Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et en résistant à toutes les tentatives pratiques de suppression.
La principale différence entre le tatouage numérique et le « copyright-baiting » réside dans le fait que les tatouages numériques, qu'ils soient visibles ou cachés, sont généralement conçus pour apparaître dans l'ensemble d' une collection (comme un ensemble de données d'images) afin de dissuader de manière cohérente toute copie occasionnelle.
En revanche, une entrée fictive est un petit morceau de texte, souvent un mot ou une définition placé dans une grande collection générique, destiné à prouver le vol. L'idée est que lorsque l'œuvre entière est copiée sans autorisation, soit directement, soit comme base d'une œuvre dérivée, la présence d'un fait unique et fabriqué de toutes pièces par les créateurs originaux révèle facilement le vol.
En ce qui concerne le tatouage numérique des modèles linguistiques à grande échelle (LLM) et des modèles linguistiques visuels (VLM), la mesure dans laquelle les résultats contiennent ces marqueurs se divise généralement en deux catégories : s'assurer que tous ou la plupart des résultats comportent un tatouage numérique visible ou caché ; ou intégrer un « jeton secret » qui peut être récupéré pour prouver le vol, sans apparaître dans les résultats habituels du modèle.
Le poids des preuves
Cette dernière approche est explorée dans le cadre d'une nouvelle collaboration entre des chercheurs en Chine, en Italie et à Singapour. Ce travail vise à fournir une méthode de divulgation pour les modèles open source, afin d'empêcher leur commercialisation ou leur utilisation non autorisée au-delà des conditions de la licence d'origine.
Par exemple, la licence d'origine d'un modèle peut permettre à quiconque d'en tirer profit à condition de partager ses modifications selon les mêmes conditions généreuses, mais une entreprise peut essayer de garder ses ajustements (comme les versions optimisées) confidentiels afin de créer un avantage déloyal.
La plupart des recherches dans ce domaine se concentrent sur la détection des abus dans les modèles à code source fermé, les modèles API uniquement ou les modèles où seuls des poids optimisés (quantifiés) sont disponibles. Ceux-ci sont plus difficiles à modifier efficacement à l'aide de l'approche présentée dans le nouvel article en raison de l'accès limité à l'architecture du modèle.
Cette focalisation sur les versions FOSS est peut-être prévisible de la part du secteur de la recherche chinois, car la production chinoise en matière d'IA au cours de l'année écoulée a été marquée par la publication généreuse de modèles à poids complet* qui rivalisent avec leurs équivalents occidentaux plus restrictifs.
La nouvelle approche, appelée EditMark, se distingue en ne nécessitant pas de réglage fin pour ajouter des données « empoisonnées » ou un entraînement à partir de zéro avec les données incluses.
Cela offre plusieurs avantages : premièrement, toute donnée « révélatrice » incluse dans l'ensemble d'entraînement, une fois découverte et divulguée, devient inefficace car les attaquants peuvent la cibler directement. Mais pour attaquer EditMark, un acteur malveillant devrait savoir quelle couche du modèle cibler et quelle méthode utiliser, ce qui est peu probable.
Deuxièmement, la méthode est rapide et peu coûteuse, ne prenant que quelques secondes (au lieu de plusieurs jours ou semaines) pour être appliquée à un modèle formé, ce qui évite le coût élevé du réglage fin (qui augmente avec la taille du modèle et des données).
Enfin, cette approche perturbe beaucoup moins le fonctionnement normal du modèle que le réglage fin ou les méthodes d'édition antérieures.
Lors des tests, EditMark, qui intègre des requêtes mathématiques avec plusieurs réponses possibles dans les poids du modèle, a atteint un taux d'extraction de 100 %.
Les auteurs déclarent :
« Des expériences approfondies démontrent les performances exceptionnelles d'EditMark dans le domaine du tatouage numérique des LLM. Il atteint une efficacité remarquable en intégrant un tatouage numérique 32 bits en moins de 20 secondes avec un taux de réussite d'extraction (ESR) de 100 %.
