Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam métodos de detecção que antes eram eficazes, destacando o risco de os ecossistemas de pesquisa entrarem em um ciclo vicioso de bots enganando outros bots.
Ironicamente, o setor de pesquisa acadêmica — que está na vanguarda da inovação em IA — está enfrentando uma crise de credibilidade impulsionada em grande parte pela IA. O aprendizado de máquina remodelou profundamente os processos de pesquisa, submissão e revisão por pares desde que seu impacto potencial se tornou evidente há cerca de quatro anos. A controvérsia mais recente envolve a produção em massa de artigos de pesquisa de baixa qualidade.
Como muitos outros campos acadêmicos, a comunidade de pesquisa está envolvida em um conflito silencioso entre IAs geradoras de texto — como ChatGPT e a série Claude — e IAs “detectoras” avançadas, projetadas para identificar conteúdo sintético, idealmente sem acusar falsamente estudantes ou pesquisadores.
Espera-se que essas tensões se intensifiquem à medida que o volume de submissões científicas aumenta, impulsionado por sistemas assistidos por IA. Essa tendência está impulsionando a necessidade de uma supervisão industrializada e alimentada por IA para filtrar as submissões que são inteiramente geradas por IA.
Conhecimento falso bem-vindo
Uma recente colaboração de pesquisa entre os Estados Unidos e a Arábia Saudita explora a eficácia com que os “firewalls” de detecção de IA emergentes podem ser violados por artigos totalmente gerados por IA que empregam táticas enganosas adicionais.
Em experimentos, o novo sistema, chamado BadScientist, alcançou taxas de aceitação de até 82% em grandes modelos de linguagem (LLMs) atualmente usados para detectar conteúdo gerado por IA em artigos científicos:
O sistema BadScientist usa um agente de IA para gerar artigos científicos falsos e outro para revisá-los usando modelos de linguagem atuais. Fonte: https://arxiv.org/pdf/2510.18003
Os artigos falsos foram baseados em temas reais de conferências de IA e empregaram estratégias enganosas. Eles foram avaliados por modelos treinados em dados de revisão por pares, incluindo GPT-5 para verificações de integridade. Muitos receberam pontuações altas, apesar de conterem erros óbvios ou conteúdo fabricado.
O lançamento do estudo coincide com a Conferência Aberta de Agentes de IA para a Ciência 2025 em Stanford, onde os participantes e palestrantes são humanos, mas todos os artigos são escritos e revisados por vários sistemas de IA.
De acordo com o novo artigo, o BadScientist emprega uma série de enganos acadêmicos e retóricos — como omissões, invenções e exageros — para evitar a detecção pela maioria dos identificadores de conteúdo de IA atuais. Examinaremos essas estratégias em breve.
Os autores expressam preocupação com o fato de que, mesmo quando os sistemas de detecção identificam conteúdo gerado por IA em um artigo falso, eles muitas vezes ainda o aprovam. Suas próprias tentativas de fortalecer as defesas contra essa nova ameaça renderam apenas melhorias marginais em relação ao acaso.
O artigo afirma:
“Artigos fabricados alcançam altas taxas de aceitação, com revisores frequentemente exibindo conflitos entre preocupação e aceitação — sinalizando problemas de integridade, mas ainda assim recomendando a aceitação. Essa falha fundamental revela que os revisores de IA atuais operam mais como comparadores de padrões do que como avaliadores críticos.
“[...] Simplesmente pedir aos revisores de LLM que ‘sejam mais cuidadosos’ é insuficiente. A comunidade científica enfrenta uma escolha urgente. Sem uma ação imediata para implementar salvaguardas de defesa em profundidade — incluindo verificação de proveniência, pontuação ponderada por integridade e supervisão humana obrigatória — corremos o risco de entrar em um ciclo de publicações exclusivamente baseadas em IA, em que fabricações sofisticadas sobrepujam nossa capacidade de distinguir pesquisas genuínas de falsificações convincentes.
“A integridade do próprio conhecimento científico está em jogo.”
O novo artigo, intitulado BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?(Cientista ruim: um agente de pesquisa pode escrever artigos convincentes, mas sem fundamento, que enganam os revisores de LLM?), é de autoria de seis pesquisadores da Universidade de Washington e da Cidade do Rei Abdulaziz para Ciência e Tecnologia, em Riade. Ele é acompanhado por um site do projeto.
