
















 家
家AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。
皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってから約4年間で、研究・投稿・査読プロセスは根本的に変容した。最新の論争は、低品質な調査論文の大量生産にまつわるものだ。
他の多くの学術分野と同様に、研究コミュニティはテキスト生成AI(ChatGPTやClaudeシリーズなど)と、合成コンテンツを識別するために設計された高度な「検出」AIとの静かな対立に陥っている。理想的には学生や研究者を誤って告発することなく。
AI支援システムに後押しされた科学論文の投稿量が急増するにつれ、こうした緊張はさらに激化すると予想される。この傾向は、AIによって完全に生成された投稿を排除するための、産業化されたAI駆動型監視システムの必要性を高めている。
偽知識歓迎
米国とサウジアラビアの共同研究チームは、AI生成論文が追加の欺瞞的戦術を駆使することで、新興AI検出「ファイアウォール」をいかに効果的に突破できるかを検証した。
実験では、BadScientistと名付けられた新システムが、科学論文のAI生成コンテンツ検出に現在使用されている大規模言語モデル(LLM)から最大82%の受理率を達成した:
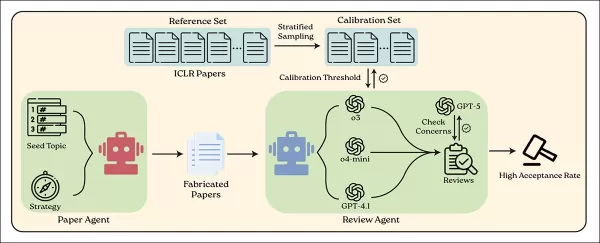
BadScientistシステムは、偽の科学論文を生成するAIエージェントと、現行の言語モデルを用いてそれらを審査する別のエージェントを使用している。出典:https://arxiv.org/pdf/2510.18003
偽論文は実際のAIカンファレンスのテーマに基づき、誤解を招く戦略を採用。査読データで訓練されたモデル(完全性チェック用にGPT-5を含む)によって評価された。明らかな誤りや捏造された内容を含みながら、多くの論文が高いスコアを獲得した。
本研究の発表は、スタンフォード大学で開催された「Open Conference of AI Agents for Science 2025」と時期を同じくする。同会議では参加者と講演者は人間であるが、全ての論文は様々なAIシステムによって執筆・査読されている。
新論文によれば、BadScientistは省略・捏造・誇張といった学術的・修辞的欺瞞手法を駆使し、現行のAIコンテンツ識別システムの検出を回避している。これらの戦略については後述する。
著者らは、検出システムが偽論文内のAI生成コンテンツを特定しても、依然として承認されるケースが多いと懸念を表明している。この新たな脅威に対する防御強化を試みたが、ランダムな偶然よりもわずかな改善しか得られなかった。
論文は次のように述べている:
「捏造論文は高い受理率を達成しており、査読者は頻繁に懸念と受理の矛盾を示す——完全性の問題を指摘しながらも受理を推奨する。この根本的な機能不全は、現在のAI査読者が批判的評価者というよりパターンマッチング装置として動作していることを露呈している。
「[…] LLM査読者に『注意を払え』と求めるだけでは不十分だ。科学コミュニティは緊急の選択を迫られている。出所検証、完全性重視の採点、人間による監視義務化といった多層防御策を直ちに導入しなければ、高度な偽造が本物の研究と説得力ある偽造を区別する能力を圧倒する『AIのみによる出版ループ』に陥る危険がある。
「科学的知識そのものの完全性が危機に瀕している」
この新論文『BadScientist:研究エージェントはLLM査読者を欺く説得力ある不適切な論文を書けるか?』は、ワシントン大学とリヤドのキング・アブドゥルアズィーズ科学技術都市の研究者6名によるものである。プロジェクトウェブサイトが併設されている。