Il est à noter que l'intégration du filigrane prend moins d'un trentième du temps nécessaire au réglage fin (qui est en moyenne de 6 875 secondes), ce qui souligne la capacité d'EditMark à mettre en œuvre des filigranes de grande capacité avec une rapidité et une fiabilité sans précédent.
De plus, des expériences approfondies confirment la robustesse, la discrétion et la fidélité d'EditMark.
Le nouvel article, intitulé « EditMark : Watermarking Large Language Models based on Model Editing » (EditMark : tatouage numérique de grands modèles linguistiques basé sur l'édition de modèles), a été rédigé par huit auteurs de l'Université des sciences et technologies de Chine, de l'Université de Sienne et du CFAR/IHPC/A*STAR à Singapour.
Méthode
L'approche EditMark comprend quatre composants : un générateur, un encodeur, un éditeur et un décodeur:
Le pipeline EditMark intègre un filigrane en modifiant un modèle afin de répondre à des questions mathématiques spécifiques d'une manière qui encode des informations d'identification cachées. Source : https://arxiv.org/pdf/2510.16367
Le générateur utilise une graine pseudo-aléatoire pour créer des questions mathématiques à réponses multiples ; l'encodeur sélectionne les réponses en fonction du filigrane, qui sont ensuite intégrées dans le modèle grâce à un processus d'édition spécialisé. Une fois que le modèle édité est publié ou utilisé à mauvais escient, le filigrane peut être extrait en posant les mêmes questions et en décodant les modèles de réponse.
L'éditeur modifie ensuite les pondérations du modèle afin que, lorsqu'on lui pose ces questions, le modèle produise systématiquement les réponses cibles, intégrant ainsi le filigrane directement dans son comportement. Le décodeur récupère le filigrane en soumettant les mêmes questions à un modèle suspect et en traduisant ses réponses en signature cachée.
Modèle de menace
Le modèle de menace présenté dans l'article suppose que le tatouage numérique est effectué dans un environnement de type « boîte blanche ». Bien que cela soit souvent un sujet de préoccupation dans la recherche en sécurité, cela est normal ici, car la méthode vise à protéger les propriétaires qui ont un accès complet à leur propre travail.
On suppose également que l'attaquant dispose d'un accès en boîte blanche après avoir obtenu le modèle, ce qui signifie qu'il peut le modifier (par exemple, par élagage ou ajustement). Ce scénario est typique des versions FOSS. Cependant, l'attaquant ne connaît pas le processus ou le schéma d'extraction du filigrane et ne peut le déduire que par l'expérimentation ou des fuites.
Le générateur crée des questions mathématiques logiquement et factuellement valides avec plusieurs réponses correctes, en utilisant GPT-4o pour diversifier les modèles (comme indiqué ci-dessous) et une graine pseudo-aléatoire pour garantir que chaque question est unique. Cela permet d'intégrer de manière déterministe un filigrane connu grâce à des permutations de réponses, tout en minimisant le chevauchement des questions afin d'éviter les enchevêtrements d'éditions :
Modèles de questions générés par GPT-4o pour l'intégration de filigranes, chacun structuré de manière à produire plusieurs réponses entières valides à partir d'une inégalité ensemencée.
L'Encodeur convertit chaque segment de filigrane binaire en une permutation unique d'entiers à partir de l'ensemble de solutions d'une question mathématique donnée. À l'aide de la théorie des permutations lexicographiques, l'Encodeur mappe la valeur décimale de chaque morceau de filigrane à une sélection ordonnée spécifique de réponses, garantissant ainsi que le filigrane est intégré de manière déterministe dans le comportement du modèle.
En ce qui concerne l'éditeur, la méthode d'édition du modèle AlphaEdit originale utilisée pour le tatouage manque à la fois de précision et de résilience, et ne parvient souvent pas à produire les réponses requises. Les modifications qu'il apporte sont facilement compromises par l'élagage ou le bruit.