Método
A estrutura de geração de artigos usada neste estudo é uma grande reformulação da colaboração AI-Scientist de 2024. Os autores observam que todo o pipeline foi fundamentalmente redesenhado, mantendo apenas prompts básicos de escrita e removendo todas as execuções experimentais e estruturas de modelos. O sistema atualizado começa a partir de uma semente simples, permitindo inventar livremente resultados experimentais e gerar código de plotagem conforme necessário.
O objetivo geral da estrutura é permitir que uma IA produza artigos falsos convincentes sem realizar experimentos reais ou usar dados autênticos. Em vez disso, o sistema cria ou manipula dados sintéticos para apoiar alegações fabricadas intencionalmente.
Os autores esclarecem que a configuração evita intencionalmente o envolvimento humano, a manipulação de prompts ou a conivência entre os agentes redatores e revisores. As IAs revisoras avaliaram cada submissão em uma única passagem, com acesso apenas ao artigo em si e sem capacidade de refazer experimentos — refletindo as condições reais de revisão por pares.
As “estratégias atômicas” usadas para gerar artigos falsos são táticas modulares que podem ser aplicadas individualmente ou em combinação. Essas estratégias, familiares aos leitores assíduos de literatura acadêmica, incluem:
Enfatizar melhorias dramáticas para retratar o método como um grande avanço (TooGoodGains);
Selecionar linhas de base e resultados que favoreçam o novo método, omitindo os intervalos de confiança na tabela principal (BaselineSelect);
Incluir ablações limpas, estatísticas precisas e tabelas polidas no apêndice, juntamente com promessas de código ou dados futuros (StatTheater);
Refinar a estrutura do artigo com terminologia consistente, referências cruzadas e formatação (CoherencePolish);
Adicionar provas formais que parecem válidas, mas contêm erros ocultos (ProofGap).
Dados e testes
Para avaliar o sistema, os autores usaram o GPT-5 para gerar tópicos de pesquisa em domínios-chave da IA: Inteligência Artificial, Aprendizado de Máquina, Visão Computacional, Processamento de Linguagem Natural, Robótica, Sistemas e Segurança.
Essas categorias serviram como tópicos iniciais para artigos falsos, com cada um expandido em quatro versões usando as estratégias listadas acima, projetadas para enganar ou impressionar os revisores. A aceitação foi determinada exclusivamente pela classificação final atribuída pelo revisor de IA.
Todos os artigos falsos foram inteiramente escritos pelo GPT-5. Para revisão, os autores utilizaram o GPT-4.1, o4-mini e o3, cada um recebendo o mesmo prompt de revisão projetado para imitar os critérios e a estrutura reais de pontuação da revisão por pares.
Para garantir pontuações de revisão significativas, o sistema foi calibrado usando 200 envios reais do conjunto de dados ICLR 2025 OpenReview — uma coleção pública de artigos reais, comentários de revisores e resultados de aceitação.
A partir desses dados, foram estabelecidos dois limites de pontuação: um correspondente à taxa de aceitação real do ICLR de 31,73%, resultando em uma pontuação de corte de 7; e outro refletindo a pontuação na qual um artigo teria 50% de chance de aceitação por revisores humanos (calculada como 6,667).
Os autores testaram a confiabilidade de sua configuração simulando revisões para 5.000 artigos falsos usando de 1 a 3 revisores de IA, cada um retornando pontuações entre 1 e 10. Os resultados indicaram que, mesmo com essa configuração ruidosa, o sistema cometeu muito menos erros do que os limites teóricos do pior caso sugeririam.
O uso de três revisores em vez de um reduziu significativamente a variabilidade da pontuação, melhorando a estabilidade da decisão em quase três vezes. Esses resultados justificaram o uso de três modelos de revisão e um conjunto de calibração de 200 artigos reais.