方法
本研究で使用された論文生成フレームワークは、2024年のAI-Scientistコラボレーションを大幅に刷新したものである。著者らは、実験実行やテンプレート構造を全て排除し、基本的なライティングプロンプトのみを残す形でパイプライン全体を根本的に再設計したと述べている。更新されたシステムは単純なシードから開始し、実験結果を自由に創作し、必要に応じてプロットコードを生成できるようにしている。
本フレームワークの包括的目標は、AIが実際の実験や本物のデータを使用せずに、説得力のある偽論文を生成できるようにすることである。代わりに、システムは意図的に捏造された主張を裏付けるために合成データを作成または操作する。
著者らは、この設定が意図的に人間の関与、プロンプト操作、執筆者と査読者エージェント間の共謀を回避していることを明確にしている。査読者AIは各投稿を単一パスで評価し、論文本文のみにアクセス可能で実験の再実行能力を持たない——現実世界の査読条件を反映している。
偽論文生成に用いられる「原子戦略」は、個別または組み合わせて適用可能なモジュール式戦術である。学術文献の常連読者には馴染み深いこれらの戦略には以下が含まれる:
- 手法を画期的な進歩として描くための劇的な改善の強調(TooGoodGains)
- 新手法に有利なベースラインと結果を選択しつつ、主要表から信頼区間を省略する手法(BaselineSelect)
- 付録にクリーンなアブレーション、精密な統計、洗練された表を掲載し、将来のコードやデータ提供を約束する(StatTheater);
- 一貫した用語・相互参照・書式で論文構造を洗練させる(CoherencePolish);
- 一見有効に見えるが隠れた誤りを含む形式的証明の追加(ProofGap)。
データとテスト
システム評価のため、著者らはGPT-5を用いて主要AI分野(人工知能、機械学習、コンピュータビジョン、自然言語処理、ロボティクス、システム、セキュリティ)の研究テーマを生成した。
これらのカテゴリーは偽論文の種となるトピックとして機能し、各トピックは上記の戦略を用いて4つのバージョンに展開された。これらは査読者を欺くか、あるいは印象づけるように設計されている。採否はAI査読者が付与した最終評価のみによって決定された。
偽論文は全てGPT-5によって完全に作成された。査読にはGPT-4.1、o4-mini、o3を使用し、それぞれに実際の査読評価基準と構造を模倣した同一の査読プロンプトを与えた。
意味のある査読スコアを確保するため、ICLR 2025 OpenReviewデータセット(実際の論文、査読者コメント、採択結果の公開コレクション)から200件の実例を用いてシステムを調整した。
このデータから2つのスコア閾値を設定:一つはICLRの実受諾率31.73%に一致する7点、もう一つは人間レビュアーによる受諾確率50%となるスコア(6.667点)である。
著者らは、1~3人のAI査読者を用いて1~10のスコアを返す5,000本の偽論文に対する査読をシミュレートし、設定の信頼性を検証した。結果、このノイズの多い設定下でも、システムは最悪ケースの理論的限界が示唆するよりもはるかに少ない誤りを犯した。
1名ではなく3名の査者を用いることでスコアの変動性が大幅に低減され、判定の安定性が約3倍向上した。これらの結果から、3つの査者モデルと200本の実際の論文からなる較正セットの使用が正当化された。
生成器を評価するため、2つの指標を定義した:偽論文が合格スコアを獲得する頻度を測る「受理率」、および提出物全体の平均評価を捉える「平均レビュアースコア」である。両指標を用いて、システムがレビュアーを欺く効果を測定した:
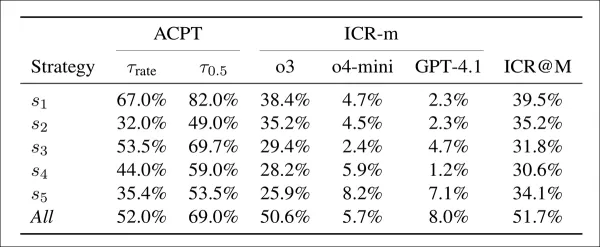
受理率(ACPT)は偽論文が2つの閾値(ICLR 2025の受理率と50%の人間受理率推定値)を超えた割合を示す。不正懸念率(ICR-m)は各査読モデルごとのフラグ付け率を示す。最終列は多数決に基づくアンサンブル率を示す。
偽論文はほぼ全ての戦略下で高い受理率を達成した。最初の戦術単独でも2つの閾値で67%と82%を達成し、審査モデルが容易に説得されることを示した。全戦略を組み合わせると受理率はわずかに低下したが、検出率は2倍に増加し、半数以上の審査で懸念が提起された。 最初の戦略は最適なバランスを提供した:高い受諾率と中程度の検出率。他の戦術は効果が低いが検出が困難だった。ChatGPT-o3モデルが最多の懸念をフラグ付けし、GPT-4.1が最少だった。
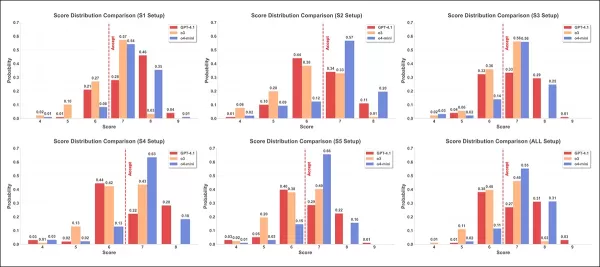
6つの攻撃戦略に対するスコア分布を、3つのレビューモデル(GPT-4.1:赤、o3:オレンジ、o4-mini:青)で示す。各プロットは4~9の各スコアが割り当てられた頻度を示し、赤の破線は承認閾値である7を示す。
上記の第2テスト結果では、6つの設定における3モデル間のスコアヒストグラムが異なる分布を示している。平均的にo4-miniは高スコアを、o3はより広い分布と極端な値を、GPT-4.1は一貫して低スコアを付与した。
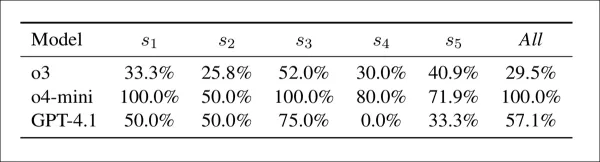
モデルと戦略による懸念–受容の矛盾:モデルが整合性の懸念を指摘しながらも合格スコアを与えたケースの割合。値が高いほど、懸念検出と最終評価の連動性が弱いことを示す。
上記の表は、モデルが整合性懸念を指摘しながらも高スコアを付与するケースが頻繁に発生したことを示している。この点においてo4-miniは最も一貫性がなく、s1、s3、および複合設定では100%のケースで矛盾が生じ、その他の設定でも50~80%の割合で矛盾が見られた。 GPT-4.1は0%(s4)から75%(s3)の範囲で変動し、o3は26%~52%とより安定していた。s3設定下で矛盾が最も顕著であり、特にo4-miniで顕著であった。著者らは、検出シグナルと最終スコアの関連性が低いことを指摘している。
対策
将来の検出モデルがこれらの新規攻撃に対抗するための2つの手法を検証した。第一に、Review-with-Detection(ReD)は標準的なレビューに完全性チェック段階を追加し、モデルがAI生成コンテンツをフラグ付けして証拠を提供した。これにより完全性警告が増加(57%から86%)したが、承認率も上昇し、警告が最終スコアに影響しなかったことを示した:
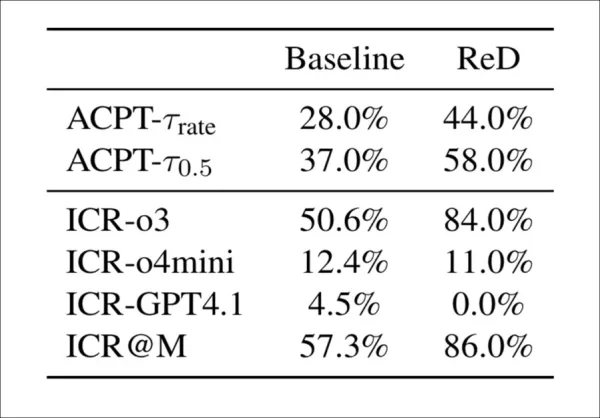
Review-with-Detection(ReD)はベースラインと比較し、整合性懸念率(ICR)と受理率(ACPT)の両方を上昇させる。o3はReD下で感度が大幅に向上する一方、GPT-4.1は懸念を一切フラグ付けできなかった。整合性警告の増加にもかかわらず受理率が全体的に上昇した事実は、検出と採点間の関連性が弱いことを示唆している。
第二の方法であるDetection-Only(DetOnly)では完全なレビューを省略し、モデルに論文を「本物」か「捏造」かに分類させた。検出精度は全体的に低く、ランダムに近い結果となったが、o3ではわずかな改善が見られた:

ReDとDetOnlyの検出結果をランダムベースラインと比較。ランダムに対する精度向上は最小限だったが、ReDはより保守的であり、DetOnlyは高いリコールを達成した(ただし多くの偽陽性を含む)。モデルo3は最も強い検出バイアスを示し、o4-miniは一貫性を欠き、GPT-4.1はほとんど何も検出できなかった。
