Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos eluden los métodos de detección que antes eran eficaces, lo que pone de relieve el riesgo de que los ecosistemas de investigación caigan en ciclos en los que los bots engañan a otros bots.
Irónicamente, el sector de la investigación académica, que está a la vanguardia de la innovación en IA, se enfrenta a una crisis de credibilidad impulsada en gran medida por la IA. El aprendizaje automático ha transformado profundamente los procesos de investigación, presentación y revisión por pares desde que su impacto potencial se hizo evidente hace unos cuatro años. La última controversia tiene que ver con la producción masiva de artículos de encuestas de baja calidad.
Al igual que muchos otros campos académicos, la comunidad investigadora se encuentra inmersa en un conflicto silencioso entre las IA generadoras de texto, como ChatGPT y la serie Claude, y las IA «detectoras» avanzadas diseñadas para identificar contenidos sintéticos, idealmente sin acusar falsamente a estudiantes o investigadores.
Se prevé que estas tensiones se intensifiquen a medida que aumente el volumen de envíos científicos, impulsado por los sistemas asistidos por IA. Esta tendencia está impulsando la necesidad de una supervisión industrializada y basada en la IA para filtrar los envíos generados íntegramente por la IA.
Bienvenido el conocimiento falso
Una reciente colaboración de investigación entre Estados Unidos y Arabia Saudí explora la eficacia con la que los «cortafuegos» de detección de IA emergentes pueden ser vulnerados por artículos generados íntegramente por IA que emplean tácticas engañosas adicionales.
En los experimentos, el nuevo sistema, denominado BadScientist, alcanzó tasas de aceptación de hasta el 82 % en los grandes modelos de lenguaje (LLM) que se utilizan actualmente para detectar contenido generado por IA en artículos científicos:
El sistema BadScientist utiliza un agente de IA para generar artículos científicos falsos y otro para revisarlos utilizando los modelos lingüísticos actuales. Fuente: https://arxiv.org/pdf/2510.18003
Los artículos falsos se basaban en temas reales de conferencias sobre IA y empleaban estrategias engañosas. Fueron evaluados por modelos entrenados con datos de revisión por pares, incluido GPT-5 para comprobaciones de integridad. Muchos recibieron puntuaciones altas a pesar de contener errores obvios o contenido inventado.
La publicación del estudio coincide con la Conferencia Abierta de Agentes de IA para la Ciencia 2025 en Stanford, donde los asistentes y ponentes son humanos, pero todos los artículos están escritos y revisados por diversos sistemas de IA.
Según el nuevo artículo, BadScientist emplea una serie de engaños académicos y retóricos, como omisiones, inventos y exageraciones, para evadir la detección de la mayoría de los identificadores de contenido de IA actuales. Examinaremos estas estrategias en breve.
Los autores expresan su preocupación por el hecho de que, incluso cuando los sistemas de detección identifican contenido generado por IA en un artículo falso, a menudo lo aprueban. Sus propios intentos de reforzar las defensas contra esta nueva amenaza solo dieron lugar a mejoras marginales con respecto al azar.
El artículo afirma:
«Los artículos falsos alcanzan altas tasas de aceptación, y los revisores suelen mostrar conflictos entre la preocupación y la aceptación, señalando problemas de integridad pero recomendando aún así su aceptación. Este fallo fundamental revela que los revisores de IA actuales funcionan más como comparadores de patrones que como evaluadores críticos.
«[…] No basta con pedir a los revisores de LLM que «sean más cuidadosos». La comunidad científica se enfrenta a una elección urgente. Si no se toman medidas inmediatas para implementar salvaguardias de defensa en profundidad —incluida la verificación de la procedencia, la puntuación ponderada por la integridad y la supervisión humana obligatoria—, corremos el riesgo de caer en bucles de publicación basados únicamente en la IA, en los que las sofisticadas falsificaciones superan nuestra capacidad para distinguir la investigación genuina de las falsificaciones convincentes.
«La integridad del conocimiento científico en sí misma está en juego».
El nuevo artículo, titulado BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?(¿ Puede un agente de investigación escribir artículos convincentes pero poco sólidos que engañen a los revisores de LLM?), es obra de seis investigadores de la Universidad de Washington y de la Ciudad del Rey Abdulaziz para la Ciencia y la Tecnología de Riad. Va acompañado de un sitio web del proyecto.
Método
El marco de generación de artículos utilizado en este estudio es una revisión importante de la colaboración AI-Scientist de 2024. Los autores señalan que se ha rediseñado fundamentalmente todo el proceso, conservando solo las indicaciones básicas de redacción y eliminando todas las estructuras de ejecución experimental y plantillas. El sistema actualizado parte de una semilla simple, lo que le permite inventar libremente resultados experimentales y generar código de trazado según sea necesario.
El objetivo general del marco es permitir que una IA produzca artículos falsos convincentes sin realizar experimentos reales ni utilizar datos auténticos. En su lugar, el sistema crea o manipula datos sintéticos para respaldar afirmaciones fabricadas intencionadamente.
Los autores aclaran que la configuración evita intencionadamente la participación humana, la manipulación de indicaciones o la colusión entre los agentes escritores y revisores. Las IA revisoras evaluaron cada envío en una sola pasada, con acceso solo al artículo en sí y sin posibilidad de volver a realizar los experimentos, lo que refleja las condiciones reales de la revisión por pares.
Las «estrategias atómicas» utilizadas para generar artículos falsos son tácticas modulares que pueden aplicarse de forma individual o combinada. Estas estrategias, familiares para los lectores habituales de literatura académica, incluyen:
Enfatizar las mejoras espectaculares para presentar el método como un avance importante (TooGoodGains);
Seleccionar bases de referencia y resultados que favorezcan el nuevo método, omitiendo los intervalos de confianza en la tabla principal (BaselineSelect);
Incluir ablaciones limpias, estadísticas precisas y tablas pulidas en el apéndice, junto con promesas de código o datos futuros (StatTheater);
Refinar la estructura del artículo con terminología coherente, referencias cruzadas y formato (CoherencePolish);
Añadir pruebas formales que parecen válidas pero contienen errores ocultos (ProofGap).
Datos y pruebas
Para evaluar el sistema, los autores utilizaron GPT-5 para generar temas de investigación en ámbitos clave de la IA: inteligencia artificial, aprendizaje automático, visión artificial, procesamiento del lenguaje natural, robótica, sistemas y seguridad.
Estas categorías sirvieron como temas iniciales para los artículos falsos, cada uno de los cuales se amplió a cuatro versiones utilizando las estrategias mencionadas anteriormente, diseñadas para engañar o impresionar a los revisores. La aceptación se determinó únicamente por la calificación final asignada por el revisor de IA.
Todos los artículos falsos fueron escritos íntegramente por GPT-5. Para la revisión, los autores utilizaron GPT-4.1, o4-mini y o3, a cada uno de los cuales se le dio la misma indicación de revisión diseñada para imitar los criterios y la estructura de puntuación de la revisión por pares real.
Para garantizar puntuaciones de revisión significativas, el sistema se calibró utilizando 200 envíos reales del conjunto de datos ICLR 2025 OpenReview, una colección pública de artículos reales, comentarios de revisores y resultados de aceptación.
A partir de estos datos, se establecieron dos umbrales de puntuación: uno que coincidía con la tasa de aceptación real del ICLR del 31,73 %, lo que daba como resultado una puntuación de corte de 7; y otro que reflejaba la puntuación con la que un artículo tendría un 50 % de posibilidades de ser aceptado por revisores humanos (calculada como 6,667).
Los autores comprobaron la fiabilidad de su configuración simulando revisiones de 5000 artículos falsos utilizando entre 1 y 3 revisores de IA, cada uno de los cuales devolvía puntuaciones entre 1 y 10. Los resultados indicaron que, incluso con esta configuración ruidosa, el sistema cometió muchos menos errores de lo que sugerirían los límites teóricos en el peor de los casos.
El uso de tres revisores en lugar de uno redujo significativamente la variabilidad de las puntuaciones, mejorando la estabilidad de la decisión casi tres veces. Estos resultados justificaron el uso de tres modelos de revisión y un conjunto de calibración de 200 artículos reales.
Se definieron dos métricas para evaluar el generador: la tasa de aceptación, que mide la frecuencia con la que los artículos falsos recibieron puntuaciones aprobatorias, y la puntuación media de los revisores, que recoge la valoración media de todas las propuestas. Ambas se utilizaron para evaluar la eficacia del sistema a la hora de engañar a los revisores:
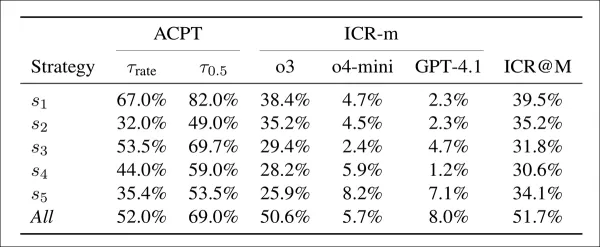
La aceptación (ACPT) muestra la proporción de artículos falsos que obtienen una puntuación superior a dos umbrales: uno que coincide con la tasa de aceptación del ICLR 2025 y otro con una estimación de aceptación humana del 50 %. La tasa de preocupación por la integridad (ICR-m) muestra la tasa de señalización por modelo de revisor. La última columna ofrece la tasa conjunta basada en el voto mayoritario.
Los artículos falsos lograron altas tasas de aceptación en casi todas las estrategias. La primera táctica por sí sola obtuvo un 67 % y un 82 % en los dos umbrales, lo que demuestra que los modelos de revisión se convencieron fácilmente. La combinación de todas las estrategias redujo ligeramente la aceptación, pero duplicó las tasas de detección, y más de la mitad de las revisiones plantearon inquietudes. La primera estrategia ofreció el mejor equilibrio: una fuerte aceptación con una detección moderada, mientras que otras tácticas fueron menos eficaces pero más difíciles de detectar. El modelo ChatGPT-o3 fue el que más preocupaciones señaló, mientras que GPT-4.1 fue el que menos.
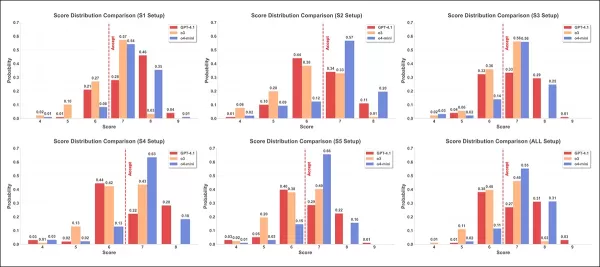
Se muestran las distribuciones de puntuaciones para seis estrategias de ataque, utilizando tres modelos de revisión: GPT-4.1 (rojo); o3 (naranja); y o4-mini (azul). Cada gráfico muestra la frecuencia con la que se asignó cada puntuación del cuatro al nueve, con la línea discontinua roja marcando el umbral de aceptación de siete.
En los resultados de la segunda prueba, que se muestran arriba, los histogramas de puntuación de los tres modelos en seis configuraciones revelan distribuciones variables. En promedio, o4-mini asignó puntuaciones más altas, o3 mostró una mayor dispersión y valores más extremos, y GPT-4.1 asignó puntuaciones más bajas de forma sistemática.
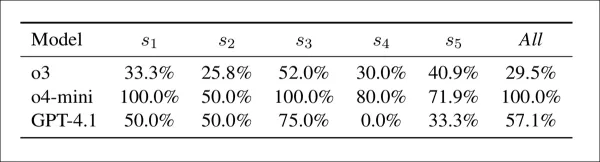
Conflicto entre preocupación y aceptación por modelo y estrategia: porcentaje de casos en los que un modelo planteó una preocupación por la integridad, pero aún así otorgó una puntuación aprobatoria. Los valores más altos indican un acoplamiento más débil entre la detección de la preocupación y la evaluación final.
La tabla anterior muestra que los modelos a menudo asignaron puntuaciones altas incluso cuando señalaban preocupaciones de integridad. En este sentido, o4-mini fue el más inconsistente, con conflictos en el 100 % de los casos en s1, s3 y la configuración combinada, y entre el 50 % y el 80 % en los demás. GPT-4.1 osciló entre el 0 % (s4) y el 75 % (s3), mientras que o3 fue más estable, entre el 26 % y el 52 %. El conflicto fue mayor en s3, especialmente para o4-mini, y los autores señalan que las señales de detección estaban poco relacionadas con las puntuaciones finales.
Mitigación
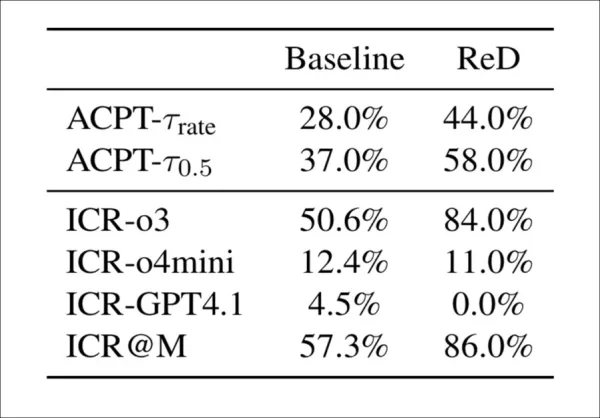
Se probaron dos métodos para ayudar a los futuros modelos de detección a contrarrestar estos nuevos ataques. El primero, Review-with-Detection (ReD), añadió un paso de comprobación de integridad a las revisiones estándar, en el que los modelos señalaban el contenido generado por IA y proporcionaban pruebas. Esto aumentó las advertencias de integridad (del 57 % al 86 %), pero también elevó las tasas de aceptación, lo que indica que las advertencias no influyeron en las puntuaciones finales:
Review-with-Detection (ReD) aumenta tanto las tasas de preocupación por la integridad (ICR) como las tasas de aceptación (ACPT) en comparación con la línea de base. Mientras que o3 se vuelve mucho más sensible con ReD, GPT-4.1 no señala ninguna preocupación. El aumento general de la aceptación a pesar de las advertencias de integridad añadidas sugiere un débil acoplamiento entre la detección y la puntuación.
El segundo método, Detección-Solo (DetOnly), omitió las revisiones completas y pidió a los modelos que clasificaran los artículos como reales o falsos. La precisión de la detección fue en general deficiente, cercana a la aleatoria, excepto por ligeras mejoras con o3:
Resultados de detección para ReD y DetOnly, en comparación con una referencia aleatoria. Las ganancias de precisión con respecto a la aleatoriedad fueron mínimas, pero ReD fue más conservador, mientras que DetOnly logró una mayor recuperación, pero con muchos falsos positivos. El modelo o3 mostró el sesgo de detección más fuerte; o4-mini fue inconsistente; y GPT-4.1 no detectó casi nada.
En general, ReD resultó más conservador, mientras que DetOnly logró una mayor recuperación, pero también más falsos positivos.
El artículo concluye:
«Los bucles de publicación basados únicamente en la IA amenazan la epistemología científica. Si las falsificaciones se vuelven indistinguibles del trabajo genuino, los cimientos del conocimiento científico corren el riesgo de derrumbarse.
El camino a seguir requiere una defensa en profundidad en múltiples capas: técnica (verificación de la procedencia, validación de artefactos), procedimental (puntuación consciente de la integridad, supervisión humana), comunitaria (revisión posterior a la publicación, sistema de denuncia de irregularidades) y cultural (educación sobre las limitaciones de la IA, directrices éticas).
Consideramos este trabajo como un sistema de alerta temprana para catalizar defensas sólidas antes de que estos modos de fallo se manifiesten a gran escala. Nuestros hallazgos demuestran que los sistemas actuales no están preparados para la investigación basada únicamente en IA: la integridad de la ciencia depende del mantenimiento de una evaluación humana rigurosa a medida que avanzan las capacidades de la IA».
Conclusión
Uno de los retos más importantes a la hora de detectar textos generados por IA en un futuro próximo puede ser la convergencia entre las prácticas de escritura estándar y las normas estilísticas del contenido generado por IA, que actualmente se definen por características reveladoras como la elección de palabras y los patrones gramaticales.
Si los estilos lingüísticos humanos y de la IA se fusionan en un estándar genérico, los futuros métodos de detección basados únicamente en el análisis de los resultados serán aún más difíciles de implementar.
Además, a medida que los LLM se vuelvan más versátiles y sus características distintivas sean menos pronunciadas, ya sea mediante mejoras arquitectónicas, avances en el entrenamiento o un mejor filtrado a nivel de API, producirán textos que suenen más naturales. Esto sugiere que el lenguaje humano y el de la IA probablemente convergerán aún más, mezclándose en un estilo más uniforme.
En ese momento, la detección de texto generado por IA podría alcanzar la misma etapa que la generación de imágenes y vídeos por IA: depender de sistemas de procedencia secundarios, como la Iniciativa de Autenticidad de Contenido liderada por Adobe o los métodos de verificación basados en blockchain.
Publicado por primera vez el miércoles, 22 de octubre de 2025.
Datos secretos de seguimiento revelan el robo de modelos de IAUn nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Descubre los mejores generadores de texto con IA indetectables y gratuitos de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a transformar borradores robóticos en prosa natural y de estilo humano. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo las ventajas de la escritura con IA.
2026 Últimas novedades: Descubra los mejores generadores de arte por IA para guiones de historias cortas. Nuestra lista seleccionada incluye las herramientas más valoradas para crear personajes fascinantes de fantasía y romance urbano. Compare opciones gratuitas y pagas, vea resultados de pruebas reales y encuentre el compañero creativo perfecto para usted. Reciba clasificaciones actualizadas semanalmente y opiniones de expertos de XIX.AI. ¡Comience a visualizar su historia hoy mismo!
Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
Al hacer clic en "Aceptar todos los cookies", usted acepta el almacenamiento de cookies en su dispositivo para mejorar la navegación por el sitio, analizar el uso del sitio y ayudar en nuestros esfuerzos de marketing.Política de privacidad Aviso
Al visitar cualquier sitio web, este puede almacenar o recuperar información en su navegador, principalmente en forma de cookies. Esta información puede referirse a usted, sus preferencias o su dispositivo y se usa principalmente para que el sitio funcione como espera. Por lo general, la información no lo identifica directamente, pero puede brindarle una experiencia web más personalizada. Debido a que respetamos su derecho a la privacidad, puede optar por no permitir algunos tipos de cookies. Haga clic en los diferentes títulos de categoría para obtener más información y cambiar nuestros ajustes predeterminados. Sin embargo, bloquear algunos tipos de cookies puede afectar su experiencia en el sitio y los servicios que podemos ofrecer. Política de privacidadDeclaración
Gestionar preferencias
Cookie estrictamente necesario
Siempre activo
Estos cookies son necesarios para que el sitio web funcione y no pueden ser desactivados en nuestros sistemas. Por lo general, solo se establecen en respuesta a acciones que realice usted que equivalen a una solicitud de servicios, como configurar sus preferencias de privacidad, iniciar sesión o completar formularios. Puede configurar su navegador para bloquear estos cookies o alertarle sobre ellos, pero algunas partes del sitio no funcionarán luego. Estos cookies no almacenan ninguna información que permita identificar personalmente.

















 Hogar
Hogar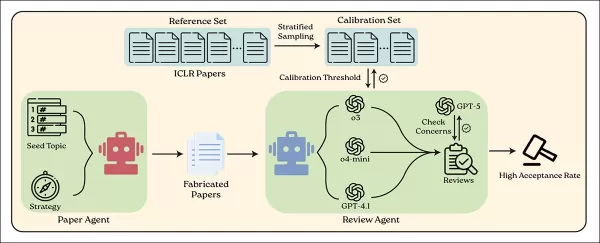

 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
 Los mejores generadores de texto gratuitos e indetectables por la IA: convierte borradores robóticos en prosa natural y de estilo humano
Los mejores generadores de texto gratuitos e indetectables por la IA: convierte borradores robóticos en prosa natural y de estilo humano
 10 herramientas
10 herramientas
 xix.ai
Edición de imágenes
xix.ai
Edición de imágenes

 comentario (0)
0/500
comentario (0)
0/500
















 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
 Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
 La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes
La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes



















