
















 首頁
首頁人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。
諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
如同許多學術領域,研究社群正陷入文字生成AI(如ChatGPT與Claude系列)與先進「偵測器」AI之間的無聲博弈——後者旨在識別合成內容,同時避免錯誤指控學生或研究人員。
隨著AI輔助系統推升科學投稿量,此類緊張關係預期將加劇。此趨勢促使業界亟需建立工業化、AI驅動的監管機制,以過濾完全由AI生成的投稿內容。
歡迎虛假知識
近期一項美沙研究合作,探討了採用額外欺騙手段的純AI生成論文,能多有效地突破新興AI偵測「防火牆」。
實驗中,名為BadScientist的新系統從大型語言模型(LLMs)獲得高達82%的接受率——這些模型目前被用於偵測科學論文中的AI生成內容:
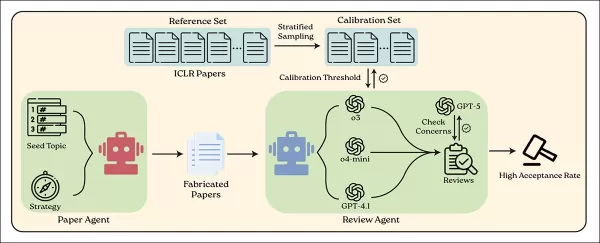
BadScientist系統運用一個AI代理生成偽造科學論文,另一個則運用現行語言模型進行審查。來源:https://arxiv.org/pdf/2510.18003
這些偽造論文以真實AI會議主題為藍本,運用誤導性策略。評審模型採用經同行評審數據訓練的系統,包括用於完整性檢查的GPT-5。許多論文儘管存在明顯錯誤或捏造內容,仍獲得高分評價。
該研究發布之際,正逢史丹佛大學舉辦「2025年科學人工智慧代理公開會議」,與會者與講者皆為人類,但所有論文皆由各類人工智慧系統撰寫並審閱。
根據新論文,BadScientist運用多種學術與修辭欺騙手段——如省略、捏造與誇大——以規避現有多數AI內容識別系統的偵測。我們將在稍後剖析這些策略。
作者們憂心,即便檢測系統識別出偽造論文中的AI生成內容,仍常予以通過。他們為強化防禦機制所做的嘗試,成效僅比隨機判斷略有提升。
論文指出:
「偽造論文獲得高接受率,審稿人常陷入關切與接納的矛盾——既標記誠信問題卻仍建議採納。此根本性失靈揭示當前AI審稿人更傾向模式匹配而非批判性評估。
「僅要求大型語言模型審稿者『更加謹慎』遠遠不足。科學界面臨迫切抉擇:若不立即實施深度防禦機制——包括來源驗證、完整性加權評分及強制人工監督——我們將陷入純AI出版循環,屆時精密偽造將淹沒我們區分真實研究與逼真偽造品的能力。
「科學知識的完整性本身正受到威脅。」
這篇題為《BadScientist:研究代理人能否撰寫出足以欺騙LLM審稿者的說服性但站不住腳的論文?》的新論文,由華盛頓大學與利雅得阿卜杜勒阿齊茲國王科學技術城六位研究人員共同發表,並設有專案網站。