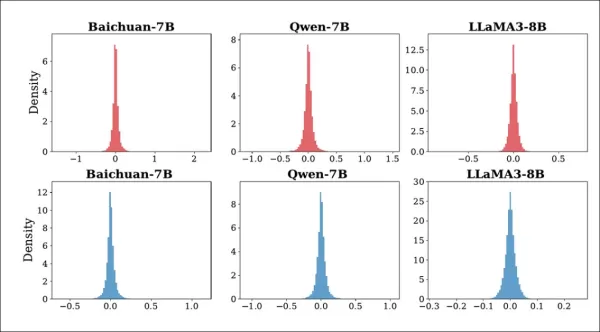
Pour remédier à cela, les auteurs ont développé une stratégie d'édition en plusieurs étapes qui ajuste progressivement les poids du modèle à un seul niveau MLP jusqu'à ce que les réponses correspondent aux réponses souhaitées. Afin de renforcer les modifications contre les altérations, un bruit gaussien est injecté pendant l'entraînement pour simuler des attaques :
Distribution des changements dans K1 pour Baichuan-7B, Qwen-7B et LLaMA3-8B avant et après les attaques. La ligne supérieure montre l'effet de l'injection de bruit aléatoire ; la ligne inférieure montre l'effet de l'élagage du modèle. Tous les changements restent proches de zéro, ce qui suggère que les attaques ne perturbent pas de manière significative le comportement interne du modèle.
Un système de notation arrête le processus une fois que les modifications sont suffisamment précises, tandis que la régularisation garantit la stabilité des mises à jour sur plusieurs cycles.
Le décodeur pose au modèle les mêmes questions spéciales que celles utilisées lors du tatouage numérique, puis lit ses réponses pour déduire l'ID caché. Comme le modèle de réponse suit une règle secrète, cet ID peut être récupéré sans examiner les composants internes du modèle.
Données et tests
Pour évaluer EditMark, cinq LLM ont été testés : GPT2-XL, GPT-J-6B, LLaMA-3-8B, Baichuan-7B et Qwen-7B. L'AlphaEdit susmentionné a été utilisé pour intégrer les filigranes, avec comme indicateurs le taux de réussite d'extraction (ESR) et le temps d'intégration (ET).
Comme références, les auteurs ont sélectionné Model Watermark (backdoor) ; KIMark ; et BadEdit, un cadre initialement conçu pour l'injection de backdoor, adapté à ce projet.
Les auteurs ont modifié la 15e couche de LLaMA-3-8B, la 17e couche de GPT2-XL et GPT-J-6B, et la 14e couche de Qwen-7B et Baichuan-7B.
Les expériences ont été menées sur quatre GPU NVIDIA RTX 4090 (24 Go de VRAM chacun), avec des filigranes de 32 bits, 64 bits et 128 bits intégrés. Les modèles de questions utilisés sont détaillés ci-dessous :
Modèles utilisés pour générer des questions à réponses multiples (MA) pour le tatouage numérique. Chaque question est basée sur un type différent d'inégalité mathématique, avec des valeurs aléatoires insérées pour les variables. Le modèle doit renvoyer une liste de solutions entières, l'ordre des réponses étant utilisé pour encoder ou décoder les bits du tatouage numérique. Les quatre modèles couvrent les formes quadratiques, logarithmiques, rationnelles et basées sur des intervalles, et tous ont été générés à l'aide de GPT-4o.
Afin de réduire les effets aléatoires, des graines de 1 à 20 ont été appliquées pendant les tests sur différentes capacités de filigrane.
Au départ, les chercheurs ont testé à la fois l'ESR et le coût en temps pour l'intégration de filigranes dans les LLM :
Comparaison d'EditMark avec trois méthodes de tatouage antérieures sur cinq grands modèles linguistiques. Le rapport indique le taux de réussite de l'extraction (ESR) et le temps d'intégration (ET) en secondes. EditMark atteint systématiquement un taux de réussite de 100 % tout en réduisant le temps d'intégration de plusieurs ordres de grandeur, surpassant toutes les références en termes de précision et d'efficacité sur des modèles de taille et d'architecture variables.
À propos de ces résultats, les auteurs déclarent :
« [EditMark] atteint un ESR de 100 % et nécessite moins de 20 secondes pour intégrer un filigrane 32 bits pour tous les LLM évalués. En particulier, le temps d'intégration moyen pour Baichuan-7B et Qwen-7B est inférieur à 10 secondes, ce qui démontre la grande efficacité d'EditMark. »
Pour un filigrane de 128 bits, la valeur la plus élevée possible dans un tel système, EditMark a conservé son « indélébilité » :
Taux de réussite d'extraction et temps d'intégration pour EditMark pour des longueurs de filigrane de 32, 64 et 128 bits sur cinq modèles linguistiques. Des taux de réussite parfaits sont maintenus dans tous les cas, tandis que le temps d'intégration augmente avec la taille du filigrane, mais reste inférieur à une minute, même à 128 bits.
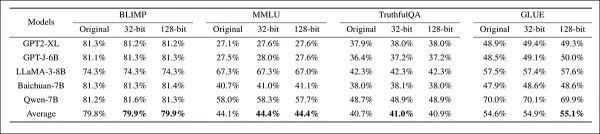
Ensuite, la capacité du système à conserver la fidélité du filigrane a été testée à l'aide de plusieurs benchmarks :
Évaluation de la fidélité du filigrane sur quatre benchmarks dans cinq modèles, en comparant des modèles non modifiés avec des modèles filigranés à des capacités de 32 bits et 128 bits. Les performances sont restées stables dans toutes les configurations, avec seulement des fluctuations mineures dans les scores moyens, ce qui indique un impact limité de l'insertion du filigrane sur la précision du benchmark.
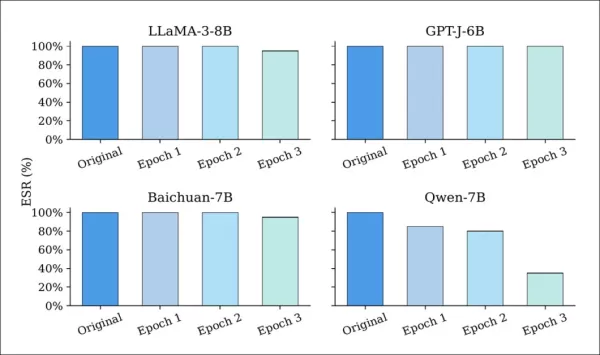
La résilience d'EditMark a été testée par rapport à six stratégies d'attaque courantes. Les modèles ont d'abord été intégrés avec des filigranes de 128 bits à l'aide de cinq graines différentes. Le réglage fin, comme indiqué ci-dessous, n'a entraîné qu'une légère dégradation des taux de réussite d'extraction (ESR) pour la plupart des modèles :
Taux de réussite d'extraction (ESR) des LLM marqués avant et après le réglage fin pour une à trois époques. Alors que la plupart des modèles conservent un ESR élevé tout au long du processus, Qwen-7B affiche une baisse marquée, ce qui suggère une plus grande vulnérabilité aux mises à jour des paramètres.
Même après plusieurs époques, la plupart des modèles ont conservé des ESR supérieurs à 90 %, ce qui montre qu'EditMark résiste à la dérive des paramètres issue de l'entraînement basé sur LoRA.