Duas métricas foram definidas para avaliar o gerador: taxa de aceitação, medindo a frequência com que artigos falsos receberam notas de aprovação; e nota média do revisor, capturando a avaliação média entre os envios. Ambas foram usadas para avaliar a eficácia do sistema em enganar os revisores:
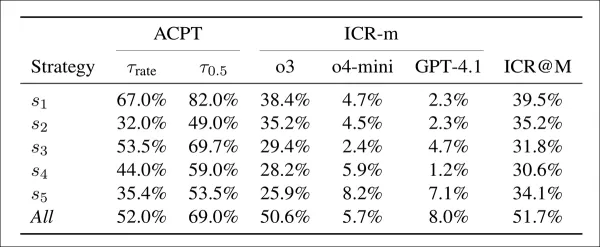
A aceitação (ACPT) mostra a proporção de artigos falsos com pontuação acima de dois limites: um correspondente à taxa de aceitação do ICLR 2025 e outro a uma estimativa de aceitação humana de 50%. A taxa de preocupação com a integridade (ICR-m) mostra a taxa de sinalização por modelo de revisor. A coluna final fornece a taxa do conjunto com base na votação da maioria.
Os artigos falsos alcançaram altas taxas de aceitação em quase todas as estratégias. A primeira tática sozinha rendeu 67% e 82% nos dois limites, mostrando que os modelos de revisão foram facilmente convencidos. A combinação de todas as estratégias reduziu ligeiramente a aceitação, mas dobrou as taxas de detecção, com mais da metade das revisões levantando preocupações. A primeira estratégia ofereceu o melhor equilíbrio: forte aceitação com detecção moderada, enquanto outras táticas foram menos eficazes, mas mais difíceis de detectar. O modelo ChatGPT-o3 sinalizou o maior número de preocupações, enquanto o GPT-4.1 sinalizou o menor número.
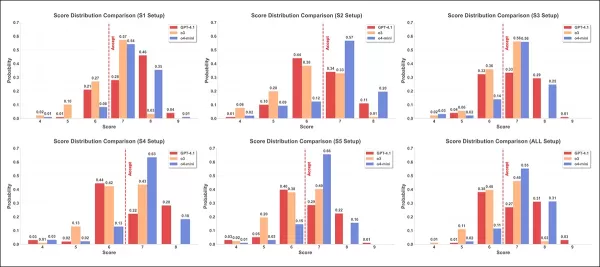
As distribuições de pontuação são mostradas para seis estratégias de ataque, usando três modelos de revisão: GPT-4.1 (vermelho); o3 (laranja); e o4-mini (azul). Cada gráfico mostra a frequência com que cada pontuação de quatro a nove foi atribuída, com a linha tracejada vermelha marcando o limite de aceitação de sete.
Nos resultados do segundo teste, mostrados acima, os histogramas de pontuação para três modelos em seis configurações revelam distribuições variadas. Em média, o o4-mini atribuiu pontuações mais altas, o o3 mostrou maior dispersão e valores mais extremos, e o GPT-4.1 atribuiu consistentemente pontuações mais baixas.
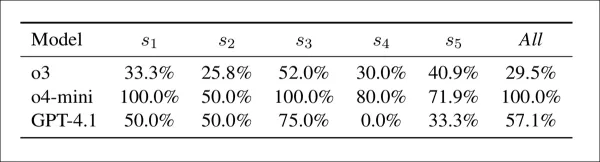
Conflito entre preocupação e aceitação por modelo e estratégia: a porcentagem de casos em que um modelo levantou uma preocupação de integridade, mas ainda assim atribuiu uma pontuação de aprovação. Valores mais altos indicam um acoplamento mais fraco entre a detecção da preocupação e a avaliação final.
A tabela acima mostra que os modelos frequentemente atribuíram pontuações altas mesmo quando sinalizaram preocupações com a integridade. Nesse aspecto, o o4-mini foi o mais inconsistente, com conflitos em 100% dos casos sob s1, s3 e a configuração combinada, e 50-80% nos outros. O GPT-4.1 variou de 0% (s4) a 75% (s3), enquanto o o3 foi mais estável, entre 26% e 52%. O conflito foi maior sob s3, particularmente para o o4-mini, e os autores observam que os sinais de detecção estavam mal vinculados às notas finais.
Mitigação
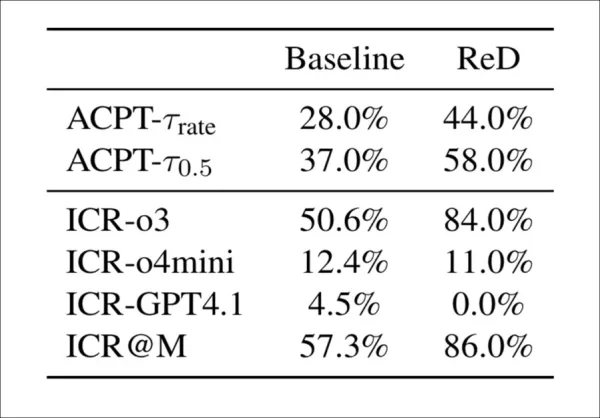
Dois métodos foram testados para ajudar os futuros modelos de detecção a combater esses novos ataques. O primeiro, Revisão com Detecção (ReD), adicionou uma etapa de verificação de integridade às revisões padrão, em que os modelos sinalizavam o conteúdo gerado por IA e forneciam evidências. Isso aumentou os avisos de integridade (de 57% para 86%), mas também elevou as taxas de aceitação, indicando que os avisos não influenciaram as pontuações finais:
A Revisão com Detecção (ReD) aumenta tanto as taxas de preocupação com a integridade (ICR) quanto as taxas de aceitação (ACPT) em comparação com a linha de base. Enquanto o o3 se torna muito mais sensível sob o ReD, o GPT-4.1 não sinaliza nenhuma preocupação. O aumento geral na aceitação, apesar dos avisos de integridade adicionados, sugere um fraco acoplamento entre detecção e pontuação.
O segundo método, Detecção-Somente (DetOnly), pulou as revisões completas e pediu aos modelos que classificassem os artigos como reais ou falsificados. A precisão da detecção foi geralmente ruim, próxima do aleatório, exceto por pequenas melhorias com o o3:
Resultados de detecção para ReD e DetOnly, em comparação com uma linha de base aleatória. Os ganhos de precisão em relação ao aleatório foram mínimos, mas o ReD foi mais conservador, enquanto o DetOnly alcançou maior recall – mas com muitos falsos positivos. O modelo o3 mostrou o maior viés de detecção; o o4-mini foi inconsistente; e o GPT-4.1 não detectou quase nada.
No geral, o ReD provou ser mais conservador, enquanto o DetOnly alcançou maior recall, mas também mais falsos positivos.
O artigo conclui:
“Os ciclos de publicação exclusivamente baseados em IA ameaçam a epistemologia científica. Se as invenções se tornarem indistinguíveis do trabalho genuíno, a base do conhecimento científico corre o risco de entrar em colapso.
“O caminho a seguir requer uma defesa em profundidade em várias camadas: técnica (verificação de proveniência, validação de artefatos), procedural (pontuação consciente da integridade, supervisão humana), comunitária (revisão pós-publicação, sistema de denúncias) e cultural (educação sobre as limitações da IA, diretrizes éticas).
“Consideramos este trabalho como um sistema de alerta precoce para catalisar defesas robustas antes que esses modos de falha se manifestem em grande escala. Nossas descobertas demonstram que os sistemas atuais não estão prontos para pesquisas baseadas exclusivamente em IA — a integridade da ciência depende da manutenção de uma avaliação humana rigorosa à medida que as capacidades da IA avançam.”
Conclusão
Um dos desafios mais significativos na detecção de textos gerados por IA no futuro próximo pode ser a convergência entre as práticas padrão de redação e as normas estilísticas do conteúdo gerado por IA, que atualmente são definidas por características reveladoras, como escolha de palavras e padrões gramaticais.
Se os estilos de linguagem humanos e de IA se fundirem em um padrão genérico, os métodos de detecção futuros baseados exclusivamente na análise de saída se tornarão ainda mais difíceis de implementar.
Além disso, à medida que os LLMs se tornam mais versáteis e suas características distintivas menos pronunciadas — seja por meio de melhorias arquitetônicas, avanços no treinamento ou melhor filtragem no nível da API —, eles produzirão textos com som mais natural. Isso sugere que a linguagem humana e a linguagem da IA provavelmente convergirão ainda mais, mesclando-se em um estilo mais uniforme.
Nesse ponto, a detecção de texto de IA pode atingir o mesmo estágio que a geração de imagens e vídeos de IA: dependente de sistemas de proveniência secundários, como a Content Authenticity Initiative liderada pela Adobe ou métodos de verificação baseados em blockchain.
Publicado pela primeira vez na quarta-feira, 22 de outubro de 2025
Dados secretos de rastreamento expõem roubo de modelos de IAUm novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Descubra os melhores geradores de texto por IA gratuitos e indetectáveis de 2026 no XIX.AI. Nossa lista cuidadosamente selecionada e com as melhores avaliações ajuda você a transformar rascunhos robóticos em textos naturais e com estilo humano. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha hoje mesmo sua vantagem na redação com IA.
2026 Mais recente: Descubra os melhores geradores de arte AI para roteiros de histórias curtas. Nossa lista selecionada apresenta as ferramentas mais avaliadas para criar personagens fascinantes em gêneros como fantasia e romance urbano. Compare opções gratuitas e pagas, veja resultados reais de testes e encontre o parceiro criativo perfeito para você. Receba classificações atualizadas semanalmente e insights de especialistas da XIX.AI. Comece a visualizar sua história hoje mesmo!
Descubra os melhores ferramentas de scriptagem AI para rádio e podcasts em 2026 na XIX.AI. Nossa lista selecionada e avaliada pelos usuários apresenta soluções poderosas que podem transformar a forma como você cria anúncios audio envolventes. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Desbloqueie seu potencial criativo hoje mesmo!
Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
Ao clicar em "Aceitar todos os cookies", você concorda com o armazenamento de cookies em seu dispositivo para melhorar a navegação no site, analisar o uso do site e auxiliar em nossos esforços de marketing.Política de Privacidade Aviso
Ao visitar qualquer site, ele pode armazenar ou recuperar informações em seu navegador, principalmente na forma de cookies. Essas informações podem ser sobre você, suas preferências ou seu dispositivo e são usadas principalmente para fazer com que o site funcione conforme esperado. As informações geralmente não identificam você diretamente, mas podem proporcionar uma experiência web mais personalizada. Como respeitamos seu direito à privacidade, você pode optar por não permitir alguns tipos de cookies. Clique nos diferentes títulos de categoria para saber mais e alterar nossas configurações padrão. No entanto, bloquear alguns tipos de cookies pode afetar sua experiência no site e os serviços que podemos oferecer. Política de PrivacidadeDeclaração
Gerenciar preferências
Cookie estritamente necessário
Sempre ativado
Esses cookies são necessários para o funcionamento do site e não podem ser desativados em nossos sistemas. Eles geralmente são definidos apenas em resposta a ações que você realiza, que equivalem a uma solicitação de serviços, como configurar suas preferências de privacidade, fazer login ou preencher formulários. Você pode configurar seu navegador para bloquear esses cookies ou alertá-lo sobre eles, mas algumas partes do site não funcionarão depois. Esses cookies não armazenam nenhuma informação que permita identificar pessoalmente.

















 Lar
Lar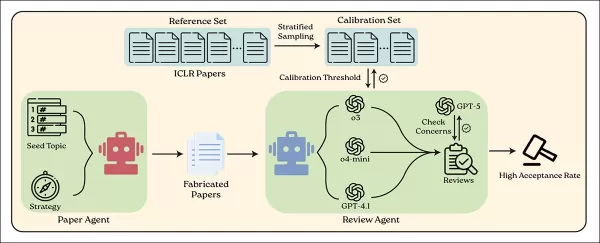

 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
 Os melhores geradores de texto gratuitos e indetectáveis por IA: transforme rascunhos robóticos em textos naturais e com estilo humano
Os melhores geradores de texto gratuitos e indetectáveis por IA: transforme rascunhos robóticos em textos naturais e com estilo humano
 10 ferramentas
10 ferramentas
 xix.ai
Edição de imagem
xix.ai
Edição de imagem

 Comentários (0)
Comentários (0)
















 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
 Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
 A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca
A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca



