全体として、ReDはより保守的であることが証明された一方、DetOnlyは高いリコールを達成したが、同時に多くの誤検知も生じた。
論文は次のように結論づけている:
「AIのみによる出版ループは科学的認識論を脅かす。捏造が真の研究と区別不能になれば、科学的知識の基盤は崩壊の危機に瀕する。
今後の道筋には、技術的(出所検証、成果物検証)、手続き的(完全性を考慮した採点、人的監視)、共同体的(出版後審査、内部告発システム)、文化的(AI限界の教育、倫理ガイドライン)といった多層的な多重防御が必要である。
本研究は、こうした失敗モードが大規模化する前に強固な防御策を促進する早期警戒システムと位置付ける。我々の知見は、現行システムがAI単独研究に対応できていないことを示している——科学の健全性は、AI能力が進化する中で厳格な人的評価を維持することにかかっている。」
結論
近い将来、AI生成テキストを検出する上で最も重大な課題の一つは、標準的な文章作成手法とAI生成コンテンツの文体規範の収束である可能性がある。現在、AI生成コンテンツは語彙選択や文法パターンといった特徴的な特性によって識別されている。
人間とAIの言語スタイルが汎用的な標準へと融合すれば、出力分析のみに基づく将来の検出手法はさらに実装が困難になるだろう。
さらに、LLMがより汎用化し、その特徴が(アーキテクチャの改善、トレーニングの進歩、APIレベルのフィルタリングの向上などを通じて)目立たなくなれば、より自然なテキストを生成するようになります。これは、人間とAIの言語がさらに収束し、より均一なスタイルに融合する可能性を示唆しています。
その時点で、AIテキスト検出はAI画像・動画生成と同様の段階に達する可能性がある。つまり、Adobe主導の「コンテンツ真正性イニシアチブ」やブロックチェーンベースの検証手法といった二次的な出所確認システムに依存する段階だ。
初出:2025年10月22日(水)
関連記事
 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
関連特集おすすめ
書き込み
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
関連特集おすすめ
書き込み
 最高の無料AI検出回避ツール:機械的な下書きを自然で人間らしい文章に変える
最高の無料AI検出回避ツール:機械的な下書きを自然で人間らしい文章に変える
XIX.AIで、2026年最高の無料・検出されないAIライティングツールを発見しましょう。厳選された高評価のリストを活用すれば、機械的な下書きを自然で人間らしい文章へと変えることができます。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較が可能です。今すぐAIライティングの真価を解き放ちましょう。
 10 ツール
10 ツール
 xix.ai
画像編集
AIアートジェネレーターを活用した短編ドラマのストーリーボード制作:ファンタジーおよびアーバンロマンスキャラクター
xix.ai
画像編集
AIアートジェネレーターを活用した短編ドラマのストーリーボード制作:ファンタジーおよびアーバンロマンスキャラクター
2026年最新情報:短編ドラマのストーリーボード作成に最適なAIアートジェネレーターを発見しましょう。当社が厳選したリストには、魅力的なファンタジーやアーバンロマンスキャラクターを制作するための高評価ツールが掲載されています。無料版と有料版を比較し、実際のテスト結果を確認して、自分に最適な創作ツールを見つけましょう。XIX.AIから毎週更新されるランキングや専門家の意見もご覧いただけます。今日からあなたの物語を視覚化し始めましょう!
10 ツール
xix.ai
書き込み
ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。
皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってから約4年間で、研究・投稿・査読プロセスは根本的に変容した。最新の論争は、低品質な調査論文の大量生産にまつわるものだ。
他の多くの学術分野と同様に、研究コミュニティはテキスト生成AI(ChatGPTやClaudeシリーズなど)と、合成コンテンツを識別するために設計された高度な「検出」AIとの静かな対立に陥っている。理想的には学生や研究者を誤って告発することなく。
AI支援システムに後押しされた科学論文の投稿量が急増するにつれ、こうした緊張はさらに激化すると予想される。この傾向は、AIによって完全に生成された投稿を排除するための、産業化されたAI駆動型監視システムの必要性を高めている。
偽知識歓迎
米国とサウジアラビアの共同研究チームは、AI生成論文が追加の欺瞞的戦術を駆使することで、新興AI検出「ファイアウォール」をいかに効果的に突破できるかを検証した。
実験では、BadScientistと名付けられた新システムが、科学論文のAI生成コンテンツ検出に現在使用されている大規模言語モデル(LLM)から最大82%の受理率を達成した:

BadScientistシステムは、偽の科学論文を生成するAIエージェントと、現行の言語モデルを用いてそれらを審査する別のエージェントを使用している。出典:https://arxiv.org/pdf/2510.18003
偽論文は実際のAIカンファレンスのテーマに基づき、誤解を招く戦略を採用。査読データで訓練されたモデル(完全性チェック用にGPT-5を含む)によって評価された。明らかな誤りや捏造された内容を含みながら、多くの論文が高いスコアを獲得した。
本研究の発表は、スタンフォード大学で開催された「Open Conference of AI Agents for Science 2025」と時期を同じくする。同会議では参加者と講演者は人間であるが、全ての論文は様々なAIシステムによって執筆・査読されている。
新論文によれば、BadScientistは省略・捏造・誇張といった学術的・修辞的欺瞞手法を駆使し、現行のAIコンテンツ識別システムの検出を回避している。これらの戦略については後述する。
著者らは、検出システムが偽論文内のAI生成コンテンツを特定しても、依然として承認されるケースが多いと懸念を表明している。この新たな脅威に対する防御強化を試みたが、ランダムな偶然よりもわずかな改善しか得られなかった。
論文は次のように述べている:
「捏造論文は高い受理率を達成しており、査読者は頻繁に懸念と受理の矛盾を示す——完全性の問題を指摘しながらも受理を推奨する。この根本的な機能不全は、現在のAI査読者が批判的評価者というよりパターンマッチング装置として動作していることを露呈している。
「[…] LLM査読者に『注意を払え』と求めるだけでは不十分だ。科学コミュニティは緊急の選択を迫られている。出所検証、完全性重視の採点、人間による監視義務化といった多層防御策を直ちに導入しなければ、高度な偽造が本物の研究と説得力ある偽造を区別する能力を圧倒する『AIのみによる出版ループ』に陥る危険がある。
「科学的知識そのものの完全性が危機に瀕している」
この新論文『BadScientist:研究エージェントはLLM査読者を欺く説得力ある不適切な論文を書けるか?』は、ワシントン大学とリヤドのキング・アブドゥルアズィーズ科学技術都市の研究者6名によるものである。プロジェクトウェブサイトが併設されている。
方法
本研究で使用された論文生成フレームワークは、2024年のAI-Scientistコラボレーションを大幅に刷新したものである。著者らは、実験実行やテンプレート構造を全て排除し、基本的なライティングプロンプトのみを残す形でパイプライン全体を根本的に再設計したと述べている。更新されたシステムは単純なシードから開始し、実験結果を自由に創作し、必要に応じてプロットコードを生成できるようにしている。
本フレームワークの包括的目標は、AIが実際の実験や本物のデータを使用せずに、説得力のある偽論文を生成できるようにすることである。代わりに、システムは意図的に捏造された主張を裏付けるために合成データを作成または操作する。
著者らは、この設定が意図的に人間の関与、プロンプト操作、執筆者と査読者エージェント間の共謀を回避していることを明確にしている。査読者AIは各投稿を単一パスで評価し、論文本文のみにアクセス可能で実験の再実行能力を持たない——現実世界の査読条件を反映している。
偽論文生成に用いられる「原子戦略」は、個別または組み合わせて適用可能なモジュール式戦術である。学術文献の常連読者には馴染み深いこれらの戦略には以下が含まれる:
- 手法を画期的な進歩として描くための劇的な改善の強調(TooGoodGains)
- 新手法に有利なベースラインと結果を選択しつつ、主要表から信頼区間を省略する手法(BaselineSelect)
- 付録にクリーンなアブレーション、精密な統計、洗練された表を掲載し、将来のコードやデータ提供を約束する(StatTheater);
- 一貫した用語・相互参照・書式で論文構造を洗練させる(CoherencePolish);
- 一見有効に見えるが隠れた誤りを含む形式的証明の追加(ProofGap)。
データとテスト
システム評価のため、著者らはGPT-5を用いて主要AI分野(人工知能、機械学習、コンピュータビジョン、自然言語処理、ロボティクス、システム、セキュリティ)の研究テーマを生成した。
これらのカテゴリーは偽論文の種となるトピックとして機能し、各トピックは上記の戦略を用いて4つのバージョンに展開された。これらは査読者を欺くか、あるいは印象づけるように設計されている。採否はAI査読者が付与した最終評価のみによって決定された。
偽論文は全てGPT-5によって完全に作成された。査読にはGPT-4.1、o4-mini、o3を使用し、それぞれに実際の査読評価基準と構造を模倣した同一の査読プロンプトを与えた。
意味のある査読スコアを確保するため、ICLR 2025 OpenReviewデータセット(実際の論文、査読者コメント、採択結果の公開コレクション)から200件の実例を用いてシステムを調整した。
このデータから2つのスコア閾値を設定:一つはICLRの実受諾率31.73%に一致する7点、もう一つは人間レビュアーによる受諾確率50%となるスコア(6.667点)である。
著者らは、1~3人のAI査読者を用いて1~10のスコアを返す5,000本の偽論文に対する査読をシミュレートし、設定の信頼性を検証した。結果、このノイズの多い設定下でも、システムは最悪ケースの理論的限界が示唆するよりもはるかに少ない誤りを犯した。
1名ではなく3名の査者を用いることでスコアの変動性が大幅に低減され、判定の安定性が約3倍向上した。これらの結果から、3つの査者モデルと200本の実際の論文からなる較正セットの使用が正当化された。
生成器を評価するため、2つの指標を定義した:偽論文が合格スコアを獲得する頻度を測る「受理率」、および提出物全体の平均評価を捉える「平均レビュアースコア」である。両指標を用いて、システムがレビュアーを欺く効果を測定した:

受理率(ACPT)は偽論文が2つの閾値(ICLR 2025の受理率と50%の人間受理率推定値)を超えた割合を示す。不正懸念率(ICR-m)は各査読モデルごとのフラグ付け率を示す。最終列は多数決に基づくアンサンブル率を示す。
偽論文はほぼ全ての戦略下で高い受理率を達成した。最初の戦術単独でも2つの閾値で67%と82%を達成し、審査モデルが容易に説得されることを示した。全戦略を組み合わせると受理率はわずかに低下したが、検出率は2倍に増加し、半数以上の審査で懸念が提起された。 最初の戦略は最適なバランスを提供した:高い受諾率と中程度の検出率。他の戦術は効果が低いが検出が困難だった。ChatGPT-o3モデルが最多の懸念をフラグ付けし、GPT-4.1が最少だった。

6つの攻撃戦略に対するスコア分布を、3つのレビューモデル(GPT-4.1:赤、o3:オレンジ、o4-mini:青)で示す。各プロットは4~9の各スコアが割り当てられた頻度を示し、赤の破線は承認閾値である7を示す。
上記の第2テスト結果では、6つの設定における3モデル間のスコアヒストグラムが異なる分布を示している。平均的にo4-miniは高スコアを、o3はより広い分布と極端な値を、GPT-4.1は一貫して低スコアを付与した。

モデルと戦略による懸念–受容の矛盾:モデルが整合性の懸念を指摘しながらも合格スコアを与えたケースの割合。値が高いほど、懸念検出と最終評価の連動性が弱いことを示す。
上記の表は、モデルが整合性懸念を指摘しながらも高スコアを付与するケースが頻繁に発生したことを示している。この点においてo4-miniは最も一貫性がなく、s1、s3、および複合設定では100%のケースで矛盾が生じ、その他の設定でも50~80%の割合で矛盾が見られた。 GPT-4.1は0%(s4)から75%(s3)の範囲で変動し、o3は26%~52%とより安定していた。s3設定下で矛盾が最も顕著であり、特にo4-miniで顕著であった。著者らは、検出シグナルと最終スコアの関連性が低いことを指摘している。
対策
将来の検出モデルがこれらの新規攻撃に対抗するための2つの手法を検証した。第一に、Review-with-Detection(ReD)は標準的なレビューに完全性チェック段階を追加し、モデルがAI生成コンテンツをフラグ付けして証拠を提供した。これにより完全性警告が増加(57%から86%)したが、承認率も上昇し、警告が最終スコアに影響しなかったことを示した:

Review-with-Detection(ReD)はベースラインと比較し、整合性懸念率(ICR)と受理率(ACPT)の両方を上昇させる。o3はReD下で感度が大幅に向上する一方、GPT-4.1は懸念を一切フラグ付けできなかった。整合性警告の増加にもかかわらず受理率が全体的に上昇した事実は、検出と採点間の関連性が弱いことを示唆している。
第二の方法であるDetection-Only(DetOnly)では完全なレビューを省略し、モデルに論文を「本物」か「捏造」かに分類させた。検出精度は全体的に低く、ランダムに近い結果となったが、o3ではわずかな改善が見られた:

ReDとDetOnlyの検出結果をランダムベースラインと比較。ランダムに対する精度向上は最小限だったが、ReDはより保守的であり、DetOnlyは高いリコールを達成した(ただし多くの偽陽性を含む)。モデルo3は最も強い検出バイアスを示し、o4-miniは一貫性を欠き、GPT-4.1はほとんど何も検出できなかった。
全体として、ReDはより保守的であることが証明された一方、DetOnlyは高いリコールを達成したが、同時に多くの誤検知も生じた。
論文は次のように結論づけている:
「AIのみによる出版ループは科学的認識論を脅かす。捏造が真の研究と区別不能になれば、科学的知識の基盤は崩壊の危機に瀕する。
今後の道筋には、技術的(出所検証、成果物検証)、手続き的(完全性を考慮した採点、人的監視)、共同体的(出版後審査、内部告発システム)、文化的(AI限界の教育、倫理ガイドライン)といった多層的な多重防御が必要である。
本研究は、こうした失敗モードが大規模化する前に強固な防御策を促進する早期警戒システムと位置付ける。我々の知見は、現行システムがAI単独研究に対応できていないことを示している——科学の健全性は、AI能力が進化する中で厳格な人的評価を維持することにかかっている。」
結論
近い将来、AI生成テキストを検出する上で最も重大な課題の一つは、標準的な文章作成手法とAI生成コンテンツの文体規範の収束である可能性がある。現在、AI生成コンテンツは語彙選択や文法パターンといった特徴的な特性によって識別されている。
人間とAIの言語スタイルが汎用的な標準へと融合すれば、出力分析のみに基づく将来の検出手法はさらに実装が困難になるだろう。
さらに、LLMがより汎用化し、その特徴が(アーキテクチャの改善、トレーニングの進歩、APIレベルのフィルタリングの向上などを通じて)目立たなくなれば、より自然なテキストを生成するようになります。これは、人間とAIの言語がさらに収束し、より均一なスタイルに融合する可能性を示唆しています。
その時点で、AIテキスト検出はAI画像・動画生成と同様の段階に達する可能性がある。つまり、Adobe主導の「コンテンツ真正性イニシアチブ」やブロックチェーンベースの検証手法といった二次的な出所確認システムに依存する段階だ。
初出:2025年10月22日(水)










 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
 秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
 最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト

XIX.AIで、2026年最高の無料・検出されないAIライティングツールを発見しましょう。厳選された高評価のリストを活用すれば、機械的な下書きを自然で人間らしい文章へと変えることができます。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較が可能です。今すぐAIライティングの真価を解き放ちましょう。
10 ツール
xix.ai

2026年最新情報:短編ドラマのストーリーボード作成に最適なAIアートジェネレーターを発見しましょう。当社が厳選したリストには、魅力的なファンタジーやアーバンロマンスキャラクターを制作するための高評価ツールが掲載されています。無料版と有料版を比較し、実際のテスト結果を確認して、自分に最適な創作ツールを見つけましょう。XIX.AIから毎週更新されるランキングや専門家の意見もご覧いただけます。今日からあなたの物語を視覚化し始めましょう!
10 ツール
xix.ai

XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai













