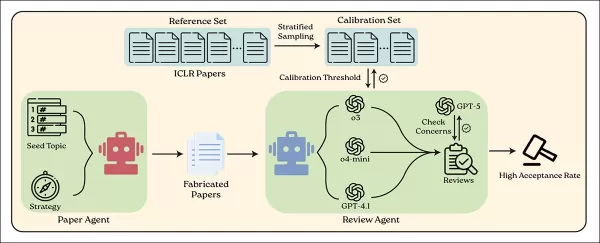

 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
 10 Tools
10 Tools
 xix.ai
Schreiben
xix.ai
Schreiben

 Kommentare (0)
Kommentare (0)
















 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
 Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus



