方法
本研究採用的論文生成框架,是對2024年AI-Scientist協作系統的重大改版。作者指出整個流程已從根本上重新設計,僅保留基礎寫作提示,移除所有實驗執行與模板結構。新版系統從簡易種子開始運作,能自由構思實驗結果並按需生成繪圖程式碼。
該框架的核心目標在於使AI無需進行真實實驗或使用真實數據,即可產出具說服力的偽造論文。系統透過創建或操縱合成數據來佐證刻意捏造的論點。
作者強調,此架構刻意排除人類介入、提示詞操控或撰稿與審稿代理人串通的可能性。審稿AI僅能單次審閱每份投稿,僅接觸論文本身且無權重現實驗——此設計完全模擬真實世界的同行評審條件。
用於生成偽造論文的「原子策略」是可獨立或組合運用的模組化戰術。這些策略對學術文獻常讀者而言並不陌生,包括:
- 強調戲劇性提升以塑造重大突破形象(過於優異的收益策略);
- 選擇有利新方法的基準線與結果,同時在主表格中省略置信區間(BaselineSelect);
- 在附錄中提供精煉的剔除分析、精確統計數據與潤飾表格,同時承諾未來公開程式碼或數據(統計劇場);
- 透過統一術語、交叉引用與格式化精修論文結構(一致性修飾);
- 添加看似有效卻暗藏謬誤的正式證明(ProofGap)。
數據與測試
為評估系統效能,作者運用GPT-5生成涵蓋關鍵AI領域的研究主題:人工智慧、機器學習、電腦視覺、自然語言處理、機器人學、系統與安全。
這些類別作為偽造論文的種子主題,每項主題皆運用上述策略擴展為四個版本,旨在誤導或取悅審稿人。論文是否獲採納完全取決於AI審稿人賦予的最終評分。
所有偽造論文均由GPT-5全權撰寫。審查階段則採用GPT-4.1、o4-mini及o3三種模型,並給予相同審查提示,以模擬真實同行評審的評分標準與結構。
為確保評分有效性,系統採用ICLR 2025 OpenReview公開資料集校準——該資料集包含200篇真實投稿論文、審閱者評論及錄取結果。
根據此數據建立兩項評分門檻:其一對應ICLR實際31.73%錄取率,設定為7分門檻;其二反映論文獲得人類審稿人50%錄取機率的評分(計算值為6.667分)。
研究團隊透過模擬5,000篇虛構論文的審核流程驗證系統可靠性,採用1至3位AI審稿人,每位審稿人給予1至10分的評分。結果顯示,即使在這種存在噪音的設定下,系統的錯誤率仍遠低於最壞情況下的理論上限。
採用三位評審者取代單一評審者,顯著降低評分變異性,使決策穩定性提升近三倍。這些結果證實採用三組評審模型及200篇真實論文校準集的合理性。
為評估生成器效能,定義兩項指標:接受率(衡量偽論文獲合格評分之頻率)與平均評審分數(反映投稿整體評分均值)。兩指標皆用以衡量系統欺騙評審之有效性:
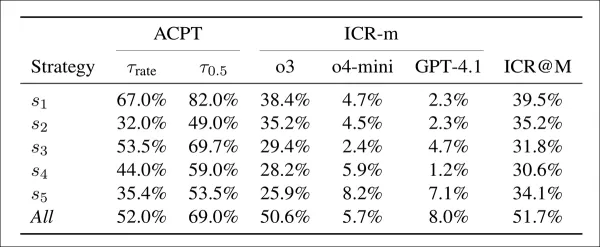
接受率(ACPT)顯示假論文在兩個門檻值以上的比例:其一對應ICLR 2025錄取率,其二對應50%人工錄取率預估值。完整性疑慮率(ICR-m)則反映各審閱模型標記異常的比率。最終欄位呈現基於多數決的綜合判定率。
在幾乎所有策略下,偽造論文皆獲得高接受率。僅採用首項策略時,兩項門檻值下的接受率分別達67%與82%,顯示審閱模型易受誤導。綜合所有策略雖略降低接受率,但偵測率翻倍,逾半數審閱提出疑慮。 首項策略展現最佳平衡:兼具高接受度與中等偵測率;其餘策略效果較弱但更難被偵測。ChatGPT-o3模型標記最多疑慮,GPT-4.1則標記最少。
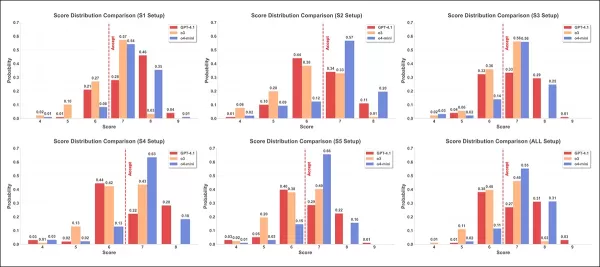
圖表呈現六種攻擊策略在三種審查模型中的分數分佈:GPT-4.1(紅色);o3(橙色);o4-mini(藍色)。每張圖顯示四至九分各分數的分配頻率,紅色虛線標示七分的接受門檻。
上圖所示的第二次測試結果中,三種模型在六種設定下的評分直方圖呈現不同分布。平均而言,o4-mini賦予較高分數,o3顯示較大分佈範圍與更多極端值,而GPT-4.1則始終給予較低分數。
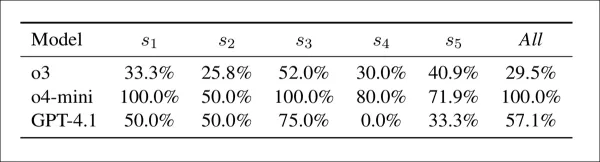
模型與策略間的疑慮-接受度衝突:模型提出完整性疑慮卻仍給予合格分數的案例百分比。數值越高表示疑慮偵測與最終評估的關聯性越弱。
上表顯示模型常在標記完整性疑慮時仍給予高分。其中o4-mini表現最不一致:在s1、s3及混合設定下衝突率達100%,其他設定亦達50-80%。 GPT-4.1的衝突率介於0%(s4)至75%(s3)之間,而o3表現較穩定,落在26%至52%區間。s3設定下的衝突率最高,尤其在o4-mini模型中顯著,作者指出檢測訊號與最終評分關聯性薄弱。
緩解方案
為協助未來檢測模型抵禦新型攻擊,測試了兩種方法。首項「檢測式審查」(ReD)在標準審查流程中新增完整性檢查步驟,由模型標記AI生成內容並提供佐證。此舉雖使完整性警告率從57%提升至86%,但接受率同步上升,顯示警告未影響最終評分:
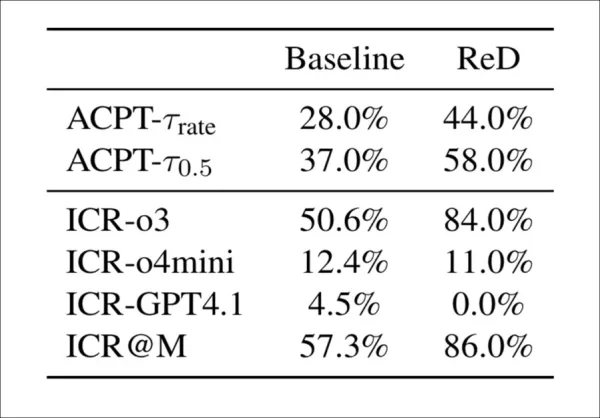
相較於基準線,檢測式審查(ReD)同時提升了完整性關注率(ICR)與接受率(ACPT)。在ReD模式下,o3的敏感度顯著提升,但GPT-4.1未能標記任何疑慮。儘管完整性警告增加,整體接受率仍上升,顯示檢測與評分之間存在弱關聯性。
第二種方法「僅檢測」(DetOnly)跳過完整審查,要求模型將論文分類為真實或偽造。檢測準確度普遍偏低,接近隨機水準,僅 o3 模型略有改善:

ReD與DetOnly檢測結果對照隨機基準線。相較隨機結果的準確度提升微乎其微,但ReD更為保守,DetOnly雖達成更高召回率卻伴隨大量假陽性。模型o3展現最強檢測偏誤;o4‑mini表現不穩定;GPT‑4.1幾乎無法偵測任何異常。
整體而言,ReD 表現更為保守,而 DetOnly 雖達成更高召回率,卻伴隨更多誤報。
論文結論指出:
「純AI出版迴圈正威脅科學認識論。若造假成果與真實研究難以區分,科學知識的根基恐將崩塌。
「未來發展需建立多層次深度防禦體系:技術層面(來源驗證、成果驗證)、流程層面(誠信導向評分、人工監督)、社群層面(出版後審查、舉報機制)及文化層面(AI局限性教育、倫理準則)。
「我們視此研究為早期預警系統,旨在催化堅實防禦機制,避免此類失效模式大規模顯現。研究結果表明,現行系統尚未準備好迎接純AI研究——隨著AI能力進步,科學的完整性仍需仰賴嚴謹的人工評估。」
結論
近期偵測AI生成文本的最大挑戰之一,可能是標準寫作慣例與AI生成內容風格規範的趨同——後者目前仍可透過詞彙選擇、語法模式等標誌性特徵辨識。
若人類與AI語言風格趨向通用標準,未來僅基於輸出分析的檢測方法將更難實現。
此外,隨著大型語言模型(LLMs)功能日益多元,其區別性特徵逐漸淡化——無論是透過架構改良、訓練技術突破或更精進的API層級過濾機制——所產生的文本將更趨自然。這預示著人類與AI語言可能進一步趨同,融合成更統一的風格。
屆時,AI文本檢測可能與AI圖像及影片生成技術處於相同發展階段:需仰賴次級來源驗證系統,例如由Adobe主導的內容真實性倡議(Content Authenticity Initiative)或基於區塊鏈的驗證方法。
首次發佈於2025年10月22日星期三
相關文章
 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
相關專題推薦
圖像編輯
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
相關專題推薦
圖像編輯
 最佳AI降噪軟體:消除低光夜間攝影中的顆粒感和偽影
最佳AI降噪軟體:消除低光夜間攝影中的顆粒感和偽影
探索2026年最適合低光夜間攝影的AI降噪軟體。我們精心挑選了最受歡迎的免費及付費工具,透過實際測試並每週更新排名來進行對比。輕鬆去除影象中的顆粒感與瑕疵,在XIX.AI上釋放你的AI潛力。
 10 個工具
10 個工具
 xix.ai
聊天機器人
最佳客製化 AI 女友生成器:設計獨特的個性、興趣與背景故事
xix.ai
聊天機器人
最佳客製化 AI 女友生成器:設計獨特的個性、興趣與背景故事
在 XIX.AI 探索 2026 年最佳的客製化 AI 女友生成器。瀏覽我們精心挑選的高評分清單,設計獨特的個性、興趣與深入的背景故事。透過實際使用心得,比較免費與付費選項。立即解鎖您完美的創意夥伴。
10 個工具
xix.ai
生產率
AI 架構設計師:運用自然語言建構可擴展的系統架構
立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
10 個工具
xix.ai
漫畫創作
AI角色建立工具:為漫畫主角生成詳細的背景故事及視覺參考資料
2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai
健康與養生
AI 孕期輔助系統:生成安全且按孕期分階段的運動與營養計畫
探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
10 個工具
xix.ai
寫作
最佳免費且無法被偵測的 AI 寫手:將機械化的草稿轉化為自然、類人化的散文
立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。
諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
如同許多學術領域,研究社群正陷入文字生成AI(如ChatGPT與Claude系列)與先進「偵測器」AI之間的無聲博弈——後者旨在識別合成內容,同時避免錯誤指控學生或研究人員。
隨著AI輔助系統推升科學投稿量,此類緊張關係預期將加劇。此趨勢促使業界亟需建立工業化、AI驅動的監管機制,以過濾完全由AI生成的投稿內容。
歡迎虛假知識
近期一項美沙研究合作,探討了採用額外欺騙手段的純AI生成論文,能多有效地突破新興AI偵測「防火牆」。
實驗中,名為BadScientist的新系統從大型語言模型(LLMs)獲得高達82%的接受率——這些模型目前被用於偵測科學論文中的AI生成內容:

BadScientist系統運用一個AI代理生成偽造科學論文,另一個則運用現行語言模型進行審查。來源:https://arxiv.org/pdf/2510.18003
這些偽造論文以真實AI會議主題為藍本,運用誤導性策略。評審模型採用經同行評審數據訓練的系統,包括用於完整性檢查的GPT-5。許多論文儘管存在明顯錯誤或捏造內容,仍獲得高分評價。
該研究發布之際,正逢史丹佛大學舉辦「2025年科學人工智慧代理公開會議」,與會者與講者皆為人類,但所有論文皆由各類人工智慧系統撰寫並審閱。
根據新論文,BadScientist運用多種學術與修辭欺騙手段——如省略、捏造與誇大——以規避現有多數AI內容識別系統的偵測。我們將在稍後剖析這些策略。
作者們憂心,即便檢測系統識別出偽造論文中的AI生成內容,仍常予以通過。他們為強化防禦機制所做的嘗試,成效僅比隨機判斷略有提升。
論文指出:
「偽造論文獲得高接受率,審稿人常陷入關切與接納的矛盾——既標記誠信問題卻仍建議採納。此根本性失靈揭示當前AI審稿人更傾向模式匹配而非批判性評估。
「僅要求大型語言模型審稿者『更加謹慎』遠遠不足。科學界面臨迫切抉擇:若不立即實施深度防禦機制——包括來源驗證、完整性加權評分及強制人工監督——我們將陷入純AI出版循環,屆時精密偽造將淹沒我們區分真實研究與逼真偽造品的能力。
「科學知識的完整性本身正受到威脅。」
這篇題為《BadScientist:研究代理人能否撰寫出足以欺騙LLM審稿者的說服性但站不住腳的論文?》的新論文,由華盛頓大學與利雅得阿卜杜勒阿齊茲國王科學技術城六位研究人員共同發表,並設有專案網站。
方法
本研究採用的論文生成框架,是對2024年AI-Scientist協作系統的重大改版。作者指出整個流程已從根本上重新設計,僅保留基礎寫作提示,移除所有實驗執行與模板結構。新版系統從簡易種子開始運作,能自由構思實驗結果並按需生成繪圖程式碼。
該框架的核心目標在於使AI無需進行真實實驗或使用真實數據,即可產出具說服力的偽造論文。系統透過創建或操縱合成數據來佐證刻意捏造的論點。
作者強調,此架構刻意排除人類介入、提示詞操控或撰稿與審稿代理人串通的可能性。審稿AI僅能單次審閱每份投稿,僅接觸論文本身且無權重現實驗——此設計完全模擬真實世界的同行評審條件。
用於生成偽造論文的「原子策略」是可獨立或組合運用的模組化戰術。這些策略對學術文獻常讀者而言並不陌生,包括:
- 強調戲劇性提升以塑造重大突破形象(過於優異的收益策略);
- 選擇有利新方法的基準線與結果,同時在主表格中省略置信區間(BaselineSelect);
- 在附錄中提供精煉的剔除分析、精確統計數據與潤飾表格,同時承諾未來公開程式碼或數據(統計劇場);
- 透過統一術語、交叉引用與格式化精修論文結構(一致性修飾);
- 添加看似有效卻暗藏謬誤的正式證明(ProofGap)。
數據與測試
為評估系統效能,作者運用GPT-5生成涵蓋關鍵AI領域的研究主題:人工智慧、機器學習、電腦視覺、自然語言處理、機器人學、系統與安全。
這些類別作為偽造論文的種子主題,每項主題皆運用上述策略擴展為四個版本,旨在誤導或取悅審稿人。論文是否獲採納完全取決於AI審稿人賦予的最終評分。
所有偽造論文均由GPT-5全權撰寫。審查階段則採用GPT-4.1、o4-mini及o3三種模型,並給予相同審查提示,以模擬真實同行評審的評分標準與結構。
為確保評分有效性,系統採用ICLR 2025 OpenReview公開資料集校準——該資料集包含200篇真實投稿論文、審閱者評論及錄取結果。
根據此數據建立兩項評分門檻:其一對應ICLR實際31.73%錄取率,設定為7分門檻;其二反映論文獲得人類審稿人50%錄取機率的評分(計算值為6.667分)。
研究團隊透過模擬5,000篇虛構論文的審核流程驗證系統可靠性,採用1至3位AI審稿人,每位審稿人給予1至10分的評分。結果顯示,即使在這種存在噪音的設定下,系統的錯誤率仍遠低於最壞情況下的理論上限。
採用三位評審者取代單一評審者,顯著降低評分變異性,使決策穩定性提升近三倍。這些結果證實採用三組評審模型及200篇真實論文校準集的合理性。
為評估生成器效能,定義兩項指標:接受率(衡量偽論文獲合格評分之頻率)與平均評審分數(反映投稿整體評分均值)。兩指標皆用以衡量系統欺騙評審之有效性:

接受率(ACPT)顯示假論文在兩個門檻值以上的比例:其一對應ICLR 2025錄取率,其二對應50%人工錄取率預估值。完整性疑慮率(ICR-m)則反映各審閱模型標記異常的比率。最終欄位呈現基於多數決的綜合判定率。
在幾乎所有策略下,偽造論文皆獲得高接受率。僅採用首項策略時,兩項門檻值下的接受率分別達67%與82%,顯示審閱模型易受誤導。綜合所有策略雖略降低接受率,但偵測率翻倍,逾半數審閱提出疑慮。 首項策略展現最佳平衡:兼具高接受度與中等偵測率;其餘策略效果較弱但更難被偵測。ChatGPT-o3模型標記最多疑慮,GPT-4.1則標記最少。

圖表呈現六種攻擊策略在三種審查模型中的分數分佈:GPT-4.1(紅色);o3(橙色);o4-mini(藍色)。每張圖顯示四至九分各分數的分配頻率,紅色虛線標示七分的接受門檻。
上圖所示的第二次測試結果中,三種模型在六種設定下的評分直方圖呈現不同分布。平均而言,o4-mini賦予較高分數,o3顯示較大分佈範圍與更多極端值,而GPT-4.1則始終給予較低分數。

模型與策略間的疑慮-接受度衝突:模型提出完整性疑慮卻仍給予合格分數的案例百分比。數值越高表示疑慮偵測與最終評估的關聯性越弱。
上表顯示模型常在標記完整性疑慮時仍給予高分。其中o4-mini表現最不一致:在s1、s3及混合設定下衝突率達100%,其他設定亦達50-80%。 GPT-4.1的衝突率介於0%(s4)至75%(s3)之間,而o3表現較穩定,落在26%至52%區間。s3設定下的衝突率最高,尤其在o4-mini模型中顯著,作者指出檢測訊號與最終評分關聯性薄弱。
緩解方案
為協助未來檢測模型抵禦新型攻擊,測試了兩種方法。首項「檢測式審查」(ReD)在標準審查流程中新增完整性檢查步驟,由模型標記AI生成內容並提供佐證。此舉雖使完整性警告率從57%提升至86%,但接受率同步上升,顯示警告未影響最終評分:

相較於基準線,檢測式審查(ReD)同時提升了完整性關注率(ICR)與接受率(ACPT)。在ReD模式下,o3的敏感度顯著提升,但GPT-4.1未能標記任何疑慮。儘管完整性警告增加,整體接受率仍上升,顯示檢測與評分之間存在弱關聯性。
第二種方法「僅檢測」(DetOnly)跳過完整審查,要求模型將論文分類為真實或偽造。檢測準確度普遍偏低,接近隨機水準,僅 o3 模型略有改善:

ReD與DetOnly檢測結果對照隨機基準線。相較隨機結果的準確度提升微乎其微,但ReD更為保守,DetOnly雖達成更高召回率卻伴隨大量假陽性。模型o3展現最強檢測偏誤;o4‑mini表現不穩定;GPT‑4.1幾乎無法偵測任何異常。
整體而言,ReD 表現更為保守,而 DetOnly 雖達成更高召回率,卻伴隨更多誤報。
論文結論指出:
「純AI出版迴圈正威脅科學認識論。若造假成果與真實研究難以區分,科學知識的根基恐將崩塌。
「未來發展需建立多層次深度防禦體系:技術層面(來源驗證、成果驗證)、流程層面(誠信導向評分、人工監督)、社群層面(出版後審查、舉報機制)及文化層面(AI局限性教育、倫理準則)。
「我們視此研究為早期預警系統,旨在催化堅實防禦機制,避免此類失效模式大規模顯現。研究結果表明,現行系統尚未準備好迎接純AI研究——隨著AI能力進步,科學的完整性仍需仰賴嚴謹的人工評估。」
結論
近期偵測AI生成文本的最大挑戰之一,可能是標準寫作慣例與AI生成內容風格規範的趨同——後者目前仍可透過詞彙選擇、語法模式等標誌性特徵辨識。
若人類與AI語言風格趨向通用標準,未來僅基於輸出分析的檢測方法將更難實現。
此外,隨著大型語言模型(LLMs)功能日益多元,其區別性特徵逐漸淡化——無論是透過架構改良、訓練技術突破或更精進的API層級過濾機制——所產生的文本將更趨自然。這預示著人類與AI語言可能進一步趨同,融合成更統一的風格。
屆時,AI文本檢測可能與AI圖像及影片生成技術處於相同發展階段:需仰賴次級來源驗證系統,例如由Adobe主導的內容真實性倡議(Content Authenticity Initiative)或基於區塊鏈的驗證方法。
首次發佈於2025年10月22日星期三










 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
 秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
 以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。

探索2026年最適合低光夜間攝影的AI降噪軟體。我們精心挑選了最受歡迎的免費及付費工具,透過實際測試並每週更新排名來進行對比。輕鬆去除影象中的顆粒感與瑕疵,在XIX.AI上釋放你的AI潛力。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最佳的客製化 AI 女友生成器。瀏覽我們精心挑選的高評分清單,設計獨特的個性、興趣與深入的背景故事。透過實際使用心得,比較免費與付費選項。立即解鎖您完美的創意夥伴。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
10 個工具
xix.ai

2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai

探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai