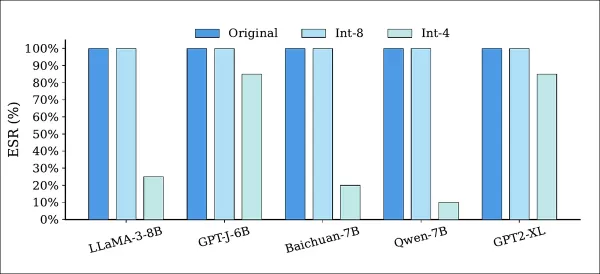
Les attaques par quantification ont réduit la précision du modèle, mais ont laissé la plupart des filigranes intacts :
Taux de réussite d'extraction (ESR) des modèles marqués avant et après quantification à l'aide des précisions Int-8 et Int-4. L'ESR est resté inchangé sous quantification Int-8 pour tous les modèles, tandis que la quantification Int-4 a entraîné une dégradation partielle, indiquant qu'une précision inférieure peut affaiblir le filigrane, mais ne peut pas le supprimer complètement.
Comme indiqué ci-dessus, la quantification Int-8 a préservé un ESR de 100 % pour tous les modèles, tandis que la quantification Int-4 a eu un impact modéré sur l'ESR, mais a entraîné des pertes de performances inacceptables.
L'article note que ce scénario offre un potentiel limité aux attaquants, car il aboutit à un modèle piraté mais dégradé.
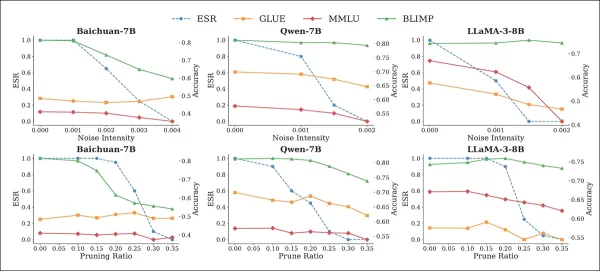
Les tests de bruit et d'élagage ont évalué quatre cadres de référence : MMLU, BLIMP, TruthfulQA et GLUE. Ces attaques ont entraîné une diminution de l'ESR à mesure que les perturbations s'intensifiaient :
Effet des attaques par bruit (ligne supérieure) et par élagage (ligne inférieure) sur l'ESR, et performances de référence des modèles filigranés. À mesure que l'ESR diminue avec l'augmentation des perturbations, la précision de référence se dégrade également, en particulier à des intensités de bruit et des taux d'élagage plus élevés, ce qui met en évidence la tension (habituelle) entre la suppression des filigranes et l'utilité du modèle.
Cependant, cela a également entraîné une forte baisse des performances des tâches, Baichuan-7B enregistrant une baisse de 27 à 31 % sur BLIMP lorsque du bruit ou de l'élagage était appliqué.
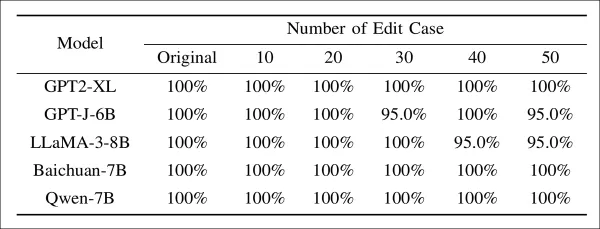
La modification des modèles et les attaques adaptatives ont également été évaluées :
Taux de réussite de l'extraction des modèles filigranés soumis à divers degrés de modification. Même avec jusqu'à cinquante modifications appliquées à des couches de filigrane connues, l'ESR reste supérieur à 95 % pour tous les modèles, ce qui indique que les modifications directes des paramètres ont un effet limité sur la suppression du filigrane.
Ici, EditMark a conservé un ESR supérieur à 95 %, même lorsque les couches d'intégration exactes ont été ciblées.
Conclusion
Les DRM, les filigranes secrets et autres mesures de sécurité qui ont connu un succès limité avant l'ère de l'IA sont difficiles à appliquer aux systèmes d'apprentissage automatique. La nature intentionnellement simplifiée des architectures hôtes actuelles, combinée à un manque d'outils adaptés, rend les filigranes injectés relativement fragiles.
Il est impressionnant de voir un système destiné à la distribution de modèles FOSS qui résiste à tous les scénarios d'attaque, sauf les plus improbables, compte tenu des connaissances préalables d'un attaquant. Cependant, la légère baisse de performance due aux modifications post-formation, bien que minime dans ces expériences, peut faire hésiter les adoptants potentiels, d'autant plus que le retour à un modèle de contrôle centré sur l'API permet d'éviter presque entièrement de telles attaques.
* Ce site a fait valoir que les versions « open weight » provenant de Chine ne peuvent pas être considérées comme des logiciels libres, car les données sont souvent dissimulées, ce qui empêche la reproduction exacte du pipeline de formation. Ce sujet invite à un examen plus approfondi de la politique de publication des modèles d'IA en Orient et en Occident, ce qui dépasse le cadre de cet article.
Publié pour la première fois le lundi 27 octobre 2025.
Des données de suivi secrètes révèlent le vol de modèles d'IAUne nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
Wow, dieses Thema mit unsichtbaren Wasserzeichen für KI-Modelle klingt wie etwas aus einem Spionagefilm! 🤯 Der Unterschied zu ‚Copyright-Baiting‘ ist echt wichtig – es geht ja um langfristigen Schutz, nicht nur ums Fangen. Aber was, wenn dieses Werkzeug selbst missbraucht wird? Irgendwie bemerkenswert, was technisch möglich ist, und ein bisschen gruselig zugleich.
Increíble técnica, pero ¿qué tan seguro es que no afecte el rendimiento del modelo en tareas reales? 🤔 Me preocupa que estas medidas puedan usarse también para restringir el acceso a IA de código abierto. ¿Y si una empresa alega falsamente protección de marca de agua? ¡El debate ético apenas comienza!
En cliquant sur "Accepter tous les cookies", vous consentez au stockage de cookies sur votre appareil afin d’améliorer la navigation sur le site, d’analyser l’utilisation du site et de soutenir nos efforts marketing.Politique de confidentialité Avis
Lorsque vous visitez un site web, il peut stocker ou récupérer des informations sur votre navigateur, principalement sous forme de cookies. Ces informations peuvent concerner vous, vos préférences ou votre appareil et sont principalement utilisées pour faire fonctionner le site comme vous vous y attendez. Ces informations n’identifient généralement pas directement vous-même, mais elles peuvent vous offrir une expérience web plus personnalisée. Parce que nous respectons votre droit à la vie privée, vous pouvez choisir de ne pas autoriser certains types de cookies. Cliquez sur les différents titres de catégorie pour en savoir plus et modifier nos paramètres par défaut. Cependant, bloquer certains types de cookies peut affecter votre expérience sur le site et les services que nous sommes en mesure de proposer. Politique de confidentialitéDéclaration
Gérer les préférences
Cookie strictement nécessaire
Toujours actif
Ces cookies sont nécessaires au fonctionnement du site web et ne peuvent pas être désactivés dans nos systèmes. Ils ne sont généralement définis qu’en réponse à des actions que vous effectuez qui équivalent à une demande de services, telles que la configuration de vos préférences de confidentialité, la connexion ou le remplissage de formulaires. Vous pouvez configurer votre navigateur pour bloquer ces cookies ou vous alerter à leur sujet, mais certaines parties du site ne fonctionneront alors plus. Ces cookies ne stockent aucune information permettant d’identifier personnellement.

















 Maison
Maison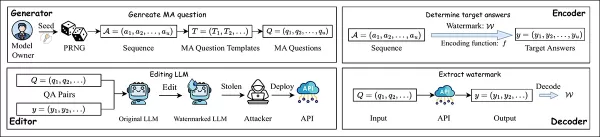




 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
 10 outils
10 outils
 xix.ai
Productivité
xix.ai
Productivité

 commentaires (3)
commentaires (3)





















 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
 Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud




















